In this ultimate guide, we will explore the world of web scraping, a powerful technique to extract data from websites. rat
Que vous soyez un débutant curieux du concept ou un programmeur expérimenté cherchant à améliorer ses compétences, ce guide a quelque chose de précieux pour tout le monde. De la compréhension des bases de l'extraction de données HTML à l'utilisation de CSS et de XPath des sélecteurs au web scraping pratique avec Python, nous avons tout ce qu'il faut. En outre, nous aborderons les aspects juridiques, les considérations éthiques et les meilleures pratiques pour garantir un web scraping responsable.

Clause de non-responsabilité : Ce document a été élaboré strictement à des fins d'information. Il ne constitue pas une approbation d'activités (y compris les activités illégales), de produits ou de services. Vous êtes seul responsable du respect des lois applicables, y compris les lois sur la propriété intellectuelle, lorsque vous utilisez nos services ou que vous vous fiez à toute information contenue dans le présent document. Nous n'acceptons aucune responsabilité pour les dommages résultant de l'utilisation de nos services ou des informations qu'ils contiennent, de quelque manière que ce soit, sauf lorsque la loi l'exige explicitement.
Table des matières
- Qu'est-ce que le Web Scraping et comment ça marche ?
- Bases de l'extraction de données HTML : sélecteurs CSS et XPath.
- Web Scraping avec Python (+ Code).
- Le Web Scraping est-il légal ?
- Comment les sites web tentent-ils de bloquer le web scraping ?
- Éthique et meilleures pratiques pour le Web Scraping.
- Web Scraping : Foire aux questions (FAQ)
- Conclusion
1. Qu'est-ce que le Web Scraping et comment ça marche ?
Le web scraping (également connu sous le nom de récolte de données Web ou extraction de données) est le processus d'extraction automatique de données à partir de sites Web, de services Web et d'applications Web.
Le web scraping nous évite d'avoir à accéder à chaque site Web et à extraire manuellement des données, un processus long et inefficace. Le processus implique l'utilisation de scripts ou de programmes automatisés. Le script ou le programme accède à la structure HTML de la page Web, analyse les données et extrait les éléments spécifiques nécessaires de la page pour une analyse plus approfondie.
a. À quoi sert le Web Scraping ?
Le web scraping est fantastique s’il est effectué de manière responsable. Généralement, il peut être utilisé pour étudier des marchés, par exemple pour obtenir des informations et connaître les tendances d'un marché spécifique. Il est également populaire dans la surveillance de la concurrence pour suivre leur stratégie, leurs prix, etc.
Les cas d'utilisation plus spécifiques sont :
- Plateformes sociales (Scraping de Facebook et Twitter)
- Suivi des évolutions de prix en ligne,
- Avis sur les produits,
- Campagnes de référencement,
- Annonces immobilières,
- Suivi des données météorologiques,
- Suivi de la réputation d'un site Web,
- Suivi de la disponibilité et des prix des vols,
- Testez les annonces, quelle que soit la zone géographique,
- Suivi des ressources financières,
b. Comment fonctionne le Web Scraping ?
Les éléments typiques impliqués dans le web scraping sont l’initiateur et la cible. L'initiateur (web scraper) utilise un logiciel d'extraction automatique de données pour gratter les sites Web. Les cibles, en revanche, sont généralement le contenu du site Web, les coordonnées, les formulaires ou tout ce qui est accessible au public sur le Web.
Le processus typique est le suivant :
- ÉTAPE 1: L'initiateur utilise l'outil de scraping – un logiciel (qui peut être soit un service basé sur le cloud, soit un script fait maison) pour commencer à générer des requêtes HTTP (utilisées pour interagir avec des sites Web et récupérer des données). Ce logiciel peut lancer n'importe quoi, depuis une requête HTTP GET, POST, PUT, DELETE ou HEAD, jusqu'à une requête OPTIONS vers un site Web cible.
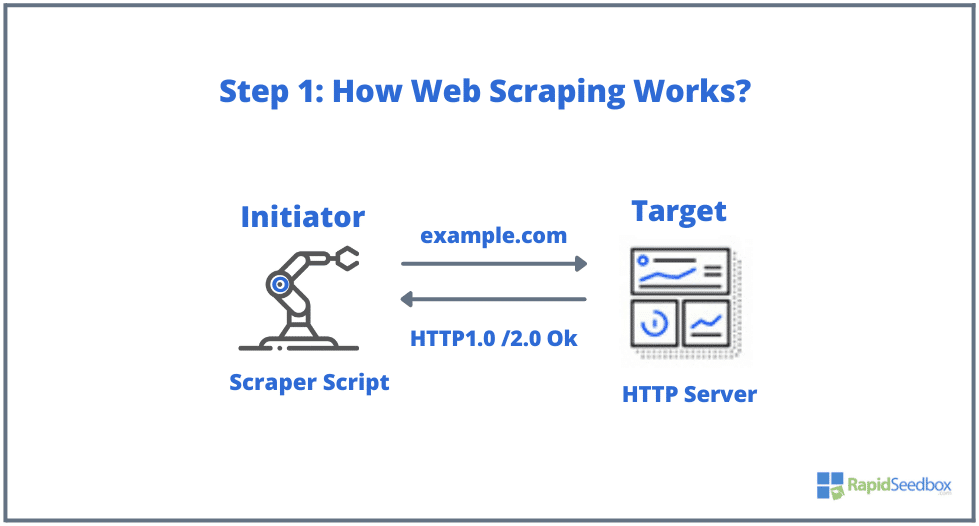
- ÉTAPE 2: Si la page existe, le site Web cible répondra à la demande du scraper avec le HTTP/1.0 200 OK (la réponse typique aux visiteurs.) Lorsque le scraper recevra la réponse HTML (par exemple 200 OK), il procédera alors à l'analyse du documenter et collecter ses données non structurées.
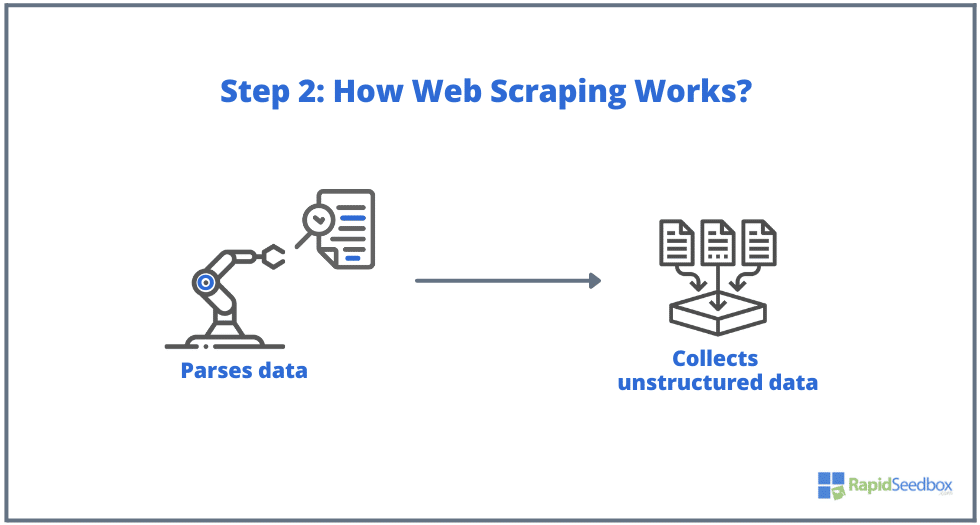
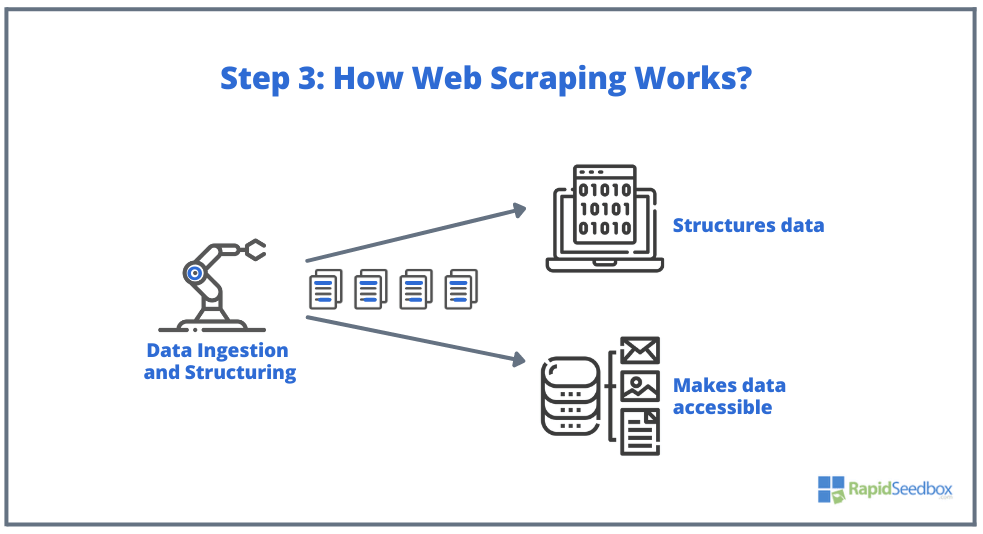
- ÉTAPE 3:. Le logiciel Scraper extrayait ensuite les données brutes, les stockait et ajoutait une structure (index) aux données selon tout ce qui avait été spécifié par l'initiateur. Les données structurées sont accessibles via des formats lisibles tels que XLS, CSV, SQL ou XML.
