Avec plus de 666 millions d'utilisateurs actifs, l'ancienne Twitter, ou une nouvelle marque XTwitter est l'une des plateformes de médias sociaux les plus populaires et une source d'information précieuse pour les entreprises, les chercheurs et les particuliers. Cependant, l'extraction et le filtrage manuels des données du vaste domaine des données Twitter sont fastidieux et non fonctionnels.

Le scraping sur Twitter consiste à utiliser des logiciels ou des scripts pour collecter des données sur la plateforme. Vous pouvez analyser ces données pour obtenir des informations précieuses sur les sujets et hashtags en vogue, les conversations, les interactions qui se produisent sur la plateforme et le comportement des utilisateurs.
Les informations collectées peuvent être minutieusement analysées à des fins diverses, telles que l'analyse des sentiments, les études de marché et la surveillance des médias sociaux. Cet article se penche sur les différents aspects de l'analyse des sentiments, des études de marché et de la surveillance des médias sociaux. raclage Données Twitter à l'aide des méthodes existantes, du script au logiciel sans code, coûts associés, légalité et éthique.
Clause de non-responsabilité : Ce document a été élaboré strictement à des fins d'information. Il ne constitue pas une approbation d'activités (y compris les activités illégales), de produits ou de services. Vous êtes seul responsable du respect des lois applicables, y compris les lois sur la propriété intellectuelle, lorsque vous utilisez nos services ou que vous vous fiez à toute information contenue dans le présent document. Nous n'acceptons aucune responsabilité pour les dommages résultant de l'utilisation de nos services ou des informations qu'ils contiennent, de quelque manière que ce soit, sauf lorsque la loi l'exige explicitement.
Table des matières
Quels types de données peut-on extraire de Twitter ?
Vous pouvez extraire différents types de données de Twitter. Voici les trois principaux types de données pour le scraping de Twitter :
- Tweets : Vous pouvez capturer des données spécifiques à partir de tweets filtrés en fonction des profils, telles que les likes, les réponses, les retweets et les URL spécifiées.
- Profils d'utilisateurs : Tout ce qui se trouve dans un profil d'utilisateur public peut être collecté, comme la biographie de l'utilisateur, la description de son profil, le nombre de tweets, de retweets, le nombre de followers/suivis et l'image de son profil.
- Mots-clés/Hashtags : Vous pouvez collecter des tweets contenant des mots-clés particuliers, des hashtags ou leur combinaison. Il est également possible d'affiner votre recherche en fonction du nombre de likes ou en recherchant des dates et heures spécifiques.
Légalité et éthique des conditions d'utilisation
Lorsque l'on plonge dans le monde du scraping de données, il est essentiel de comprendre les limites juridiques et éthiques qui s'y rattachent.
Selon la Conditions d'utilisation de Twitter (Developer Agreement and Policy), le scraping de données sans autorisation explicite est interdit et déclaré par la politique de Twitter : "Le scraping des services sans l'accord préalable de Twitter est expressément interdit.
Toute utilisation abusive de l'API Twitter à ces fins fera l'objet de mesures coercitives pouvant aller jusqu'à la suspension et la résiliation de l'accès.
Guide général pour le scraping de Twitter
Après une brève introduction au scraping de Twitter, il est temps d'explorer le processus de scraping des données de Twitter. Nous avons donc compilé pour vous un guide simple et complet sur le scraping de Twitter. Veuillez suivre les étapes ci-dessous :
- Tout d'abord, vous devez disposer des bons outils de grattage. Il existe de nombreuses options parmi lesquelles choisir. Déterminez donc l'option qui convient à votre budget et à vos préférences.
- Téléchargez et installez l'outil de scraping sur votre système.
- Veillez à ce qu'il y ait beaucoup d'espace de stockage disponible sur votre appareil et que vous disposez d'une connexion internet fiable.
- Après l'installation, connectez-vous en utilisant les détails de votre compte Twitter.
- L'ajustement des paramètres de récupération des données de Twitter est une étape importante qui vous permet d'extraire des données basées sur des mots-clés, des hashtags, des dates et des heures, des lieux, des URL, etc.
