Cloudflare blocks slow your pipeline and waste dev time. Rotating proxies keep traffic clean so your team can focus on insights – not errors.
Table of Contents
- Introduction
- How Bypassing Cloudflare Challenges Actually Works
- Why This Architecture Delivers Real Business Value
- How RapidSeedbox Helps
- FAQ: Bypassing Cloudflare Challenges
1. Introduction
Bypassing Cloudflare challenges while scraping is far more than just a technical obstacle. It’s a daily friction point for data engineers and automation leads who rely on predictable extraction for real business decisions. When Cloudflare blocks a scraper, entire workflows fall apart—price-tracking reports lag and SEO monitoring stops.
Cloudflare makes sense from the website’s side. Still, it creates two sharp pain points for teams who are allowed to collect data but need a stable method to do it:
- Cloudflare keeps triggering 5-second challenges, Turnstile tokens, and Error 1020. This disrupts pipelines and forces developers to babysit scrapers instead of just building features.
- IP reputation collapses fast. Even clean code gets flagged when using predictable IP ranges or high-frequency patterns, turning a simple scrape into hours of debugging.
Every slowdown ripples across reporting and decision-making. When your pipeline breaks, your business hesitates. And in fast-moving markets, hesitation costs more than any proxy plan ever will.
| 🤖 Did you know? Studies show that around 47–50% of all internet traffic comes from bots, not humans, which is why anti-bot systems like Cloudflare aggressively inspect fingerprints and reputation signals. Source: Imperva Bot Traffic Report |
2. How Bypassing Cloudflare Challenges Actually Works
Cloudflare intercepts every request and pushes suspicious traffic through layered defenses (i.e., 5-second challenges, Turnstile checks, and 1020 firewall rules. The following diagram shows how a normal bot or script gets flagged long before it reaches the target website.

Cloudflare challenges don’t disappear on their own. They fade only when your scraper behaves like a real browser with a trustworthy network identity. That’s why bypassing Cloudflare challenges while scraping starts with two pillars: clean fingerprints and stable IP reputation.
Cloudflare checks everything:
- JA3 fingerprints
- TLS handshakes
- Header order
- Canvas/WebGL signal
- Timing between requests.
If your scraper looks artificial at any layer, Cloudflare escalates the challenge. So the safest play today is a full browser environment. Playwright or Selenium, running Chrome in headless or headful mode, works best because it executes Cloudflare’s JavaScript and Turnstile checks the way a real user would.
From there, your proxy layer becomes the backbone of stability. Residential IPs mimic normal household traffic. Mobile IPs look even more natural, with ISP-level trust and constant churn from cell towers. Add rotation rules that change IPs every few requests, and use sticky sessions when you need to keep a cf_clearance cookie alive.
Here’s a lightweight example of a rotation-aware Playwright setup:
|
1 2 3 4 5 6 7 8 9 |
scraper: engine: playwright browser: chromium proxies: type: residential rotate_every_requests: 12 sticky_sessions: true wait_for: cloudflare_clearance: true max_timeout_ms: 8000 |
And here’s your integration point:
When you combine real browser execution with rotating residential or mobile IPs, Cloudflare treats your session like normal traffic (not a bot trying to brute-force its way in). In other words, a real browser plus high-trust IPs makes your activity look clean.
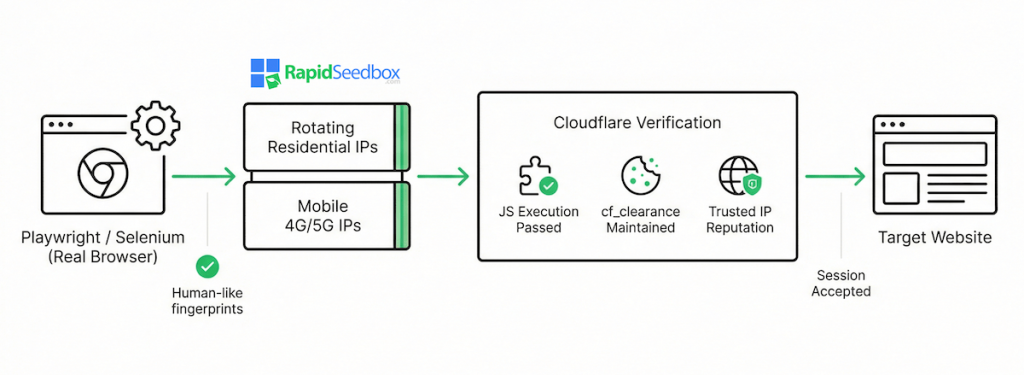
This setup works especially well with tools like Playwright or Selenium. Their browser fingerprints, paired with rotating proxies, help preserve cf_clearance cookies and pass Cloudflare’s checks without issues.
3. Why This Architecture Delivers Real Business Value
A scraper that survives Cloudflare can be considered ‘stable’. And stability is what data teams need when they’re tracking thousands of products. It is also ideal when these teams are validating SEO signals or watching price changes every hour.
Rotating Residential and Mobile Proxies give the decision-maker something rare in scraping: predictable success. The team stops firefighting and starts shipping improvements again.
When your proxy layer stays clean, your data pipelines flow with fewer surprises.
Business-Results Checklist
- Fewer blocks
- Higher success rates
- Cleaner datasets
- Faster pipelines
- Less DevOps firefighting
- Predictable scaling
- Better forecasting
- Lower total cost
- More stable automation
- Higher ROI on data operations
4. How RapidSeedbox Helps
Cloudflare is tough because it reads your traffic like a detective. RapidSeedbox is built to make your traffic look natural, credible, and human-like (without hacks or shortcuts).
If you need help, feel free to schedule a demo.
