Com mais de 666 milhões de utilizadores activos, o antigo Twitter, ou a nova marca XO Twitter é uma das mais populares plataformas de redes sociais e uma valiosa fonte de informação para empresas, investigadores e indivíduos. No entanto, a extração e filtragem manual de dados do vasto domínio de dados do Twitter é esmagadora e não funcional.

O scraping do Twitter envolve a utilização de software ou scripts para recolher dados da plataforma. Pode analisar estes dados para obter informações valiosas sobre tópicos de tendências e hashtags, conversas, interacções que ocorrem na plataforma e comportamento dos utilizadores.
As informações recolhidas podem ser meticulosamente analisadas para vários fins, tais como análise de sentimentos, estudos de mercado e monitorização de redes sociais. Este artigo abordará os diferentes aspectos da raspagem Dados do Twitter utilizando os métodos existentes, desde o scripting ao software sem código, custos associados e termos éticos e de legalidade.
Isenção de responsabilidade: Este material foi desenvolvido estritamente para fins informativos. Não constitui uma aprovação de quaisquer atividades (incluindo atividades ilegais), produtos ou serviços. O usuário é o único responsável pelo cumprimento das leis aplicáveis, incluindo as leis de propriedade intelectual, quando utiliza os nossos serviços ou se baseia em qualquer informação aqui contida. Não aceitamos qualquer responsabilidade por danos resultantes da utilização dos nossos serviços ou das informações aqui contidas, seja de que forma for, exceto quando explicitamente exigido por lei.
Índice
Que tipos de dados podem ser extraídos do Twitter?
É possível extrair diferentes tipos de dados do Twitter. Eis três tipos de dados principais para a extração de dados do Twitter:
- Tweets: É possível capturar dados específicos de tweets filtrados com base em perfis, como gostos, respostas, retweets e URLs especificados.
- Perfis de utilizador: Tudo o que estiver num perfil de utilizador público é colecionável, como a biografia do utilizador, a descrição do perfil, o número de tweets, os retweets, o número de seguidores/seguidos e a imagem de perfil.
- Palavras-chave/Hashtags: Pode recolher tweets que contenham determinadas palavras-chave, hashtags ou a sua combinação. Também é possível refinar a pesquisa pelo número de gostos ou pela procura de datas e horas específicas.
Termos de utilização legais e éticos
Ao mergulhar no mundo da extração de dados, é essencial compreender os limites legais e éticos envolvidos.
De acordo com o Termos e regulamentos do Twitter (Contrato e Política de Desenvolvedor), a raspagem de dados sem permissão explícita é proibida e declarada pela política do Twitter: "É expressamente proibido fazer scraping dos Serviços sem o consentimento prévio do Twitter.
Qualquer utilização abusiva da API do Twitter para estes fins será objeto de medidas coercivas, que podem incluir a suspensão e o cancelamento do acesso.
Guia geral para a recolha de dados do Twitter
Após uma breve introdução à recolha de dados do Twitter, está na altura de explorar o processo de recolha de dados do Twitter. Assim, compilámos para si um guia simples e completo sobre a recolha de dados do Twitter. Por favor, siga os passos abaixo:
- Em primeiro lugar, é necessário ter as ferramentas de raspagem correctas. Há muitas opções por onde escolher. Por isso, determine a opção que melhor se adapta ao seu orçamento e às suas preferências.
- Descarregue e instale a ferramenta de recolha de dados no seu sistema.
- Certificar-se de que existe muito espaço de arrumação disponível no seu dispositivo e que dispõe de uma ligação fiável à Internet.
- Após a instalação, inicie sessão utilizando os detalhes da sua conta do Twitter.
- Ajustar os parâmetros para extrair dados do Twitter é um passo importante que lhe permite extrair dados com base em palavras-chave, hashtags, datas e horas, localizações, URLs, etc.
- Após a execução da ferramenta de extração, será deixada para trás uma grande quantidade de dados. Pode exportar os dados para diferentes formatos de ficheiro (xlsx, CSV, JSON, etc.).
