Con más de 666 millones de usuarios activos, la antigua Twitter, o la nueva marca XTwitter es una de las plataformas de redes sociales más populares y una valiosa fuente de información para empresas, investigadores y particulares. Sin embargo, extraer y filtrar datos manualmente del vasto dominio de datos de Twitter resulta abrumador y poco funcional.

El scraping de Twitter consiste en utilizar software o scripts para recopilar datos de la plataforma. Puedes analizar estos datos para obtener información muy valiosa sobre los temas y hashtags de moda, las conversaciones, las interacciones que se producen en la plataforma y el comportamiento de los usuarios.
La información recopilada puede analizarse meticulosamente para diversos fines, como el análisis de opiniones, la investigación de mercados y la monitorización de redes sociales. Este artículo profundizará en distintos aspectos de raspado datos de Twitter utilizando los métodos existentes, desde el scripting hasta el software sin código, los costes asociados y la legalidad y los términos éticos.
Descargo de responsabilidad: Este material ha sido desarrollado estrictamente con fines informativos. No constituye respaldo de ninguna actividad (incluidas las actividades ilegales), productos o servicios. Usted es el único responsable de cumplir con las leyes aplicables, incluidas las leyes de propiedad intelectual, cuando utilice nuestros servicios o confíe en cualquier información contenida en este documento. No aceptamos ninguna responsabilidad por los daños que surjan del uso de nuestros servicios o la información contenida en este documento de ninguna manera, excepto cuando lo exija explícitamente la ley.
Tabla de contenidos
¿Qué tipos de datos pueden extraerse de Twitter?
Puedes extraer diferentes tipos de datos de Twitter. Aquí tienes tres tipos de datos principales para el scraping de Twitter:
- Tweets: Puede capturar datos específicos de tweets filtrados en función de perfiles, como sus me gusta, respuestas, retweets y URL especificadas.
- Perfiles de usuario: Se puede recopilar cualquier dato de un perfil de usuario público, como la biografía del usuario, la descripción del perfil, el número de tweets, retweets, el número de seguidores/seguidos y la imagen del perfil.
- Palabras clave/Hashtags: Puedes recopilar tweets que contengan determinadas palabras clave, hashtags o su combinación. También es posible refinar la búsqueda por el número de "me gusta" o buscando fechas y horas concretas.
Legalidad y ética
Al sumergirse en el mundo del scraping de datos, es esencial comprender los límites legales y éticos implicados.
Según la Condiciones de uso de Twitter (Acuerdo y Política del Desarrollador), el scraping de datos sin permiso explícito está prohibido y declarado por la política de Twitter: "El scraping de los Servicios sin el consentimiento previo de Twitter está expresamente prohibido.
Cualquier abuso de la API de Twitter para estos fines estará sujeto a medidas coercitivas, que pueden incluir la suspensión y el cese del acceso.
Guía general para el scraping de Twitter
Después de una breve introducción al scraping de Twitter, es hora de explorar el proceso de scraping a través de los datos de Twitter. Por ello, hemos recopilado para ti una guía sencilla y completa sobre el scraping de Twitter. Sigue los pasos que se indican a continuación:
- En primer lugar, debe disponer de las herramientas de raspado adecuadas. Hay muchas opciones entre las que elegir. Por tanto, determine qué opción se ajusta a su presupuesto y preferencias.
- Descargue e instale la herramienta de raspado en su sistema.
- Asegúrese de que hay mucho espacio de almacenamiento disponible en su dispositivo y que dispone de una conexión a Internet fiable.
- Tras la instalación, inicia sesión con los datos de tu cuenta de Twitter.
- Ajustar los parámetros para el scraping de datos de Twitter es un paso importante que permite extraer datos en función de palabras clave, hashtags, fechas y horas, ubicaciones, URL, etc.
- Después de ejecutar la herramienta de raspado, quedará una gran cantidad de datos. Puede exportar los datos a diferentes formatos de archivo (xlsx, CSV, JSON, etc.).
