In this ultimate guide, we will explore the world of web scraping, a powerful technique to extract data from websites. rat
Quer seja um principiante curioso sobre o conceito ou um programador experiente que procura melhorar as suas competências, este guia tem algo valioso para todos. Desde compreender as noções básicas de extração de dados HTML utilizando CSS e XPath seletores até a raspagem prática da Web com Python, temos tudo o que você precisa. Além disso, abordaremos os aspectos legais, considerações éticas e práticas recomendadas para garantir a raspagem responsável da Web.

Isenção de responsabilidade: Este material foi desenvolvido estritamente para fins informativos. Não constitui uma aprovação de quaisquer atividades (incluindo atividades ilegais), produtos ou serviços. O usuário é o único responsável pelo cumprimento das leis aplicáveis, incluindo as leis de propriedade intelectual, quando utiliza os nossos serviços ou se baseia em qualquer informação aqui contida. Não aceitamos qualquer responsabilidade por danos resultantes da utilização dos nossos serviços ou das informações aqui contidas, seja de que forma for, exceto quando explicitamente exigido por lei.
Índice.
- O que é Web Scraping e como funciona?
- Noções básicas de extração de dados HTML: Seletores CSS e XPath.
- Web Scraping com Python (+ Código).
- A raspagem da Web é legal?
- Como é que os sítios Web tentam bloquear a recolha de dados da Web?
- Práticas éticas e recomendadas para a recolha de dados na Web.
- Raspagem da Web: Perguntas frequentes (FAQ)
- Considerações Finais.
1. O que é Web Scraping e como funciona?
Web scraping (também conhecido como web harvesting ou extração de dados) é o processo de extração automática de dados de sítios Web, serviços Web e aplicações Web.
O Web scraping ajuda-nos a evitar ter de entrar em cada sítio Web e obter dados manualmente - um processo longo e ineficaz. O processo envolve a utilização de scripts ou programas automatizados. O script ou programa acede à estrutura HTML da página Web, analisa os dados e extrai os elementos específicos necessários da página para análise posterior.
a. Para que é utilizada a raspagem da Web?
O Web scraping é fantástico se for feito de forma responsável. Geralmente, pode ser utilizada para pesquisar mercados, por exemplo, para obter informações e conhecer as tendências de um mercado específico. Também é popular na monitorização da concorrência para acompanhar a sua estratégia, preços, etc.
Os casos de utilização mais específicos são:
- Plataformas sociais (Captura de dados do Facebook e do Twitter)
- Monitorização em linha das alterações de preços,
- Comentários de produtos,
- Campanhas de SEO,
- Listagens de imóveis,
- Acompanhamento de dados meteorológicos,
- Monitorizar a reputação de um sítio Web,
- Acompanhamento da disponibilidade e dos preços dos voos,
- Testar anúncios, independentemente da localização geográfica,
- Controlo dos recursos financeiros,
b. Como funciona o Web Scraping?
Os elementos típicos envolvidos na recolha de dados da Web são o iniciador e o alvo. O iniciador (web scraper) utiliza software de extração automática de dados para fazer scraping de sítios Web. Os alvos, por outro lado, são geralmente o conteúdo do sítio Web, informações de contacto, formulários ou qualquer coisa publicamente disponível na Web.
O processo típico é o seguinte:
- PASSO 1: O iniciador utiliza a ferramenta de raspagem - software (que pode ser um serviço baseado na nuvem ou um script caseiro) para começar a gerar pedidos HTTP (utilizados para interagir com sítios Web e recuperar dados). Este software pode iniciar qualquer coisa, desde um pedido HTTP GET, POST, PUT, DELETE ou HEAD, até um pedido OPTIONS para um sítio Web alvo.
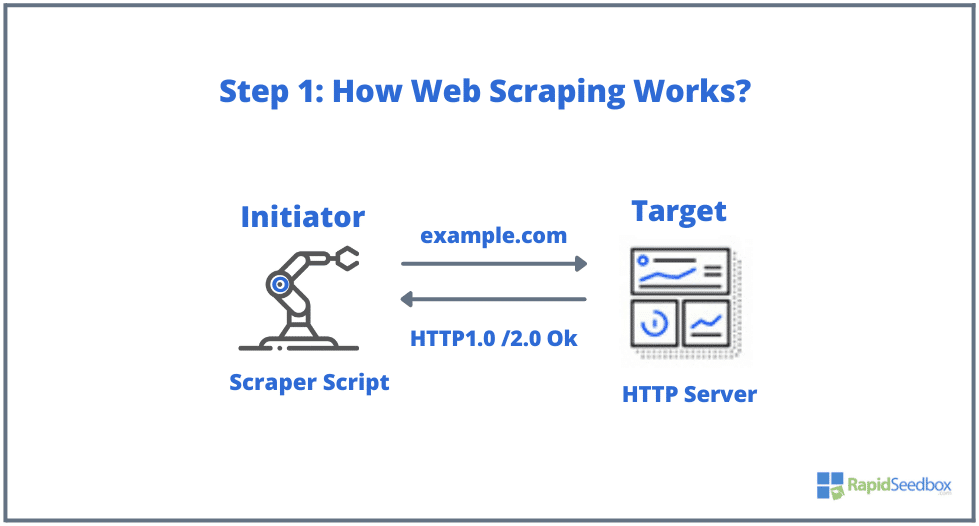
- PASSO 2. Se a página existir, o sítio Web de destino responderá ao pedido do scraper com HTTP/1.0 200 OK (a resposta típica aos visitantes). Quando o scraper recebe a resposta HTML (por exemplo, 200 OK), procede então à análise do documento e recolhe os seus dados não estruturados.
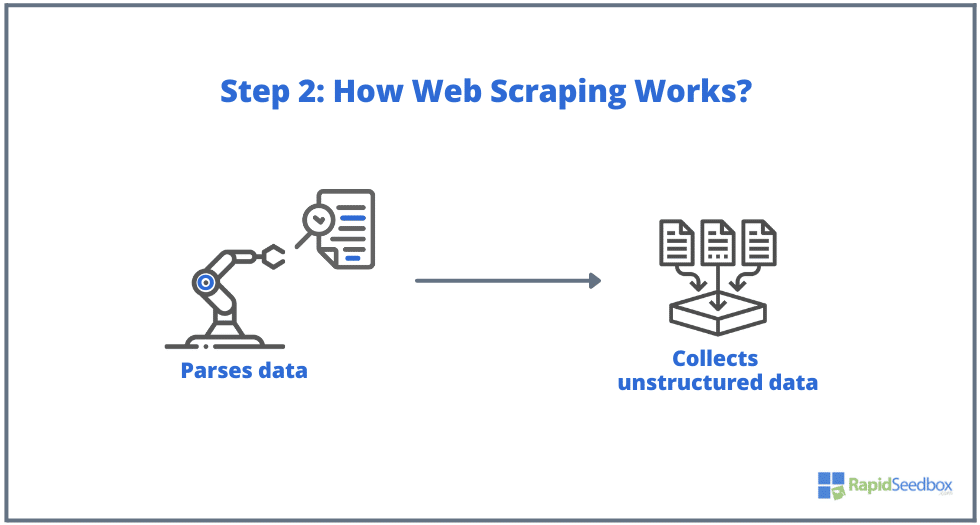
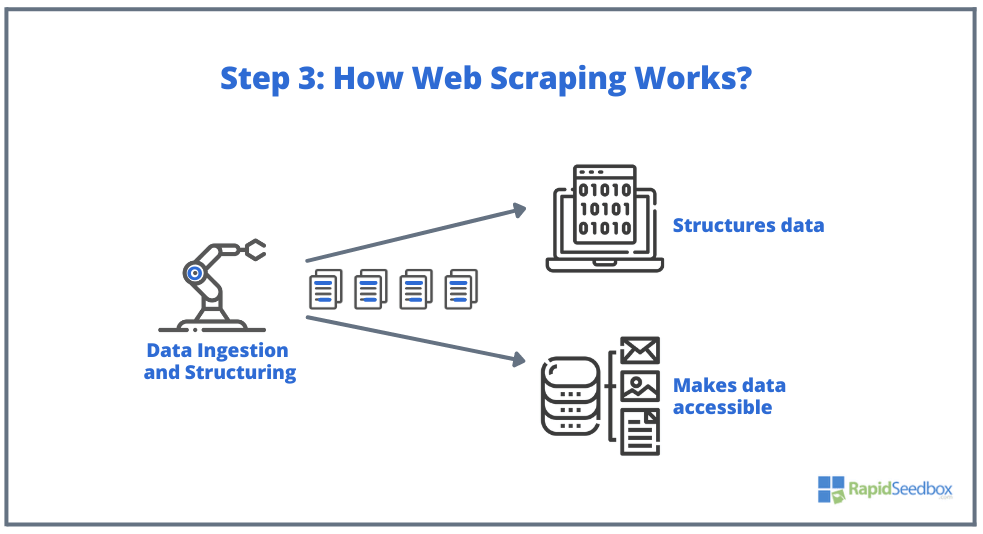
- PASSO 3. O software de recolha de dados extrai os dados em bruto, armazena-os e adiciona-lhes estrutura (índices) de acordo com o que foi especificado pelo iniciador. Os dados estruturados são acessíveis através de formatos legíveis como XLS, CSV, SQL ou XML.