- Na etapa final, deve analisar os dados exportados para obter informações sobre o seu tópico de interesse.
Ferramentas e métodos de recolha de dados do Twitter
Analisámos algumas ferramentas de raspagem disponíveis na Internet, desde a ferramenta oficial Raspador do Twitter a serviços de terceiros e até a bibliotecas Python de código aberto, e listamo-las abaixo.
4.1. Raspadores do Twitter baseados em API
O primeiro método que vamos analisar são os scrapers do Twitter baseados em API, que incluem o Twitter API V2, Apify, Brightdata e Scrapingdog.
4.1.1. API do Twitter V2
A API do Twitter v2 é a versão mais recente da API do Twitter, a API oficial e uma das mais utilizadas pelos programadores que criam aplicações com interação social ou pelos investigadores/indivíduos que recolhem dados para os seus fins específicos. A utilização de novas APIs permite a monitorização e análise sem esforço de conversas em direto nas redes sociais.
Recentemente, o Twitter adicionou algumas novas funcionalidades, tais como pontos de extremidade, opções de carga útil para publicações de tweets, conjuntos de identificadores de conversação e anotações. Estas alterações são bastante impressionantes. No entanto, a nova estrutura de preços levantou sérias preocupações aos programadores e às aplicações de terceiros. Com a nova estrutura de preços, o acesso aos serviços diminuiu drasticamente e os preços aumentaram drasticamente.
Os planos de preços da API v2 do Twitter/X têm três níveis: Gratuito, Básicoe Empresa.
- No escalão gratuito, os programadores podem publicar até 1500 tweets por mêsconcebido para utilização apenas para escrita e para testar a API do Twitter.
- O escalão básico custa $100 por mês e permite que os programadores publiquem até 3000 tweets por mês ao nível do utilizador e 50.000 tweets (com um limite de leitura de 10.000) ao nível da aplicação.
- O pneu Enterprise inclui funcionalidades mais avançadas concebidas para empresas. No entanto, o plano empresarial cobrará aos programadores/empresas um preço exorbitante de quase 42000$ por mês.
4.1.2. Apify
Através do Twitter Scraper da Apify, pode extrair informações de dados do Twitter disponíveis publicamente, como hashtags, tópicos, respostas, imagens e muito mais. As alterações recentes ao Twitter impuseram novos limites à visualização e recolha de tweets nesta plataforma, uma vez que os utilizadores só podem extrair informações públicas até 100 tweets por perfil. Este scraper não pode extrair os tweets mais recentes, mas pode recuperar os mais curtidos. Os dados extraídos podem ser acedidos nos formatos HTML, JSON, Excel e CSV.
A figura seguinte ilustra os custos mensais do serviço da Apify. Oferece ainda um desconto de 10% para o plano anual. Para mais informações, visite Preços da Apify.
