拥有超过 6.66 亿活跃用户的前 Twitter 或新品牌 XTwitter 是最流行的社交媒体平台之一,也是企业、研究人员和个人的重要信息来源。然而,从浩如烟海的 Twitter 数据中手动提取和过滤数据,既费时又费力。

Twitter 搜索包括使用软件或脚本从平台上收集数据。 通过分析这些数据,您可以深入了解流行话题和标签、对话、平台上发生的互动以及用户行为。
收集到的信息可以进行细致分析,用于情感分析、市场研究和社交媒体监测等各种目的。本文将深入探讨 刮削 使用现有方法获取 Twitter 数据(从脚本到无代码软件)、相关成本以及合法性和道德条款。
免责声明: 免责声明:本材料仅供参考。它并不构成对任何活动(包括非法活动)、产品或服务的认可。在使用我们的服务或依赖此处的任何信息时,您全权负责遵守适用的法律,包括知识产权法。对于因以任何方式使用我们的服务或此处包含的信息而造成的损害,我们不承担任何责任,除非法律明确要求。
目录
可以从 Twitter 提取哪些类型的数据?
您可以提取不同类型的 Twitter 数据。以下是 Twitter 搜刮的三种主要数据类型:
- 微博 您可以根据配置文件从过滤后的推文中捕获特定数据,如点赞、回复、转发和指定 URL。
- 用户配置文件: 公开用户配置文件中的任何内容都可以收集,例如用户的简介、配置文件描述、推文数量、转发、关注者/追随者数量以及配置文件图像。
- 关键词/标签: 您可以收集包含特定关键词、标签或其组合的推文。还可以通过点赞数或查找特定日期和时间来缩小搜索范围。
使用条款的合法性和道德性
在涉足数据挖掘领域时,必须了解其中涉及的法律和道德界限。
根据 推特条款和规定 (开发者协议和政策)的规定,未经明确许可的刮擦数据行为是 Twitter 政策所禁止的:"未经 Twitter 事先同意,明确禁止刮擦服务。
任何出于上述目的滥用 Twitter API 的行为都将受到执法处理,包括暂停和终止访问。
搜索 Twitter 的一般指南
在简要介绍了 Twitter 搜刮之后,是时候探索通过 Twitter 数据进行搜刮的过程了。因此,我们为您编制了一份简单而全面的 Twitter 搜索指南。请按照以下步骤操作:
- 首先,你需要有合适的刮削工具。有很多选择可供选择。因此,要确定哪种选择适合您的预算和喜好。
- 下载并在系统中安装刮擦工具。
- 确保有 充足的存储空间 您的设备上有可用资源,并且有可靠的网络连接。
- 安装后,使用 Twitter 帐户的详细信息登录。
- 调整从 Twitter 搜刮数据的参数是一个重要步骤,可以根据关键字、标签、日期和时间、位置、URL 等提取数据。
- 执行刮板工具后,会留下大量数据。您可以将数据导出为不同的文件格式(xlsx、CSV、JSON 等)。
- 最后一步,您应该分析导出的数据,以便深入了解您感兴趣的主题。
Twitter 搜索工具和方法
我们查看了互联网上一些可用的刮擦工具,包括官方的 Twitter 搜刮器 的第三方服务甚至开源 Python 库,并将它们列出如下。
4.1.基于 API 的 Twitter 抓取工具
我们要了解的第一种方法是基于 API 的 Twitter scrapers,其中包括 Twitter API V2、Apify、Brightdata 和 Scrapingdog。
4.1.1. 推特应用程序接口 V2
Twitter API v2 是 Twitter API 的最新版本,它是官方提供的 API,也是开发人员构建社交互动应用程序或研究人员/个人出于特定目的收集数据时最常用的 API 之一。使用新的 API 可以毫不费力地监控和分析社交网络上的实时对话。
最近,Twitter 增加了一些新功能,如端点、推文帖子的有效载荷选项、对话标识符集和注释。这些变化令人印象深刻。然而,新的定价结构引起了开发者和第三方应用程序的严重担忧。在新的定价结构下,服务访问量急剧下降,价格却大幅上涨。
Twitter/X API v2 的定价计划分为三个级别:免费、基本企业.
- 在免费层中,开发者最多可以发布 每月 1500 条推文旨在仅用于写入和测试 Twitter API。
- 基本级费用 每月 $100,允许开发人员每月发布多达 3,000 条推文 在用户层面和 50,000 条推文(阅读上限为 10,000 条) 在应用程序层面。
- 企业版包含更多专为企业设计的高级功能。不过,企业计划将向开发人员/企业收取高昂的费用,即 每月近 42000$.