2. Bases de l'extraction de données HTML : sélecteurs CSS et XPath.
Vous connaissez peut-être déjà les bases : Le Web scraping consiste à extraire des données de sites Web, et tout commence par HTML :l'épine dorsale des pages Web. Dans un fichier HTML, vous trouverez des classes et des identifiants, des tableaux, des listes, des blocs ou des conteneurs, autant d'éléments de base qui constituent la structure d'une page.
CSS, quant à lui, est un langage de feuille de style utilisé pour contrôler la présentation et la mise en page des documents HTML. Il définit la manière dont les éléments HTML sont affichés sur une page Web, comme les couleurs, les polices, les marges et le positionnement. CSS joue un rôle clé dans le web scraping, car il permet d'extraire les données des éléments souhaités.
Remarque : Expliquer en détail ce que sont HTML et CSS et comment ils fonctionnent sort du cadre de cet article. Nous supposons que vous possédez déjà les compétences fondamentales en HTML et CSS.
Bien qu'il soit possible d'extraire des données directement du HTML brut à l'aide de diverses techniques telles que les expressions régulières, cela peut être très long et difficile. Étant donné que le langage structuré HTML a été conçu pour être « lisible par machine », il peut devenir très complexe et varié. C'est là que les sélecteurs CSS et XPath jouent un rôle clé.
a. Compilation et inspection du HTML.
Dans la section suivante, nous fournirons quelques exemples de sélecteurs CSS et XPath (compilés et inspectés). Tous les exemples HTML et CSS suivants ont été compilés avec l'éditeur en ligne HTML-CSS-JS.
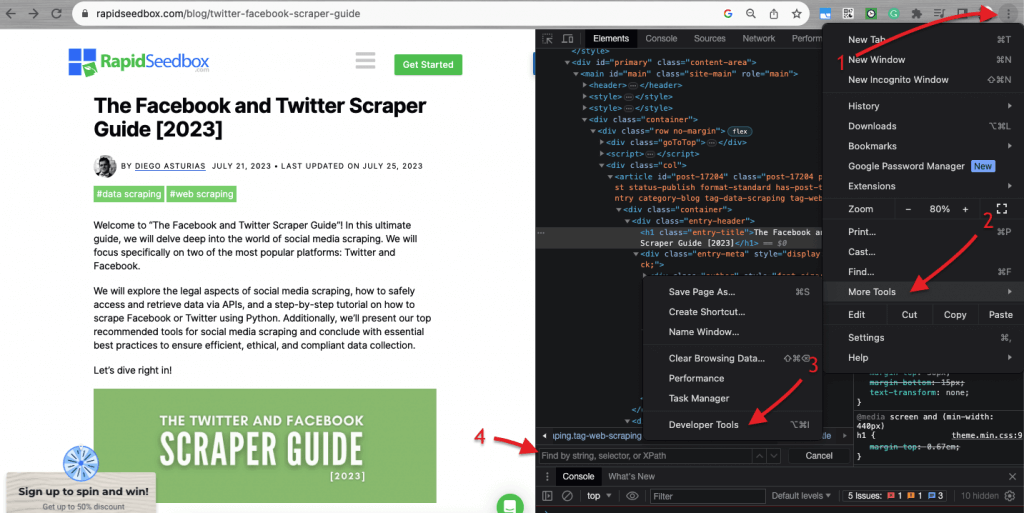
Lorsqu'il s'agit d'inspecter le code HTML des sites Web, Les navigateurs Web sont livrés avec des outils de développement, vous pouvez donc littéralement inspecter le HTML ou le CSS publiquement disponible sur n'importe quel site Web. Vous pouvez cliquer avec le bouton droit sur une page Web et sélectionner « Inspecter », « Inspecter l'élément » ou « Inspecter la source ». Pour une meilleure comparaison dynamique des pages côte à côte et du code, sur le navigateur Chrome > accédez aux trois points en haut à gauche (1) > Plus d'outils (2) > Outils de développement (3).
Les outils de développement sont livrés avec un filtre de recherche pratique (4) qui vous permet d'effectuer une recherche par chaîne, sélecteur ou XPath. À titre d'exemple, nous allons extraire certaines données de : https://www.rapidseedbox.com/blog/twitter-facebook-scraper-guide.
b. Sélecteurs CSS :
Les sélecteurs CSS sont des modèles utilisés pour sélectionner et cibler les éléments HTML d'une page Web. Ils sont utiles pour le web scraping (et le style) car ils offrent un moyen plus efficace et ciblé d'obtenir des données à partir de documents HTML. Bien qu'il soit possible d'extraire des données directement du HTML brut à l'aide de diverses techniques telles que les expressions régulières, les sélecteurs CSS offrent plusieurs avantages qui en font un choix privilégié pour le web scraping.
Techniques de ciblage et de sélection d'éléments HTML dans une page Web :
i. Sélection de nœud.
La sélection de nœuds est le processus de sélection d'éléments HTML sur la base de leurs noms de nœuds. Par exemple, sélectionner tous les éléments "p" ou tous les éléments "a" d'une page. Cette technique permet de cibler des types d'éléments spécifiques dans le document HTML.

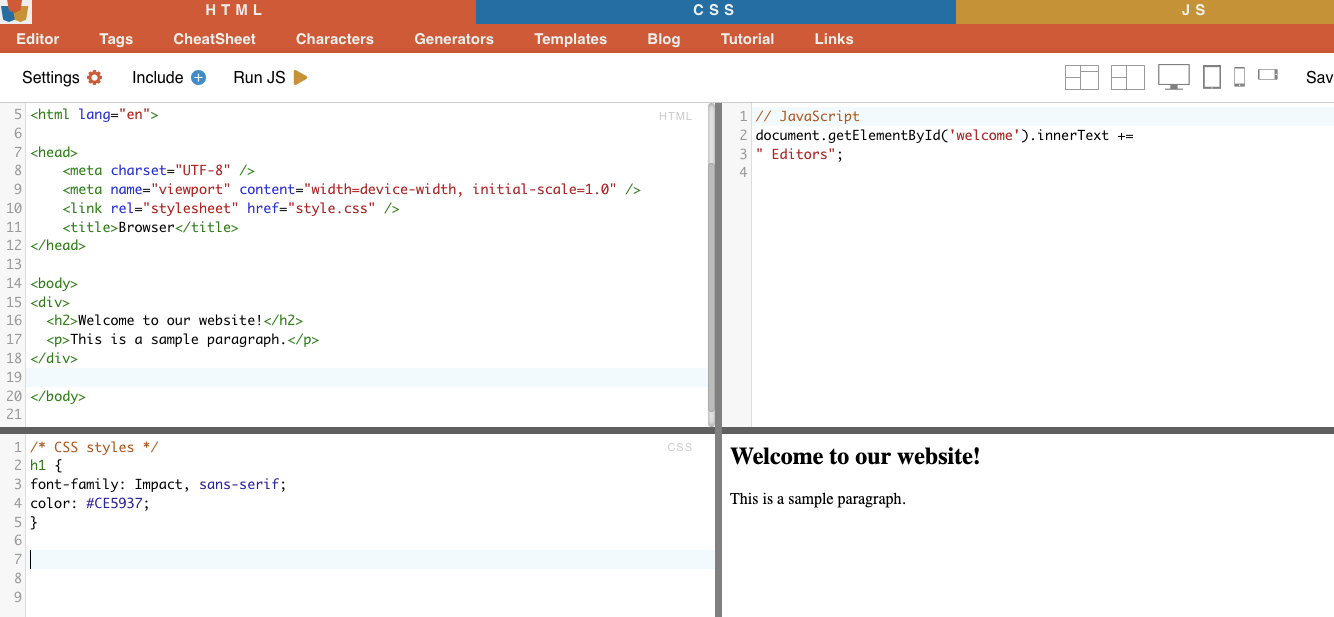
Exemple concret : Recherche manuelle des H2.