- En el último paso, debe analizar los datos exportados para obtener información sobre su tema de interés.
Herramientas y métodos de Twitter Scraping
Hemos revisado algunas herramientas de scraping disponibles en Internet, desde la oficial Twitter scraper a servicios de terceros e incluso a librerías Python de código abierto, y las enumero a continuación.
4.1. Raspadores de Twitter basados en API
El primer método que vamos a analizar son los raspadores de Twitter basados en API, entre los que se incluyen Twitter API V2, Apify, Brightdata y Scrapingdog.
4.1.1. Twitter API V2
Twitter API v2 es la última versión de la API de Twitter, la API oficial y una de las más utilizadas por los desarrolladores que crean aplicaciones con interacción social o por investigadores o particulares que recopilan datos para sus fines específicos. El uso de las nuevas API permite supervisar y analizar sin esfuerzo las conversaciones en directo en las redes sociales.
Recientemente, Twitter ha añadido algunas características nuevas, como puntos finales, opciones de carga útil para publicaciones de tweets, conjuntos de identificadores de conversación y anotaciones. Estos cambios son bastante impresionantes. Sin embargo, la nueva estructura de precios ha suscitado serias preocupaciones entre los desarrolladores y las aplicaciones de terceros. Con la nueva estructura de precios, el acceso a los servicios ha disminuido drásticamente y los precios han subido mucho.
Los planes de precios de la API v2 de Twitter/X tienen tres niveles: Gratuito, Básicoy Empresa.
- En el nivel gratuito, los desarrolladores pueden publicar hasta 1500 tweets al mesdiseñado para uso de sólo escritura y para probar la API de Twitter.
- El nivel básico cuesta $100 al mes y permite a los desarrolladores publicar hasta 3.000 tweets al mes a nivel de usuario y 50.000 tweets (con un límite de lectura de 10.000) a nivel de aplicación.
- El neumático Enterprise incluye características más avanzadas diseñadas para las empresas. Sin embargo, el plan Enterprise cobrará a los desarrolladores/empresas un precio desorbitado de 1,5 millones de euros. casi 42000$ al mes.
4.1.2. Apify
A través de Twitter Scraper de Apify, puedes extraer información de datos de Twitter disponibles públicamente, como hashtags, hilos, respuestas, imágenes y mucho más. Los recientes cambios en Twitter han puesto nuevos límites a la visualización y raspado de tweets en esta plataforma, ya que los usuarios sólo podrán extraer información pública hasta 100 tweets por perfil. Este scraper no puede extraer los tweets más recientes, pero sí los que más gustan. Se puede acceder a los datos extraídos en formatos HTML, JSON, Excel y CSV.
La siguiente figura ilustra los costes mensuales del servicio de Apify. También ofrece un descuento de 10% para el plan anual. Para más información, visite Precios Apify.
