Incorrect NAP data. Missing reviews. Inconsistent rankings across regions. Local SEO teams rely on clean location data, yet Google aggressively throttles automation. Here’s how agencies and multi-location brands can reliably collect public Google Business listings.
Local Business Data Drives Visibility, Revenue, and Competitive Strategy
Whether you’re managing local SEO for hundreds of client locations or your own brand, Google Business Profiles (GBP) are your battlefield.
Reliable GBP scraping gives you:
- Accurate rankings across zip codes
- Local pack performance
- Competitor density
- Star rating trends
- Review velocity
- Photo freshness
- Hours & attribute changes
- Category consistency
- Spam competitors that need reporting
- Local market saturation signals
But scraping this data is notoriously difficult.
Teams regularly experience:
- Quick blocks after just a few searches
- Wrong geo results (e.g., London IP → UK rankings)
- Missing address or phone fields
- Partial listings
- Captchas on scroll
- Infinite-loader pages
- “Unusual traffic detected” warnings
Local SEO requires precision. When your GBP data malfunctions, you have to rely on guesswork instead of data-driven decisions.
Why Google Defends Local Listings So Aggressively
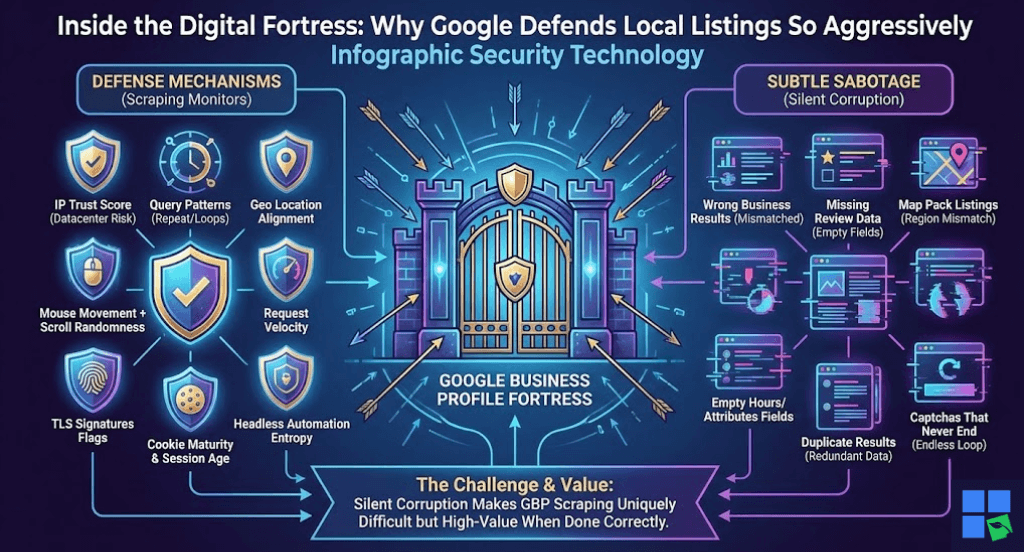
Google Business data is tied to real businesses and reputations in local markets. Google monitors scraping attempts with extreme granularity. They check:
- IP trust score (datacenter IPs equal instant risk)
- Query patterns (repeat keywords, loops)
- Geo location alignment
- Mouse movement + scroll randomness
- Request velocity
- Browser fingerprint entropy
- TLS signatures
- Headless automation flags
- Cookie maturity & session age
Google rarely provides a clear “blocked” message when it detects automation. Instead, it delivers subtle sabotage.
- Wrong business results
- Missing review data
- Map pack listings that don’t match the region
- Empty hours/attributes fields
- Duplicate results
- Captchas that never end
This silent corruption is what makes GBP scraping both uniquely challenging and high-value, if done correctly.
How to Scrape Google Business Listings Safely and at Scale
To safely scrape Google Business listings, use geo-matched residential proxies, real-browser automation (Playwright or Puppeteer), and human-paced interactions. Only collect publicly visible GBP fields, intelligently rotate IPs, and monitor soft-block signals to maintain reliable local SEO data pipelines.
1. Use Region-Accurate Residential Proxies for True Local Results
Google Business results shift dramatically based on:
- Zip code
- City boundary
- Device location
- Language settings
- Proxy reputation
- Search history
Even a few kilometers of misalignment in your IP can render your local ranking data useless.
Residential proxies solve this by providing:
- Authentic, real-user IP fingerprints
- Clean local geotargeting (city or metro level)
- Lower Captcha frequency
- Stable sessions for multi-page scraping
- Correct map pack and local finder outputs
With RapidSeedbox, teams monitor thousands of locations simultaneously with geographically precise IP distribution.
2. Render Local Search Pages Fully (Static Scrapers Miss 60% of GBP Data)
Google Business results rely on dynamic components:
- Review summaries
- Questions & answers
- Popular times charts
- Photos and media
- Attributes (e.g., “women-owned,” “open 24 hours”)
- Service menus
- Map pack positions
- Local finder pagination
Static HTML requests will always miss key fields.
Use full browser rendering:
|
1 2 3 4 5 6 7 8 9 10 |
from playwright.sync_api import sync_playwright with sync_playwright() as p: browser = p.chromium.launch(headless=False) page = browser.new_page() page.goto("https://www.google.com/search?q=plumber+near+me") page.wait_for_timeout(3000) html = page.content() browser.close() |
This ensures that all dynamic listing elements load before extraction.
3. Mimic Real Search Behavior to Prevent Blocks
Google watches how you behave, not just what you search for.
