The comparison of Playwright vs Selenium is a critical consideration for developers and data scientists alike. While similar in purpose, these tools take different architectural approaches. Due to this discrepancy, you may find them offering different operational advantages.
This comparison is meant to give a high-level overview and is not a deep-dive technical comparison. We also focus on their web scraping activities, which naturally will involve proxy servers.

Disclaimer: This material has been developed strictly for informational purposes. It does not constitute endorsement of any activities (including illegal activities), products or services. You are solely responsible for complying with the applicable laws, including intellectual property laws, when using our services or relying on any information herein. We do not accept any liability for damage arising from the use of our services or information contained herein in any manner whatsoever, except where explicitly required by law.
Table of Contents
- Overview of Playwright vs Selenium
- Installation and Setup Process
- Comparison of Data Scraping Capabilities
- Code Simplicity and Learning Curve
- Browser Support and Compatibility
- Performance and Speed
- Reliability and Error Handling
- Final Thoughts
- References
1. Overview of Playwright vs Selenium
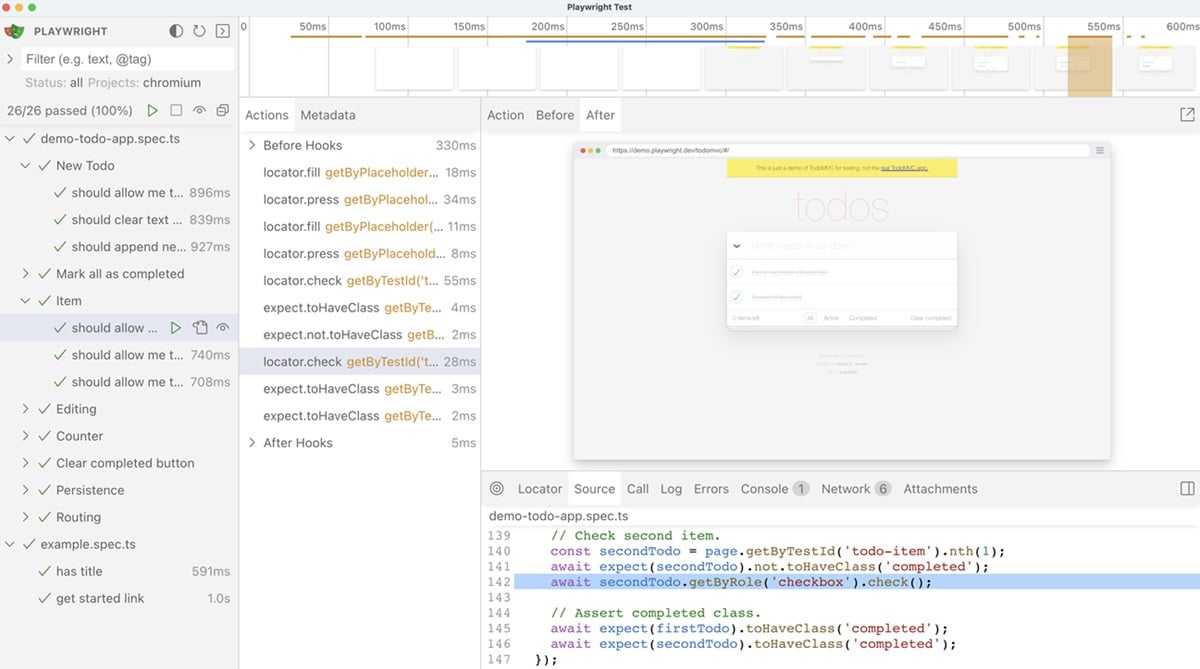
Microsoft released Playwright in 2020, making it a newer addition. It is exceptionally capable of managing dynamic content and single-page applications. Additionally, one of the critical points in the Playwright vs Selenium debate is Playwright’s out-of-the-box multi-language support.
Comparatively, Selenium has been long enough in the field to enjoy broad adoption and substantial community backing. It has become a cornerstone tool for developers and QA engineers in many fields.
As of writing, their adoption rate varies significantly. Playwright ekes by with a marginal market share of 1.53% compared to the 30.81% that Selenium enjoys. However, it’s notable that Playwright is often more highly retained by new adopters.