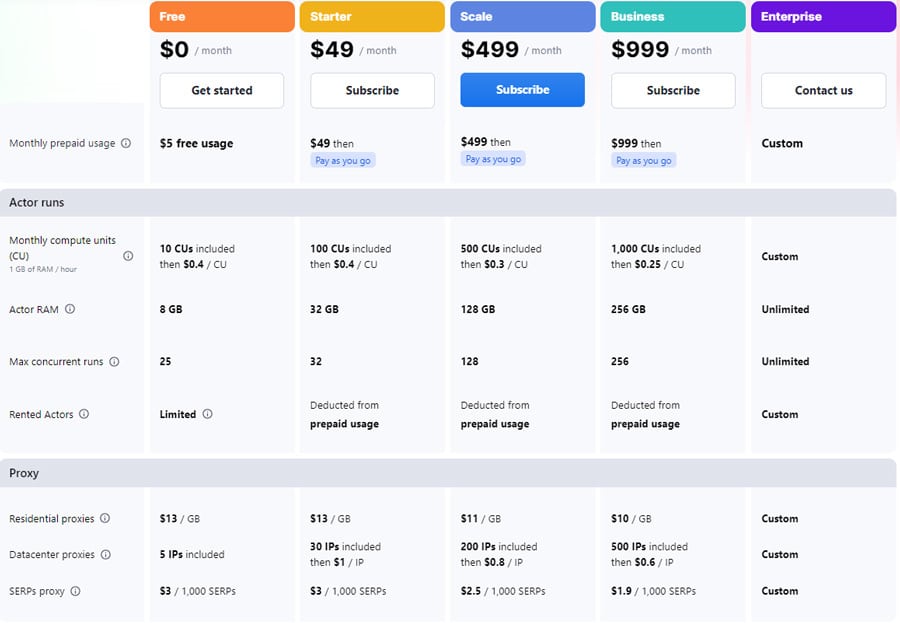
4.1.3. Brightdata
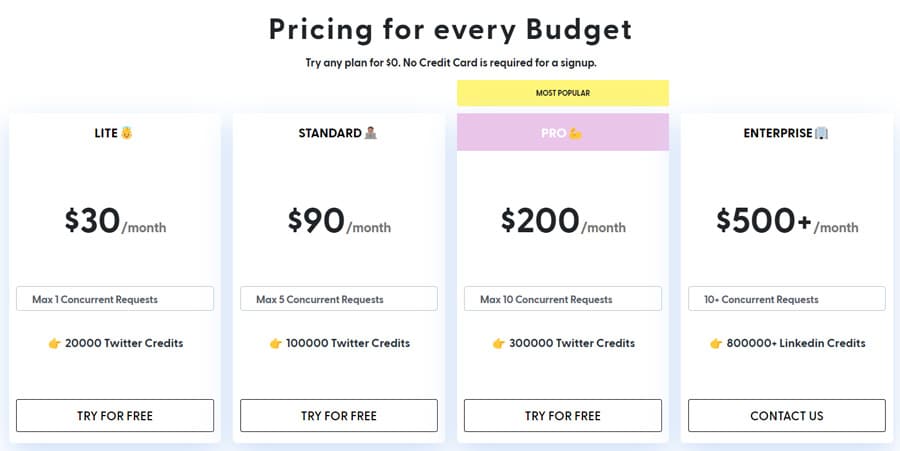
Bright Data is a data collection platform that offers web scraping tools such as proxy servers, APIs, and no-code solutions. Bright Data’s Web Scraper gives users the ability to extract data from public Twitter profiles, including images, videos, tweets, hashtags, and more.
Los precios comienzan con un 500$ mensual para 151000 cargas de página. Bright Data Twitter scraper colector de datos es compatible con todos los servicios web y salidas de sus datos en formato Excel. También ofrece una prueba de 7 días, y usted puede probar la plataforma antes de pagar 500 dólares.
¿Listo para llevar tu Twitter scraper al siguiente nivel?
4.1.4. Scrapingdog
Scrapingdog es una API de raspado web que te ayuda a raspar cualquier sitio web, incluido Twitter. Te permite scrapear tweets usando IDs de tweets o scrapear páginas públicas para extraer detalles como número de seguidores, número de seguidos y enlaces a sitios web.
Te cuesta 0,0009$ por página raspar Twitter en el plan estándar, que se encuentra entre el mejor valor sobre el precio en comparación con los otros mejores raspadores de Twitter. También han proporcionado una prueba gratuita; puede cancelar su suscripción en cualquier momento y reembolsar su dinero fácilmente. Para obtener más información acerca de cómo raspar datos utilizando Scrapingdog, puede visitar Documentación de la API de Twitter Scraping.
4.2. Bibliotecas y paquetes de Python para el scraping de Twitter
Ahora que estás familiarizado con la API de Twitter y aplicaciones como Apify, es el momento de echar un vistazo a las bibliotecas y paquetes de Python para Twitter scraping.