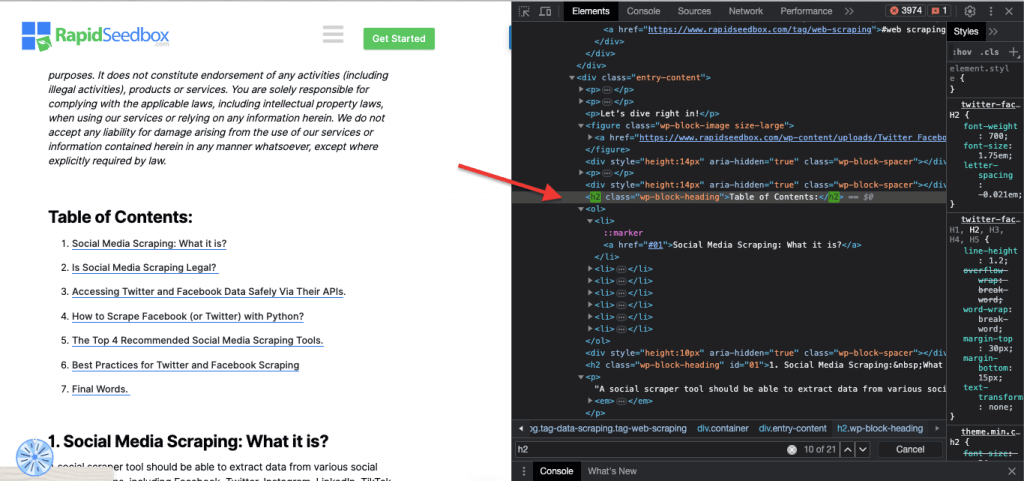
ii. Classe.
Dans les sélecteurs CSS, la sélection de classe implique la sélection d'éléments HTML en fonction de l'attribut de classe qui leur est attribué. L'attribut class vous permet d'appliquer un nom de classe spécifique à un ou plusieurs éléments. De plus, dans les styles CSS ou JavaScript, il peut être appliqué à tous les éléments de cette classe. Des exemples de noms de « classe » sont les boutons, les éléments de formulaire, les menus de navigation, les dispositions de grille, etc.
Exemple: Le sélecteur CSS suivant : 'highlight' sélectionnera tous les éléments dont l'attribut class est défini sur "highlight".


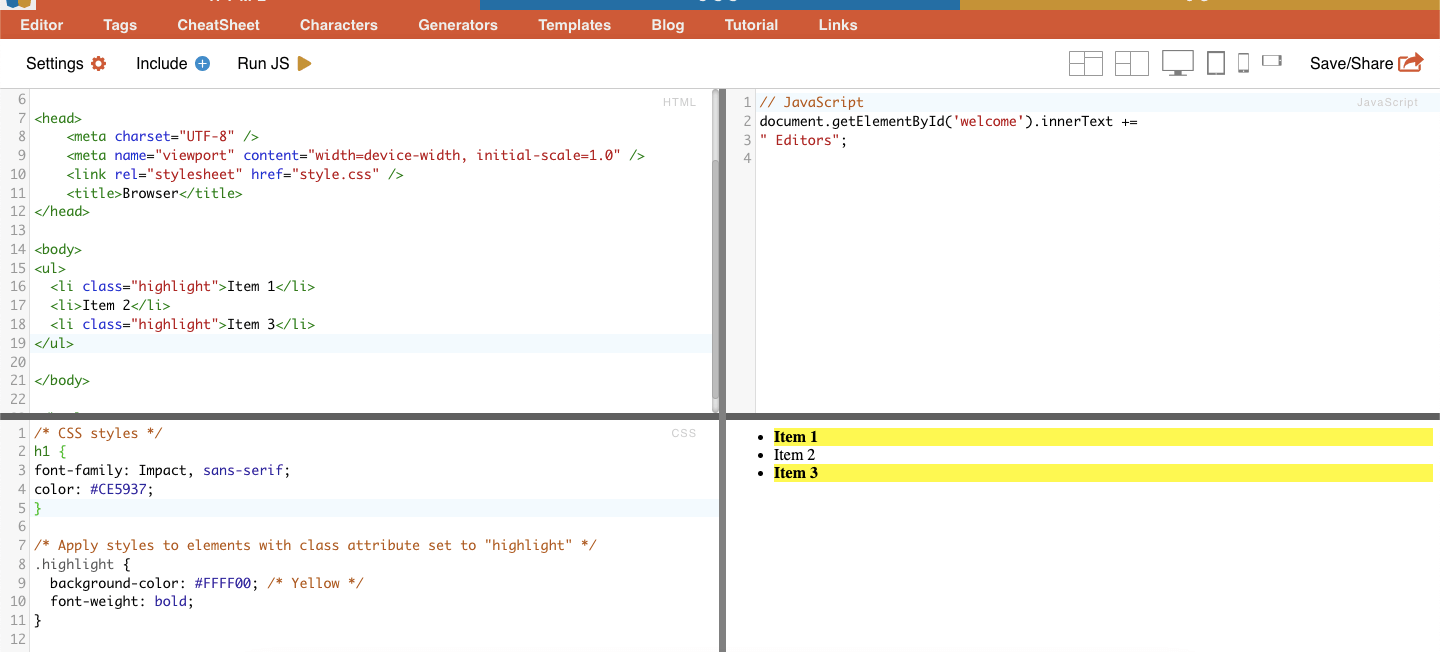
Exemple concret : Recherche manuelle de classes.
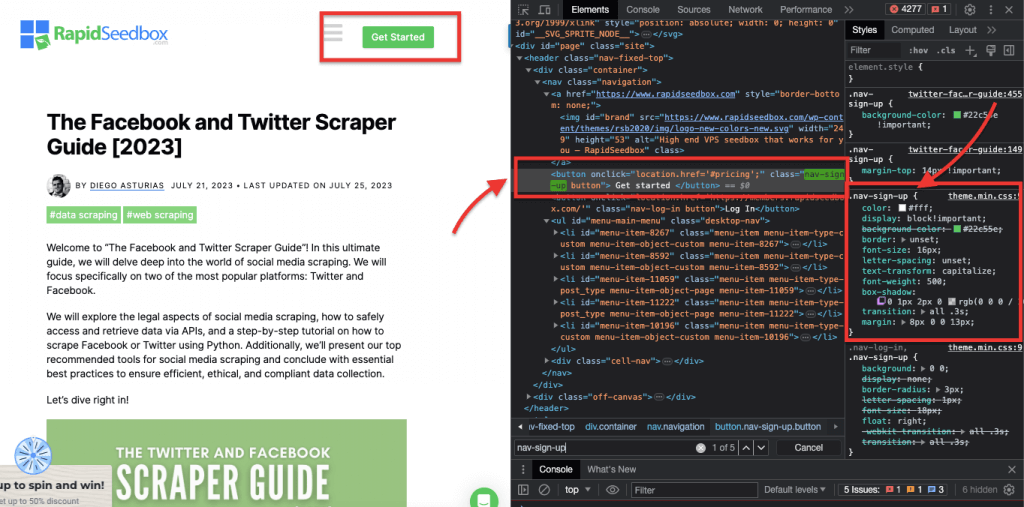
iii. Contraintes d'identification.