2. Noções básicas de extração de dados HTML: Seletores CSS e XPath.
Talvez já saiba o básico: O Web scraping envolve a extração de dados de sítios Web, e tudo começa com HTML-a espinha dorsal das páginas Web. Num ficheiro HTML, encontrará classes e IDs, tabelas, listas, blocos ou contentores - todos os elementos básicos que constituem a estrutura de uma página.
O CSS, por outro lado, é uma linguagem de folha de estilos utilizada para controlar a apresentação e a disposição dos documentos HTML. Define a forma como os elementos HTML são apresentados numa página Web, como cores, tipos de letra, margens e posicionamento. O CSS desempenha um papel fundamental na raspagem da Web, pois ajuda a extrair dados dos elementos desejados.
Nota: Explicar em pormenor o que é HTML e CSS e como funcionam está fora do âmbito deste artigo. Partimos do princípio de que já possui os conhecimentos fundamentais de HTML e CSS.
Embora seja possível extrair dados diretamente do HTML em bruto utilizando várias técnicas, como expressões regulares, isso pode ser muito moroso e difícil. Uma vez que a linguagem estruturada do HTML foi concebida para ser "legível por máquinas", pode tornar-se muito complexa e variada. É aqui que os selectores CSS e XPath desempenham um papel fundamental.
a. Compilação e inspeção de HTML.
Na secção seguinte, forneceremos alguns exemplos de selectores CSS e XPath (compilados e inspeccionados). Todos os seguintes exemplos de HTML e CSS foram compilados com o editor online HTML-CSS-JS.
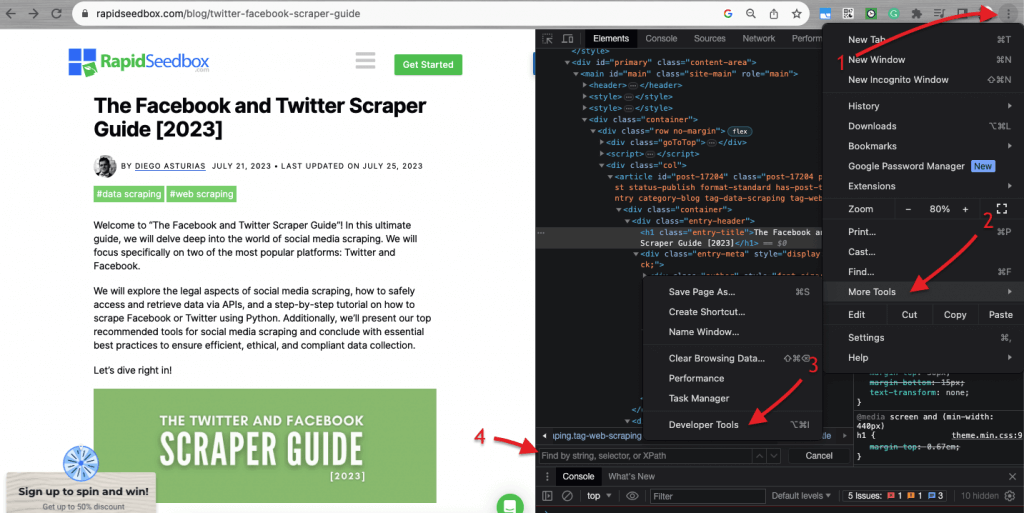
Quando se trata de inspecionar o código HTML em sítios Web, Os navegadores Web vêm com ferramentas de desenvolvimento, pelo que pode literalmente inspecionar o HTML ou CSS que está publicamente disponível em qualquer sítio Web. Pode clicar com o botão direito do rato numa página Web e selecionar "Inspecionar", "Inspecionar elemento" ou "Inspecionar fonte". Para uma melhor comparação lado a lado da página e da dinâmica do código, no navegador Chrome > aceda aos três pontos no canto superior esquerdo (1) > Mais ferramentas (2) > Ferramentas de desenvolvimento (3).
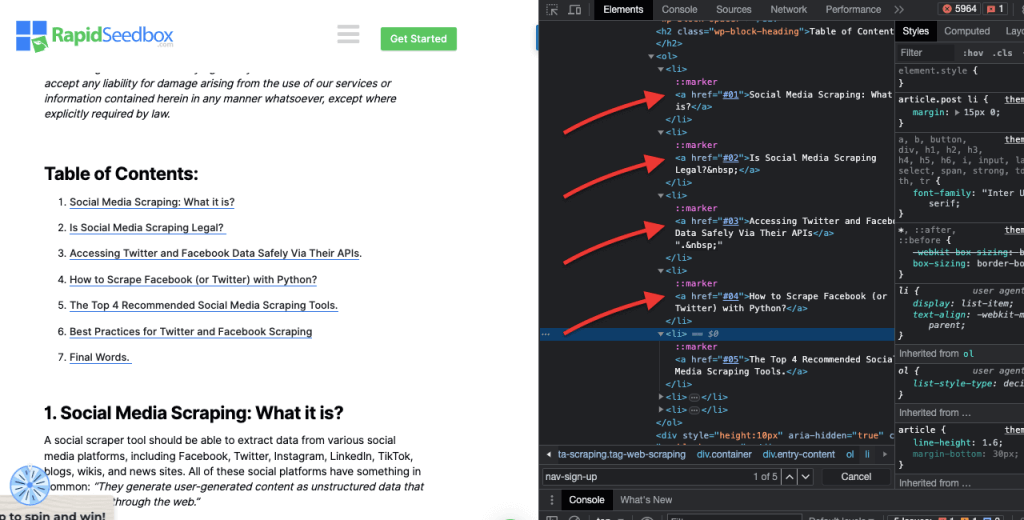
As ferramentas de desenvolvedor vêm com um filtro de pesquisa útil (4) que permite pesquisar por string, seletor ou XPath. Como exemplo, vamos extrair alguns dados de: https://www.rapidseedbox.com/blog/twitter-facebook-scraper-guide.
b. Seletores CSS:
Os selectores CSS são padrões utilizados para selecionar e direcionar os elementos HTML de uma página Web. São úteis para a extração (e estilização) da Web, uma vez que proporcionam uma forma mais eficiente e direccionada de obter dados de documentos HTML. Embora seja possível extrair dados diretamente do HTML em bruto utilizando várias técnicas, como expressões regulares, os selectores CSS oferecem várias vantagens que os tornam a escolha preferida para a extração de dados da Web.