- Après l'exécution de l'outil scraper, une grande quantité de données sera laissée derrière. Vous pouvez exporter les données vers différents formats de fichiers (xlsx, CSV, JSON, etc.).
- La dernière étape consiste à analyser les données exportées afin d'obtenir des informations sur le sujet qui vous intéresse.
Outils et méthodes d'extraction de données de Twitter
Nous avons passé en revue quelques outils de scraping disponibles sur l'internet, de l'officiel Gratte-papier Twitter à des services tiers et même à des bibliothèques Python à code source ouvert, et nous les avons répertoriés ci-dessous.
4.1. Racleurs Twitter basés sur l'API
La première méthode que nous allons examiner est celle des scrapers Twitter basés sur les API, qui comprennent Twitter API V2, Apify, Brightdata et Scrapingdog.
4.1.1. Twitter API V2
Twitter API v2 est la dernière version de l'API de Twitter, l'API officielle et l'une des plus utilisées par les développeurs d'applications d'interaction sociale ou par les chercheurs/individus qui collectent des données à des fins spécifiques. L'utilisation de nouvelles API permet de surveiller et d'analyser sans effort les conversations en direct sur les réseaux sociaux.
Récemment, Twitter a ajouté de nouvelles fonctionnalités, telles que des points de terminaison, des options de charge utile pour les tweets, des ensembles d'identifiants de conversation et des annotations. Ces changements sont assez impressionnants. Cependant, la nouvelle structure tarifaire a soulevé de sérieuses inquiétudes pour les développeurs et les applications tierces. Avec la nouvelle structure tarifaire, l'accès aux services a considérablement diminué et les prix ont augmenté de manière drastique.
Les plans tarifaires de l'API Twitter/X v2 comportent trois niveaux : Gratuit, Basiqueet Entreprise.
- Dans le volet gratuit, les développeurs peuvent publier jusqu'à 1500 tweets par moisconçu pour une utilisation en écriture seule et pour tester l'API de Twitter.
- Le niveau de base coûte $100 par mois et permet aux développeurs de publier jusqu'à 3 000 tweets par mois au niveau de l'utilisateur et 50 000 tweets (avec une limite de lecture de 10 000) au niveau de l'application.
- Le plan Entreprise comprend des fonctionnalités plus avancées conçues pour les entreprises. Cependant, le plan d'entreprise fait payer aux développeurs/entreprises un prix exorbitant de près de 42000$ par mois.
4.1.2. Apify
Grâce à Twitter Scraper d'Apify, vous pouvez extraire des informations à partir de données Twitter accessibles au public, telles que les hashtags, les fils de discussion, les réponses, les images, etc. Les récentes modifications apportées à Twitter ont imposé de nouvelles limites à l'affichage et à l'extraction de tweets sur cette plateforme, les utilisateurs ne pouvant extraire des informations publiques que dans la limite de 100 tweets par profil. Ce scraper ne peut pas extraire les derniers tweets, mais il peut récupérer les tweets les plus appréciés. Les données extraites peuvent être accessibles aux formats HTML, JSON, Excel et CSV.
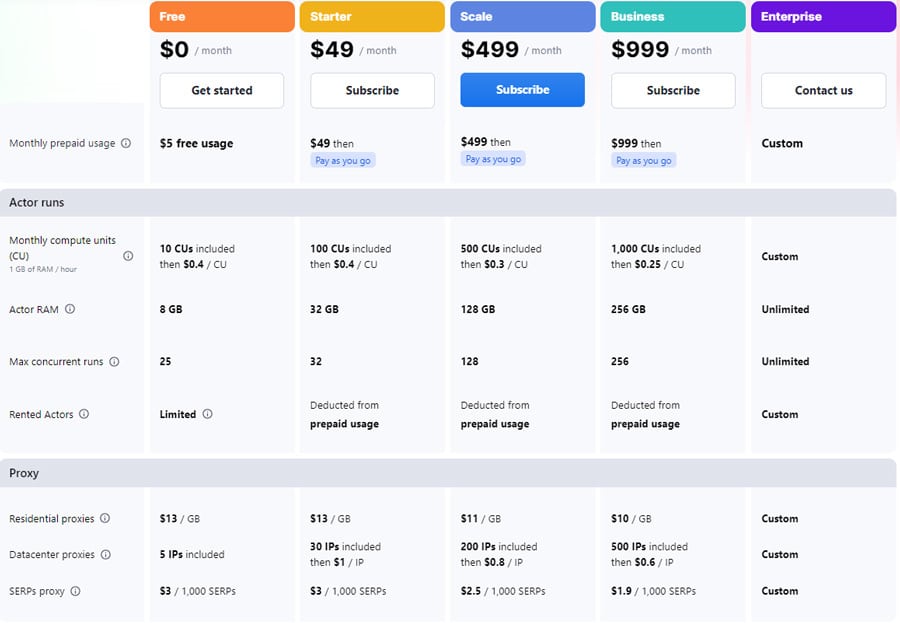
La figure suivante illustre les coûts de service mensuels d'Apify. Apify offre également une réduction de 10% pour le plan annuel. Pour plus d'informations, visitez le site Prix d'Apify.