To avoid flagging:
- Add irregular pauses between searches (2-6 seconds)
- Scroll unevenly (top to mid to bottom and then up)
- Randomize pointer movements
- Avoid scraping from the same IP at scale
- Introduce “reading delays” every 5-10 listings
- Change search phrasing slightly
- Rotate user agents periodically
Avoid:
- Identical keyword loops
- Zero-delay pagination
- High-volume scraping from one IP
- Headless browsers with no interaction model
Local SERPs behave differently from product pages, so behavioral simulation is mandatory.
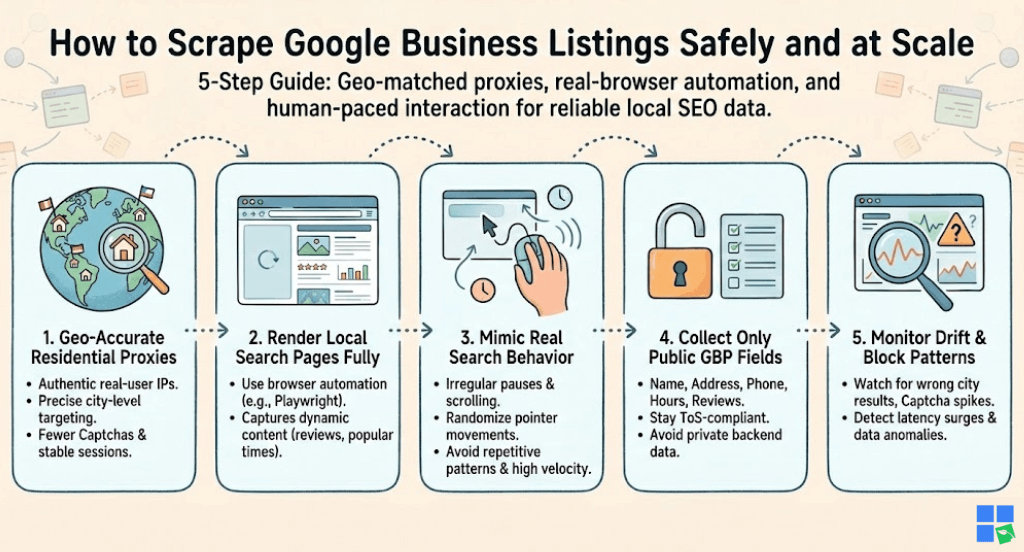
4. Collect Only Public Google Business Listing Fields (ToS-Compliant)
You may only gather information that is accessible to any user without logging in.
Public GBP fields include:
- Business name and categories
- Address and map pin
- Phone number (public)
- Website link
- Business hours
- Photos (public URLs)
- Review count & rating
- Review snippets (publicly visible excerpts)
- Popular times charts
- Attributes (e.g., dine-in, wheelchair accessible)
- Menu or service items (public)
- Peak-hour signals
- Map pack ranking position
Avoid:
- Backend insights
- Review author profiles
- Search Console data
- Private dashboard metrics
- Account-gated views
This ensures long-term sustainability. It also ensures legal compliance.
5. Monitor Result Drift, Block Patterns, and Geo Accuracy
Local searches are sensitive and noisy. Scrapers require ongoing monitoring for detection.
- Wrong city results
- Duplicate listings
- Missing primary categories
- Captcha spikes
- Latency surges
- Sudden drops in review count
- Map pack position shuffling
- Layout changes in the local finder
- “Zero results” anomalies due to soft bans
GBP scraping isn’t “set and forget.” Businesses that treat it as a continuously monitored pipeline outperform those that don’t.
Why Reliable Google Business Data Changes Everything
Clean GBP data allows for measurable improvements in local marketing.
Accurate Local Ranking Tracking
You can see exactly where a business appears across neighborhoods, rather than making guesses.
Clean Review Intelligence
Identify reputation risks and praise themes in hundreds of locations.
Real-Time Listing Health
Instantly detect missing hours, broken URLs, and misaligned categories.
Competitor Visibility
See who dominates the map packs, who’s on the rise, and who’s stagnating.
Better Location Strategy
Before making expansion decisions, identify areas that are overserved or underserved.
Reduced Manual QA
The stability of scraping results in a reduction of spreadsheets and late-night emergency fixes. A consistent GBP data set makes your entire local SEO practice predictable and scalable.
Why Teams Choose RapidSeedbox for Google Business Scraping
Generic proxy providers don’t deliver the stability required for local search scraping.
RapidSeedbox offers:
- Residential proxies with neighborhood-level accuracy
- Exceptionally low block and Captcha rate
- Consistent session behavior
- Rotation controls tailored for SERPs
- Real engineering support
- Transparent dashboards
- Test-first onboarding to reduce risk
Ready to Scrape Google Business Data Without the Headaches?
An effective local SEO strategy requires accurate, real-world listing data. RapidSeedbox provides the infrastructure and expertise necessary to safely scrape Google Business listings at an enterprise scale.
FAQs
You may collect publicly visible information, but you must adhere to Google’s terms and applicable laws.
Google personalizes map results based on proximity to the user’s location.
Residential rotating proxies with precise geo-location.
Tracking rankings is done daily, while full competitive intelligence is tracked weekly.
There are missing fields, repeated listings, incorrect city results, and CAPTCHA.
Disclaimer: This content is for educational purposes only. RapidSeedbox does not encourage violating any website’s Terms of Service. Scrapers must comply with all laws and policies.
0Comments