Les contraintes d'ID aident à sélectionner un élément HTML en fonction de son attribut ID unique. Cet attribut ID est utilisé pour identifier de manière unique un seul élément sur la page Web. Contrairement aux classes, qui peuvent être utilisées sur plusieurs éléments, les identifiants doivent être uniques au sein de la page.
Exemple: Le sélecteur CSS '#header' sélectionnera l'élément avec l'attribut ID défini sur "header".


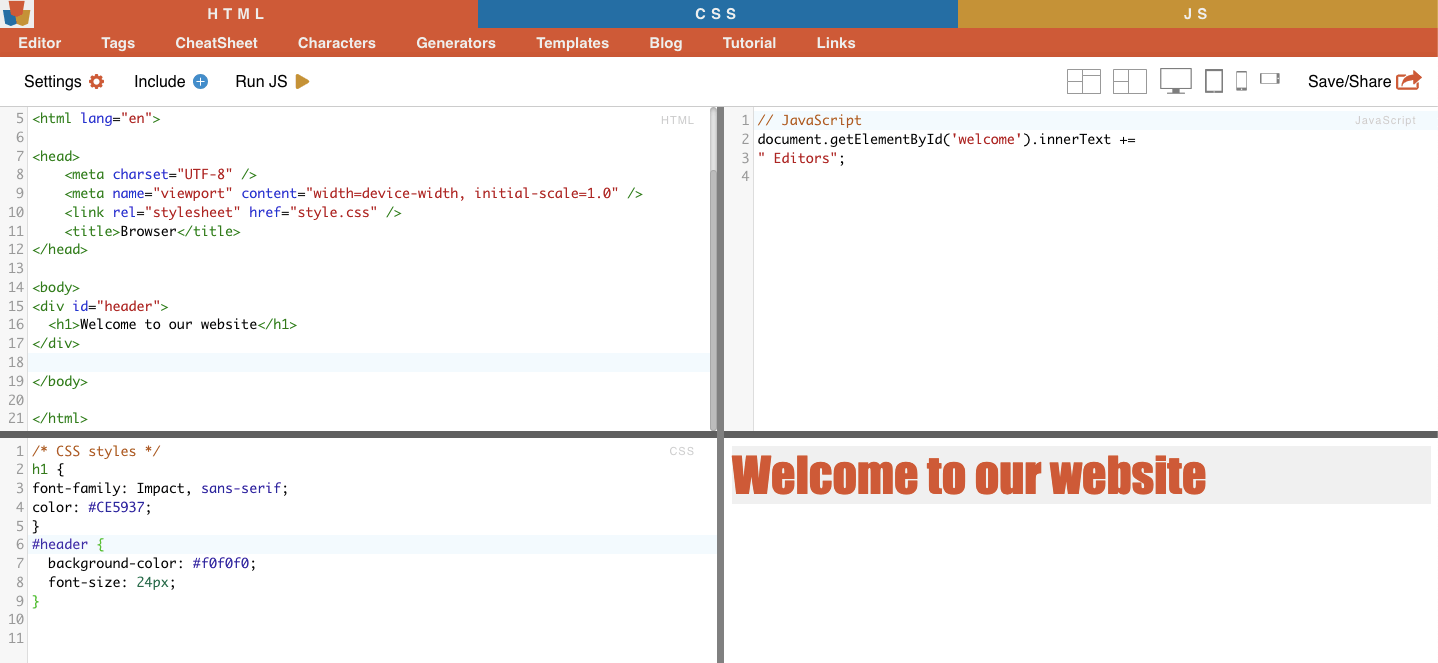
Exemple concret : Recherche manuelle des identifiants. Après avoir trouvé le #01, vous devrez localiser l'id=”01″
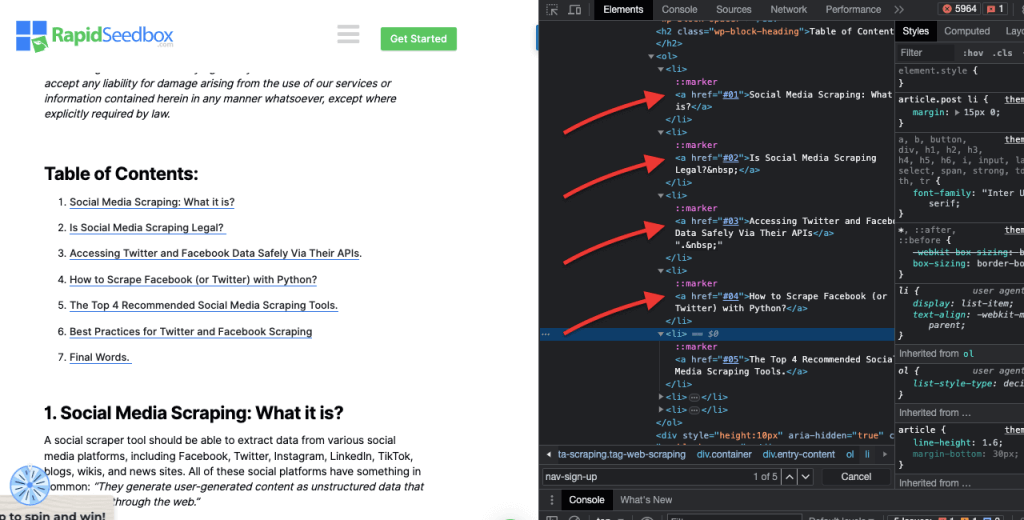
iv. Correspondance d'attributs.
Cette technique consiste à sélectionner des éléments HTML en fonction d'attributs spécifiques et de leurs valeurs. Il vous permet de cibler des éléments qui ont un attribut ou une valeur d'attribut particulière. Il existe différents types de correspondance d'attributs, tels que la correspondance exacte, la correspondance de sous-chaînes, etc.
Exemple: L'exemple suivant montre un attribut personnalisé appelé type de données. Pour cibler ou styliser certains éléments (par exemple les éléments de la liste marqués comme "fruit"), vous pouvez utiliser le sélecteur CSS qui sélectionne les éléments en fonction des valeurs de leurs attributs.
Pour récupérer uniquement les éléments marqués comme « fruit », vous pouvez utiliser le sélecteur CSS suivant :

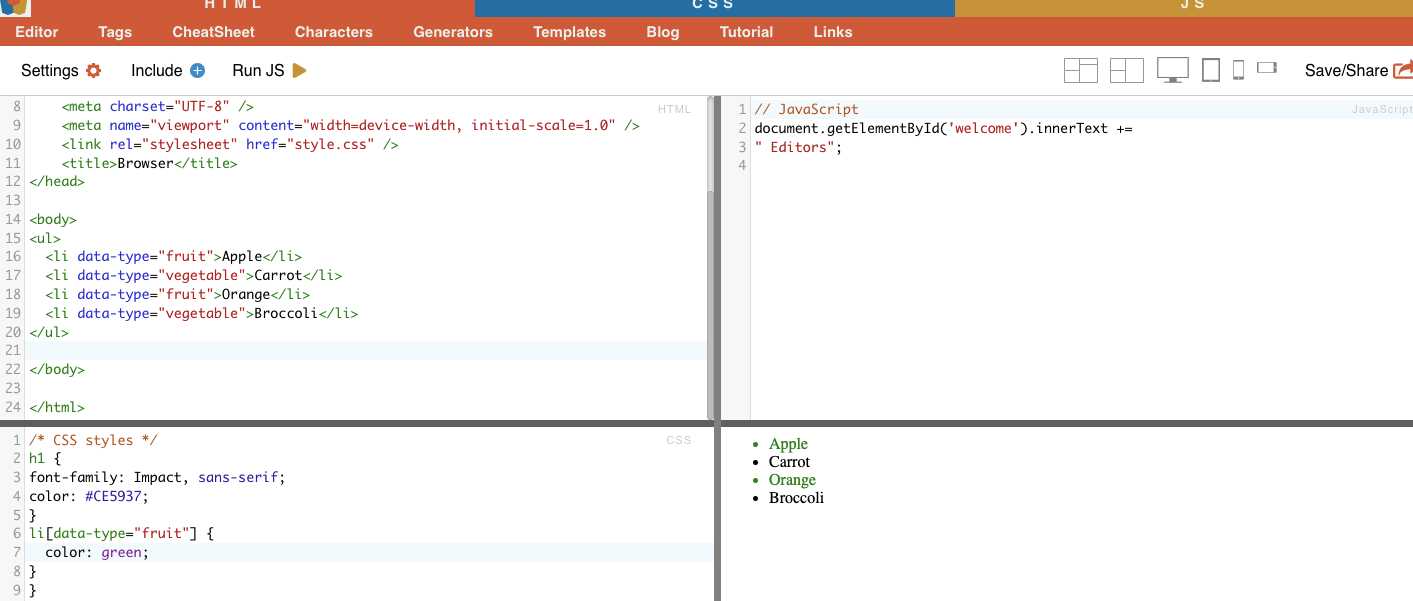
Exemple concret : Recherche manuelle d'attributs.
