Data is often touted as the new oil. However, like oil, it must be processed to unlock greater value. With data parsing, we can convert data to different formats. This, in turn, makes it available for a broader range of applications, such as web scraping. Today, we’ll be walking through the process of how this works.

Disclaimer: This material has been developed strictly for informational purposes. It does not constitute an endorsement of any activities (including illegal activities), products, or services. You are solely responsible for complying with the applicable laws, including intellectual property laws when using our services or relying on any information herein. We do not accept any liability for damage arising from using our services or information contained herein in any manner whatsoever except where explicitly required by law.
Table of Contents
- What is Data Parsing?
- How Data Parsing Works
- Types of Data Formats Commonly Parsed
- Examples of Data Parsing Tools
- Real-world Applications of Data Parsing
- Common Challenges and How to Address Them
- Best Practices in Data Parsing
- Final Thoughts & Resources
1. What is Data Parsing?
Data parsing is a process that converts data from one format to another. It is a critical transformation process in data management. The conversion makes data more accessible and easier to work with.
It’s like translating a foreign language into your native tongue. The translation will make the content available to a much broader audience. That accessibility gives the language greater value.
2. How Data Parsing Works
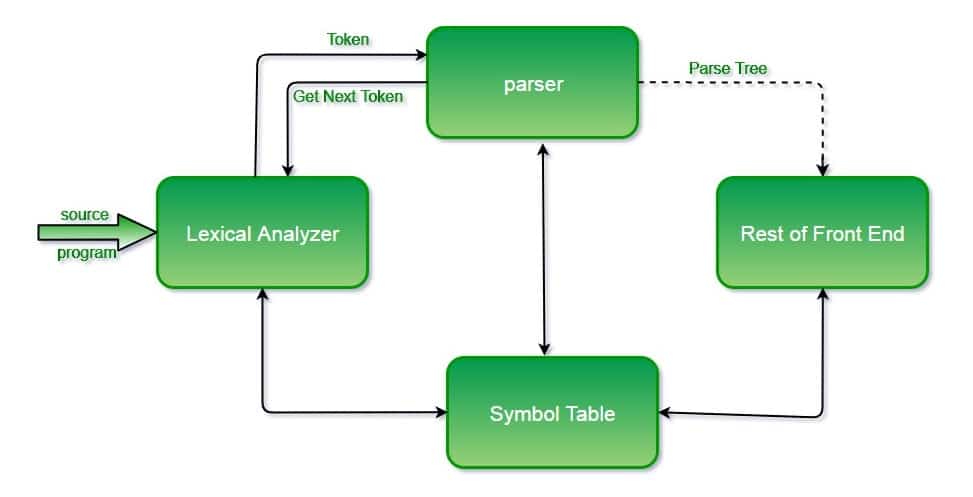
At its heart, data parsing simplifies complex data structures. That simplification makes it possible to extract and utilize meaningful information. It is like breaking down a large puzzle into smaller, more easily manageable pieces.
Data Parsing Process Breakdown
- Data Acquisition: The first step involves accessing the data to be parsed. This data could be stored in a file, received as input from a user, or captured from the internet. For the latter, most scrapers use proxies.
- Structure Identification: The parser examines the input data to identify its format and structure. This could involve recognizing patterns, delimiters (such as commas in CSV files), or specific tags in XML/HTML documents.
- Data Transformation: Once the structure is understood, the parsing algorithm converts the data into a desired format. This might mean turning a JSON string into a Python dictionary or extracting information from a webpage into a structured database.
- Output Generation: The final step is to output the transformed data in a more suitable format for storage, analysis, or further processing.
3. Types of Data Formats Commonly Parsed
Data professionals can tailor their parsing strategies by understanding the characteristics and applications of these formats. They can meet their projects’ needs, ensuring efficient and effective data analysis.