4.1.3. Brightdata
Bright Data is a data collection platform that offers web scraping tools such as proxy servers, APIs, and no-code solutions. Bright Data’s Web Scraper gives users the ability to extract data from public Twitter profiles, including images, videos, tweets, hashtags, and more.
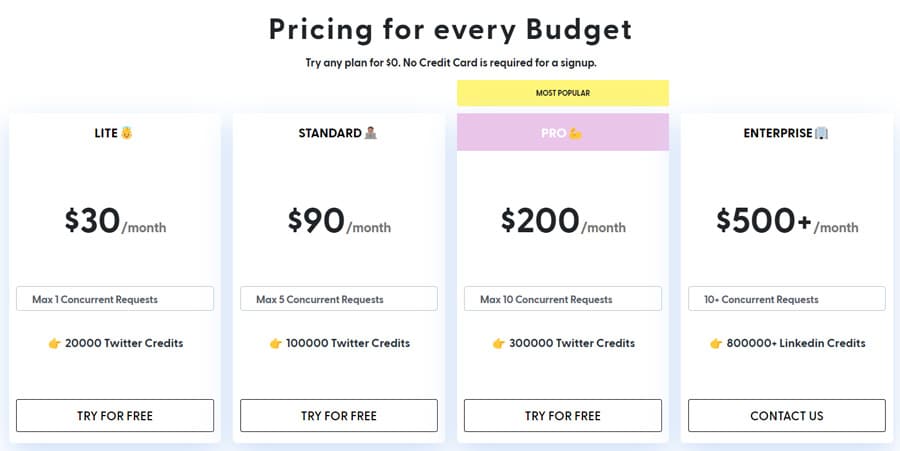
Les prix commencent avec un abonnement mensuel de 500$ pour 151000 pages chargées.. Bright Data Twitter scraper data collector est compatible avec tous les services web et fournit ses données au format Excel. Il offre également une période d'essai de 7 jours, et vous pouvez tester la plateforme avant de payer 500 dollars.
Prêt à passer à la vitesse supérieure avec votre scraper Twitter ?
4.1.4. Chien de garde
Scrapingdog est une API de scraping web qui vous aide à scraper n'importe quel site web, y compris Twitter. Elle vous permet d'extraire des tweets en utilisant des ID de tweet ou des pages publiques pour extraire des détails tels que le nombre de followers, le nombre de followers et les liens du site web.
Il vous en coûte 0,0009$ par page pour récupérer les données de Twitter. dans l'offre standard, ce qui est l'un des meilleurs rapports qualité/prix par rapport aux autres racleurs de tweets. Ils ont également fourni un essai gratuit ; vous pouvez annuler votre abonnement à tout moment et rembourser votre argent facilement. Pour plus d'informations sur la façon de récupérer des données avec Scrapingdog, vous pouvez visiter le site suivant Documentation de l'API Twitter Scraping.
4.2. Bibliothèques et paquets Python pour l'analyse de Twitter
Maintenant que vous êtes familiarisé avec l'API Twitter et les applications comme Apify, il est temps de jeter un coup d'œil sur les bibliothèques et les paquets Python pour le scraping Twitter.