c. Sélecteurs XPath :
Les sélecteurs CSS sont idéaux pour les tâches de web scraping simples où la structure HTML est relativement simple. Mais lorsque la structure HTML devient plus complexe, il existe une autre solution : les sélecteurs XPath.
Sélecteurs XPath (sélecteurs de langage de chemin XML) est un langage de chemin flexible utilisé pour naviguer dans les éléments d'un document XML ou HTML. Ils aident à sélectionner des nœuds spécifiques dans le code HTML en fonction de l'emplacement, des noms, des attributs ou du contenu. Les sélecteurs XPath peuvent également être utiles pour cibler des éléments en fonction de leurs attributs de classe et d'ID.
Voici trois exemples de sélecteurs XPath pour le web scraping.
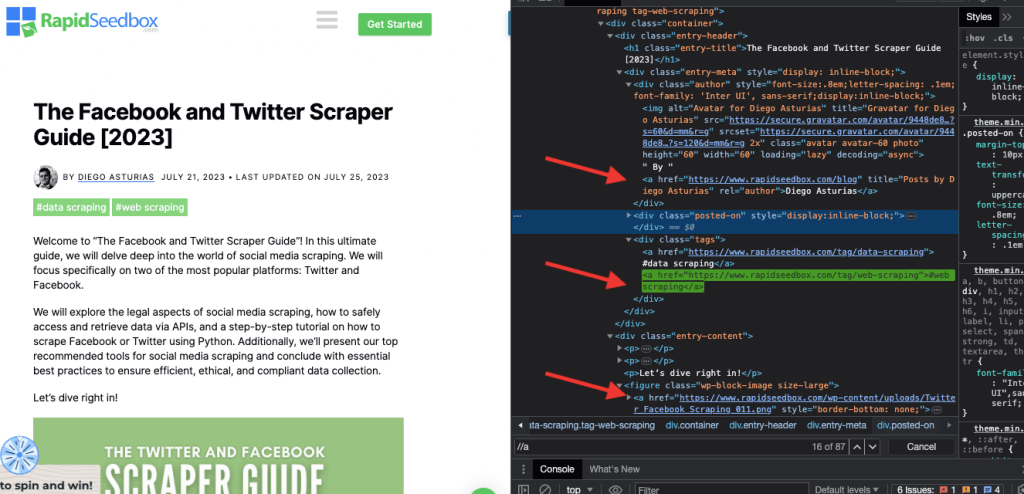
i. Exemple 1 : Expression XPath : ' //a
L'expression XPath " //a " sélectionne tous les éléments " " de la page, quel que soit leur emplacement dans le document. La capture d'écran suivante montre la localisation manuelle de tous les éléments "" sur la page.
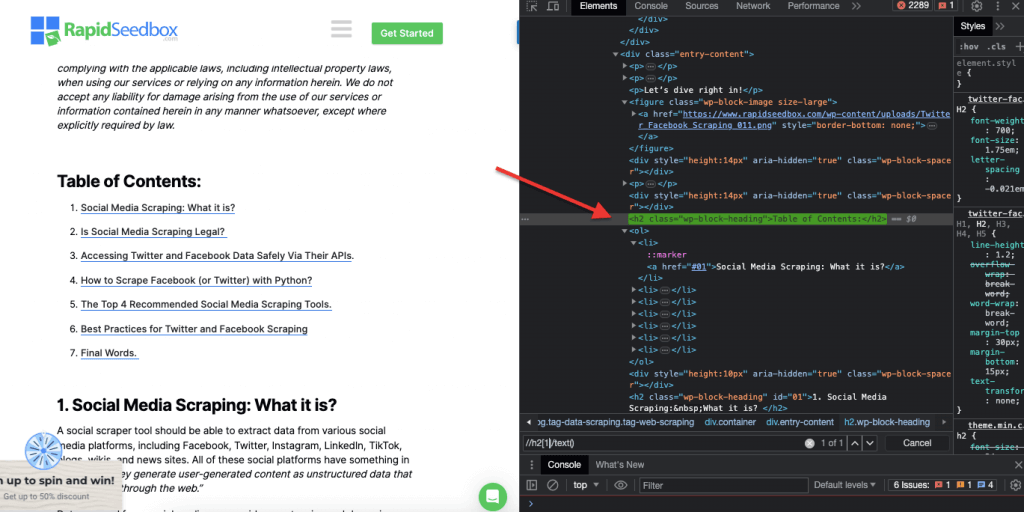
ii. Exemple 2 : ' //h2[1]/text()'
L'expression XPath :
' //h2[1]/text() '
Il sélectionnera le contenu textuel du premier titre h2 de la page. L'indice '[1]' est utilisé pour spécifier la première occurrence de l'élément h2, vous pouvez également spécifier la deuxième occurrence avec l'indice '[2]', et ainsi de suite. La capture d'écran suivante montre la localisation manuelle du premier titre h2 sur la page à l'aide de ce sélecteur XPath.