2. Installation and Setup Process
| Playwright | Selenium | |
| Primary Environment | Node.js (with bindings for Python, C#, Java) | Multiple (Java, Python, C#, Ruby, JavaScript) |
| Browser Binaries | Automatically installs binaries for Chromium, Firefox, and WebKit | Requires manual download and setup of browser-specific drivers |
| Driver Management | Integrated; no manual driver setup required | A manual driver setup is needed for each browser |
| Ease of Setup | Simple | More steps |
| Multi-Browser Support | Out-of-the-box support for multiple browsers without extra setup | Supports multiple browsers but requires a separate driver setup for each |
| Documentation | Comprehensive, with guides for different programming languages | Extensive, covers various programming environments and detailed driver setup |
| Initial Setup Time | Generally quicker due to bundled browser binaries | It may take longer due to the need for manual driver management |
Playwright offers a straightforward installation process that perfectly fits modern development environments. Installation is done with a single command. During the installation, binaries for compatible browsers are installed alongside, reducing the need for manual driver management.
Selenium, on the other hand, requires a more hands-on approach. After installing the Selenium library for your programming language, you must separately download and set up the correct versions of browser drivers required for your tests. Care must be taken to ensure driver compatibility.
Key Differences
Both frameworks offer support for multiple programming languages. However, the way they handle the bindings during setup varies. Where Playwright leverages language package managers, Selenium requires more detailed processes for each required language.
This complexity extends further once you consider the broader ecosystem of Selenium tools and third-party integrations. For example, configuring Selenium Grid for parallel testing or selecting and using various build tools.
3. Comparison of Data Scraping Capabilities
| Playwright | Selenium | |
| Handling of Dynamic Content | Excellent | Good, but often requires more explicit waits and conditions. |
| Ease of Data Extraction | Concise and expressive API simplifies scripts for efficient data extraction | Versatile API that can handle complex data extraction tasks |
| Adaptability to Complex Web Scraping Tasks | Quickly adaptable to complex tasks with reduced needs for external tools | Highly flexible, supported by a broad range of plugins |
When comparing the data scraping capabilities of Playwright vs Selenium, several crucial factors come into play. In this comparison, we see that it’s more a matter of the nature of the site and content being scraped.
Handling of Dynamic Content
Playwright and Selenium offer robust solutions for interacting with and scraping dynamic content. Because of their nature, they excel at working with websites powered by AJAX and JavaScript frameworks.
However, Playwright comes with several additional goodies out of the box. Even without additional support, it can handle multi-page scenarios and more sophisticated interactions, such as working with shadow DOM elements. This comes in addition to automated waits for requests.
While capable of managing dynamic content, Selenium often requires more explicit waits and conditions to ensure elements are loaded correctly. This can make Selenium scripts slightly more complex, but experienced devs can easily customize them.