4.2.1. Tweepy
Tweepy es un paquete Python de código abierto que permite a los desarrolladores acceder a los puntos finales de Twitter de forma fluida y transparente. Sin embargo, debe tener en cuenta que Twitter ha impuesto limitaciones al número de solicitudes enviadas a la API X/Twitter, donde Se permiten 900 solicitudes cada 15 minutos. En esta sección, pretendemos echar un vistazo a la funcionalidad de Tweepy y dar un ejemplo sencillo.
Para empezar, instala el paquete Tweepy usando el comando "pip install Tweepy" en tu IDE de Python y luego importa también Tweepy. Registrar tu aplicación cliente con Twitter es el siguiente paso. Crea una nueva aplicación. Una vez completado, recibirás un token de portador.
|
1 2 |
pip install tweepy importar tweepy |
A continuación, debes crear una instancia "Cliente" para pasar el token de consumidor portador que has obtenido de la API de Twitter.
En la variable de consulta, especificamos un campo, una mención y un hashtag como se ha demostrado.
|
1 2 3 |
cliente = tweepy.Cliente(ficha_portador='bearer_token') consulta = 'consulta @menciones #hashtags' |
Para buscar los tweets de los últimos siete días, puede utilizar la función search_recent_tweets disponible en Tweepy. Para especificar los datos que buscas, necesitas pasar una consulta de búsqueda.
|
1 2 |
tweets_recientes = cliente.buscar_tweets_recientes(consulta=consulta, campos_tweet=['tweet_field_1', 'campo_tweet_2'], max_resultados=100) |
Si tiene acceso a la pista de productos de investigación académica, puede recuperar tweets de más de 7 días. Del archivo completo de tuits disponibles públicamente.
|
1 2 |
tuitea = cliente.buscar_todos_los_tweets(consulta=consulta, campos_tweet=['tweet_field_1', 'campo_tweet_2'], max_resultados=100) |
Puede exportar los resultados utilizando el siguiente código.
|
1 2 3 4 5 |
para tuitee en tuitea.data: imprimir(tuitee.texto) si len(tuitee.anotaciones_de_contexto) > 0: imprimir(tuitee.anotaciones_de_contexto) |
También hay un montón de funciones en Tweepy capaces de realizar diversas tareas en casos más complejos y específicos.
4.2.2. Snscrape
Otra forma de obtener información de Twitter sin depender de una API es a través de Snscrape. Te permite recuperar información básica como perfiles de usuario, contenido de los tweets, fuentes, etc. A diferencia de Tweepy, no hay límites en el número de tweets que puedes raspar o en las fechas de los tweets, y puedes extraer datos antiguos de Twitter. Dado que Snscrape no está conectado a la API de Twitter, carece de funcionalidad al nivel de Tweepy. Consulta nuestra guía completa sobre Snscrape.
En esta sección, también revisamos un ejemplo básico de scraping de algunos datos de Twitter utilizando Snscrape en Python.
En primer lugar, debes instalar Snscrape. Ten en cuenta que debes tener Python 3.8 o superior instalado para que funcione.
|
1 2 |
pip install snscrape |
En el siguiente paso, instale las siguientes bibliotecas.
|
1 2 3 |
importar snscrape.módulos.twitter como sntwitter importar pandas como pd |
Enviamos una consulta (en nuestro caso, "query") utilizando la función "TwitterSearchScraper(query).get_items" y obtenemos elementos de la búsqueda igual que los resultados de la barra de búsqueda de Twitter.
|
1 2 3 4 5 6 |
consulta = "consulta" para tuitee en sntwitter.TwitterSearchScraper(consulta).obtener_artículos(): imprimir(vars(tuitee)) romper |
Hay otros métodos que se pueden utilizar para el scraping de datos de Twitter, tales como: TwitterSearchScraper, TwitterUserScraper, TwitterProfileScraper, TwitterHashtagScraper, TwitterTweetScraperMode, TwitterTweetScraper, TwitterListPostsScraper, TwitterTrendsScraper.