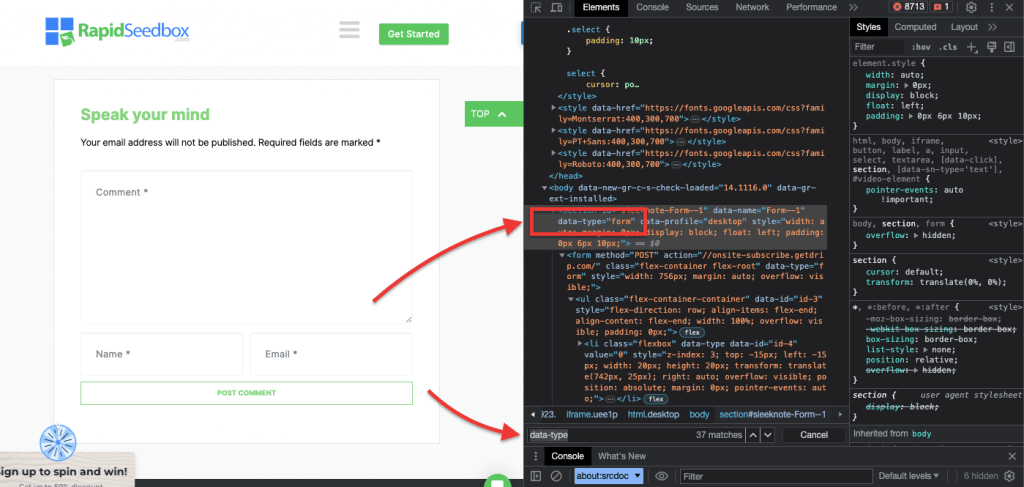
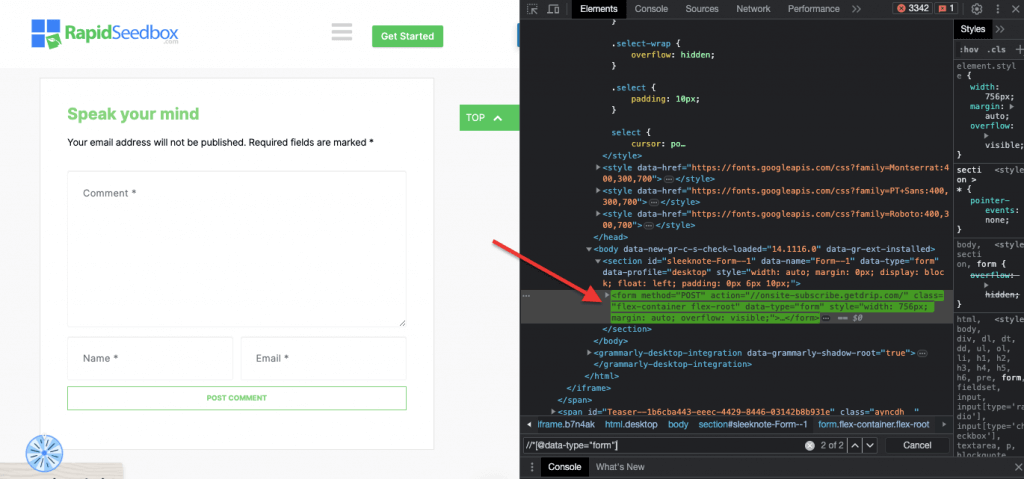
iii. Exemple 3. ' //* [@data-type="form"]
L'expression XPath //* [@data-type="form"] sélectionne tous les éléments qui ont un attribut de données avec la valeur « form ». Le * Le symbole indique que tout élément avec l'attribut de données spécifié sera sélectionné, quel que soit son nom de nœud. La capture d'écran suivante montre le processus de localisation manuelle des éléments avec la valeur « form ».
L'inspection visuelle et l'extraction manuelle des données d'une page HTML à l'aide de ces sélecteurs CSS et XPath peuvent non seulement prendre du temps, mais également être sujettes à des erreurs. De plus, l’extraction manuelle ou visuelle des données est totalement inadaptée à la collecte de données à grande échelle ou aux tâches de scraping répétitives. C'est là que les scripts et la programmation sont très utiles.
Boostez votre web scraping avec les proxies rapides, sécurisés et anonymes de RapidSeedbox.
Quels sont les meilleurs langages de programmation pour le web scraping ?
Le langage de programmation le plus populaire pour le scraping est Python en raison de ses bibliothèques et de ses packages (plus d'informations à ce sujet dans la section suivante.) Un autre langage de programmation populaire pour le web scraping est R, car il dispose également d'un ensemble fantastique de bibliothèques et de frameworks pris en charge. De plus, il convient également de mentionner C#, un langage de programmation populaire utilisé par de nombreux web scrapers. Des sites Web tels que ZenRows proposent des guides complets sur comment web scrape un site Web en C#, ce qui permet aux développeurs de comprendre plus facilement le processus et de démarrer leurs propres projets.
Par souci de simplicité, ce guide de web scraping se concentrera sur le web scraping avec Python. Continuez à lire !
3. Web Scraping avec Python (avec code).
Pourquoi inspecter visuellement et extraire manuellement des données HTML à l'aide de sélecteurs CSS ou de sélecteurs XPath alors que vous pouvez les utiliser de manière systématique et automatique avec les langages de programmation ?
Il existe de nombreuses bibliothèques et frameworks de web scraping populaires qui prennent en charge les sélecteurs CSS pour une extraction plus facile des données. L'un des langages de programmation les plus populaires pour le web scraping est Python, pour ses bibliothèques comme BeautifulSoup, Demandes, CSS-Select, Sélénium, et Ferraille. Ces bibliothèques permettent aux web scrapers d'exploiter les sélecteurs CSS et XPath pour extraire efficacement les données.
BeautifulSoup.
BeautifulSoup est l'un des packages Python les plus populaires et les plus puissants conçus pour analyser les documents HTML et XML. Ce package crée une arborescence d'analyse des pages, vous permettant d'extraire facilement des données du HTML.
| À savoir ! Dans la lutte contre le COVID-19, Le robot DXY-COVID-19-Crawler de Jiabao Lin a utilisé BeautifulSoup pour extraire des données précieuses d'un site web médical chinois. Ce faisant, il a aidé les chercheurs à surveiller et à comprendre la propagation du virus. [(Source)] |
Demandes.
Python Demandes est une bibliothèque HTTP simple mais puissante. Il est utile pour effectuer des requêtes HTTP afin de récupérer des données à partir de sites Web. « Demandes » simplifie le processus d'envoi de requêtes HTTP et de gestion des réponses dans votre projet Python de web scraping.
a. Tutoriel pour le Web Scraping avec Python (+ Code)
Dans ce tutoriel de web scraping avec Python, nous obtiendrons les données d'un site Web HTML cible en utilisant le code Python avec les « requêtes » et la bibliothèque BeautifulSoup.
Conditions préalables:
Assurez-vous que les conditions préalables suivantes sont remplies :
- Environnement Python : Assurez-vous que vous avez Python installé sur votre ordinateur. Assurez-vous également que vous pouvez exécuter le script dans votre environnement Python préféré (par exemple, IDLE ou Bloc-notes Jupyter).
- Bibliothèque de requêtes : Installez le
demandesbibliothèque. Il est utilisé pour envoyer des requêtes HTTP GET à l'URL spécifiée. Vous pouvez l'installer en utilisanttuyauen exécutantpip install requestsdans votre invite de commande ou votre terminal. - Bibliothèque BeautifulSoup : Installez le
bellesoupe4Vous pouvez l'installer en utilisanttuyauen exécutantpip install beautifulsoup4dans votre terminal.
Le code Python pour récupérer les données Web d'une page (avec BeautifulSoup)
Le script suivant récupérera l'URL spécifiée, analysera le contenu HTML à l'aide de BeautifulSoup et imprimera les titres des principaux articles d'actualité sur la page Web.

Lors de l'exécution du script sur IDLE Shell, l'écran imprime tous les « news_titles » rassemblés sur le site Web ciblé.

b. Variations de notre code Python pour le web scraping.
Nous pouvons prendre notre précédent code Python de web scraping et faire quelques variations pour récupérer différents types de données.
Par exemple:
- Recherche d'images : Pour trouver toutes les balises d'image (
) sur la page web, vous pouvez utiliser la méthode find_all() avec le nom de balise "img" :

- Trouver des liens : Pour trouver toutes les balises d'ancrage () qui représentent des liens sur la page web, vous pouvez utiliser la méthode find_all() avec le nom de balise "a" :

Le script fourni (avec ses variantes) est un script de base pour le web scraping. Il extrait et imprime simplement les titres des principaux articles d'actualité à partir de l'URL spécifiée. Mais, malheureusement, ce script simple manque de nombreuses fonctionnalités qui constituent un projet de web scraping plus complet. Vous souhaiterez peut-être envisager plusieurs éléments en ajoutant le stockage de données, la gestion des erreurs, la pagination/exploration, l'utilisation de l'agent utilisateur et des en-têtes, des mesures de limitation et de politesse, ainsi que la capacité de gérer du contenu dynamique.
4. Le Web Scraping est-il légal ?
Le web scraping est généralement perçu comme controversé ou illégal. Mais en réalité, il s’agit d’une pratique légitime selon laquelle, si elle respecte certaines limites éthiques et juridiques, le web scraping est parfaitement légal.
La légalité du web scraping dépend de la nature des données extraites et des méthodes utilisées. Le web scraping est considéré comme licite lorsqu’il est utilisé pour recueillir des informations accessibles au public sur Internet. Cependant, la prudence est toujours de mise, surtout lorsqu’il s’agit de données personnelles ou de contenus protégés par le droit d’auteur.