Ease of Data Extraction
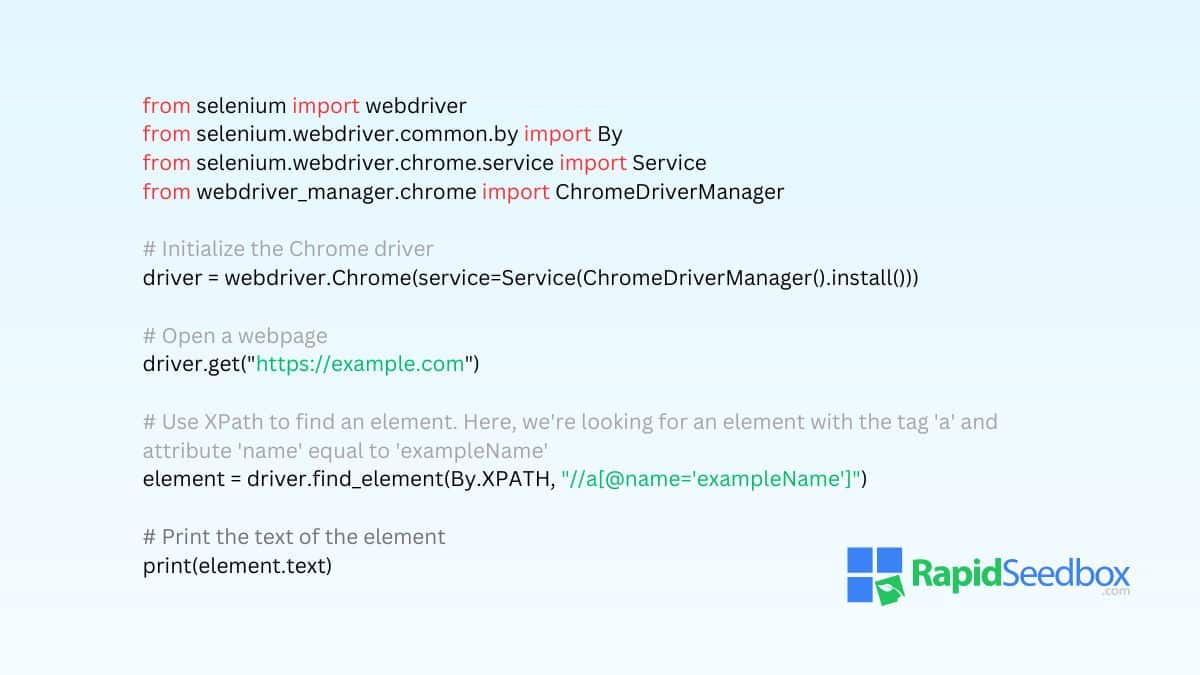
For data extraction, both tools provide a straightforward approach to accessing and manipulating the DOM to retrieve the necessary data. They also use several selector strategies, including CSS and xpath.
Playwright’s API is designed to be concise and expressive. Writing scripts that extract data is more straightforward since you handle fewer lines of code. It can also parallelize scraping jobs efficiently, even with authentication involved.
Selenium offers a mature and versatile API that experienced developers can leverage to perform complex data extraction tasks, albeit with potentially more verbose code and handling requirements.
Adaptability to Complex Web Scraping Tasks
Selenium is supported by a wide range of plugins and community-contributed tools that extend its functionality. Because of the ecosystem, it is a versatile choice for complex scraping tasks requiring handling elements like captcha, navigating through multi-step forms, or dealing with extensive session management.
Playwright is sometimes favored due to its built-in browser context and session support. This feature allows for more sophisticated scraping workflows.
Use With Proxy Servers
Playwright and Selenium can and should be combined with proxy servers for web scraping activities. The reasons for this are typical and likely already expected for most data collectors:
- Privacy and Anonymity: Proxy servers make it harder for websites to track and identify your automation scripts.
- Geolocation Testing: By routing traffic through proxies in different geographical locations, you can test geo-specific features, content, and behaviors.
- Rate Limit Avoidance: Proxies with rotating IP addresses can help reduce the likelihood of hitting rate limits.
- Accessing Restricted Content: Proxies help circumvent content restrictions based on location or deny access to specific IP ranges.
- Monitoring and Logging: Proxies can be used to monitor and log your test traffic. This is useful for debugging issues.
Playwright allows you to configure proxy settings directly in your browser context. This capability makes it straightforward to route all browser traffic through your chosen proxy.
Selenium WebDriver also supports using proxies through its capabilities configuration. You can direct the browser’s traffic through a proxy server by setting the appropriate proxy settings in your WebDriver’s capabilities.
Need a proxy for web scraping?
Combine RapidSeedbox’s high-success rate proxy servers with bulk IPv4 or IPv6 rentals. Enjoy always available customer support and fast, stable performance.
4. Code Simplicity and Learning Curve
| Playwright | Selenium | |
| Code Simplicity | Concise and expressive API | Powerful but more verbose API. Requires explicit handling. |
| Ease of Writing Scripts | Simplifies interaction with dynamic content | Increased script complexity for dynamic content |
| Learning Curve | Relatively gentle for those familiar with JavaScript and Node.js | Steeper due to the necessity to understand multiple programming languages |
Playwright’s architecture is designed to gracefully handle asynchronous operations, thanks to its Node.js roots.
Its API supports async/await out of the box, making writing readable and non-blocking code easier. This is particularly advantageous when dealing with the inherently asynchronous nature of web page interactions.