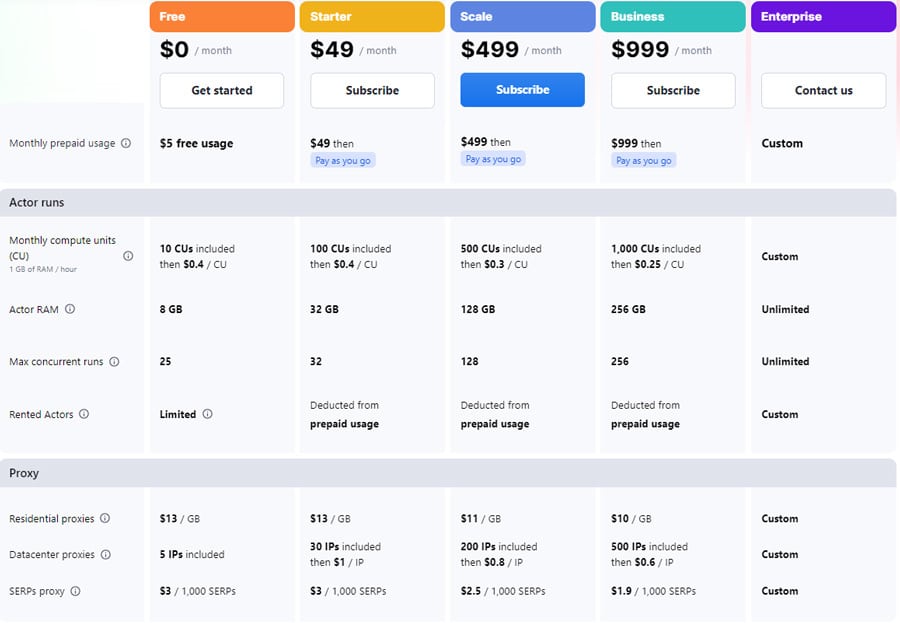
4.1.3. Brightdata
Bright Data is a data collection platform that offers web scraping tools such as proxy servers, APIs, and no-code solutions. Bright Data’s Web Scraper gives users the ability to extract data from public Twitter profiles, including images, videos, tweets, hashtags, and more.
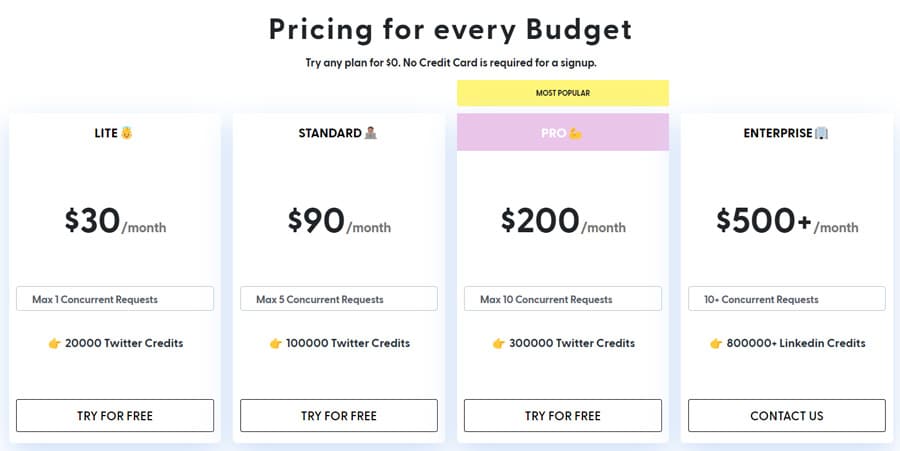
Os preços começam com um 500$ mensal para 151000 carregamentos de páginas. O coletor de dados Bright Data Twitter scraper é compatível com todos os serviços Web e produz os seus dados em formato Excel. Também oferece um teste de 7 dias, e pode testar a plataforma antes de pagar 500 dólares.
Pronto para levar o seu raspador do Twitter para o nível seguinte?
4.1.4. Cão de rasto
Scrapingdog é uma API de raspagem da Web que o ajuda a raspar qualquer sítio Web, incluindo o Twitter. Permite-lhe extrair tweets utilizando IDs de tweets ou páginas públicas para extrair detalhes como o número de seguidores, o número de seguidores e ligações de sítios Web.
Custa-lhe 0,0009$ por página para fazer scraping do Twitter no plano padrão, que está entre o melhor valor em relação ao preço em comparação com os outros raspadores do Twitter de topo. Também disponibilizaram um teste gratuito; pode cancelar a sua subscrição em qualquer altura e reembolsar o seu dinheiro facilmente. Para mais informações sobre como extrair dados com o Scrapingdog, pode visitar Documentação da API de raspagem do Twitter.
4.2. Bibliotecas e pacotes Python para raspar o Twitter
Agora que está familiarizado com a API do Twitter e com aplicações como a Apify, está na altura de dar uma vista de olhos às bibliotecas e pacotes Python para a recolha de dados do Twitter.