4.1.2. Apify
通过 Apify 的 Twitter Scraper,您可以从公开的 Twitter 数据中提取信息,如标签、主题、回复、图片等。Twitter 最近的变化对在该平台上查看和搜刮推文设置了新的限制,因为用户在每个配置文件中最多只能提取 100 条推文的公开信息。该搜刮工具不能搜刮最新的推文,但可以检索最受用户喜欢的推文。提取的数据可以 HTML、JSON、Excel 和 CSV 格式访问。
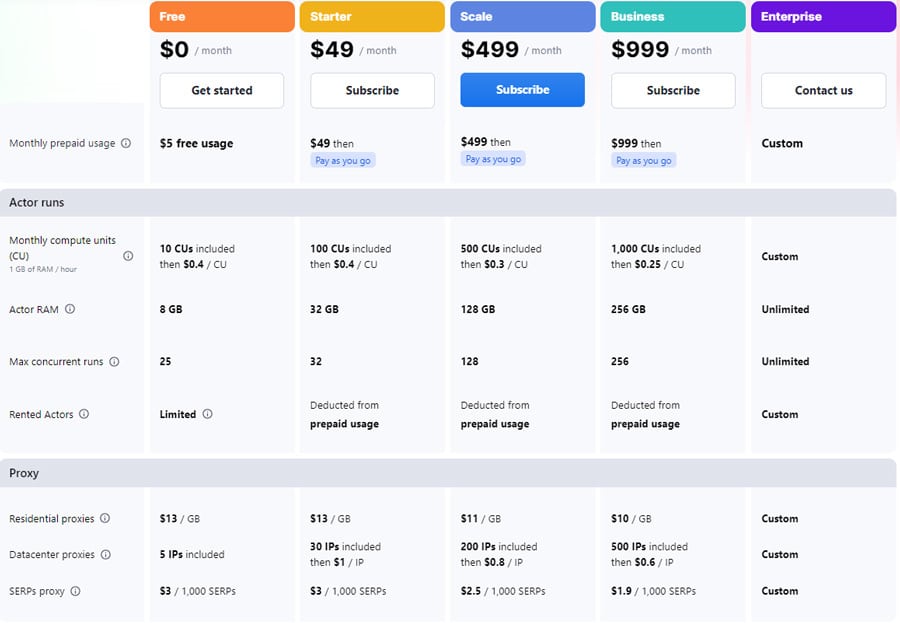
下图说明了 Apify 的每月服务费用。它还为年度计划提供 10% 折扣。更多信息,请访问 Apify 定价.
4.1.3. Brightdata
Bright Data 是一个数据收集平台,提供代理服务器、API 和无代码解决方案等网络刮擦工具。Bright Data 的 Web Scraper 使用户能够从公开 Twitter 资料中提取数据,包括图片、视频、推文、标签等。
价格从每月 500$ 开始,页面加载次数为 151000 次.Bright Data Twitter scraper 数据收集器兼容所有网络服务,并能以 Excel 格式输出数据。它还提供为期 7 天的试用版,您可以在支付 500 美元之前对平台进行测试。
准备好让你的 Twitter 搜刮器更上一层楼了吗?
4.1.4. Scrapingdog
Scrapingdog 是一个网络搜刮 API,可帮助你搜刮包括 Twitter 在内的任何网站。它允许你使用推文 ID 搜刮推文,或搜刮公共页面以提取关注者数量、关注者人数和网站链接等详细信息。
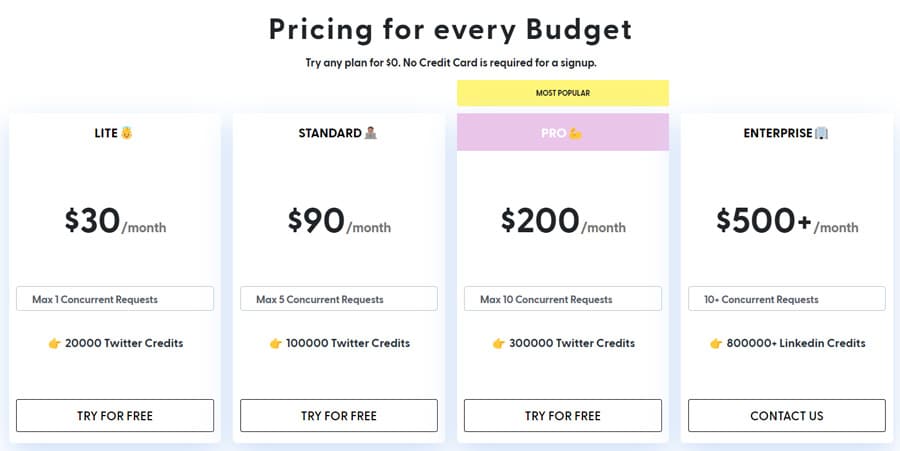
搜索 Twitter 每个页面的成本为 0.0009$ 在标准计划中,与其他顶级 Twitter 搜刮工具相比,它的性价比最高。他们还提供免费试用;你可以随时取消订阅并轻松退款。有关如何使用 Scrapingdog 搜刮数据的更多信息,请访问 Twitter Scraping API 文档.