Voici quelques conseils à garder à l’esprit :
- Ne supprimez pas les données privées. Il est également illégal d’extraire des données qui ne sont pas accessibles au public. Récupérer des données derrière une page de connexion, avec connexion par utilisateur et mot de passe, est contraire à la loi aux États-Unis, au Canada et dans la plupart des pays d'Europe.
- Ce que vous faites avec les données est ce qui peut vous causer des ennuis. Le web scraping éthique implique d’être attentif aux données collectées et à leur finalité. Une attention particulière doit être accordée aux données personnelles et à la propriété intellectuelle. Assurez-vous de respecter les réglementations telles que le RGPD et le CCPA, qui régissent le traitement des données personnelles. Par exemple, la réutilisation ou la revente de contenu ou le téléchargement de matériel protégé par le droit d'auteur sont illégaux (et doivent être évités).
- Il est également essentiel de consulter les conditions d’utilisation sur les sites Web. Il s’agit de documents qui indiquent à toute personne utilisant son service ou son contenu comment elle doit et ne doit pas interagir avec les ressources.
- Assurez-vous toujours d’avoir des alternatives comme l’utilisation d’API officiellement fournies. Certains sites web, comme les agences gouvernementales, la météo et les plateformes de médias sociaux, rendent certaines de leurs données accessibles au public par le biais d'API.
- Pensez à vérifier le fichier robots.txt. This file is saved on the web server and gives directions to web crawlers and web scraping about what parts of a website to avoid and what parts are authorized. It also gives directions about the rate limits.
- Évitez de lancer des attaques de web scraping. Selon le contexte, le web scraping est parfois appelé une attaque de scraping. Lorsque les spammeurs utilisent des botnets (armées de robots) pour cibler un site Web avec des requêtes volumineuses et rapides, l’ensemble du service du site Web peut échouer. Les récupérations de données à grande échelle peuvent faire tomber des sites entiers.
Actualités récentes sur les aspects juridiques du web scraping.
Des décisions de justice récentes ont précisé que la suppression de données accessibles au public n'est généralement pas considérée comme une violation. Une décision historique de la cour d'appel américaine a réaffirmé la légalité du web scraping, déclarant que le scraping de données accessibles au public sur Internet ne viole pas le Computer Fraud and Abuse Act (CFAA) [source : TechCrunch].
Par ailleurs, les récents procès intentés contre OpenAI et Microsoft mettent en lumière les préoccupations relatives à la protection de la vie privée, à la propriété intellectuelle et aux lois anti-piratage, selon des informations récentes [Bloomberg]. Bien que la CFAA ait une efficacité limitée, les réclamations pour rupture de contrat et les lois nationales sur la protection de la vie privée sont à l'étude. L’interaction entre le droit d’auteur et le droit des contrats reste irrésolue, laissant de nombreuses questions sans réponse dans le contexte du web scraping.
Aux dernières nouvelles, [source : IndiaTimes] Elon Musk modifie les règles de Twitter pour empêcher des niveaux extrêmes de grattage de données. Selon Musk, le web scraping extrême a un impact négatif sur l’expérience utilisateur. Il a suggéré que les organisations utilisant de grands modèles linguistiques pour l’IA générative étaient à blâmer.
5. Comment les sites Web tentent-ils de bloquer le Web Scraping ?
Les entreprises souhaitent que certaines de leurs données soient accessibles aux visiteurs humains. Mais lorsque des entreprises ou des utilisateurs utilisent des scripts automatisés ou des robots pour extraire agressivement des données du site, il peut y avoir un abus de la vie privée et des ressources sur le serveur et la page web ciblés. Les sites victimes préfèrent décourager ce type de trafic.
Techniques anti-scraping.
- Des volumes de trafic inhabituels et élevés provenant d’une seule source. Les serveurs Web peuvent utiliser des WAF (Web Application Firewalls) avec des listes noires d'adresses IP bruyantes pour bloquer le trafic, des filtres sur les taux et tailles de requêtes « inhabituels » et des mécanismes de filtrage. Certains sites utilisent une combinaison de WAF et de CDN (Content Delivery Networks) pour filtrer entièrement ou réduire le bruit de ces adresses IP.
- Certains sites Web peuvent détecter des modèles de navigation de type robot. Comme pour la technique précédente, les sites web bloquent également les requêtes en fonction de l'agent utilisateur (en-tête HTTP). Les bots n'utilisent pas de navigateur normal. Ces robots ont différentes chaînes d'agent utilisateur (par exemple, crawler, spider ou bot), un manque de variation, une absence d'en-têtes (navigateurs sans tête), demander des tarifs, etc.
- Les sites web modifient également souvent leur balisage HTML. Les robots de balayage du web suivent un itinéraire cohérent de "balisage HTML" lorsqu'ils parcourent le contenu d'un site web. Certains sites web modifient régulièrement et de manière aléatoire les éléments HTML au sein du balisage. Cette technique perturbe les habitudes ou le calendrier de scraping d'un robot. La modification du balisage HTML n'empêche pas le web scraping, mais le rend beaucoup plus difficile.
- L'utilisation de défis comme le CAPTCHA. Pour éviter que les robots n'utilisent des navigateurs sans tête, certains sites Web nécessitent des défis CAPTCHA. Les robots utilisant des navigateurs sans tête ont du mal à résoudre ce type de défis. Les CAPTCHA ont été conçus pour être résolus au niveau de l'utilisateur (via un navigateur) et non par des robots.
- Certains sites sont des pièges (pots de miel) pour gratter les robots. Certains sites Web sont créés uniquement pour piéger les robots scrapers. Il s'agit d'une technique appelée honeypots. Ces pots de miel ne sont visibles que par les robots scrapers (et non par les visiteurs humains ordinaires) et sont conçus pour conduire les web scrapers dans un piège.
6. Éthique et meilleures pratiques pour le Web Scraping.
Le web scraping doit être effectué de manière responsable et éthique. Comme indiqué précédemment, la lecture des conditions générales d'utilisation devrait vous donner une idée des restrictions auxquelles vous devez vous conformer. Si vous souhaitez vous faire une idée des règles applicables à un robot d'exploration, consultez son fichier ROBOTS.txt.
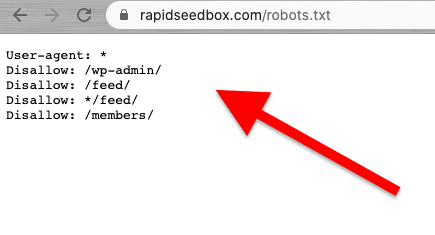
Si le web scraping est entièrement interdit ou bloqué, utilisez leur API (si elle est disponible).
Soyez également attentif à la bande passante du site Web cible pour éviter de surcharger un serveur avec trop de requêtes. Il est crucial d’automatiser les requêtes avec un taux et des délais d’attente appropriés pour éviter de mettre à rude épreuve le serveur cible. Simuler un utilisateur en temps réel devrait être optimal. De plus, ne supprimez jamais les données derrière les pages de connexion.
Suivez les règles et tout devrait bien se passer.
Meilleures pratiques de scraping Web.
- Utilisez un proxy. Un proxy est un serveur intermédiaire qui transmet les requêtes. Lors du web scraping avec un proxy, vous acheminez votre demande initiale via celui-ci. Ainsi, le proxy mappe la demande avec sa propre adresse IP et la transmet au site Web cible. Utilisez un proxy pour :
- Éliminez les risques de voir votre adresse IP mise sur liste noire ou bloquée. Faites toujours des demandes via divers proxys : proxys IPv6 en sont un bon exemple. Un pool de proxy peut vous aider à effectuer des requêtes de volume plus important sans être bloqué.
- Contournez le contenu géo-adapté. Un proxy dans une région spécifique est utile pour récupérer des données en fonction de cette région géographique particulière. Ceci est utile lorsque les sites Web et les services se trouvent derrière un CDN.
- Proxy Tournantes. Les proxys rotatifs prennent (font pivoter) une nouvelle adresse IP du pool pour chaque nouvelle connexion. Gardez à l'esprit que Les VPN ne sont pas des proxys. Bien qu’ils fassent quelque chose de très similaire, à savoir assurer l’anonymat, ils travaillent à des niveaux différents.
