When managing blacklists in web scraping becomes a daily fight, pipelines stall and teams lose hours. RapidSeedbox’s Rotating Residential Proxies keep your crawlers running.
Table of Contents
- Introduction
- How Managing Blacklists in Web Scraping Actually Works
- Why This Matters to Business Outcomes
- How RapidSeedbox Helps
- FAQ: Managing Blacklists in Web Scraping
1. Introduction
If you run large-scale price tracking or market-intelligence crawlers, you’ve felt it — one day the pipeline hums, the next it’s drowning in 403s and CAPTCHAs.
Blacklists don’t just slow scraping. They break the trust your team has in the data, and they force your CTO or data lead into crisis mode when they should be building product.
Here’s what usually hurts the most:
- Unstable scraping jobs: Jobs fail halfway through. Status pages show red. An entire batch of URLs returns challenge pages instead of real HTML. The team scrambles to diagnose whether it’s the proxy pool, the target site, or a fingerprint issue.
- High engineering overhead: Developers lose hours swapping IPs, adjusting backoff logic, and re-running failed tasks. Your data lead ends up doing DevOps instead of strategy.
When blacklists hit at scale, they don’t feel like a tech issue. They feel like the business is flying blind.
💡Did you know? In large-scale crawling environments, nearly half of users report frequent blocks or CAPTCHA triggers – roughly 43%. (Source: The State of Web Crawling in 2026)
2. How Managing Blacklists in Web Scraping Actually Works
Blacklists show up when a site decides your traffic looks risky — too fast, too repetitive, or too easy to fingerprint. But you can design a system that feels human, rotates clean IPs, and adapts in real time.
Most teams start by shaping traffic. They spread requests across many residential IPs, change headers often, and reuse cookies for a short session so the crawler behaves more like a normal visitor. The stronger setups go further. They track per-IP error rates, put “burned” IPs into cooldown, and route risky endpoints through their highest-trust addresses.
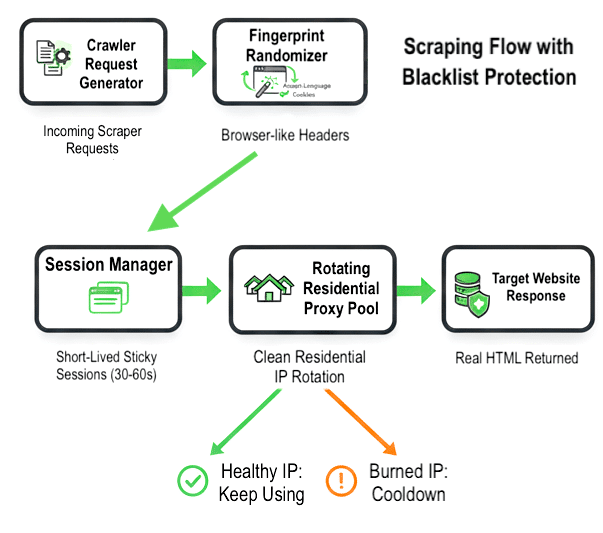
The previous diagram shows the full protection flow:
| Flow: request generation → fingerprint randomization → session management → rotating residential IPs → clean, unblocked HTML responses, with burned IPs sent to cooldown. |
A typical configuration uses rotating residential proxies plus simple per-IP quotas. Something like:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
proxy_pool: type: rotating_residential max_requests_per_ip: 15 cooldown_on_403: 6h headers: rotate_user_agents: true accept_language: "en-US,en;q=0.9" sessions: sticky_duration_seconds: 45 retry_strategy: backoff: exponential detect_captcha: true |
When you combine IP rotation, sticky sessions, browser-like headers, and automated cooldown, blacklists become rare – and temporary.
The Industry Standard Fix
Managing blacklists in web scraping is simpler when you rely on high-trust residential IPs.
See How3. Why This Matters for Business Outcomes
A reliable proxy layer doesn’t just keep your scrapers alive. It keeps your data predictable, lets your data lead relax, and gives your product team consistent insights. When errors don’t spike, your entire workflow steadies – planning, forecasting, reporting.
Rotating Residential Proxies from RapidSeedbox make scraping feel smooth (not fragile). You get IP trust, geographic diversity, and a rotation system that behaves more like real users and less like a bot army.
Business Results Checklist
- Fewer blocks
- Higher success rates
- Lower total cost
- Faster pipelines
- Cleaner datasets
- Predictable scaling
- Less DevOps firefighting
- More stable automation
- Better forecasting
- Higher ROI on data operations
4. How RapidSeedbox Helps
When blacklists slow your crawlers down, the fix usually isn’t another patch — it’s a better proxy layer. One that rotates real residential IPs, keeps sessions fresh, and shields your traffic from getting flagged. RapidSeedbox gives you that layer in one plug-and-play system.