4.2.用于搜索 Twitter 的 Python 库和软件包
现在,您已经熟悉了 Twitter API 和 Apify 等应用程序,是时候看看用于 Twitter 搜索的 Python 库和软件包了。
4.2.1. Tweepy
Tweepy 是一个开源 Python 软件包,允许开发人员流畅、透明地访问 Twitter 端点。不过,你应该知道,Twitter 已对发送到 X/Twitter API 的请求数量施加了限制。 每 15 分钟允许 900 次请求.在本节中,我们将介绍 Tweepy 的功能,并给出一个简单的示例。
首先,在 Python IDE 上使用 "pip install Tweepy "命令安装 Tweepy 软件包,然后导入 Tweepy。下一步是向 Twitter 注册客户端应用程序。创建一个新的应用程序。完成后,您将收到一个不记名令牌。
|
1 2 |
核心 安装 软绵绵 舶来品 软绵绵 |
接下来,您必须创建一个 "客户端 "实例,以传递从 Twitter API 获取的消费者承载令牌。
在查询变量中,我们指定了一个字段、一个提及和一个标签,如图所示。
|
1 2 3 |
客户 = 软绵绵.客户(持有人令牌=承载令牌) 询问 = 查询 @mentions #hashtags |
要搜索过去七天的推文,可以使用 Tweepy 提供的 search_recent_tweets 功能。要指定所要查找的数据,您需要传递一个搜索查询。
|
1 2 |
最近推文 = 客户.搜索最新推文(询问=询问, 推特字段=[;tweet_field_1', 'tweet_field_2'], max_results=100) |
如果您可以访问学术研究产品跟踪,则可以检索 7 天前的推文。从完整的公开推文档案中获取。
|
1 2 |
鸣叫 = 客户.搜索所有推文(询问=询问, 推特字段=[;tweet_field_1', 'tweet_field_2'], max_results=100) |
您可以使用以下代码导出结果。
|
1 2 3 4 5 |
对于 鸣叫 于 鸣叫.数据: 打印(鸣叫.文本) 如果 宽(鸣叫.上下文注释) > 0: 打印(鸣叫.上下文注释) |
Tweepy 中还有很多函数,能够在更复杂、更特殊的情况下执行各种任务。
4.2.2. Snscrape
另一种不依赖 API 从 Twitter 获取信息的方法是通过 Snscrape。它允许你检索用户资料、推文内容、来源等基本信息。与 Tweepy 不同的是,Snscrape 对可抓取的推文数量或日期没有限制,而且还可以提取 Twitter 的旧数据。由于 Snscrape 没有连接到 Twitter API,因此它的功能不如 Tweepy。查看我们的完整指南 Snscrape.