In comparison, Selenium can seem a bit more cumbersome. Although it has been modified to include async/await patterns (for supporting languages), there is a broader base of boilerplate code for similar tasks.
Key Differences
The difference in approach may seem minimal from a broader perspective. However, it strongly influences several design aspects from an operational standpoint. For example:
- The way dynamic content is handled
- Browser context and session management
- Cross-browser testing methodologies
From a business perspective, Playwright is more desirable since developers may find Playwright easier to handle and more productive. At least from an even starting line point of view. However, these advantages may be less relevant for experienced developers.
Playwright vs Selenium Code Comparison
In the following Playwright script, we can see that no code manages browser drivers or detailed waits. The reason is that Playwright handles waits intelligently.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
const { chromium } = require('playwright'); (async () => { const browser = await chromium.launch(); const page = await browser.newPage(); await page.goto('https://example.com'); await page.type('#search-input', 'Product Name'); await page.click('#search-button'); await page.waitForSelector('.product-item'); const title = await page.innerText('.product-title'); const price = await page.innerText('.product-price'); console.log(`Product: ${title}, Price: ${price}`); await browser.close(); })(); |
In the following Selenium script, note the necessity of waiting for elements and the lengthy setup. This includes the setup of the WebDriver, adding to overall code complexity.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
from selenium import webdriver from selenium.webdriver.common.keys import Keys from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC driver = webdriver.Chrome('/path/to/chromedriver') driver.get("https://example.com") search_box = driver.find_element(By.ID, "search-input") search_box.send_keys("Product Name") search_box.send_keys(Keys.RETURN) # Wait for the product item to be visible wait = WebDriverWait(driver, 10) product_item = wait.until(EC.visibility_of_element_located((By.CLASS_NAME, "product-item"))) title = driver.find_element(By.CLASS_NAME, "product-title").text price = driver.find_element(By.CLASS_NAME, "product-price").text print(f"Product: {title}, Price: {price}") driver.quit() |
5. Browser Support and Compatibility
| Playwright | Selenium | |
| Supported Browsers | Chromium, Firefox, WebKit | Chrome, Firefox, Safari, Internet Explorer, Opera, and more |
| Cross-Browser Testing | Seamless and immediate, with included browser binaries | Requires separate browser drivers, offering extensive coverage, including older versions |
| API Consistency | Uniform API across all supported browsers | API consistency can vary depending on the browser and driver |
| Mobile Support | Yes, for both Android and iOS via WebKit and Chromium | Limited, depending on the browser and driver capabilities |
| Legacy Browser Support | Focuses on modern browsers, limited support for older versions | Extensive, including support for browsers like Internet Explorer |
Playwright offers consistent API behavior across the latest versions of major browsers. Its rapid update cycle also ensures your scraping and automation projects can keep pace with web development trends.
Conversely, Selenium’s strength lies in its broad browser support, including legacy systems, and the flexibility provided by manual browser driver management. Because of this, it’s ideal for projects with diverse browser requirements or requiring compatibility with older web applications.
6. Performance and Speed
| Playwright | Selenium | |
| Parallel Execution | Native support for parallel processing, optimizing speed for large-scale tasks. | Supports concurrency, though performance may be impacted by driver management. |
| Headless Browsing | Built-in support for headless mode, enhancing performance by reducing resource usage. | Supports headless mode but may require more setup and optimization. |
| Dynamic Content Handling | Excellently handles dynamic content with minimal delay, thanks to efficient wait strategies. | Capable of managing dynamic content, but explicit waits can introduce delays. |
| Resource Usage | Optimized to minimize resource consumption, especially in headless mode. | Resource usage depends on the browser and driver configuration, with the potential for optimization. |
| Execution Speed | Generally faster, benefiting from modern architecture and streamlined content handling. | Reliable but may vary in speed, influenced by browser-driver interactions and content complexity. |
Playwright is tailored for high-speed performance, especially in environments where parallel processing and efficient handling of dynamic content are paramount. Its design minimizes resource consumption and execution time.