These are some common data format types:
Structured Data Formats
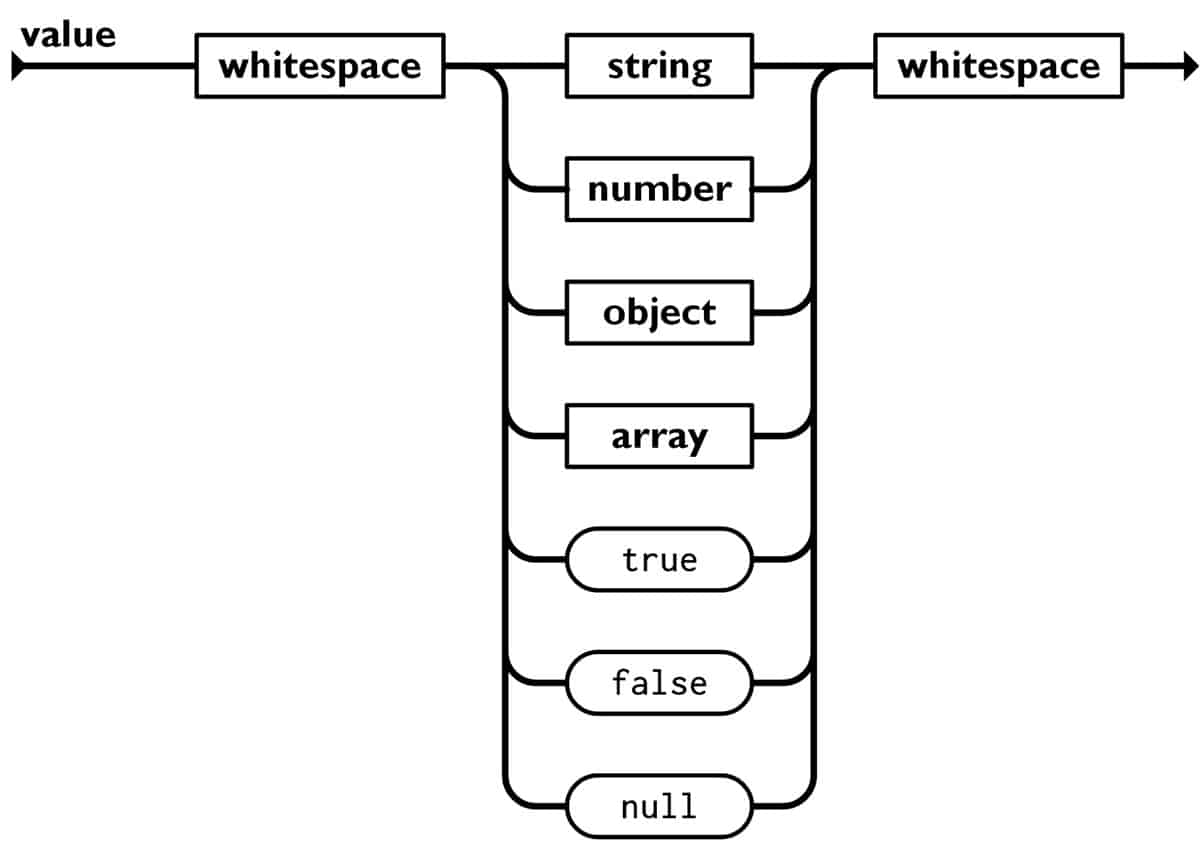
Structured data adheres to a specific format, making it easier to analyze and process. These formats are preferred for their predictability and the ease with which they can be parsed and manipulated using standard programming tools. Common examples include:
- eXtensible Markup Language: XML is widely used for storing and transporting data. It is highly structured, with a tag-based format that allows for the definition of custom tags, making it versatile for various applications.
- JavaScript Object Notation: Known for its lightweight and text-based structure, JSON is ideal for data interchange between servers and web applications. Its easy-to-understand format, resembling JavaScript object literals, makes it a favorite among web developers.
- Comma-Separated Values: Typically known as “the Excel format,” CSV files represent data in a tabular format. They simply use commas to separate values. This format is widely supported and commonly used for spreadsheets and databases.
Unstructured Data Formats
Unstructured data does not follow a specific format or structure, posing a more significant challenge for parsing. Working with unstructured data often involves more complex processes, such as regular expressions. Examples include:
- Text Files: Plain text files contain data without a defined structure, often requiring custom parsing logic to extract meaningful information based on patterns or keywords.
- Web Pages: HTML documents are a prime example of unstructured data that can be worked with to extract information. Tools like web scrapers navigate the hierarchical structure of HTML tags to retrieve specific data points.
Semi-Structured Data Formats
Semi-structured data formats contain characteristics of both structured and unstructured data. They do not have a rigid schema like structured data but possess identifiable patterns facilitating the conversion process. Examples include:
- Emails: While the body of an email may be unstructured text, headers, and metadata follow a consistent format that can be parsed.
- Logs: System or application logs typically follow a semi-structured format, where each entry is unstructured text but follows a consistent pattern, making it possible to analyze log data systematically.
4. Examples of Data Parsing Tools
A variety of tools are available for data parsing. Some are standalone, while others exist within development ecosystems. Here are some examples of the most popular tools:
- Logstash: A server-side data processing pipeline that simultaneously ingests data from multiple sources. Logstash transforms it and then sends it to a “stash” like Elasticsearch. It is beneficial for parsing logs and other time-based data, offering filters that can parse and transform the data before it is indexed.
- Apache NiFi: An integrated data logistics platform for automating data movement between disparate systems. NiFi supports various data transformation functions, making it suitable for complex data flows.