Técnicas para direcionar e selecionar elementos HTML numa página Web:
i. Seleção de nós.
A seleção de nós é o processo de escolha de elementos HTML com base nos seus nomes de nós. Por exemplo, selecionar todos os elementos 'p' ou todos os elementos 'a' de uma página. Esta técnica permite-lhe selecionar tipos específicos de elementos no documento HTML.

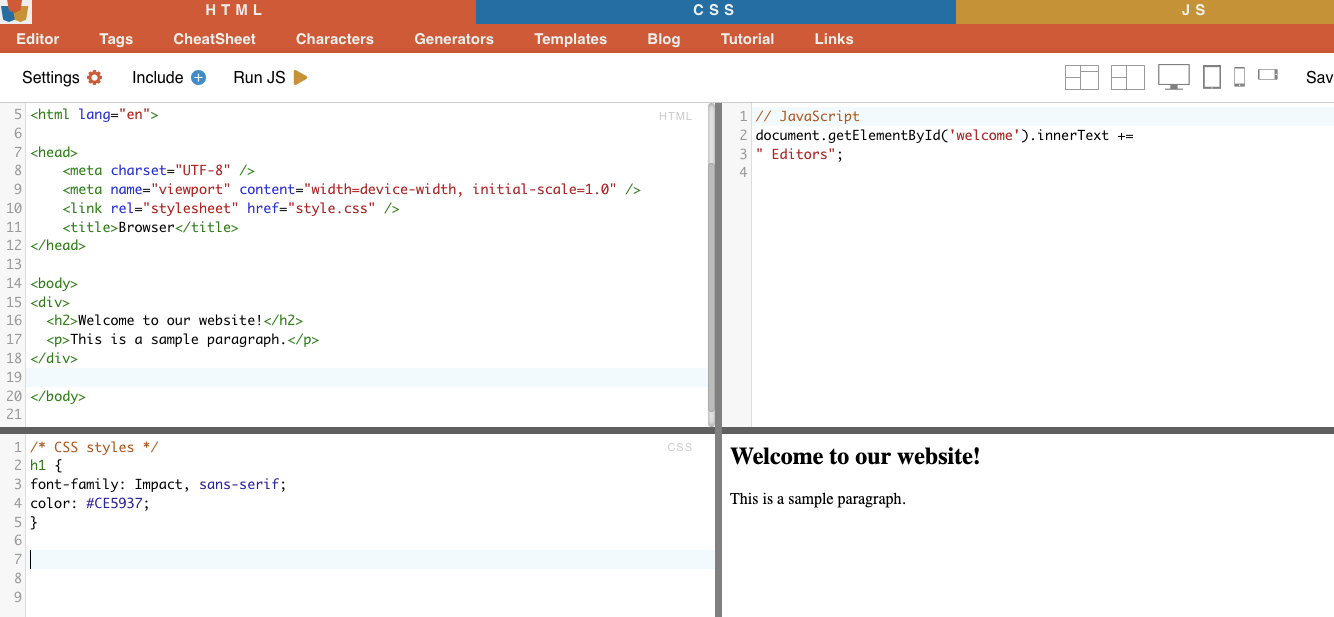
Exemplo da vida real: Pesquisa manual de H2s.
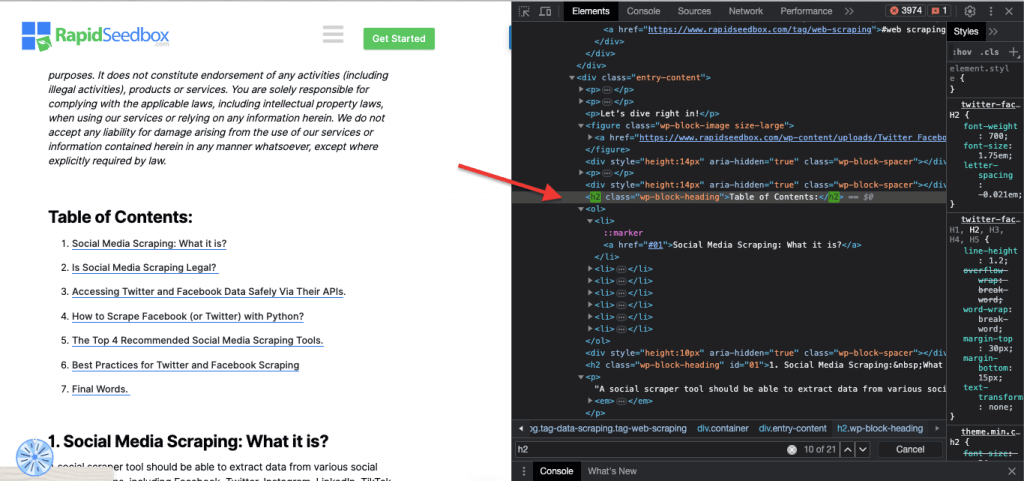
ii. Classe.
Nos Seletores CSS, a seleção de classe envolve a seleção de elementos HTML com base no atributo de classe atribuído. O atributo de classe permite-lhe aplicar um nome de classe específico a um ou mais elementos. Além disso, nos estilos CSS ou JavaScript, pode ser aplicado a todos os elementos com essa classe. Exemplos de nomes de 'classe' são botões, elementos de formulário, menus de navegação, esquemas de grelha, entre outros.
Exemplo: O seguinte seletor CSS: 'highlight' seleccionará todos os elementos com o atributo de classe definido como "highlight".


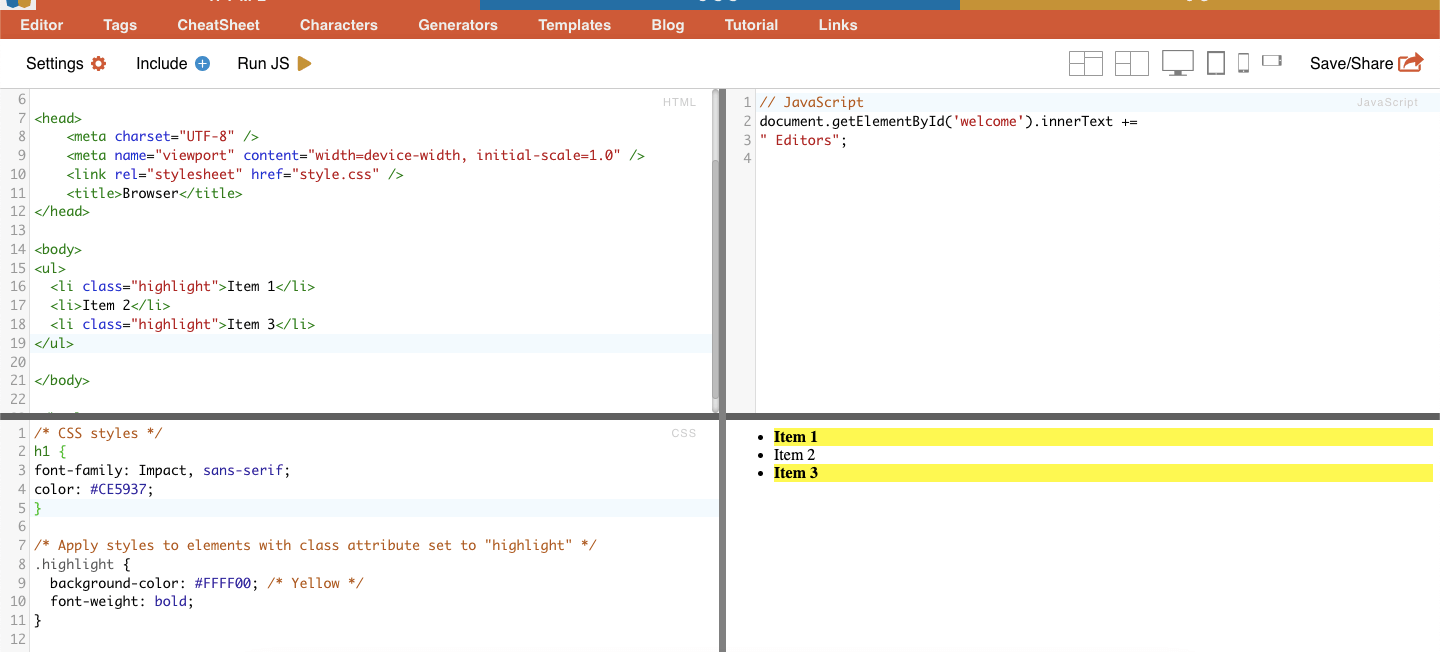
Exemplo da vida real: Pesquisa manual de turmas.