Técnicas avanzadas de scraping y desafíos
Cuando los métodos básicos de scraping alcanzan sus límites con las sofisticadas defensas de Twitter, las técnicas avanzadas se vuelven esenciales. La moderna interfaz de Twitter se basa en gran medida en la renderización de JavaScript e implementa múltiples capas de detección de bots, por lo que las solicitudes HTTP tradicionales resultan insuficientes para una recopilación de datos fiable.
Gestión de contenidos dinámicos con navegadores sin cabecera
La cronología de Twitter se carga dinámicamente a través de JavaScript, lo que significa que el contenido que ves no está presente en la respuesta HTML inicial. Los navegadores Headless simulan las interacciones reales del usuario, renderizando JavaScript y gestionando la carga dinámica de contenidos.
Playwright vs Selenium: Playwright ofrece un mejor rendimiento y un manejo más fiable de las aplicaciones web modernas, mientras que Selenium sigue siendo la opción establecida con un amplio apoyo de la comunidad.
He aquí un ejemplo práctico utilizando Playwright para scrapear tweets cargados dinámicamente:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
importar asyncio de dramaturgo.async_api importar async_playwright importar json async def raspar_perfil_twitter(nombre de usuario): async con async_playwright() como p: # Iniciar navegador sin cabeza navegador = await p.cromo.lanzar(sin cabeza=Verdadero) contexto = await navegador.nuevo_contexto( agente_usuario="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36" ) página = await contexto.nueva_página() pruebe: # Navegar hasta el perfil await página.ir a(f"https://twitter.com/{username}") # Esperar a que se carguen los tweets await página.wait_for_selector('[data-testid="tweet"]', tiempo de espera=10000) # Desplácese para cargar más tweets para i en gama(3): await página.evaluar("window.scrollTo(0, document.body.scrollHeight)") await página.wait_for_timeout(2000) # Extraer datos de tweets tuitea = await página.evaluar(""" () => { const tweetElements = document.querySelectorAll('[data-testid="tuitee"]'); return Array.from(tweetElements).map(tweet => { const textElement = tweet.querySelector('[data-testid="tweetText"]'); const timeElement = tweet.querySelector('time'); devolver { text: textElement ? textElement.innerText : '', timestamp: timeElement ? timeElement.getAttribute('datetime') : '', url: window.location.href }; }); } """) devolver tuitea excepto Excepción como e: imprimir(f"Error scraping {username}: {e}") devolver [] finalmente: await navegador.cerrar() # Utilización tuitea = asyncio.run(raspar_perfil_twitter("elonmusk")) imprimir(json.vuelca(tuitea[:3], sangría=2)) |
Principales ventajas de los navegadores headless incluyen la gestión de la renderización de JavaScript, la gestión automática de cookies y sesiones, y la evasión de la detección básica de bots mediante huellas dactilares realistas del navegador.
Consideraciones sobre los recursos: Los navegadores sin cabeza consumen mucha más memoria y CPU que las simples peticiones HTTP. Para operaciones a gran escala, considere la posibilidad de ejecutar varias instancias del navegador en diferentes servidores o utilizar grupos de navegadores.
Eludir las medidas antiscraping
Twitter emplea una sofisticada detección de bots que va más allá de la simple limitación de la tasa. Comprender estas medidas ayuda a desarrollar contramedidas eficaces.
Técnicas habituales contra el scraping
Limitación de velocidad: Twitter monitors request frequency per IP address, implementing both short-term (requests per minute) and long-term (daily quotas) limits. Learn more in Web Scraping Rate Limiting: The Fix.
Bloqueo de IP: Las direcciones IP sospechosas se bloquean temporal o permanentemente. Las IP de centros de datos se someten a más escrutinio que las direcciones residenciales.