Selenium offers remarkable flexibility and broad browser compatibility but may exhibit variability in execution speed due to its reliance on separate browser drivers and the need for more detailed configuration. However, performance remains robust.
Speed Test Sample
| Playwright (ms) | Selenium (ms) | |
| Run 1 | 229 | 294 |
| Run 2 | 231 | 297 |
| Run 3 | 235 | 290 |
| Average | 231 | 294 |
For academic purposes, we ran some simplified tests. We created scripts to navigate to a mock search engine, perform a search operation, and extract the first search result. Following that, the scripts were run on the same virtual machine under identical network conditions.
The primary measurement is the total execution time from launching the browser to closing it after extracting the data. While both tools achieved the same end goal, the execution time varied slightly due to methodological differences.
7. Reliability and Exception Handling
| Playwright | Selenium | |
| Type of Exceptions | Uses its own set of exceptions for specific errors | Relies on WebDriver exceptions for browser errors |
| Error Reporting | Detailed error messages with stack traces | Descriptive but sometimes less detailed than Playwright |
| Timeout Exceptions | Timeout exceptions with context-specific information | Generic timeout exception |
| Selector Exceptions | Clearly indicates when a selector does not match any elements | Also reports unmatched selectors, potentially less informative |
| Network Request Failures | Captures and reports directly in the test output | Requires additional setup, such as using browser dev tools |
| Page Navigation Errors | Detailed errors on navigation failures, including HTTP status codes | Navigation errors are reported but may lack detailed information |
| Async/Await Handling | Natively supports async/await | Supports async/await through WebDriverJS |
| Custom Exception Handling | Easy integration of custom exception handling logic within tests | Supports custom exception handling, more complex implementation |
What does this mean?
Thus far, the theme we often see is that Playwrights prefer simplicity, whereas Selenium leans toward control. That’s why it’s interesting that their roles somewhat face a reversal regarding exception handling.
Playwright relies on the dev writing the code to build exception handling into the scripts. Managing this will depend significantly on the individual devs and their chosen language. For example, Python coders will use try/except blocks, while for JavaScript kiddies, it will be the try/catch blocks.
These mechanisms take a further turn if integrations like Axe DevTools are involved. In these cases, further exception handling is dependent on the individual integration. Overall, it feels like a typical Microsoft mess.
Selenium is much more organized and comes with robust exception handling for devs. Exception handling here falls under either checked or unchecked categories. However, these can use many handles to resolve potential issues.
Note: These conclusions shouldn’t be taken at face value. Referring to the comparison table will give you a much better idea of the different approaches in the Playwright vs. Selenium debate regarding reliability.
8. Final Thoughts
Comparing Playwright vs Selenium seemed like a blast from the past. It was akin to comparing Windows against Linux. As with these two operating systems, Playwright and Selenium have pros and cons.
Playwright is much easier to get used to, making it an ideal starting point for those new to web scraping. However, Selenium’s granular controls mean it should be more capable of meeting real-world demands.
It should be interesting to see if Playwright can maintain its slight competitive edge in performance as devs on the platform stack integration modules.
But that’s an article for another day.
9. References
- Bansal, M., DAR, M. A., & Bhat, M. M. (2023). Data Ingestion and Processing using Playwright. Authorea Preprints.
- Bär, J. (2022). Declarative Web Automation Toolkit.
- Gheorghe, M., Mihai, F. C., & Dârdală, M. (2018). Modern techniques of web scraping for data scientists. International Journal of User-System Interaction, 11(1), 63-75.
- Paul, N., & Tommy, R. (2018, July). An Approach of Automated Testing on Web Based Platform Using Machine Learning and Selenium. In 2018 International Conference on Inventive Research in Computing Applications (ICIRCA) (pp. 851-856). IEEE.
- Manjari, K. U., Rousha, S., Sumanth, D., & Devi, J. S. (2020, June). Extractive Text Summarization from Web pages using Selenium and TF-IDF algorithm. In 2020 4th international conference on trends in electronics and informatics (ICOEI)(48184) (pp. 648-652). IEEE.
Are your data scraping activities getting blocked?
Unlock the potential of robust proxy servers that will power your data extraction efforts with unmatched efficiency. Say goodbye to IP bans and restricted access.
0Comments