E-commerce engineers and data teams hit walls all the time. Blocks, CAPTCHAs, bans. With RapidSeedbox’s residential pool and a rule-based proxy client you’ll be able to keep your requests clean and under the radar. Anti-bot while web scraping made easy!
Table of Contents
- Why Ethical Scraping Still Gets You Blocked
- How Ethical Web Scraping Anti-Bot Systems Actually Work
- Data Without Drama: Why This Matters to Your Business
- How RapidSeedbox Can Help
- FAQ: Bypassing Anti-Bot Systems While Scraping
1. Why Ethical Scraping Still Gets You Blocked
Scraping public product data shouldn’t feel like you’re breaking into a bank vault. But if you’re in e-commerce, that is a different world. Bot protection is everywhere (and it’s brutal).
Scraping engineers and growth teams know every block wastes time and every ban breaks pipelines. You’re stuck rerouting traffic and troubleshooting ghosts.
- Getting blocked at scale: Sites flag your IP and challenge you with CAPTCHAs. They may even throw fake content your way. And so, your scraper goes blind, fast.
- Poor proxy and browser handling: Default user-agents sloppy IPs or headless browsers scream “bot.” You’re spotted before you even load the page.
You need to get in, get the data, and get out, all without making a sound.
2. How Ethical Web Scraping Anti-Bot Systems Actually Work
To beat the bots, you don’t need to outmuscle, you outsmart. You mimic real humans. For example, unpredictable clicking and scrolling. And one delay at a time.
That’s where Residential proxy pools shine. They route traffic through real residential IPs, rotating them intelligently. You can choose sticky sessions, rotate per request, or set rules that match your target’s risk profile.
Use Playwright or Puppeteer to render JavaScript-heavy pages in a real browser environment. Pair it with stealth plugins to remove traces like navigator.webdriver. Add human-like mouse movement and randomized delays.
|
1 2 3 4 5 |
yarn add puppeteer-extra puppeteer-extra-plugin-stealth const { addExtra } = require('puppeteer-extra'); const StealthPlugin = require('puppeteer-extra-plugin-stealth'); const puppeteer = addExtra(require('puppeteer')); puppeteer.use(StealthPlugin()); |
Take a look at the diagram below — it breaks down exactly how ethical web scraping avoids anti-bot detection. From Playwright or Puppeteer automation to RapidSeedbox’s rule-based proxy layer and residential IP rotation. Each stage keeps your requests human-like and invisible to bot defenses.

3. Data Without Drama: Why This Matters to Your Business
Proxies and stealth scraping don’t just unblock data. They unblock revenue.
Every time your scraper hits a CAPTCHA, an HTTP 403, or a fake page — that’s time lost, leads missed, pricing updates delayed. It adds up. Engineering hours vanish into firefights. Forecasts run stale. Your team’s trust in the pipeline erodes.
With RapidSeedbox, your infrastructure actually behaves. The Residential Pool gives you IPs that don’t raise flags. The Rule-Based Proxy Client routes requests with surgical precision — adapting when pages change, when CAPTCHAs show up, when sites throttle traffic. You get resilience, not whack-a-mole chaos.
What you gain:
- Fewer blocks and retries
- More stable, resilient automation
- Cleaner datasets that actually load
- Predictable scaling even across high-risk targets
- Lower scraping cost per target and per session
- Higher ROI on every data operation, from pricing to inventory to SEO intel
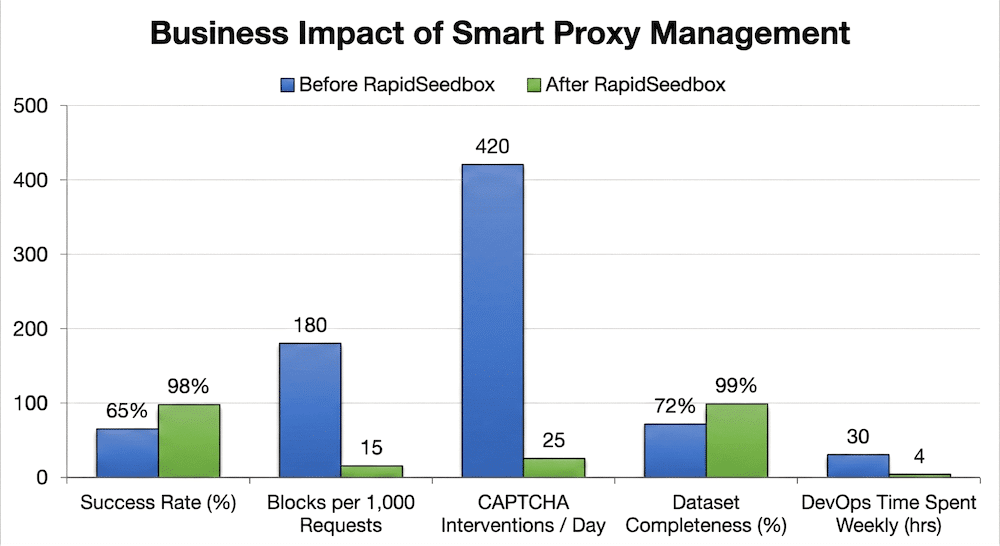
The chart below shows the impact of smarter proxy management with RapidSeedbox — higher success rates, fewer blocks and CAPTCHAs, and a major drop in DevOps hours, all leading to cleaner data and protected revenue.
