High-volume scraping breaks when IPs get flagged. E-commerce data teams feel this pain every day. But with the right proxy stack—especially real-device Mobile Proxies and high-trust Residential IPs—you can keep pipelines running, even under heavy anti-bot pressure.
Table of Contents
- Introduction
- How Web Scraping Without Getting Blocked Actually Works
- Why This Matters for Business Outcomes
- How RapidSeedbox Helps You Scrape Without Getting Blocked
- FAQ: Web Scraping Without Getting Blocked
1. Introduction
If your platform depends on price tracking or retail intelligence at scale, you’ve already hit the wall: scrapers break.
This is not because your code is bad, but because the internet is becoming harder to access at machine speed. Examples are anti-bot filters that change fast or IP reputations that shift without warning. What worked last month collapses after one aggressive update.
And when it comes to business decision-making, this is more than annoying. A blocked scraper isn’t just a failed job, but it also means missing data and broken dashboards. Executives asking why yesterday’s numbers don’t match today’s.
The biggest pains usually show up like this:
- High block rates & CAPTCHAs that freeze your scrapers mid-run and crush your pipeline reliability.
- Inconsistent data from IP reputation issues, unstable ASNs, or sudden anti-bot updates that force expensive re-runs or rebuilds.
The following diagram shows what happens when a scraper connects to websites without using proxies. Because all requests come from a single IP (or network) with suspicious headers or high request volume, websites quickly flag the traffic as automated. The result is predictable: IP blocks, CAPTCHAs, 429 errors, and full access denial, breaking the data pipeline.
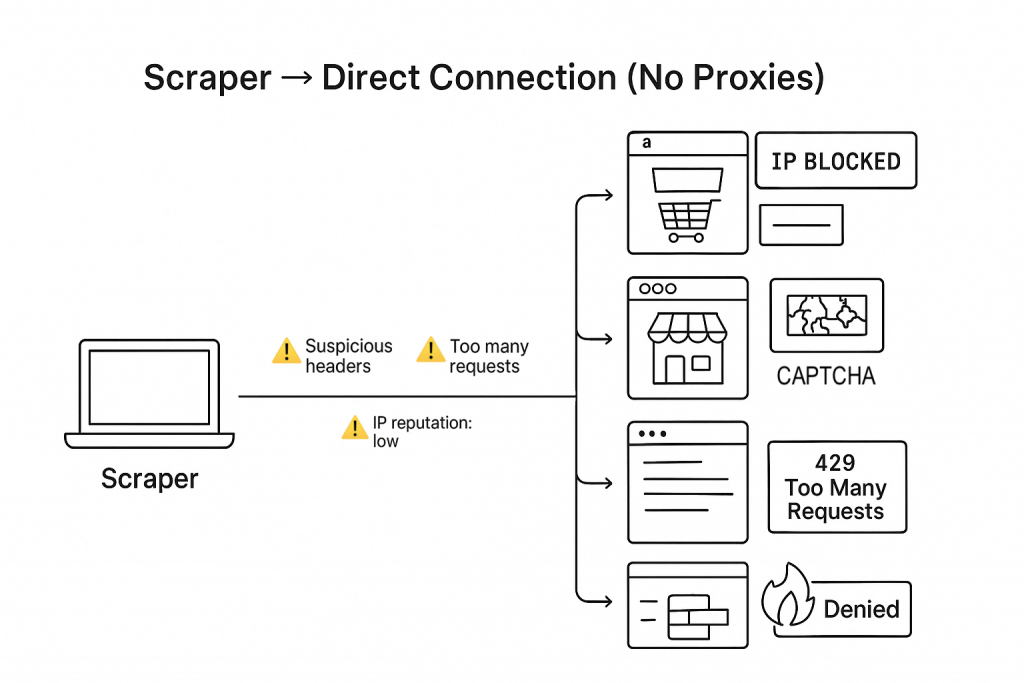
The cost isn’t only technical. Teams lose trust in their own data flow. Leaders hesitate to scale because the foundation crumbles.
Let’s fix that.
2. How Web Scraping Without Getting Blocked Actually Works
Building a scraper that stays alive under real-world anti-bot systems requires more than just “using rotating proxies.” But it’s also architecture. Think: a defensive perimeter around every request.
At the core, you need four layers working together:
- Proxy diversification: Mixing residential and mobile IPs
- Fingerprint and header realism: Modern Playwright/Selenium profiles
- Session persistence: Cookies, tokens, and identity reuse
- Dynamic throttling: Speed that adapts to the site, not your schedule
A typical modern Python stack uses Playwright for fingerprint realism, Scrapy for structure, and a dedicated proxy engine for rotation. With the right IP layer (especially real-device Mobile Proxies from RSB) you bypass hard blocks because mobile carriers rotate IPs naturally and have extremely high trust scores.
Here’s a simple Python example rotating authenticated sessions:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
from playwright.sync_api import sync_playwright with sync_playwright() as p: browser = p.firefox.launch( proxy={"server": PROXY} ) page = browser.new_page() page.goto("https://target-website.com") print(page.content()) browser.close() |
This setup avoids basic fingerprint blocks and respects the identity of the session. It also uses a clean/trusted IP footprint.
When you scale this—multi-geo rotation, rate adaptation, cookie reuse—you build a scraper that behaves like thousands of real users instead of one loud bot.
Prevent IP Blocking with Trust 🌍
Clean residential IPs help requests appear natural, keeping your scrapers steady even during heavy runs.
Try Residential IPs3. Why This Matters for Business Outcomes
Technical strength is good but having a predictable output is a lot better.
Yes, a stable scraping pipeline is about the requests; but it’s also about the business that depends on those requests.