iii. Restrições de ID.
As restrições de ID ajudam a selecionar um elemento HTML com base no seu atributo de ID exclusivo. Este atributo de ID é utilizado para identificar de forma única um único elemento na página Web. Ao contrário das classes, que podem ser utilizadas em vários elementos, os IDs devem ser únicos dentro da página.
Exemplo: O seletor CSS "#header" seleccionará o elemento com o atributo ID definido como "header".


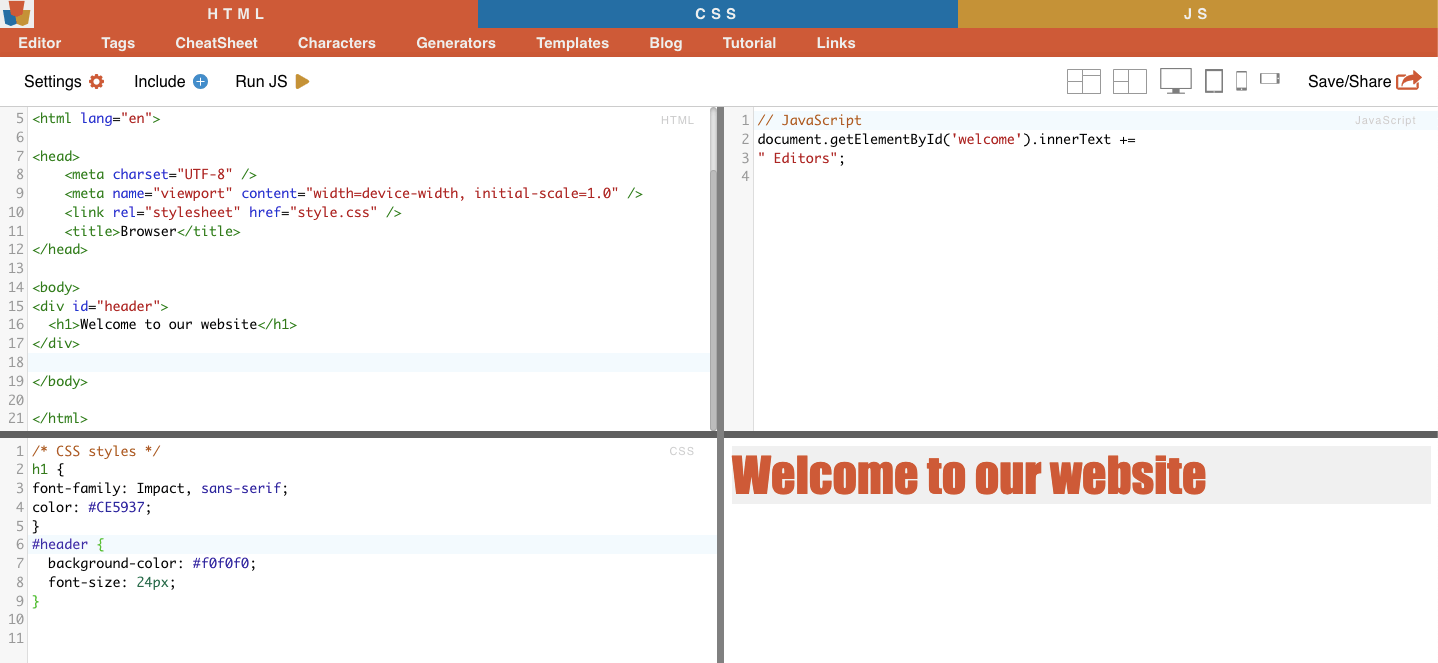
Exemplo da vida real: Procura manual de IDs. Depois de encontrar o #01, é necessário localizar o id="01″
iv. Correspondência de atributos.
Esta técnica envolve a seleção de elementos HTML com base em atributos específicos e respectivos valores. Permite-lhe selecionar elementos que tenham um determinado atributo ou valor de atributo. Existem diferentes tipos de correspondência de atributos, como a correspondência exacta, a correspondência de substring, etc.
Exemplo: O exemplo seguinte mostra um atributo personalizado denominado tipo de dados. Para direcionar ou estilizar determinados itens (por exemplo, itens de lista marcados como "fruta"), pode utilizar o seletor CSS que selecciona elementos com base nos seus valores de atributo.
Para recolher apenas os itens marcados como "fruta", pode utilizar o seguinte seletor CSS:

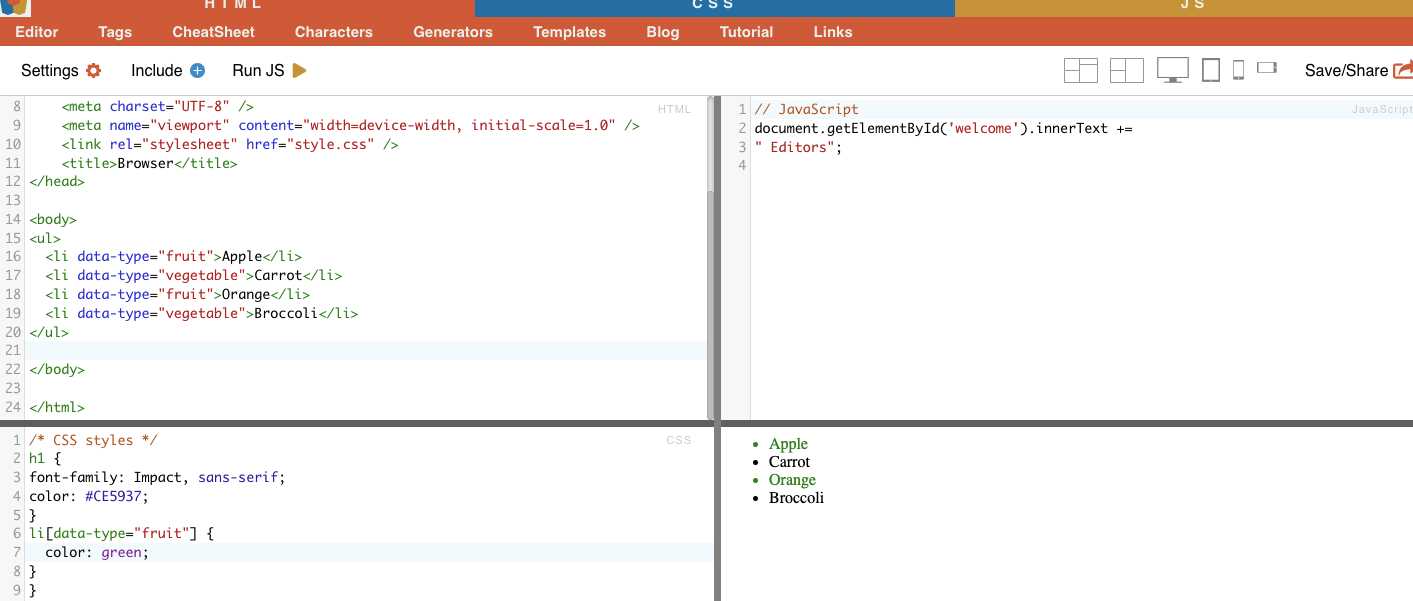
Exemplo da vida real: Pesquisa manual de atributos.