Desafíos CAPTCHA: Presentación automatizada de CAPTCHA cuando se detecta un comportamiento de tipo bot. Los CAPTCHA modernos utilizan análisis de comportamiento que van más allá del simple reconocimiento de imágenes.
Huella digital del navegador: Análisis de las características del navegador, incluidos el agente de usuario, la resolución de pantalla, los plugins instalados y los patrones de ejecución de JavaScript.
Contramedidas eficaces
Estrategia de rotación de apoderados: El uso de servicios como RapidSeedbox proporciona acceso a grupos de IP residenciales que aparecen como tráfico de usuario legítimo. Los proxies residenciales de su red de más de 6,9 millones de IP reducen significativamente la detección en comparación con los proxies de centros de datos.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
importar al azar importar tiempo de itertools importar ciclo # Configuración de la rotación del proxy lista_proxy = [ "http://user:[email protected]:8080" ] ciclo_proxy = ciclo(lista_proxy) def get_next_proxy(): devolver siguiente(ciclo_proxy) # Implementar en su rascador async def raspar_con_rotación(): para i en gama(10): proxy = get_next_proxy() # Configure su navegador/sesión con el nuevo proxy # Realizar solicitud de raspado # Añadir retardo aleatorio await asyncio.dormir(al azar.uniforme(5, 15)) |
Rotación del agente de usuario: Variar las firmas de los navegadores para evitar la detección de patrones. Utiliza cadenas de agentes de usuario reales de distintos navegadores y sistemas operativos.
|
1 2 3 4 5 6 7 8 9 |
AGENTES_USUARIOS = [ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, como Gecko) Chrome/120.0.0.0 Safari/537.36", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, como Gecko) Chrome/120.0.0.0 Safari/537.36", "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:121.0) Gecko/20100101 Firefox/121.0" ] def get_random_user_agent(): devolver al azar.elección(AGENTES_USUARIOS) |
Patrones de comportamiento: Imita el comportamiento de navegación humano con retardos variables, patrones de desplazamiento realistas y actividades ocasionales no relacionadas con el scraping.
Gestión de sesiones: Mantenga sesiones consistentes con un manejo adecuado de cookies y evite crear demasiadas sesiones nuevas desde la misma IP.
Evitación de detección avanzada
Plazo de solicitud: Implementa el backoff exponencial cuando encuentres límites de velocidad. Empieza con retardos más largos y redúcelos gradualmente en función de las tasas de éxito.
Coherencia de la geolocalización: Cuando utilice proxies, asegúrese de que sus solicitudes mantienen la coherencia geográfica. No salte rápidamente de un país a otro.
Gestión de huellas dactilares del navegador: Utilice herramientas como undetected-chromedriver o plugins de ocultación para reducir la eficacia de las huellas digitales del navegador.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
de selenio importar webdriver de selenium_stealth importar sigilo def create_stealth_driver(): opciones = webdriver.ChromeOptions() opciones.añadir_argumento("--headless") opciones.añadir_argumento("--no-sandbox") opciones.añadir_argumento("--disable-dev-shm-usage") conductor = webdriver.Cromo(opciones=opciones) sigilo(conductor, idiomas=["en-US", "es"], vendedor="Google Inc.", plataforma="Win32", proveedor_webgl="Intel Inc.", renderizador="Motor Intel Iris OpenGL", fijar_línea_de_pelo=Verdadero, ) devolver conductor |
Tratamiento de errores: Implemente una gestión de errores ágil que pueda distinguir entre bloqueos temporales, prohibiciones permanentes y problemas técnicos.
La combinación de proxies residenciales de servicios como RapidSeedbox, técnicas adecuadas de ocultación del navegador y patrones de comportamiento realistas crea una base sólida para la recopilación de datos de Twitter a gran escala, al tiempo que minimiza los riesgos de detección.
Recuerda que las medidas anti-bot de Twitter siguen evolucionando, por lo que el éxito del scraping requiere una adaptación continua de estas técnicas en función del comportamiento actual de la plataforma.