4.2.1. Tweepy
O Tweepy é um pacote Python de código aberto que permite que os desenvolvedores acessem os pontos de extremidade do Twitter de forma suave e transparente. No entanto, você deve estar ciente de que o Twitter impôs limitações no número de solicitações enviadas para a API X/Twitter, onde São permitidos 900 pedidos a cada 15 minutos. Nesta secção, pretendemos dar uma vista de olhos à funcionalidade do Tweepy e apresentar um exemplo simples.
Para começar, instale o pacote Tweepy usando o comando "pip install Tweepy" no seu IDE Python e, em seguida, importe o Tweepy também. O próximo passo é registar a sua aplicação cliente no Twitter. Crie uma nova aplicação. Uma vez concluído, receberá um token de portador.
|
1 2 |
tubagem install tweepy importação tweepy |
Em seguida, deve criar uma instância "Client" para passar o token de portador do consumidor que obteve da API do Twitter.
Na variável de consulta, especificámos um campo, uma menção e uma hashtag, conforme demonstrado.
|
1 2 3 |
cliente = tweepy.Cliente(ficha_do_portador="bearer_token) consulta = "consultar @menções #hashtags |
Para pesquisar tweets dos últimos sete dias, você pode usar o recurso search_recent_tweets disponível no Tweepy. Para especificar os dados que está a procurar, precisa de passar uma consulta de pesquisa.
|
1 2 |
tweets_recentes = cliente.pesquisar_tweets_recentes(consulta=consulta, campos_tweets=['tweet_field_1', 'campo_do_tweeter_2'], max_results=100) |
Se tiver acesso à faixa de produtos de investigação académica, pode recuperar tweets com mais de 7 dias. Do arquivo completo de tweets disponíveis publicamente.
|
1 2 |
tweets = cliente.pesquisar_todos_tweets(consulta=consulta, campos_tweets=['tweet_field_1', 'campo_do_tweeter_2'], max_results=100) |
É possível exportar os resultados utilizando o seguinte código.
|
1 2 3 4 5 |
para tweet em tweets.data: imprimir(tweet.texto) se len(tweet.anotações_de_contexto) > 0: imprimir(tweet.anotações_de_contexto) |
Existem também muitas funções no Tweepy capazes de realizar várias tarefas em casos mais complexos e específicos.
4.2.2. Snscrape
Outra forma de obter informações do Twitter sem depender de uma API é através do Snscrape. Permite obter informações básicas como perfis de utilizadores, conteúdo de tweets, fontes, etc. Ao contrário do Tweepy, não há limites para o número de tweets que pode extrair ou para as datas dos tweets, e pode extrair dados antigos do Twitter. Como o Snscrape não está conectado à API do Twitter, ele não tem funcionalidade no nível do Tweepy. Confira nosso guia completo para Snscrape.
Nesta secção, também analisamos um exemplo básico de recolha de alguns dados do Twitter utilizando o Snscrape em Python.
Primeiro, você deve instalar o Snscrape. Observe que é necessário ter o Python 3.8 ou superior instalado para que ele funcione.
|
1 2 |
tubagem install snscrape |
Na etapa seguinte, instale as seguintes bibliotecas.
|
1 2 3 |
importação snscrape.módulos.twitter como sntwitter importação pandas como pd |
Enviamos uma consulta (no nosso caso, "consulta") utilizando a função "TwitterSearchScraper(query).get_items" e obtemos elementos da pesquisa tal como os resultados da barra de pesquisa do Twitter.
|
1 2 3 4 5 6 |
consulta = "consulta" para tweet em sntwitter.TwitterSearchScraper(consulta).get_items(): imprimir(vars(tweet)) pausa |
Existem outros métodos que podem ser utilizados para extrair dados do Twitter, tais como: TwitterSearchScraper, TwitterUserScraper, TwitterProfileScraper, TwitterHashtagScraper, TwitterTweetScraperMode, TwitterTweetScraper, TwitterListPostsScraper, TwitterTrendsScraper.