- Tourner UA (User Agents) et en-têtes de requête HTTP. Pour faire pivoter les en-têtes UA et HTTP, vous devrez collecter une liste de chaînes UA à partir de vrais navigateurs Web. Mettez la liste dans votre code de web scraping en Python et définissez des requêtes pour sélectionner des chaînes aléatoires.
- Ne repoussez pas les limites. Ralentissez le nombre de requêtes, effectuez une rotation et randomisez. Si vous faites un grand nombre de demandes pour un site Web, commencez par randomiser les choses. Faites en sorte que chaque demande semble aléatoire et humaine. Tout d’abord, modifiez l’adresse IP de chaque requête à l’aide de proxys rotatifs. Utilisez également différents en-têtes HTTP pour donner l’impression que les requêtes proviennent d’autres navigateurs.
Boostez votre web scraping avec les proxies rapides, sécurisés et anonymes de RapidSeedbox.
7. Web Scraping : Foire aux questions (FAQ)
a. Qu'est-ce que robots.txt et quel rôle joue-t-il dans le web scraping ?
Le robots.txt sert d'outil de communication entre les propriétaires de sites web, les robots d'indexation et les "scrapeurs". Il s'agit d'un fichier texte placé sur le serveur d'un site web qui fournit des instructions aux robots web (robots d'indexation, araignées web et autres robots automatisés) sur les parties du site web auxquelles ils sont autorisés à accéder et à gratter, et sur celles qu'ils doivent éviter. Les robots d'exploration "bien élevés" (comme Googlebot) sont conçus pour lire automatiquement le fichier robots.txt. Les scrapeurs ne sont pas conçus pour lire ce fichier. Il est donc très important de connaître le fichier robots.txt afin de respecter les souhaits du propriétaire du site web.
b. Quelles techniques les administrateurs de sites Web utilisent-ils pour éviter les tentatives de scraping « abusives » ou « non autorisées » ?
Tous les scrapers n’extraient pas les données de manière éthique et légale. Ils ne suivent pas les TOS (Conditions de service) du site ni les directives robots.txt. Les administrateurs de sites Web peuvent donc prendre des mesures supplémentaires pour protéger leurs données et leurs ressources, comme l'utilisation du blocage IP ou des défis CAPTCHA. Ils peuvent également utiliser des mesures de limitation de débit, la vérification de l'agent utilisateur (pour identifier les robots potentiels), suivre les sessions, utiliser une authentification basée sur des jetons, utiliser des CDN (Content Delivery Networks) ou même utiliser des systèmes de détection basés sur le comportement.
c. Web Scraping ou Web Crawling ?
Bien que le web scraping et le web crawling soient tous deux des techniques d'extraction de données sur le web, ils ont des objectifs, des champs d'application, une automatisation et des aspects juridiques différents. D'une part, les techniques de "web scraping" visent à extraire des données spécifiques de sites particuliers. Elles sont ciblées et ont une portée spécifique et limitée. Elles utilisent des scripts automatisés ou des outils tiers pour demander, recevoir, analyser, extraire et structurer des données. Les techniques d'exploration du web (comme recherche dans les listes), quant à eux, sont utilisés pour effectuer des recherches systématiques sur le web. Ils sont populaires parmi les moteurs de recherche (champ d'application plus large), les plateformes de médias sociaux, les chercheurs, les agrégateurs de contenu, etc. Les robots d'indexation peuvent visiter de nombreux sites automatiquement (via des bots, des crawlers ou des spiders), établir une liste, indexer les données (créer une copie) et les stocker dans une base de données. Les robots d'indexation vérifient généralement les fichiers ROBOTS.txt.
d. Data mining vs Data scraping : quelles sont leurs différences et similitudes ?
Le data mining et le data scraping impliquent tous deux l'extraction de données. Cependant, le data mining se concentre sur l'utilisation de techniques statistiques et d'apprentissage automatique pour analyser des ensembles de données structurées. Il vise à identifier des modèles, des relations et des idées dans des ensembles de données structurées vastes et complexes. Le grattage de données, quant à lui, se concentre sur la "collecte" d'informations spécifiques à partir de pages web et de sites web. Les deux techniques et outils peuvent être utilisés conjointement. Le web scraping peut être une étape préliminaire pour collecter des données sur le web, qui sont ensuite introduites dans des algorithmes d'exploration de données pour une analyse approfondie et la découverte d'informations.
e. Qu’est-ce que le grattage d’écran ? Et quel est le rapport avec le Data Scraping ?
Les deux techniques se concentrent sur l'extraction de données, mais diffèrent par le type de données qu'elles extraient. Raclage de l'écran visent à capturer et à extraire "automatiquement" les données visuelles affichées sur les sites web et les documents, y compris le texte de l'écran. Contrairement au web scraping, qui analyse les données HTML (et extrait ainsi un large éventail de données web), le screen scraping lit les données textuelles directement à partir de l'affichage de l'écran.
f. Le Web Harvesting est-il la même chose que le Web Scraping ?
Le scraping de données et le web harvesting sont étroitement liés et souvent utilisés de manière interchangeable, mais il ne s'agit pas du même concept. La collecte de données sur le web a une connotation plus large. Il englobe différentes méthodes d'extraction de données sur le web, y compris divers mécanismes d'extraction automatique, comme le web scraping. Une distinction claire est que le web harvesting est souvent utilisé lorsqu'une API est impliquée, plutôt que d'analyser directement le code HTML des pages web (comme le fait le web scraping).
g. Sélecteur CSS vs Sélecteur XPath : Quelles sont les différences lors du scraping ?
Les sélecteurs CSS sont un moyen efficace d'extraire des données lors du web scraping. Ils offrent une syntaxe simple et fonctionnent bien dans la plupart des scénarios de scraping. Toutefois, dans les cas plus complexes ou lorsqu'il s'agit de structures imbriquées, les sélecteurs XPath peuvent apporter une flexibilité et une fonctionnalité supplémentaires.
h. Comment gérer des sites Web dynamiques avec Selenium ?
Selenium est un outil puissant pour le web scraping de sites Web dynamiques. Il vous permet d'interagir avec les éléments de la page Web comme le ferait un utilisateur humain. Cette capacité permet à votre « script » de naviguer dans le contenu généré dynamiquement. En utilisant WebDriver de Selenium, vous pouvez attendre que les éléments de la page se chargent, interagir avec les éléments AJAX et récupérer les données des sites Web qui dépendent fortement de JavaScript.
i. Comment gérer AJAX et JavaScript lors du Web Scraping ?
Lorsqu'il s'agit d'AJAX et de JavaScript lors du web scraping, les bibliothèques traditionnelles telles que Requests et Beautiful Soup peuvent ne pas suffire. Pour gérer les requêtes AJAX et le contenu rendu en JavaScript, vous pouvez utiliser des outils comme Selenium ou des navigateurs sans tête tels que Marionnettiste.
8. Le mot de la fin.
Toutes nos félicitations! Vous complétez le guide ultime du web scraping !
Nous espérons que ce guide vous a doté des connaissances et des outils nécessaires pour exploiter le potentiel du web scraping pour vos projets.
N’oubliez pas qu’un grand pouvoir implique de grandes responsabilités. Lorsque vous commencez votre parcours vers le web scraping, donnez toujours la priorité aux pratiques éthiques, respectez les conditions d’utilisation des sites Web et soyez attentif à la confidentialité des données.
Nous avons effleuré la partie émergée de l'iceberg. Le grattage de sites web est un sujet très vaste. Mais bon, vous avez déjà scrappé un site web !
Une formation continue et une mise à jour des dernières technologies et évolutions juridiques vous permettront de naviguer dans ce monde complexe.
L'inspection visuelle et l'extraction manuelle des données d'une page HTML à l'aide de ces sélecteurs CSS et XPath peuvent non seulement prendre du temps, mais également être sujettes à des erreurs. De plus, l’extraction manuelle ou visuelle des données est totalement inadaptée à la collecte de données à grande échelle ou aux tâches de scraping répétitives. C'est là que les scripts et la programmation sont très utiles.
0Commentaires