c. Selectores Xpath:
Os seletores CSS são ideais para tarefas diretas de raspagem da Web em que a estrutura HTML é relativamente simples. Mas quando a estrutura HTML se torna mais intrincada e complexa, existe outra solução: Os selectores XPath.
Seletores XPath (seletores de linguagem de caminho XML) é uma linguagem de caminho flexível utilizada para navegar através dos elementos de um documento XML ou HTML. Ajudam a selecionar nós específicos no código HTML com base na localização, nomes, atributos ou conteúdo. Os selectores XPath também podem ser úteis para selecionar elementos com base nos seus atributos de classe e ID.
Eis três exemplos de selectores XPath para recolha de dados da Web.
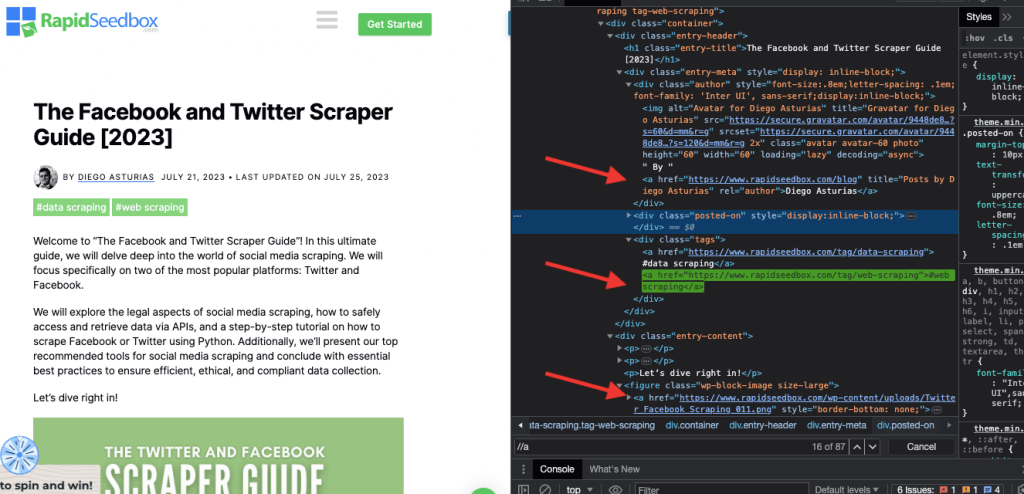
i. Exemplo 1: Expressão XPath: ' //a
A expressão XPath ' //a' selecciona todos os elementos '' na página, independentemente da sua localização no documento. A seguinte captura de ecrã mostra a localização manual de todos os elementos '' na página.
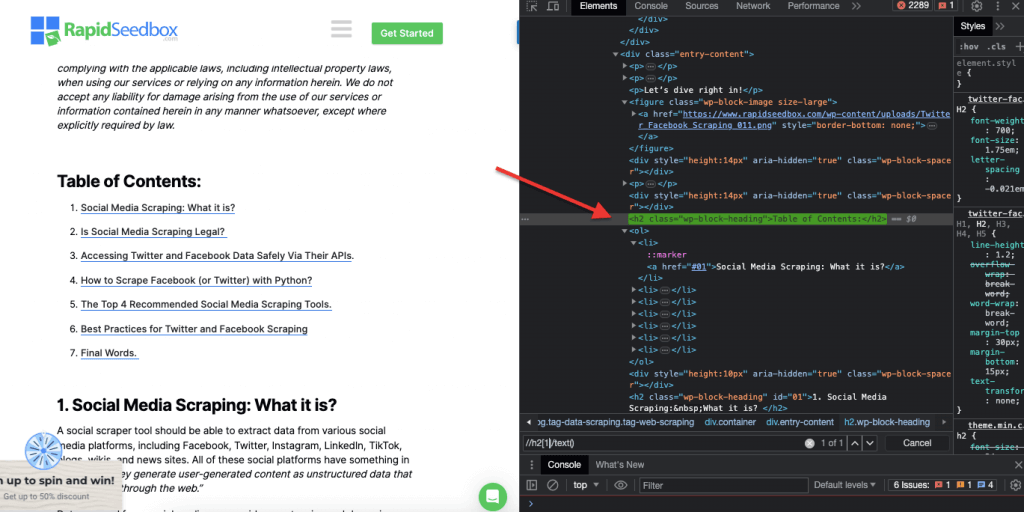
ii. Exemplo 2: ' //h2[1]/text()'
A expressão XPath:
' //h2[1]/text() '
Seleccionará o conteúdo de texto do primeiro título h2 na página. O índice '[1]' é utilizado para especificar a primeira ocorrência do elemento h2, pode também especificar a segunda ocorrência com o índice '[2]', e assim por diante. A seguinte captura de ecrã mostra a localização manual do primeiro título h2 na página utilizando este seletor XPath.
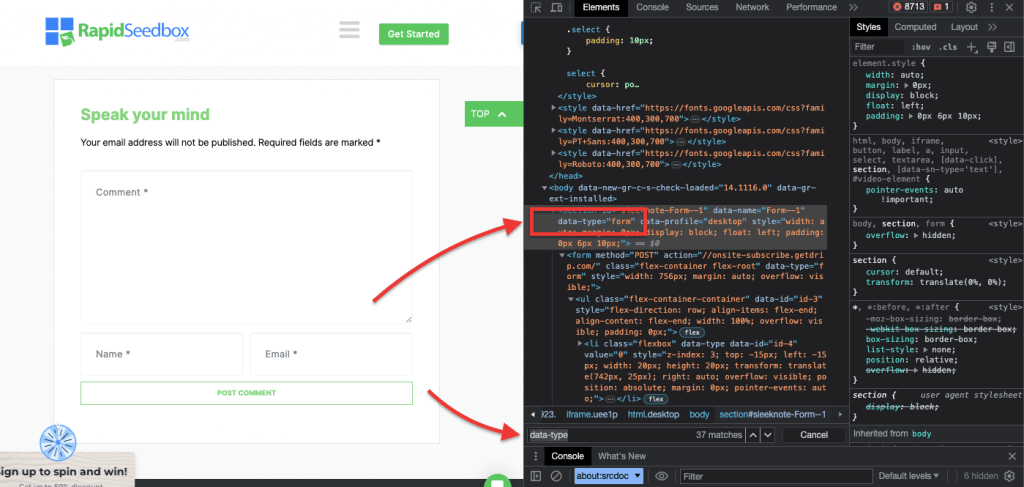
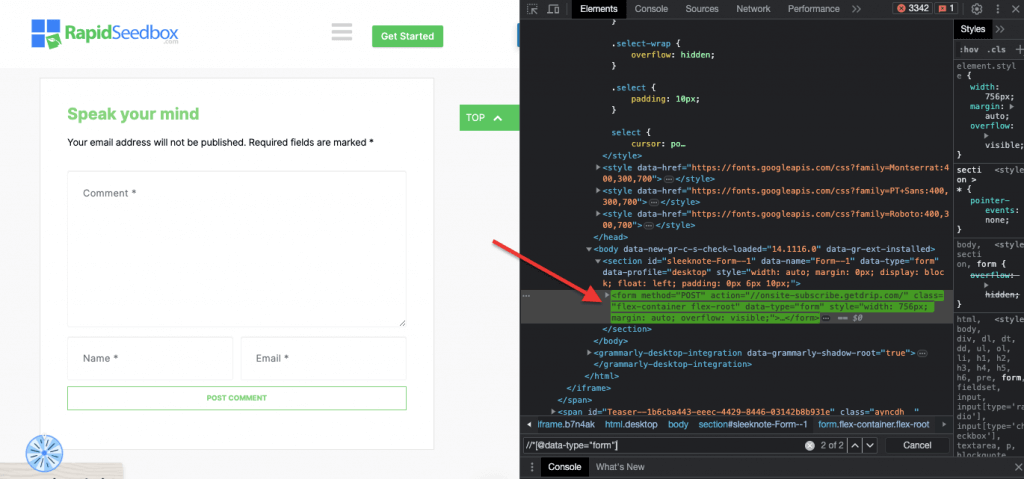
iii. Exemplo 3. ' //* [@data-type="form"]'
A expressão XPath //* [@data-type="form"] selecciona todos os elementos que têm um atributo de dados com o valor "form". O * indica que qualquer elemento com o atributo de dados especificado será selecionado, independentemente do seu nome de nó. A seguinte captura de ecrã mostra o processo de localização manual dos elementos com o valor "form".