Técnicas avançadas de raspagem e desafios
Quando os métodos básicos de recolha de dados atingem os seus limites com as sofisticadas defesas do Twitter, as técnicas avançadas tornam-se essenciais. A interface moderna do Twitter depende muito da renderização em JavaScript e implementa várias camadas de deteção de bots, tornando os pedidos HTTP tradicionais insuficientes para uma recolha de dados fiável.
Manipulação de conteúdo dinâmico com navegadores sem cabeça
A linha do tempo do Twitter é carregada dinamicamente por meio de JavaScript, o que significa que o conteúdo que você vê não está presente na resposta HTML inicial. Os navegadores sem cabeça simulam interações reais do utilizador, processando JavaScript e lidando com o carregamento de conteúdo dinâmico.
Playwright vs Selenium: O Playwright oferece um melhor desempenho e um tratamento mais fiável das aplicações Web modernas, enquanto o Selenium continua a ser a escolha estabelecida com um vasto apoio da comunidade.
Eis um exemplo prático que utiliza o Playwright para recolher tweets carregados dinamicamente:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
importação assíncrono de dramaturgo.async_api importação reprodução assíncrona importação json assíncrono defesa recolher_perfil_do_twitter(nome de utilizador): assíncrono com reprodução assíncrona() como p: # Iniciar o navegador sem cabeça navegador = aguardar p.crómio.lançamento(sem cabeça=Verdadeiro) contexto = aguardar navegador.novo_contexto( agente_do_utilizador="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36" ) página = aguardar contexto.nova_página() tentar: # Navegar para o perfil aguardar página.goto(f"https://twitter.com/{nome de utilizador}") # Aguardar que os tweets sejam carregados aguardar página.esperar_por_selector('[data-testid="tweet"]', tempo limite=10000) # Desloque-se para ver mais tweets para i em gama(3): aguardar página.avaliar("window.scrollTo(0, document.body.scrollHeight)") aguardar página.esperar_por_timeout(2000) # Extrair dados do tweet tweets = aguardar página.avaliar(""" () => { const tweetElements = document.querySelectorAll('[data-testid="tweet"]'); return Array.from(tweetElements).map(tweet => { const textElement = tweet.querySelector('[data-testid="tweetText"]'); const timeElement = tweet.querySelector('time'); voltar { text: textElement ? textElement.innerText : '', timestamp: timeElement ? timeElement.getAttribute('datetime') : '', url: window.location.href }; }); } """) retorno tweets exceto Exceção como e: imprimir(f"Erro ao raspar {nome de utilizador}: {e}") retorno [] finalmente: aguardar navegador.fechar() # Utilização tweets = assíncrono.run(recolher_perfil_do_twitter("elonmusk")) imprimir(json.lixeiras(tweets[:3], travessão=2)) |
Principais vantagens dos navegadores sem cabeça incluem o tratamento da renderização de JavaScript, a gestão automática de cookies e sessões e o contornar da deteção básica de bots através de impressões digitais realistas do navegador.
Considerações sobre os recursos: Os navegadores sem cabeça consomem significativamente mais memória e CPU em comparação com pedidos HTTP simples. Para operações em grande escala, considere executar várias instâncias de navegador em diferentes servidores ou usar pools de navegador.
Contornar medidas anti-scraping
O Twitter emprega uma sofisticada deteção de bots que vai além da simples limitação de taxa. Entender essas medidas ajuda a desenvolver contramedidas eficazes.
Técnicas comuns de anti-scraping
Limitação da taxa: Twitter monitors request frequency per IP address, implementing both short-term (requests per minute) and long-term (daily quotas) limits. Learn more in Web Scraping Rate Limiting: The Fix.
Bloqueio de IP: Os endereços IP suspeitos são bloqueados temporária ou permanentemente. Os IPs de centros de dados são mais controlados do que os endereços residenciais.
Desafios do CAPTCHA: Apresentação automatizada de CAPTCHA quando é detectado um comportamento do tipo bot. Os CAPTCHAs modernos utilizam a análise comportamental para além do simples reconhecimento de imagem.