4.2.1. Tweepy
Tweepy est un paquetage Python open-source qui permet aux développeurs d'accéder aux points d'extrémité de Twitter de manière fluide et transparente. Cependant, vous devez savoir que Twitter a imposé des limites sur le nombre de requêtes envoyées à l'API X/Twitter, où 900 demandes sont autorisées toutes les 15 minutes. Dans cette section, nous allons examiner les fonctionnalités de Tweepy et donner un exemple simple.
Pour commencer, installez le paquet Tweepy en utilisant la commande "pip install Tweepy" sur votre IDE Python et importez Tweepy. L'étape suivante consiste à enregistrer votre application client auprès de Twitter. Créez une nouvelle application. Une fois l'enregistrement terminé, vous recevrez un jeton de porteur.
|
1 2 |
tuyau install tweepy l'importation tweepy |
Ensuite, vous devez créer une instance "Client" pour transmettre le jeton de consommateur que vous avez obtenu de l'API Twitter.
Dans la variable de requête, nous avons spécifié un champ, une mention et un hashtag comme indiqué.
|
1 2 3 |
client = tweepy.Client(jeton_porteur='bearer_token' (jeton de porteur)) interrogation = 'query @mentions #hashtags' |
Pour rechercher les tweets des sept derniers jours, vous pouvez utiliser la fonction search_recent_tweets disponible dans Tweepy. Pour spécifier les données que vous recherchez, vous devez passer une requête de recherche.
|
1 2 |
tweets_récents = client.search_recent_tweets(interrogation=interrogation, champs_tweet=[ ;'tweet_field_1', 'tweet_field_2'], max_results=100) |
Si vous avez accès au produit de recherche universitaire, vous pouvez récupérer des tweets datant de plus de 7 jours. À partir de l'archive complète des tweets accessibles au public.
|
1 2 |
tweets = client.search_all_tweets(interrogation=interrogation, champs_tweet=[ ;'tweet_field_1', 'tweet_field_2'], max_results=100) |
Vous pouvez exporter les résultats en utilisant le code suivant.
|
1 2 3 4 5 |
pour tweet en tweets.données: imprimer(tweet.texte) si len(tweet.Annotations contextuelles) > 0: imprimer(tweet.Annotations contextuelles) |
Il existe également de nombreuses fonctions dans Tweepy capables d'effectuer diverses tâches dans des cas plus complexes et spécifiques.
4.2.2. Snscrape
Snscrape est un autre moyen d'obtenir des informations de Twitter sans passer par une API. Il vous permet de récupérer des informations de base telles que les profils d'utilisateurs, le contenu des tweets, les sources, etc. Contrairement à Tweepy, il n'y a pas de limites sur le nombre de tweets que vous pouvez récupérer ou sur les dates des tweets, et vous pouvez extraire d'anciennes données de Twitter. Snscrape n'étant pas connecté à l'API Twitter, il ne dispose pas des mêmes fonctionnalités que Tweepy. Consultez notre guide complet sur Snscrape.
Dans cette section, nous passons également en revue un exemple basique de récupération de données de Twitter à l'aide de Snscrape en Python.
Tout d'abord, vous devez installer Snscrape. Notez que vous devez avoir installé Python 3.8 ou plus pour que cela fonctionne.
|
1 2 |
tuyau install grattage |
Dans l'étape suivante, installez les bibliothèques suivantes.
|
1 2 3 |
l'importation grattage.modules.twitter comme sntwitter l'importation pandas comme pd |
Nous envoyons une requête (dans notre cas, "query") à l'aide de la fonction "TwitterSearchScraper(query).get_items" et obtenons des éléments de la recherche tout comme les résultats de la barre de recherche Twitter.
|
1 2 3 4 5 6 |
interrogation = "requête" pour tweet en sntwitter.TwitterSearchScraper(interrogation).get_items(): imprimer(vars(tweet)) pause |
D'autres méthodes peuvent être utilisées pour extraire des données de Twitter, telles que : TwitterSearchScraper, TwitterUserScraper, TwitterProfileScraper, TwitterHashtagScraper, TwitterTweetScraperMode, TwitterTweetScraper, TwitterListPostsScraper, TwitterTrendsScraper.