在本节中,我们还将回顾一个使用 Python 中的 Snscrape 从 Twitter 搜刮数据的基本示例。
首先,您应该安装 Snscrape。请注意,您必须安装 Python 3.8 或更高版本才能使用它。
|
1 2 |
核心 安装 snscrape |
下一步,安装以下库。
|
1 2 3 |
舶来品 snscrape.模块.叽叽喳喳 作为 新浪微博 舶来品 大熊猫 作为 pd |
我们使用 "TwitterSearchScraper(query).get_items "函数发送查询(本例中为 "query"),然后从搜索中获取元素,就像从 Twitter 搜索栏中获取结果一样。
|
1 2 3 4 5 6 |
询问 = "查询" 对于 鸣叫 于 新浪微博.TwitterSearchScraper(询问).get_items(): 打印(变量(鸣叫)) 断裂 |
还有其他方法可用于从 Twitter 搜刮数据,例如TwitterSearchScraper、TwitterUserScraper、TwitterProfileScraper、TwitterHashtagScraper、TwitterTweetScraperMode、TwitterTweetScraper、TwitterListPostsScraper、TwitterTrendsScraper。
高级搜索技术和挑战
当基本刮擦方法在 Twitter 复杂的防御系统面前达到极限时,高级技术就变得必不可少。Twitter 的现代界面严重依赖 JavaScript 渲染,并实现了多层僵尸检测,因此传统的 HTTP 请求无法满足可靠的数据收集要求。
使用无头浏览器处理动态内容
Twitter 的时间线是通过 JavaScript 动态加载的,也就是说,你看到的内容并不存在于最初的 HTML 响应中。无头浏览器模拟真实的用户交互,呈现 JavaScript 并处理动态内容加载。
Playwright 与 Selenium:Playwright 可为现代网络应用程序提供更好的性能和更可靠的处理能力,而 Selenium 仍是具有广泛社区支持的首选。
下面是一个使用 Playwright 抓取动态加载推文的实用示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
舶来品 异步 从 编剧.async_api 舶来品 async_playwright 舶来品 json 异步 捍卫 搜刮 Twitter 个人档案(用户名): 异步 与 async_playwright() 作为 p: # 启动无头浏览器 浏览器 = 等 p.镉.启动(破魔=正确) 背景 = 等 浏览器.新语境( user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36" ) 页码 = 等 背景.new_page() 尝试: # 导航至个人资料 等 页码.开始(f"https://twitter.com/{username}") # 等待加载推文 等 页码.等待选择器('[data-testid="tweet"]', 超时=10000) # 滚动加载更多推文 对于 i 于 范围(3): 等 页码.评估("window.scrollTo(0,document.body.scrollHeight)") 等 页码.等待超时(2000) # 提取高音数据 鸣叫 = 等 页码.评估(""" () => { const tweetElements = document.querySelectorAll('[data-testid=")鸣叫"]'); return Array.from(tweetElements).map(tweet => { const textElement = tweet.querySelector('[data-testid=")鸣叫文本"]'); const timeElement = tweet.querySelector('time'); 返回 { text: textElement ? textElement.innerText : ''、 timestamp: timeElement ? timeElement.getAttribute('datetime') : ''、 url: window.location.href }; }); } """) 返回 鸣叫 除开 例外情况 作为 e: 打印(f"扫描{用户名}出错:{e}") 返回 [;] 总算: 等 浏览器.关闭() # 使用方法 鸣叫 = 异步.run(搜刮 Twitter 个人档案("elonmusk")) 打印(json.倾销(鸣叫[;:3], 缩进=2)) |
主要优势 无头浏览器的功能包括处理 JavaScript 渲染、自动管理 cookie 和会话,以及通过逼真的浏览器指纹绕过基本的僵尸检测。
资源方面的考虑:与简单的 HTTP 请求相比,无头浏览器消耗的内存和 CPU 要多得多。对于大规模操作,可考虑在不同服务器上运行多个浏览器实例,或使用浏览器池。
绕过反窃听措施
Twitter 采用了复杂的僵尸检测技术,而不仅仅是简单的速率限制。了解这些措施有助于制定有效的对策。
常见的反窃听技术
速率限制: Twitter monitors request frequency per IP address, implementing both short-term (requests per minute) and long-term (daily quotas) limits. Learn more in Web Scraping Rate Limiting: The Fix.
IP 屏蔽:可疑的 IP 地址会被暂时或永久封禁。数据中心 IP 比住宅地址面临更严格的审查。
验证码挑战:当检测到类似机器人的行为时,自动呈现验证码。现代验证码使用的行为分析已超出了简单的图像识别。
浏览器指纹识别:分析浏览器特征,包括用户代理、屏幕分辨率、安装的插件和 JavaScript 执行模式。
有效对策