- OpenRefine: Formerly known as Google Refine. OpenRefine is excellent for working with messy data. It can clean the data and transform it from one format into another.
- XPath and XQuery: Part of the XML ecosystem, these functions parse and query XML documents. They are essential for scenarios where XML data must be efficiently navigated and extracted.
5. Real-world Applications of Data Parsing
Data parsing extends its utility beyond data processing, touching various aspects of business operations, research, and everyday technology use. Here are some practical applications where data parsing plays a pivotal role:
- Web Scraping: Extracting data from web pages is a quintessential example of data parsing. It is widely used for market research, competitor analysis, price monitoring, and aggregating information from different online sources.
- Natural Language Processing: NLP is a field of artificial intelligence that relies heavily on parsing to understand human language. It can apply to everything from sentiment analysis to chatbots and language translation services.
- Log File Analysis: Enables the extraction of relevant information from logs. The data is often in a semi-structured format. Organizations parse these files to monitor system health, detect anomalies, and optimize performance.
- Financial Data Analysis: Parsing can process and analyze vast amounts of financial data. It enables financial analysts to convert raw data into a format suitable for trend analysis, risk assessment, and algorithmic trading.
- Scientific Research: Aids researchers in collecting and analyzing research data. The field of application is broad, covering everything from experimental results to analyzing large datasets.
Are you interested in web scraping to analyze website data?
Web scraping is a powerful capability, but many websites try to block scraper bots. RapidSeedbox proxy servers include many IP addresses so your scraper can rotate them.
6. Common Challenges and How to Address Them
While indispensable, data parsing is also fraught with challenges. These challenges can complicate the process and affect the outcomes. Understanding these hurdles is crucial for anyone working with data.
Here are some common challenges and how they impact the parsing process:
- Dealing with Large Datasets: Handling massive files or streams of data can lead to performance bottlenecks, requiring significant computational resources. Efficient memory management and streaming data parsing techniques are essential.
- Handling Complex Data Structures: Parsing these structures requires understanding the hierarchy and relationships within the data. Addressing it requires developing a parsing logic to navigate these complexities without losing context.
- Data Quality and Consistency: These issues can derail the parsing process, leading to inaccurate or incomplete datasets. Implementing robust error handling and data validation mechanisms is crucial to identify and address them.
- Diverse and Evolving Data Formats: Data formats tend to evolve. This requires updates to parsing algorithms to accommodate new structures or features.
- Encoding and Internationalization: These can complicate parsing, especially when dealing with global datasets. Ensuring that the parsing process respects the encoding is crucial to avoid data corruption or loss of meaning.
- Performance Optimization: Fast parsing algorithms may overlook nuances in the data, while highly accurate methods can be resource-intensive. Finding the right balance requires a thorough understanding of the data and objectives of the parsing process.
7. Best Practices in Data Parsing
Adopting certain best practices is essential to navigate the complexities of data parsing and maximize its effectiveness. These guidelines help overcome common challenges and ensure the integrity and usability of the parsed data.
- Understand Your Data: A preliminary analysis can guide your choice of parsing tools and techniques. That will ensure a good fit for the task at hand.
- Choose the Right Tools: Parsing tools often have unique characteristics. For example, Python’s BeautifulSoup is excellent for HTML parsing, while Pandas handles structured data files exceptionally well.
- Implement Error Handling: Robust mechanisms are crucial for dealing with inconsistencies, missing values, or unexpected data formats. You can either log them for review or apply default values where appropriate.
- Validate and Clean Data: This can involve checking for data type consistency and removing or correcting outliers. The process makes data more reliable and easier to analyze.
- Optimize for Performance: Techniques like parallel processing can significantly reduce memory usage and speed up parsing.
- Manage Encoding: You can prevent data corruption by accounting for different encodings and character sets. It also ensures that parsed data accurately reflects the original content.
- Document Your Process: Documentation aids troubleshooting, future updates, and collaboration.
8. Final Thoughts
Data parsing is a valuable skill in today’s data-driven world. Whether you’re a data analyst, a software developer, or just interested in data, understanding and mastering the fundamentals can be incredibly useful.
Given the broad scope of the application, it’s unlikely that we’ll stop data parsing anytime soon. As you now know, it helps companies make informed decisions, drives efficiency in operations, and fuels innovation in technology and research.
Resources:
- Stockhause, Simon. “Parsing Log Data for Compression and Querying.”
- Peres de Oliveira, Luiz. “Parsing gigabytes of JSON per second with parallel bit streams.”
- Yang, Min, et al. “Listen carefully to experts when you classify data: A generic data classification ontology encoded from regulations.”
- Abney, Steven P. “Principle-based parsing.”
- Li, Zhuang. “Semantic Parsing in Limited Resource Conditions.”
0Comments