Impressão digital do navegador: Análise das caraterísticas do browser, incluindo o agente do utilizador, a resolução do ecrã, os plugins instalados e os padrões de execução do JavaScript.
Contramedidas eficazes
Estratégia de rotação de procuradores: A utilização de serviços como o RapidSeedbox permite o acesso a pools de IP residenciais que aparecem como tráfego de utilizador legítimo. Os proxies residenciais da sua rede de mais de 6,9 milhões de IPs reduzem significativamente a deteção em comparação com os proxies de centros de dados.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
importação aleatório importação tempo de itertools importação ciclo # Configuração da rotação do proxy lista_de_proxy = [ "http://user:[email protected]:8080" ] ciclo_proxy = ciclo(lista_de_proxy) defesa get_next_proxy(): retorno seguinte(ciclo_proxy) # Implementar no seu raspador assíncrono defesa raspagem_com_rotação(): para i em gama(10): procurador = get_next_proxy() # Configurar o seu browser/sessão com o novo proxy # Efetuar pedido de raspagem # Adicionar atraso aleatório aguardar assíncrono.dormir(aleatório.uniforme(5, 15)) |
Rotação do agente do utilizador: Variar as assinaturas dos navegadores para evitar a deteção de padrões. Utilizar cadeias de agentes de utilizador reais de diferentes navegadores e sistemas operativos.
|
1 2 3 4 5 6 7 8 9 |
AGENTES_DO_UTILIZADOR = [ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, como Gecko) Chrome/120.0.0.0 Safari/537.36", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, como Gecko) Chrome/120.0.0.0 Safari/537.36", "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:121.0) Gecko/20100101 Firefox/121.0" ] defesa get_random_user_agent(): retorno aleatório.escolha(AGENTES_DO_UTILIZADOR) |
Padrões de comportamento: Imitar o comportamento humano de navegação com atrasos variáveis, padrões de deslocação realistas e actividades ocasionais de não raspagem.
Gestão de sessões: Mantenha sessões consistentes com o tratamento correto dos cookies e evite criar demasiadas sessões novas a partir do mesmo IP.
Evitar a deteção avançada
Tempo do pedido: Implemente o backoff exponencial quando se deparar com limites de taxa. Comece com atrasos maiores e reduza-os gradualmente com base nas taxas de sucesso.
Coerência da geolocalização: Quando utilizar proxies, certifique-se de que os seus pedidos mantêm a coerência geográfica. Não salte rapidamente de um país para outro.
Gestão da impressão digital do navegador: Utilize ferramentas como o undetected-chromedriver ou plugins furtivos para reduzir a eficácia da impressão digital do navegador.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
de selénio importação piloto web de selénio_silêncio importação furtivo defesa criar_condutor_silencioso(): opções = piloto web.ChromeOpções() opções.add_argumento("-- sem cabeça") opções.add_argumento("--no-sandbox") opções.add_argumento("--disable-dev-shm-usage") condutor = piloto web.Cromado(opções=opções) furtivo(condutor, línguas=["en-US", "en"], vendedor="Google Inc.", plataforma="Win32", fornecedor_webgl="Intel Inc.", renderizador="Motor Intel Iris OpenGL", fix_hairline=Verdadeiro, ) retorno condutor |
Tratamento de erros: Implementar um tratamento de erros simples que permita distinguir entre bloqueios temporários, proibições permanentes e problemas técnicos.
A combinação de proxies residenciais de serviços como o RapidSeedbox, técnicas adequadas de ocultação do navegador e padrões de comportamento realistas cria uma base robusta para a recolha de dados do Twitter em grande escala, minimizando os riscos de deteção.
Lembre-se de que as medidas anti-bot do Twitter continuam a evoluir, pelo que uma recolha de dados bem sucedida requer uma adaptação contínua destas técnicas com base no comportamento atual da plataforma.