代理权轮换战略:使用 RapidSeedbox 等服务可访问住宅 IP 池,这些 IP 池显示为合法用户流量。与数据中心代理服务器相比,来自其 690 多万 IP 网络的住宅代理服务器可大大降低检测率。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
舶来品 随机的 舶来品 时间 从 itertools 舶来品 周期 # 代理权旋转设置 代理列表 = [; "http://user:[email protected]:8080" ] 代理周期 = 周期(代理列表) 捍卫 获取下一个代理(): 返回 下一个(代理周期) # 在您的铲运机中实施 异步 捍卫 带旋转的刮削(): 对于 i 于 范围(10): 代理 = 获取下一个代理() # 使用新代理配置浏览器/会话 # 执行刮擦请求 # 添加随机延迟 等 异步.睡眠(随机的.匀净(5, 15)) |
用户代理轮换:改变浏览器签名,避免模式检测。使用不同浏览器和操作系统的真实用户代理字符串。
|
1 2 3 4 5 6 7 8 9 |
用户代理 = [; "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36", "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:121.0) Gecko/20100101 Firefox/121.0" ] 捍卫 获取随机用户代理(): 返回 随机的.选择(用户代理) |
行为模式:通过可变延迟、逼真的滚动模式和偶尔的非抓取活动来模拟人类的浏览行为。
会话管理:通过适当的 cookie 处理保持会话的一致性,避免从同一 IP 创建过多的新会话。
高级探测规避
申请时间:遇到速率限制时,实施指数后退。开始时延迟时间较长,然后根据成功率逐步缩短延迟时间。
地理位置一致性:使用代理时,确保您的请求保持地域一致性。不要在不同国家之间快速跳转。
浏览器指纹管理:使用 undetected-chromedriver 或隐身插件等工具来降低浏览器指纹识别的有效性。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
从 硒 舶来品 webdriver 从 硒隐身 舶来品 隐秘 捍卫 创建隐形驱动程序(): 选项 = webdriver.ChromeOptions() 选项.添加参数("--无头") 选项.添加参数("--无沙箱") 选项.添加参数("--禁用-dev-shm-usage") 驱动程序 = webdriver.铬(选项=选项) 隐秘(驱动程序, 语言=[;"en-US", "en"], 供应商="谷歌公司", 平台="Win32", webgl_vendor="英特尔公司", 呈现器="英特尔 Iris OpenGL 引擎, fix_hairline=正确, ) 返回 驱动程序 |
错误处理:实施优雅的错误处理,以区分临时阻止、永久禁止和技术问题。
RapidSeedbox 等服务提供的住宅代理、适当的浏览器隐身技术和真实的行为模式相结合,为大规模 Twitter 数据收集奠定了坚实的基础,同时最大限度地降低了检测风险。
请记住,Twitter 的反僵尸措施仍在不断发展,因此成功的刮擦需要根据当前的平台行为不断调整这些技术。
常见问题
Twitter 搜索存在法律灰色地带。虽然 Twitter 的服务条款禁止自动收集数据,但搜索公开数据并不自动违法。
法律风险包括
1.侵犯用户内容版权
2.在某些司法管辖区违反《美国民事诉讼法》的行为
3.个人数据的 GDPR 合规问题
更安全的方法:尽可能使用 Twitter 的官方 API,大型项目应咨询法律顾问,并将重点放在用于合法研究目的的公开数据上。
不,但编码能提供更好的结果。
无代码选项:浏览器自动化工具和可视化工作流程构建器可用于基本的刮擦,但速度和灵活性有限。
编码解决方案:使用 Selenium 或专门库的 Python 可提供更强的控制能力、更好的反僵尸处理能力和更高的成功率。
最佳方法:首先使用无代码工具来测试您的需求,然后学习基本的 Python 脚本来进行严肃的数据收集。
Twitter 的免费 API 层级有严格限制:
1. 费率限制:每月申请配额极低
2. 历史数据:仅限于最近的推文(通常是过去一周的推文)
3. 功能:没有高级分析或参与指标
4. 访问:需要申请批准
大多数研究和业务用例都超出了免费层级限制,因此有必要采用付费计划或其他方法。
Twitter 的历史数据需要专门的工具,因为常规浏览只能显示最近的内容。
最佳工具: Snscrape - 通过日期范围过滤访问多年前推文的 Python 库。
其他选择:
1.TwitterScraper 库
2.学术研究 API(需要机构访问权限)
3.第三方历史数据服务
提示:历史刮擦速度较慢,需要仔细限制速率以避免堵塞。
基本做法:
1. 速率限制:请求之间最少间隔 1-2 秒
2. 尊重 robots.txt:遵循平台指南
3. 数据最小化:只收集必要的信息
4. 适当延迟:使用 IP 轮换和住宅代理
5. 错误处理:如果受阻或速率受限,则停止刮擦
主要原则:始终先试用官方 API,然后在尊重 Twitter 基础设施和用户隐私的前提下负责任地进行刮擦。
结论
Twitter 是全网社会学信息的重要来源。通过利用从 Twitter 搜刮到的信息,您可以量身定制计划,促进销售并改进营销策略。在本文中,我们深入概述了 Twitter 搜刮的不同方面和方法,以提取对企业或研究有价值的数据。
总之,根据 Twitter API v2 的新限制,再加上高昂的成本,选择最佳刮擦器会很有挑战性。你可以从 Twitter API 或直接连接到 Twitter API 的第三方应用程序和 Python 库(Tweepy)的更高级功能中获益。
但是,您可以提出的请求数量受到严格限制。另一方面,如果你想抓取公开数据,而且基本功能能满足你的需求,那么 Snscrape Python 库等选项会是一个不错的选择。
0评论