4. How Rapidseedbox Can Help
Our Residential Pool gives you clean, undetectable IPs from real devices (not noisy subnets). Add the Rule-Based Proxy Client to set smart logic: rotate after X requests, change on error, geo-target by region.
That means you stay under the radar, even on aggressive e-commerce targets with layered anti-bot systems.
If you need assistance, we are here to help!
Rotating Residential Proxies
With over 6.9 million residential IPs in 130+ countries, RapidSeedbox delivers a massive, stable proxy network tailored for scraping at scale. You get 99.9% success rates, 99% uptime, SSL encryption, and full sticky or rotating session support. Whether you’re scraping prices, tracking SEO, or collecting social media data, you can rely on real-device IPs that blend in like native traffic.
- Unlimited threads for parallel scraping
- Sticky sessions for logged-in journeys
- Rotating IPs per request or per rule
- REST API access + 24/7 support
- Affordable pricing from $3 to $2 per GB as you scale
Effortless Anti-Bot Web Scraping
Make scraping smooth again. Clean residential IPs, smart rotation rules, and simple setup — everything you need to stay invisible.
Get Rotating Residential Proxies| 📈 It Works — Here’s Proof: “Blocked sessions fell by 70% in week one after switching to RSB’s rotation layer.” A pricing intelligence team achieved this while scraping 50k+ SKUs daily on five continents. |
5. FAQ: Bypassing Anti-Bot While Web Scraping
What’s the best proxy type for e-commerce scraping?
Residential proxies are ideal because they originate from real user devices and follow natural ISP patterns, which anti-bot systems interpret as trusted traffic. They blend in better than datacenter IPs, which are often pre-flagged or rate-limited by e-commerce sites, especially those running Cloudflare, Akamai, or DataDome.
Can headless browsers be detected?
Yes — many anti-bot systems scan for headless signatures like navigator.webdriver, missing plugins, canvas fingerprints, or unrealistic behavior. This is why Playwright or Puppeteer should run with stealth plugins that patch these traces and add human-like inputs.
What’s a sticky session?
A sticky session keeps the same residential IP for a set duration or number of requests, which is essential for actions that depend on persistent identity. Logged-in dashboards, cart actions, and paginated product views often break if the IP changes too quickly, so sticky sessions maintain continuity while still avoiding detection.
Do rotating proxies help avoid CAPTCHAs?
Absolutely. Rotating proxies spread requests across many clean IPs, reducing the volume per address and lowering the risk scores that trigger CAPTCHAs or 403 blocks. When paired with browser automation and proper timing, rotation becomes one of the strongest defenses against challenge pages. Learn more in: CAPTCHA-free Scraping Guide (2026 Update)
Trusted Anti-Bot Web Scraping for High-Scale Teams
Teams scraping 50k+ SKUs daily rely on RapidSeedbox for Anti-Bot Web Scraping stability. Use the same clean, rotating IP layer they do.
Start With Residential RotationContent Disclaimer
This article is for educational and legitimate data-collection purposes only. All scraping should comply with website terms, robots.txt rules, and applicable laws. RapidSeedbox does not support or endorse scraping private data, violating access controls, or bypassing security for unlawful use.
0Comments