A inspeção visual e a extração manual de dados de uma página HTML utilizando estes selectores CSS e XPath pode não só ser morosa como também propensa a erros. Além disso, a extração manual ou visual de dados é completamente inadequada para a recolha de dados em grande escala ou para tarefas de raspagem repetitivas. É aqui que o scripting e a programação são altamente benéficos.
Impulsione o seu web scraping com proxies rápidos, seguros e anónimos da RapidSeedbox.
Quais são as melhores linguagens de programação para a recolha de dados da Web?
A linguagem de programação mais popular para scraping é Python devido às suas bibliotecas e pacotes (mais sobre isto na próxima secção). Outra linguagem de programação popular para a raspagem da Web é Rpois este também possui um conjunto fantástico de bibliotecas e estruturas suportadas. Além disso, também vale a pena mencionar o C# - uma linguagem de programação popular que muitos raspadores da Web utilizam. Sites como o ZenRows têm guias completos sobre como extrair dados de um sítio web em C#o que torna mais fácil para os programadores compreenderem o processo e iniciarem os seus próprios projectos.
Por uma questão de simplicidade, este guia de web scraping centrar-se-á no web scraping com Python. Continue a ler!
3. Web Scraping com Python (com código).
Por que razão inspeccionaria visualmente e extrairia manualmente dados HTML utilizando selectores CSS ou selectores XPath quando pode utilizá-los de forma sistemática e automática com linguagens de programação?
Existem muitas bibliotecas e estruturas populares de recolha de dados da Web que suportam selectores CSS para facilitar a extração de dados. Uma das linguagens de programação mais populares para a extração de dados da Web é a Python, para as suas bibliotecas como Bela Sopa, Pedidos, CSS-Select, Selénio, e Scrapy. Estas bibliotecas permitem aos web scrapers tirar partido dos selectores CSS e XPath para extrair dados de forma eficiente.
Bela sopa.
O BeautifulSoup é um dos mais populares e poderosos pacotes Python concebidos para analisar documentos HTML e XML. Este pacote cria uma árvore de análise das páginas, permitindo-lhe extrair facilmente dados de HTML.
| Um facto interessante! Na luta contra a COVID-19, DXY-COVID-19-Crawler de Jiabao Lin utilizou a BeautifulSoup para extrair dados valiosos de um sítio Web médico chinês. Ao fazê-lo, ajudou os investigadores a monitorizar e a compreender a propagação do vírus. [Fonte] |
Pedidos.
O Pedidos é uma biblioteca HTTP simples mas poderosa. É útil para efetuar pedidos HTTP para obter dados de sítios Web. "Requests" simplifica o processo de envio de pedidos HTTP e o tratamento de respostas no seu projeto Python de recolha de dados da Web.
a. Tutorial para Web Scraping com Python (+ Código)
Neste tutorial de web scraping com Python, vamos obter dados de um site HTML de destino usando o código Python com os "requests" e a biblioteca BeautifulSoup.
Pré-requisitos:
Certifique-se de que os seguintes pré-requisitos são cumpridos:
- Ambiente Python: Certifique-se de que tem Python instalado no seu computador. Além disso, certifique-se de que pode executar o script no seu ambiente Python preferido (por exemplo, IDLE ou Bloco de notas Jupyter).
- Biblioteca de pedidos: Instalar o
pedidosbiblioteca. É utilizada para enviar pedidos HTTP GET para o URL especificado. Pode instalá-la utilizandotubagemcorrendopip install pedidosno seu prompt de comando ou terminal. - Biblioteca BeautifulSoup: Instalar o
beautifulsoup4biblioteca. Pode instalá-la utilizandotubagemcorrendopip install beautifulsoup4no seu terminal.
O código Python para a recolha de dados de uma página (com BeautifulSoup)
O script seguinte vai buscar o URL especificado, analisar o conteúdo HTML utilizando o BeautifulSoup e imprimir os títulos dos principais artigos de notícias na página Web.

Ao executar o script no Shell IDLE, o ecrã imprime todos os "news_titles" recolhidos do site visado.

b. Variações do nosso código Python para raspagem da web.
Podemos pegar no nosso código Python de recolha de dados da Web anterior e fazer algumas variações para recolher diferentes tipos de dados.
Por exemplo:
- Encontrar imagens: Para encontrar todas as etiquetas de imagem (
) na página Web, pode utilizar o método find_all() com o nome da etiqueta 'img':

- Encontrar ligações: Para encontrar todas as etiquetas âncora () que representam ligações na página Web, pode utilizar o método find_all() com o nome da etiqueta 'a':

O script fornecido (juntamente com variações) é um script básico de raspagem da Web. Simplesmente extrai e imprime os títulos dos principais artigos de notícias a partir do URL especificado. Mas, infelizmente, este script simples carece de muitas funcionalidades que compõem um projeto de recolha de dados da Web mais abrangente. Há vários elementos que pode querer considerar, nomeadamente o armazenamento de dados, o tratamento de erros, a paginação/rastreio, a utilização de agentes de utilizador e cabeçalhos, as medidas de limitação e de cortesia e a capacidade de tratar conteúdos dinâmicos.
4. A raspagem da Web é legal?
A recolha de dados da Web é geralmente vista como controversa ou ilegal. Mas, na realidade, trata-se de uma prática legítima que, se respeitar certos limites éticos e legais, é perfeitamente legal.
A legalidade da raspagem da Web depende da natureza dos dados que estão a ser extraídos e dos métodos utilizados. A raspagem da Web é considerada legal quando é utilizada para recolher informações publicamente disponíveis na Internet. No entanto, é sempre necessário ter cuidado, especialmente quando se trata de dados pessoais ou de conteúdos protegidos por direitos de autor.