This is where Mobile Proxies and Residential Proxy Pool shine:
- Mobile Proxies → toughest anti-bot evasion (real phones, real carriers)
- Residential Proxies → high-trust, globally distributed, ideal for large structured workloads
Both help the CTO or data lead run pipelines that feel… reliable. But also pipelines that are quiet and predictable. That’s the real win.
Business Results Checklist
A solid scraping setup creates smoother operations and cleaner data flow across the entire team. When the proxy layer stays stable, everything above it becomes easier to manage—fewer surprises and far more confidence in the pipeline.
- Fewer blocks
- Higher success rates
- Lower total cost
- Faster pipelines
- Cleaner datasets
- Predictable scaling
- Less DevOps firefighting
- More stable automation
- Better forecasting
- Higher ROI on data operations
| ⚡ Verdict: A trusted proxy foundation removes noise and keeps your scraping pipeline running in a steady rhythm. It’s the kind of stability every CTO wishes they had sooner. |
4. How RapidSeedbox Helps You Scrape Without Getting Blocked
When your data pipeline depends on reliable scraping, the last thing you want is an IP ban, a CAPTCHA wall, or a broken session in the middle of a job. RapidSeedbox gives you the proxy infrastructure built for real-world scale global coverage, and the speed to keep your automation running without friction. Everything is designed so your team can focus on extracting insights (not fighting blocks).
The following diagram shows how a proxy network like RapidSeedbox rotates real mobile and residential IPs (across different geos and ASNs) so every request looks like it comes from a trusted, natural user.
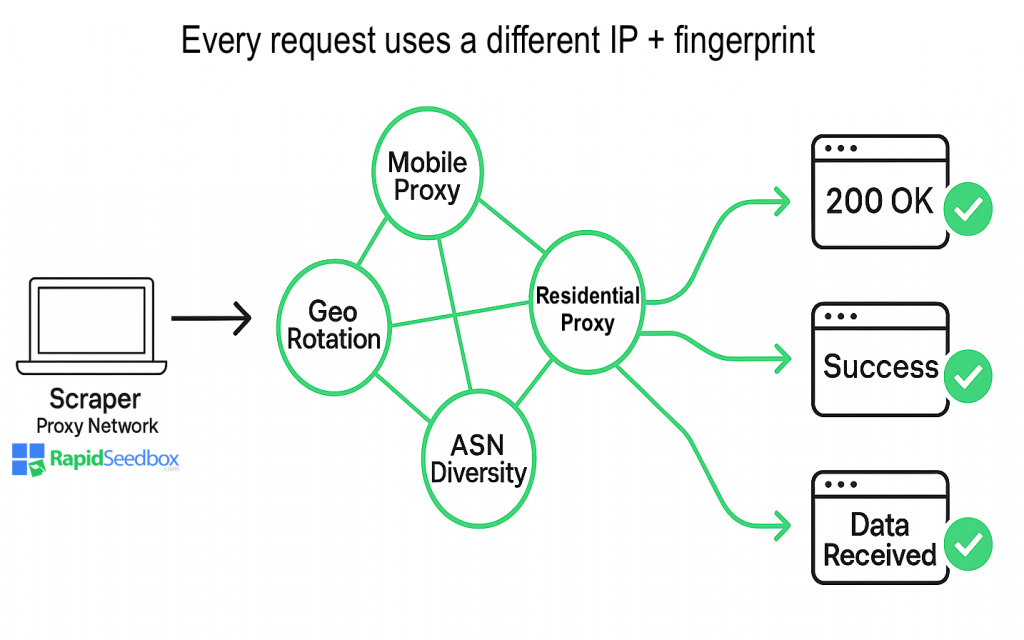
Below is a focused breakdown of how RapidSeedbox solves these problems with two of its most powerful products:
Rotating Residential Proxies
Try Rotating
- Access 6.9M+ residential IPs from real household devices in 100+ countries
- Automatic rotation per request or session to bypass bans and CAPTCHAs
- 99.9% success rate and 99% uptime for stable pipelines
- Unlimited threads for parallel scraping at serious scale
- Sticky or rotating sessions to match your workload
- Ethically sourced, clean IPs with strong trust scores
- 100+ Mbps speeds and 256-bit SSL encryption
- REST API for programmatic control
- Ideal for: large datasets, SERPs, e-commerce monitoring, global price research
Mobile Proxies (3G/4G/5G)
- Real mobile IPs across 130+ countries with ISP-level precision
- Built to mimic real users and avoid detection — perfect for strict sites
- 99.95% connection success and 0.5-second response time
- Rotating + sticky sessions for long-running scrapers
- Unlimited threads, HTTP/SOCKS5, encrypted access
- Ultra-high anonymity for sensitive scraping, ad verification, mobile SEO, and geo-testing
- Trusted by teams that need stability where other proxy types fail
5. FAQ: Web Scraping Without Getting Blocked
Use a defensive setup that includes rotating proxies, realistic browser fingerprints, session management, and dynamic throttling. Mobile and residential proxy networks help maintain stable access under heavy anti-bot pressure.
Mobile proxies and high-trust residential proxies offer the strongest resistance against IP bans and CAPTCHAs because they originate from real devices and real households. Learn more about this topic in: 7 [Real] Ways to Fix the “Your IP has been Banned” Error
Blocks happen when the scraper’s IP reputation drops, headers look automated, or request patterns trigger anti-bot systems.
Playwright, Scrapy, and Selenium are ideal for browser-based scraping. Pairing them with a rotating proxy pool improves long-term stability.
Using cookies, tokens, and authenticated sessions helps a scraper behave like a stable, returning user instead of a new bot on every request.
Content Disclaimer:
This article is provided for educational and informational purposes related to web data access. Users are responsible for ensuring that any data collection complies with all applicable laws, website terms, and local regulations. Nothing here constitutes legal, technical, or operational advice.
0Comments