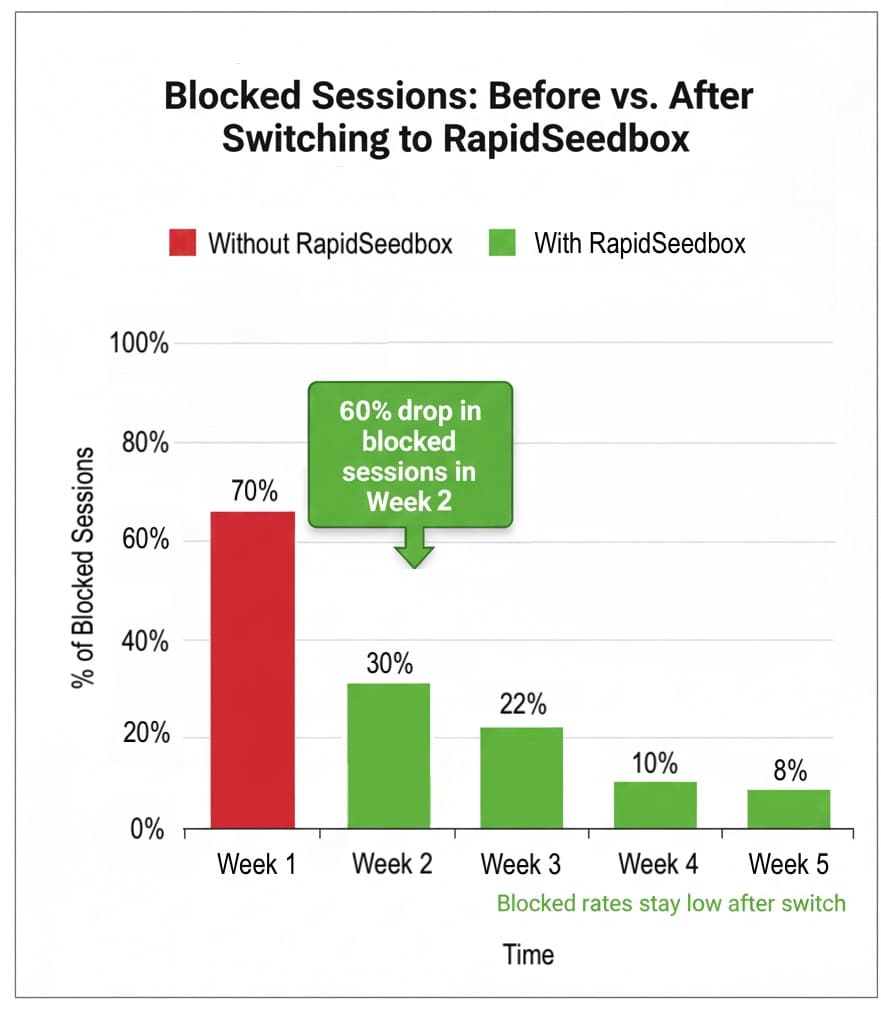
Teams switching to RapidSeedbox see blocked sessions collapse almost immediately, with a 60% drop in Week 2 alone. The graph below shows how blocker rates stay low week after week once traffic runs through high-trust residential and mobile IPs.
🔄 Rotating Residential Proxies
A pool of 6.9 million residential IPs across 100+ countries gives your scraper the reputation lift it needs. With 99.9% success, 99% uptime, and 100+ Mbps speeds, the pipeline finally feels smooth. You get unlimited threads, sticky or rotating sessions, ethical IP sourcing, and a full REST API for automation. Pricing runs from 10GB for $30 up to 500GB for $1000, which works well for mid-size and enterprise data teams.
This pool shines on price intelligence, SEO monitoring, ad checks, global targeting, and high-frequency scraping jobs.
Stop Losing Data to Cloudflare
Don’t let Cloudflare ruin another crawl — fix it with rotating residential proxies for bypassing Cloudflare challenges.
Start Now📱 Mobile Proxies (3G/4G/5G)
Cloudflare trusts mobile carriers more than almost any other source. That’s why mobile IPs deliver 99.95% success, 99.9% uptime, and fast 0.5s responses. These proxies rotate naturally through carrier infrastructure, making them extremely hard to detect or challenge.
Perfect for strict platforms, social networks, mobile-first environments, app monitoring, and high-stakes scraping workloads.
The range starts at 5GB/$45 and scales to 500GB/$2500—ideal when you need the strongest identity shielding.
The Effortless Cloudflare Fix
Stop fighting 1020 errors. Mobile proxies make bypassing Cloudflare challenges effortless.
See HowBoth proxy types solve the same core problem: Your scraper stops looking like a bot. And Cloudflare stops treating it like one.
| ⚡ Quick Win: Teams running price-intelligence crawlers saw blocked sessions drop over 70% in the first week after switching to RapidSeedbox’s rotation layer. |
5. FAQ: Bypassing Cloudflare Challenges
They distribute your requests across many clean IPs, which reduces reputation issues. Cloudflare sees normal household or mobile behavior instead of repeated traffic from a single, predictable source.
Yes. Cloudflare relies on JavaScript and fingerprinting. A headless browser completes those checks correctly and keeps your session stable.
Both have a place. Sticky sessions keep cf_clearance cookies alive. Rotation helps when you’re making many short, high-frequency requests. Most teams mix the two.
Mobile IPs carry strong trust because they come from real carriers. They trigger fewer challenges and handle tougher environments more gracefully.
It happens when your request violates a firewall rule. This often comes from fingerprint mismatches, too many requests per IP, or bad reputation signals.
Content Disclaimer: This article is for educational and operational guidance only. All scraping activity must follow local laws, website terms of service, and ethical data-collection standards. RapidSeedbox does not endorse misuse of proxies or automation tools.
0Comments