Eis algumas indicações a ter em conta:
- Não recolher dados privados. Também é ilegal extrair dados que não estejam publicamente disponíveis. A extração de dados por detrás de uma página de início de sessão, com início de sessão de utilizador e palavra-passe, é contra a lei nos EUA, Canadá e na maior parte da Europa.
- O que se faz com os dados é que pode causar problemas. A raspagem ética da Web implica ter em atenção os dados que estão a ser recolhidos e o fim a que se destinam. Deve ser dada especial atenção aos dados pessoais e à propriedade intelectual. Certifique-se de que está a cumprir regulamentos como o RGPD e a CCPA, que regem o tratamento de dados pessoais. Por exemplo, a reutilização ou revenda de conteúdos ou o descarregamento de material protegido por direitos de autor é ilegal (e deve ser evitado).
- É também essencial rever os Termos de Serviço dos sítios Web. Trata-se de documentos que indicam a qualquer pessoa que utilize o seu serviço ou conteúdo a forma como deve ou não interagir com os recursos.
- Garanta sempre alternativas como a utilização de APIs fornecidas oficialmente. Some websites like Government agencies, Weather, and Social media platforms make some of their data accessible to the public via APIs.
- Considere a possibilidade de verificar o ficheiro robots.txt. This file is saved on the web server and gives directions to web crawlers and web scraping about what parts of a website to avoid and what parts are authorized. It also gives directions about the rate limits.
- Evitar iniciar ataques de raspagem da Web. Dependendo do contexto, por vezes a raspagem da Web é referida como um ataque de raspagem. Quando os spammers utilizam botnets (exércitos de bots) para atacar um sítio Web com pedidos grandes e rápidos, todo o serviço do sítio Web pode falhar. Os ataques de raspagem de dados em grande escala podem deitar abaixo sítios inteiros.
Notícias recentes sobre os aspectos jurídicos da raspagem da Web.
Decisões jurídicas recentes clarificaram que a recolha de dados publicamente disponíveis não é geralmente considerada uma violação. Uma decisão histórica do tribunal de recurso dos EUA reafirmou a legalidade da recolha de dados na Web, declarando que a recolha de dados acessíveis ao público na Internet não viola a Lei sobre Fraude e Abuso de Computadores (CFAA) [fonte TechCrunch].
Noutras notícias, os recentes processos judiciais contra a OpenAI e a Microsoft põem em evidência as preocupações com a privacidade, a propriedade intelectual e as leis anti-hacking, de acordo com notícias recentes [Bloomberg]. Embora a CFAA tenha uma eficácia limitada, estão a ser exploradas as reivindicações de violação de contrato e as leis estatais em matéria de privacidade. A interação entre os direitos de autor e o direito dos contratos continua por resolver, deixando muitas questões por responder no contexto da raspagem da Web.
Nas últimas notícias, [fonte: IndiaTimes] Elon Musk está a alterar as regras do Twitter para evitar níveis extremos de recolha de dados. De acordo com Musk, o "web scraping" extremo tem um impacto negativo na experiência do utilizador. Ele sugeriu que a culpa é das organizações que usam modelos de linguagem grandes para IA generativa.
5. Como é que os sítios Web tentam bloquear a raspagem da Web?
As empresas querem que alguns dos seus dados sejam acessíveis a visitantes humanos. Mas quando as empresas ou os utilizadores utilizam scripts ou bots automatizados para extrair dados do sítio de forma agressiva, pode haver muita privacidade e abuso de recursos num servidor e página Web alvo. Estes sítios vítimas preferem impedir este tipo de tráfego.
Técnicas anti-scraping.
- Quantidades invulgares e elevadas de tráfego provenientes de uma única fonte. Os servidores Web podem utilizar WAFs (Web Application Firewalls) com listas negras de endereços IP ruidosos para bloquear o tráfego, filtros para taxas e tamanhos "invulgares" de pedidos e mecanismos de filtragem. Alguns sítios utilizam uma combinação de WAF e CDN (Content Delivery Networks) para filtrar totalmente ou reduzir o ruído desses IPs.
- Alguns sítios Web podem detetar padrões de navegação do tipo bot. À semelhança da técnica anterior, os sítios Web também bloqueiam pedidos com base no User-Agent (cabeçalho HTTP). Os bots não utilizam um browser normal. Estes bots têm diferentes sequências de user-agent (ou seja, crawler, spider ou bot), uma falta de variação, uma ausência de cabeçalhos (navegadores sem cabeça), solicitar taxas e muito mais.
- Os sítios Web também alteram frequentemente a sua marcação HTML. Os bots de raspagem da Web seguem uma rota consistente de "marcação HTML" ao percorrerem o conteúdo de um sítio Web. Alguns sítios Web alteram os elementos HTML dentro da marcação de forma regular e aleatória. Esta técnica afasta um bot do seu hábito ou horário regular de scraping. Alterar a marcação HTML não impede a raspagem da Web, mas torna-a muito mais difícil.
- A utilização de desafios como o CAPTCHA. Para evitar que os bots utilizem navegadores sem cabeça, alguns sítios Web exigem desafios CAPTCHA. Os robots que utilizam browsers sem cabeça têm dificuldade em resolver este tipo de desafios. Os CAPTCHAs foram criados para serem resolvidos ao nível do utilizador (através do browser) e não por robôs.
- Alguns sítios são armadilhas (honeypots) para bots de raspagem. Alguns sítios Web são criados apenas para apanhar bots de raspagem - esta é uma técnica designada por honeypots. Estes honeypots só são visíveis por bots de raspagem (e não por visitantes humanos comuns) e são construídos para conduzir os web scrapers a uma armadilha.
6. Práticas éticas e recomendadas para a raspagem da Web.
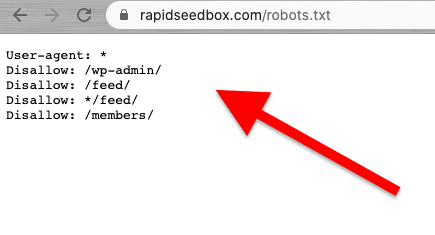
A recolha de dados da Web deve ser feita de forma responsável e ética. Como já foi referido, a leitura dos Termos e Condições ou ToS deve dar-lhe uma ideia das restrições a que tem de obedecer. Se quiser ter uma ideia das regras de um Web crawler, consulte o seu ROBOTS.txt.
Se a recolha de dados da Web for totalmente proibida ou bloqueada, utilize a sua API (se estiver disponível).
Além disso, tenha em atenção a largura de banda do sítio Web de destino para evitar sobrecarregar um servidor com demasiados pedidos. É crucial automatizar os pedidos com uma taxa e tempos limite correctos para evitar sobrecarregar o servidor de destino. Simular um utilizador em tempo real deve ser o ideal. Além disso, nunca recolha dados atrás de páginas de início de sessão.
Siga as regras e não terá problemas.
Melhores práticas de raspagem da Web.
- Utilizar um proxy. Um proxy é um servidor intermediário que encaminha pedidos. Ao fazer web scraping com um proxy, está a encaminhar o seu pedido original através dele. Assim, o proxy mapeia o pedido com o seu próprio IP e encaminha-o para o sítio Web de destino. Use um proxy para:
- Elimine as hipóteses de o seu IP ser colocado na lista negra ou bloqueado. Fazer sempre pedidos através de vários proxies- Proxies IPv6 são um bom exemplo. Um pool de proxy pode ajudá-lo a efetuar pedidos de maior volume sem ser bloqueado.
- Contornar o conteúdo geo-tailored. Um proxy numa região específica é útil para extrair dados de acordo com essa região geográfica específica. Isto é útil quando os sítios Web e os serviços estão atrás de um CDN.