Perguntas frequentes
A recolha de dados do Twitter existe numa zona cinzenta do ponto de vista jurídico. Embora os Termos de Serviço do Twitter proíbam a recolha automática de dados, a recolha de dados disponíveis publicamente não é automaticamente ilegal.
Os riscos jurídicos incluem:
1. Violação dos direitos de autor sobre o conteúdo do utilizador
2. Violações da CFAA em algumas jurisdições
3. Questões de conformidade com o RGPD relativas a dados pessoais
Abordagem mais segura: Utilize a API oficial do Twitter sempre que possível, consulte um consultor jurídico para grandes projectos e concentre-se em dados publicamente disponíveis para fins de investigação legítimos.
Não, mas a codificação permite obter melhores resultados.
Opções sem código: As ferramentas de automatização do navegador e os criadores de fluxos de trabalho visuais funcionam para a recolha de dados básica, mas são limitados em termos de velocidade e flexibilidade.
Soluções de codificação: Python com Selenium ou bibliotecas especializadas oferece maior controlo, melhor tratamento anti-bot e taxas de sucesso mais elevadas.
Melhor abordagem: Comece com ferramentas sem código para testar as suas necessidades e, em seguida, aprenda a criar scripts Python básicos para uma recolha de dados séria.
O nível gratuito da API do Twitter tem restrições severas:
1. Limites de taxas: Quotas de pedidos mensais muito baixas
2. Dados históricos: Limitado a tweets recentes (normalmente da semana passada)
3. Recursos: Sem análises avançadas ou métricas de envolvimento
4. Acesso: Requer aprovação da candidatura
A maioria dos casos de utilização empresarial e de investigação excede os limites dos níveis gratuitos, tornando necessários planos pagos ou métodos alternativos.
Os dados históricos do Twitter requerem ferramentas especializadas, uma vez que a navegação normal apenas mostra o conteúdo recente.
A melhor ferramenta: Snscrape - Biblioteca Python que acede a tweets de anos atrás com filtragem por intervalo de datas.
Outras opções:
1. Biblioteca TwitterScraper
2. API de investigação académica (é necessário acesso institucional)
3. Serviços de dados históricos de terceiros
Dica: A raspagem histórica é mais lenta e requer uma limitação cuidadosa da taxa para evitar bloqueios.
Práticas essenciais:
1. Limitação da taxa: 1-2 segundos entre pedidos, no mínimo
2. Respeitar o robots.txt: Seguir as diretrizes da plataforma
3. Minimização de dados: Recolher apenas as informações necessárias
4. Atrasos adequados: Utilizar rotação de IP e proxies residenciais
5. Tratamento de erros: Parar de fazer scraping se estiver bloqueado ou com taxa limitada
Princípio fundamental: Experimente sempre primeiro as APIs oficiais e, em seguida, faça scraping de forma responsável, respeitando a infraestrutura do Twitter e a privacidade dos utilizadores.
Conclusão
O Twitter é uma fonte valiosa de informações sociológicas em toda a Web. Ao tirar partido das informações extraídas do Twitter, pode adaptar os seus planos para aumentar as suas vendas e melhorar as suas estratégias de marketing. Neste artigo, apresentámos uma visão geral aprofundada dos diferentes aspectos e métodos de recolha de dados do Twitter para extrair dados que podem ser valiosos para as empresas ou para a investigação.
Em suma, de acordo com as novas limitações impostas à API v2 do Twitter, juntamente com os custos elevados, a seleção do melhor raspador seria um desafio. Pode beneficiar de funcionalidades mais avançadas na API do Twitter ou de aplicações de terceiros e bibliotecas Python (Tweepy) que estão diretamente ligadas à API do Twitter.
Mas o número de pedidos que pode efetuar é estritamente limitado. Por outro lado, se procura recolher dados publicamente disponíveis e as caraterísticas básicas satisfazem as suas necessidades, opções como a biblioteca Python Snscrape podem ser uma óptima escolha.
0Comentários