Techniques avancées de scraping et défis
Lorsque les méthodes de scraping de base atteignent leurs limites face aux défenses sophistiquées de Twitter, des techniques avancées deviennent indispensables. L'interface moderne de Twitter s'appuie fortement sur le rendu JavaScript et met en œuvre plusieurs couches de détection des robots, ce qui rend les requêtes HTTP traditionnelles insuffisantes pour une collecte de données fiable.
Gestion du contenu dynamique avec les navigateurs sans tête
La timeline de Twitter se charge dynamiquement via JavaScript, ce qui signifie que le contenu que vous voyez n'est pas présent dans la réponse HTML initiale. Les navigateurs sans tête simulent les interactions réelles de l'utilisateur, rendent JavaScript et gèrent le chargement dynamique du contenu.
Playwright vs Selenium: Playwright offre de meilleures performances et un traitement plus fiable des applications web modernes, tandis que Selenium reste le choix établi avec un soutien important de la communauté.
Voici un exemple pratique utilisant Playwright pour récupérer des tweets chargés dynamiquement :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
l'importation asyncio de dramaturge.async_api l'importation async_playwright l'importation json asynchrone déf. scrape_twitter_profile(Nom d'utilisateur): asynchrone avec async_playwright() comme p: # Lancer un navigateur sans tête navigateur = attendre p.chrome.lancement(sans tête=Vrai) contexte = attendre navigateur.nouveau_contexte( user_agent="Mozilla/5.0 (Windows NT 10.0 ; Win64 ; x64) AppleWebKit/537.36" ) page = attendre contexte.nouvelle_page() essayer: # Naviguer vers le profil attendre page.goto(f"https://twitter.com/{nom d'utilisateur}") # Attendre le chargement des tweets attendre page.attendre_le_sélecteur('[data-testid="tweet"]', délai d'attente=10000) # Défilez pour charger d'autres tweets pour i en gamme(3): attendre page.évaluer("window.scrollTo(0, document.body.scrollHeight)") attendre page.wait_for_timeout(2000) # Extraire les données du tweet tweets = attendre page.évaluer(""" () => { const tweetElements = document.querySelectorAll('[data-testid="tweet"]'); return Array.from(tweetElements).map(tweet => { const textElement = tweet.querySelector('[data-testid="tweetText"]'); const timeElement = tweet.querySelector('time') ; return { text : textElement ? textElement.innerText : '', timestamp : timeElement ? timeElement.getAttribute('datetime') : '', url : window.location.href }; }); } """) retour tweets sauf Exception comme e: imprimer(f"Erreur dans le scraping de {nom d'utilisateur} : {e}") retour [ ;] enfin: attendre navigateur.fermer() # Utilisation tweets = asyncio.courir(scrape_twitter_profile("elonmusk")) imprimer(json.décharges(tweets[ ;:3], indentation=2)) |
Principaux avantages des navigateurs sans tête comprennent la gestion du rendu JavaScript, la gestion automatique des cookies et des sessions, et le contournement de la détection de base des robots grâce à des empreintes digitales réalistes du navigateur.
Considérations sur les ressources: Les navigateurs sans tête consomment beaucoup plus de mémoire et d'unité centrale que les simples requêtes HTTP. Pour les opérations à grande échelle, envisagez d'exécuter plusieurs instances de navigateur sur différents serveurs ou d'utiliser des pools de navigateurs.
Contourner les mesures anti-scraping
Twitter utilise un système sophistiqué de détection des robots qui va au-delà d'une simple limitation du débit. Comprendre ces mesures permet d'élaborer des contre-mesures efficaces.
Techniques courantes de lutte contre le piratage
Limitation du taux: Twitter monitors request frequency per IP address, implementing both short-term (requests per minute) and long-term (daily quotas) limits. Learn more in Web Scraping Rate Limiting: The Fix.
Blocage de l'IP: Les adresses IP suspectes sont bloquées temporairement ou définitivement. Les adresses IP des centres de données font l'objet d'un examen plus approfondi que les adresses résidentielles.