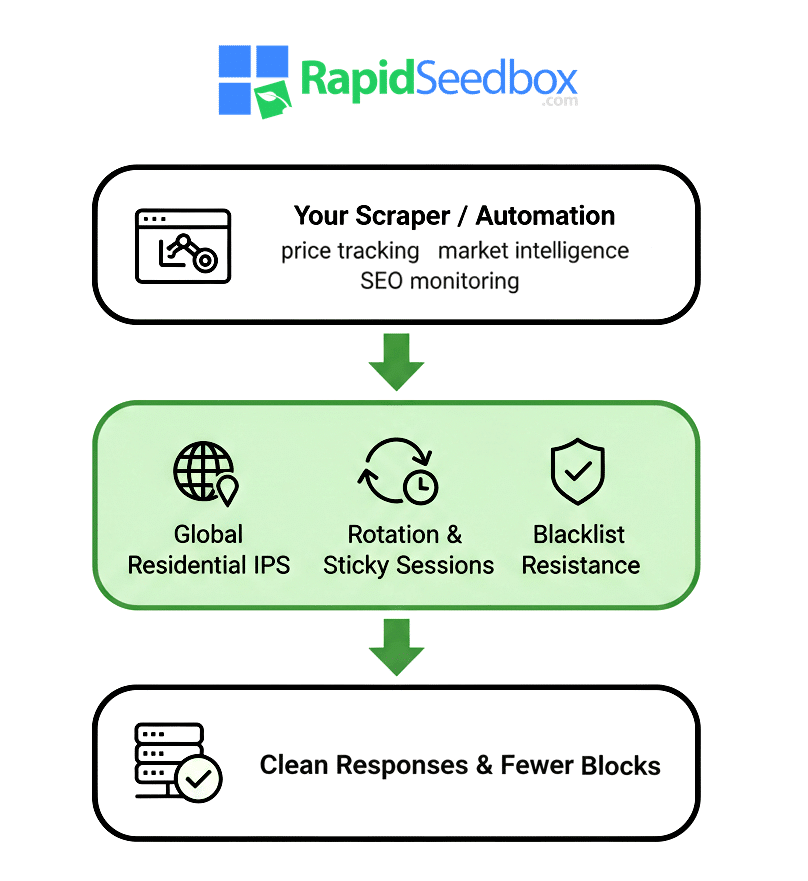
This visual shows how your scraper connects through RapidSeedbox’s rotation layer to produce clean, unblocked responses.
If you need assistance, we’ll be happy to help!
🔄 Rotating Residential Proxies
- IPs: 6.9M+ real residential IPs across 100+ countries.
- Stats: 99.9% success, 99% uptime, and 100+ Mbps speeds.
- Features: Unlimited threads, sticky or rotating sessions, ethical IP sourcing, SSL encryption, and a clean REST API.
- Geo coverage: 130+ countries (Brazil 5.6M, India 5.3M, US 2.6M…).
- Pricing: From 10GB/$30 up to 500GB/$1000.
- Use cases: Global scraping, price comparison, SEO monitoring, ad intelligence, social media, and any data collection that needs high trust.
If you want blacklist resistance, residential IPs are the safest bet — and RapidSeedbox’s pool is built for long-running crawls that can’t afford sudden drops.
| 💡Did you know? Companies running price-intelligence crawlers report blocked sessions dropping by over 70% in the first week after switching to RapidSeedbox’s rotation layer. |
Stop Blocks Before They Hit
Managing blacklists in web scraping shouldn’t slow your next crawl — fix it right now.
Start NowFAQ: Managing Blacklists in Web Scraping
Most blocks come from fast or repetitive patterns, reused IPs, missing headers, or datacenter IP ranges with low trust.
Rotation helps, but pairing it with sticky sessions, fresh headers, and cooldown logic makes the system far more stable.
Residential IPs belong to real households. They look natural and are far less likely to get flagged during scraping.
It depends on the target site, but most high-value crawlers keep per-IP usage low and rotate often.
Yes. Adding browser-level fingerprinting control makes blacklisting even harder for targets.
Content Disclaimer
This article provides general technical and operational guidance on managing blacklists in web scraping. It is not legal advice and does not guarantee full compliance with any website’s terms, policies, or regional regulations. Readers are responsible for ensuring that their scraping practices follow all applicable laws and ethical standards.
0Comments