- Proxies rotativos. Proxies rotativos pegam (rodam) um novo IP do pool para cada nova conexão. Tenha em mente que As VPN não são proxies. Embora façam algo muito semelhante, que é proporcionar o anonimato, funcionam a níveis diferentes.
- Rodar UA (User Agents) e cabeçalhos de pedidos HTTP. Para rodar UAs e cabeçalhos HTTP, é necessário recolher uma lista de cadeias de UA de navegadores Web reais. Coloque a lista no seu código de recolha de dados da Web em Python e defina pedidos para escolher cadeias aleatórias.
- Não ultrapasse os limites. Diminuir o número de pedidos, rodar e aleatorizar. Se estiver a fazer um grande número de pedidos para um Web site, comece por aleatorizar as coisas. Faça com que cada pedido pareça aleatório e humano. Primeiro, altere o IP de cada pedido com a ajuda de proxies rotativos. Além disso, use cabeçalhos HTTP diferentes para fazer com que pareça que os pedidos estão a vir de outros navegadores.
Impulsione o seu web scraping com proxies rápidos, seguros e anónimos da RapidSeedbox.
7. FAQ sobre Web Scraping: Perguntas mais frequentes.
a. O que é o robots.txt e qual o seu papel na recolha de dados da Web?
O robots.txt serve como ferramenta de comunicação entre proprietários de sítios Web, rastreadores da Web e "scrapers". Trata-se de um ficheiro de texto colocado no servidor de um sítio Web que fornece instruções aos robôs da Web (crawlers, web spiders e outros bots automatizados) sobre as partes do sítio Web a que podem aceder e fazer scraping e as partes que devem evitar. Os web crawlers "bem comportados" (como o Googlebot) foram concebidos para ler automaticamente o robots.txt. Os scrapers não foram concebidos para ler este ficheiro. Assim, ter conhecimento do ficheiro robots.txt é muito importante para respeitar os desejos do proprietário do sítio Web.
b. Que técnicas utilizam os administradores de sítios Web para evitar tentativas "abusivas" ou "não autorizadas" de recolha de dados da Web?
Nem todos os scrapers extraem dados de forma ética e legal. Não cumprem os TOS (Termos de Serviço) do sítio ou as directrizes do robots.txt. Por isso, os administradores do sítio podem tomar medidas adicionais para proteger os seus dados e recursos, como o bloqueio de IP ou desafios CAPTCHA. Podem também utilizar medidas de limitação de taxas, verificação do agente do utilizador (para identificar potenciais bots), rastrear sessões, utilizar autenticação baseada em tokens, utilizar CDN (Content Delivery Networks) ou mesmo utilizar sistemas de deteção baseados no comportamento.
c. Web Scraping vs. Web Crawling?
Although web scraping and web crawling are both web data extraction techniques, they have different purposes, scopes, automation, and legal aspects. On the one hand, web scraping techniques aim to extract specific data from particular sites. They are targeted and have a specific, limited scope. Web scraping uses automated scripts or third-party tools to request, receive, parse, extract, and structure data. Web crawling techniques (like list crawling), on the other hand, are used to systematically search the web. They are popular among search engines (broader scope), social media platforms, researchers, content aggregators, etc. Web crawlers can visit many sites automatically (via bots, crawlers, or spiders), build a list, index data (create a copy), and store it in a database. Web crawlers usually check the ROBOTS.txt files.
d. Extração de dados vs raspagem de dados: Quais são as suas diferenças e semelhanças?
Tanto a extração de dados como a raspagem de dados envolvem a extração de dados. No entanto, a extração de dados centra-se na utilização de técnicas estatísticas e de aprendizagem automática para analisar conjuntos de dados estruturados. O seu objetivo é identificar padrões, relações e conhecimentos em conjuntos de dados estruturados grandes e complexos. A extração de dados, por outro lado, centra-se na "parte de recolha" de informações específicas de páginas e sítios Web. Ambas as técnicas e ferramentas podem ser utilizadas em conjunto. A raspagem da Web pode ser um passo preliminar para recolher dados da Web, que são depois introduzidos em algoritmos de extração de dados para uma análise aprofundada e descoberta de conhecimentos.
e. O que é o Screen Scraping? E qual a sua relação com o Data Scraping?
Ambas as técnicas se centram na extração de dados, mas diferem no tipo de dados que extraem. Raspagem do ecrã visam capturar e extrair "automaticamente" dados visuais apresentados em sítios Web e documentos, incluindo texto no ecrã. Ao contrário da raspagem da Web, que analisa dados do HTML (extraindo assim uma vasta gama de dados da Web), a raspagem do ecrã lê dados de texto diretamente do ecrã.
f. Web Harvesting é o mesmo que Web Scraping?
A recolha de dados e a recolha na Web estão fortemente relacionadas e são frequentemente utilizadas como sinónimos, mas não são o mesmo conceito. A recolha na Web tem uma conotação mais ampla. Engloba diferentes métodos de extração de dados da Web, incluindo vários mecanismos automáticos de extração da Web, como o web scraping. Uma distinção clara é que a colheita na Web é frequentemente utilizada quando está envolvida uma API, em vez de analisar diretamente o código HTML das páginas Web (como faz a raspagem da Web).
g. Seletor CSS vs Seletor XPath: Quais são as diferenças quando se faz scraping?
Os selectores CSS são uma forma eficiente de extrair dados durante a recolha de dados da Web. Oferecem uma sintaxe simples e funcionam bem na maioria dos cenários de recolha de dados. No entanto, em casos mais complexos ou quando se lida com estruturas aninhadas, os selectores XPath podem fornecer flexibilidade e funcionalidade adicionais.
h. Como lidar com sítios Web dinâmicos com o Selenium?
O Selenium é uma ferramenta poderosa para a recolha de dados de sítios Web dinâmicos. Permite-lhe interagir com elementos na página Web como um utilizador humano o faria. Esta capacidade permite ao seu "script" navegar através de conteúdos gerados dinamicamente. Ao utilizar o WebDriver do SeleniumSe o JavaScript for utilizado, pode esperar que os elementos da página sejam carregados, interagir com elementos AJAX e extrair dados de sítios Web que dependem fortemente do JavaScript.
i. Como lidar com AJAX e JavaScript durante o Web Scraping?
Ao lidar com AJAX e JavaScript durante a raspagem da Web, as bibliotecas tradicionais, como Requests e Beautiful Soup, podem não ser suficientes. Para lidar com solicitações AJAX e conteúdo renderizado em JavaScript, é possível usar ferramentas como Selenium ou navegadores sem cabeça, como Marionetista.
8. Considerações Finais
Parabéns! Está a completar o guia definitivo para a recolha de dados da Web!
Esperamos que este guia o tenha dotado dos conhecimentos e ferramentas necessários para aproveitar o potencial da recolha de dados da Web para os seus projectos.
Lembrem-se, com grande poder vem grande responsabilidade. Ao iniciar a sua jornada na recolha de dados da Web, dê sempre prioridade às práticas éticas, respeite os termos de serviço dos sítios Web e tenha em atenção a privacidade dos dados.
Tocámos na ponta do icebergue. O Web Scraping pode ser um tópico bastante abrangente. Mas, ei, já fizeste scraping de um site!
A aprendizagem contínua e a atualização das últimas tecnologias e desenvolvimentos jurídicos permitir-lhe-ão navegar neste mundo complexo.
A inspeção visual e a extração manual de dados de uma página HTML utilizando estes selectores CSS e XPath pode não só ser morosa como também propensa a erros. Além disso, a extração manual ou visual de dados é completamente inadequada para a recolha de dados em grande escala ou para tarefas de raspagem repetitivas. É aqui que o scripting e a programação são altamente benéficos.
0Comentários