Les défis du CAPTCHA: Présentation automatisée des CAPTCHA lorsqu'un comportement de type bot est détecté. Les CAPTCHA modernes utilisent l'analyse comportementale au-delà de la simple reconnaissance d'image.
Empreintes digitales des navigateurs: Analyse des caractéristiques du navigateur, y compris l'agent utilisateur, la résolution de l'écran, les plugins installés et les modèles d'exécution JavaScript.
Des contre-mesures efficaces
Stratégie de rotation des procurations: L'utilisation de services tels que RapidSeedbox permet d'accéder à des pools d'adresses IP résidentielles qui apparaissent comme du trafic d'utilisateurs légitimes. Les proxys résidentiels de leur réseau de plus de 6,9 millions d'adresses IP réduisent considérablement la détection par rapport aux proxys des centres de données.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
l'importation aléatoire l'importation temps de itertools l'importation cycle # Proxy rotation setup liste_proxy = [ ; "http://user:[email protected]:8080" ] cycle_proxy = cycle(liste_proxy) déf. get_next_proxy(): retour suivant(cycle_proxy) # Mettre en œuvre dans votre scraper asynchrone déf. scrape_with_rotation(): pour i en gamme(10): proxys. = get_next_proxy() # Configurez votre navigateur/session avec un nouveau proxy # Effectuer une demande de grattage # Ajouter un délai aléatoire attendre asyncio.dormir(aléatoire.uniforme(5, 15)) |
Rotation de l'agent utilisateur: Varier les signatures des navigateurs pour éviter la détection de modèles. Utiliser de véritables chaînes d'agents utilisateurs provenant de différents navigateurs et systèmes d'exploitation.
|
1 2 3 4 5 6 7 8 9 |
USER_AGENTS = [ ; "Mozilla/5.0 (Windows NT 10.0 ; Win64 ; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36", "Mozilla/5.0 (Macintosh ; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36", "Mozilla/5.0 (Windows NT 10.0 ; Win64 ; x64 ; rv:121.0) Gecko/20100101 Firefox/121.0" ] déf. get_random_user_agent(): retour aléatoire.choix(USER_AGENTS) |
Modèles de comportement: Imiter le comportement de navigation humain avec des délais variables, des modèles de défilement réalistes et des activités occasionnelles non liées à la navigation.
Gestion des sessions: Maintenez des sessions cohérentes en gérant correctement les cookies et évitez de créer trop de nouvelles sessions à partir de la même adresse IP.
Détection avancée Évitement
Calendrier des demandes: Mettre en place un backoff exponentiel lorsque l'on rencontre des limites de débit. Commencez par des délais plus longs et réduisez-les progressivement en fonction des taux de réussite.
Cohérence de la géolocalisation: Lorsque vous utilisez des serveurs mandataires, veillez à ce que vos demandes restent cohérentes d'un point de vue géographique. Ne passez pas rapidement d'un pays à l'autre.
Gestion des empreintes digitales du navigateur: Utilisez des outils tels que undetected-chromedriver ou des plugins furtifs pour réduire l'efficacité de l'empreinte du navigateur.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
de sélénium l'importation pilote web de selenium_stealth l'importation furtivité déf. créer_un_conducteur_stealth(): options = pilote web.ChromeOptions() options.add_argument("--sans tête") options.add_argument("--no-sandbox") options.add_argument("--disable-dev-shm-usage") conducteur = pilote web.Chrome(options=options) furtivité(conducteur, langues=[ ;"en-US", "fr"], vendeur="Google Inc., plateforme="Win32, webgl_vendor="Intel Inc., moteur de rendu="Moteur Intel Iris OpenGL", fix_hairline=Vrai, ) retour conducteur |
Gestion des erreurs: Mettre en place un traitement des erreurs qui permette de faire la distinction entre les blocages temporaires, les interdictions permanentes et les problèmes techniques.
La combinaison de proxys résidentiels provenant de services tels que RapidSeedbox, de techniques de furtivité du navigateur et de modèles comportementaux réalistes crée une base solide pour la collecte de données Twitter à grande échelle tout en minimisant les risques de détection.