Preguntas frecuentes
El scraping de Twitter se encuentra en una zona legal gris. Aunque las condiciones de servicio de Twitter prohíben la recopilación automatizada de datos, el scraping de datos públicos no es automáticamente ilegal.
Los riesgos legales incluyen:
1. Infracción de los derechos de autor sobre los contenidos de los usuarios
2. Violaciones de la CFAA en algunas jurisdicciones
3. Cuestiones de cumplimiento del GDPR con los datos personales
Enfoque más seguro: Utiliza la API oficial de Twitter siempre que sea posible, consulta a un asesor jurídico para proyectos de gran envergadura y céntrate en los datos disponibles públicamente para fines de investigación legítimos.
No, pero la codificación proporciona mejores resultados.
Opciones sin código: Las herramientas de automatización del navegador y los creadores de flujos de trabajo visuales funcionan para el scraping básico, pero su velocidad y flexibilidad son limitadas.
Soluciones de codificación: Python con Selenium o librerías especializadas ofrece mayor control, mejor manejo anti-bot y mayores tasas de éxito.
El mejor enfoque: Comience con herramientas sin código para probar sus necesidades y, a continuación, aprenda secuencias de comandos básicas de Python para la recopilación de datos en serio.
El nivel gratuito de la API de Twitter tiene severas restricciones:
1. Límites de tarifa: Cuotas mensuales de solicitudes muy bajas
2. Datos históricos: Limitado a tweets recientes (normalmente de la semana pasada)
3. Características: Sin análisis avanzados ni métricas de compromiso
4. Acceda a: Requiere aprobación de la solicitud
La mayoría de los casos de investigación y uso empresarial superan los límites de los niveles gratuitos, por lo que son necesarios planes de pago o métodos alternativos.
Los datos históricos de Twitter requieren herramientas especializadas, ya que la navegación habitual sólo muestra contenidos recientes.
La mejor herramienta: Snscrape - Librería Python que accede a tweets de años atrás con filtrado por rango de fechas.
Otras opciones:
1. Biblioteca TwitterScraper
2. API de investigación académica (se requiere acceso institucional)
3. Servicios de datos históricos de terceros
Consejo: El scraping histórico es más lento y requiere una cuidadosa limitación de la velocidad para evitar bloqueos.
Prácticas esenciales:
1. Limitación de velocidad: 1-2 segundos entre solicitudes como mínimo
2. Respetar robots.txt: Siga las directrices de la plataforma
3. Minimización de datos: Recoger sólo la información necesaria
4. Retrasos adecuados: Utilice la rotación de IP y proxies residenciales
5. Tratamiento de errores: Detener el scraping si está bloqueado o limitado
Principio clave: Prueba siempre primero las API oficiales y luego haz scraping de forma responsable respetando la infraestructura de Twitter y la privacidad de los usuarios.
Conclusión
Twitter es una valiosa fuente de información sociológica en la red. Al aprovechar la información raspada de Twitter, puede adaptar sus planes para impulsar sus ventas y mejorar sus estrategias de marketing. En este artículo, hemos presentado una visión en profundidad de diferentes aspectos y métodos del scraping de Twitter para extraer datos que pueden ser valiosos para las empresas o la investigación.
En resumen, de acuerdo con las nuevas limitaciones impuestas en la API v2 de Twitter, junto con los altos costes, seleccionar el mejor scraper sería todo un reto. Puedes beneficiarte de funciones más avanzadas de la API de Twitter o de aplicaciones de terceros y bibliotecas de Python (Tweepy) que están directamente conectadas a la API de Twitter.
Pero el número de peticiones que puedes hacer está estrictamente limitado. Por otro lado, si buscas hacer scraping de datos disponibles públicamente y las características básicas satisfacen tus necesidades, opciones como la librería Snscrape Python pueden ser una gran elección.
0Comentarios