N'oubliez pas que les mesures anti-bots de Twitter ne cessent d'évoluer, de sorte qu'un scraping réussi nécessite une adaptation permanente de ces techniques en fonction du comportement actuel de la plateforme.
FAQ
Le scraping de Twitter se situe dans une zone grise juridique. Si les conditions d'utilisation de Twitter interdisent la collecte automatisée de données, l'utilisation de données accessibles au public n'est pas automatiquement illégale.
Les risques juridiques sont les suivants :
1. Violation des droits d'auteur sur le contenu des utilisateurs
2. Violations de la CFAA dans certaines juridictions
3. Questions de conformité au GDPR concernant les données à caractère personnel
Une approche plus sûre: Utilisez l'API officielle de Twitter dans la mesure du possible, consultez un conseiller juridique pour les projets de grande envergure et concentrez-vous sur les données accessibles au public à des fins de recherche légitimes.
Non, mais le codage permet d'obtenir de meilleurs résultats.
Options sans code: Les outils d'automatisation des navigateurs et les outils de création de flux de travail visuels fonctionnent pour le scraping de base, mais sont limités en termes de vitesse et de flexibilité.
Solutions de codage: Python avec Selenium ou des bibliothèques spécialisées offre un meilleur contrôle, une meilleure gestion anti-bot et des taux de réussite plus élevés.
Meilleure approche: Commencez par des outils sans code pour tester vos besoins, puis apprenez les bases du script Python pour une collecte de données sérieuse.
L'API gratuite de Twitter est soumise à de sévères restrictions :
1. Limites de taux: Quotas de demandes mensuelles très bas
2. Données historiques: Limité aux tweets récents (généralement la semaine dernière)
3. Fonctionnalités: Pas d'analyse avancée ni de mesures d'engagement
4. Accès: Nécessite l'approbation de la demande
La plupart des recherches et des utilisations professionnelles dépassent les limites du niveau gratuit, ce qui nécessite des plans payants ou des méthodes alternatives.
Les données historiques de Twitter nécessitent des outils spécialisés, car la navigation normale n'affiche que le contenu récent.
Le meilleur outil: Snscrape - Bibliothèque Python permettant d'accéder aux tweets des années précédentes avec filtrage par plage de dates.
Autres options:
1. Bibliothèque TwitterScraper
2. Academic Research API (accès institutionnel requis)
3. Services de données historiques de tiers
Conseil: Le scraping historique est plus lent et nécessite une limitation prudente du débit pour éviter les blocages.
Pratiques essentielles:
1. Limitation du taux: 1-2 secondes entre les demandes au minimum
2. Respecter le fichier robots.txt: Suivre les lignes directrices de la plateforme
3. Minimisation des données: Ne collecter que les informations nécessaires
4. Délais appropriés: Utiliser la rotation d'IP et les proxys résidentiels
5. Gestion des erreurs: Arrêter le scraping en cas de blocage ou de limitation du débit
Principe clé: Essayez toujours d'abord les API officielles, puis faites du scrape de manière responsable en respectant l'infrastructure de Twitter et la vie privée des utilisateurs.
Conclusion
Twitter est une source intéressante d'informations sociologiques sur le web. En tirant parti des informations extraites de Twitter, vous pouvez adapter vos plans pour stimuler vos ventes et améliorer vos stratégies de marketing. Dans cet article, nous avons présenté une vue d'ensemble approfondie des différents aspects et méthodes de Twitter scraping pour extraire des données qui peuvent être utiles aux entreprises ou à la recherche.
En résumé, compte tenu des nouvelles limitations imposées à l'API Twitter v2 et des coûts élevés, le choix du meilleur scraper s'avère difficile. Vous pouvez bénéficier de fonctionnalités plus avancées sur l'API Twitter ou d'applications tierces et de bibliothèques Python (Tweepy) qui sont directement connectées à l'API Twitter.
Mais le nombre de requêtes que vous pouvez effectuer est strictement limité. En revanche, si vous cherchez à récupérer des données accessibles au public et que les fonctionnalités de base répondent à vos besoins, des options telles que la bibliothèque Python Snscrape peuvent constituer un excellent choix.
0Commentaires