Today, web scraping and crawling are a must-have for data extraction and analysis. IPv6, the latest Internet Protocol version, has revolutionized these processes.
That’s why, I’ll show you how to use IPv6 for web scraping and crawling. You’ll see how it’s done, what the benefits are, what challenges you might face, and most importantly – how to tackle them.

Table of Content
- TL:DR Web Scraping and Web Crawling
- Web Scraping and Crawling with IPv6 – How to do it?
- Benefits of Using IPv6 for Web Scraping and Crawling
- Potential Challenges When Web Scraping and Crawling with IPv6
- Using IPv6 for Web Scraping – Use Cases
- Final Words
1. TL:DR Web Scraping and Web Crawling
Web scraping refers to the process of extracting data from websites, while web crawling regularly browses the web for newly-indexed information.
2. Web Scraping and Crawling with IPv6 – How to do it?
For effective web scraping, using IPv6 proxies is crucial. They help bypass IP-based restrictions and maintain anonymity, which is essential for scraping.
a. Prerequisites
Before you begin, make sure your scraping tools are IPv6-ready. This compatibility is essential for seamless data extraction.
Distribute your crawling budget:
Using a variety of IPv6 addresses will significantly reduce the possible blocks imposed by your targeted websites.
b. Setting Up
- Choose a suitable web scraping tool: Select a tool or software that is compatible with IPv6. Some of the most popular options are Python libraries like Scrapy and BeautifulSoup.
- IPv6 compatibility: Ensure your internet connection is IPv6-ready. Contact your ISP if you’re unsure about your IPv6 connectivity.
c. Get IPv6 Proxies
Proxies mask your IP address, helping to bypass website restrictions and avoid bans. IPv6 proxies offer a vast range of IP addresses, making them ideal for scraping.
- Select a proxy provider: Choose a provider that offers reliable IPv6 proxies. Consider factors like cost, speed, and anonymity. Proxies can be HTTP or SOCKS5.
- Configure your proxy: Set up the proxy in your scraping tool. This usually involves entering the proxy address and port into your tool’s settings. However, these steps are just the basics, required for most tools. You should consult with your tool’s documentation or your proxy provider to integrate them seamlessly.
d. Prepare Your Scraping Script
- Basic coding: Write a script that sends requests to the target website and parses the returned HTML for data. If you’re using Python, you can consult this guide for creating scripts for scraping and parsing text.
- JavaScript handling: For JavaScript-heavy sites, consider using tools like Selenium or Puppeteer, which can render JavaScript just like a browser.
e. Run Your Scraper
- Start with test runs: At the beginning, launch small-scale tests to ensure your scraper works as intended. Monitor the performance and, if needed, adjust your script.
- Respect website rules: This goes without saying, but always check the website’s
robots.txtfile and follow its guidelines to avoid potential legal problems.
f. Manage the Acquired Data
- Data storage: Decide how you’ll store the scraped data. In most cases, you can choose between databases, CSV files, or JSON.
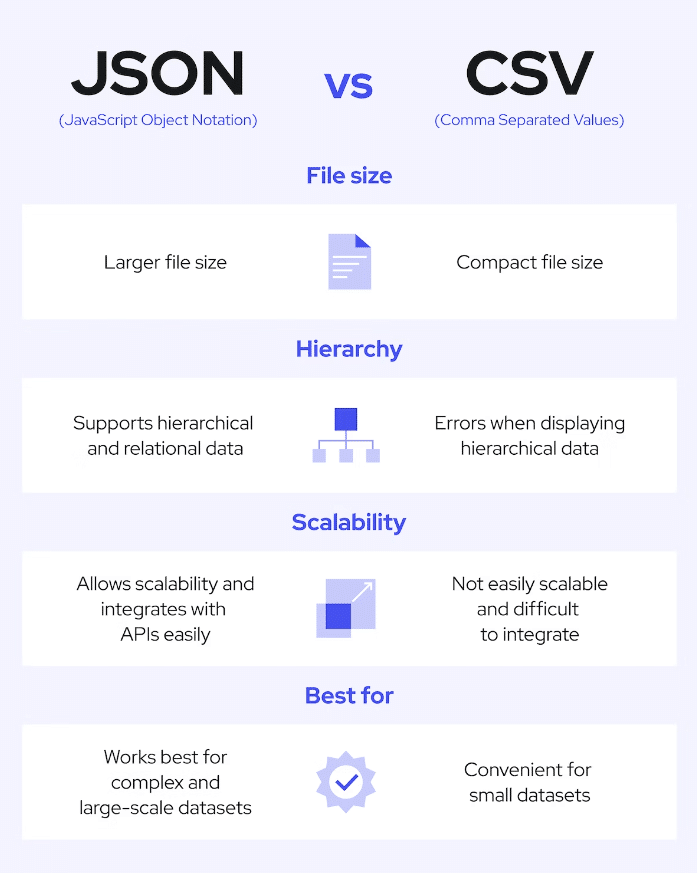
Image credit: Coresignal
- Be prepared for challenges: In theory, all can be perfect, but real-world web scraping comes with challenges. That said, be ready to handle common scraping challenges like CAPTCHAs and IP bans. Using a rotating pool of IPv6 proxies can help with these potential issues.
g. Scaling is Inevitable
- Be ready to scale: As you become more comfortable, you can scale your scraping operations. From my experience, this is always the case. Scaling involves using using more proxies and running multiple scrapers simultaneously. If you don’t have the available budget, consider your strategy carefully.
- Maintenance: This is crucial in the ever-evolving web world. Regularly update and maintain your scraping scripts, especially as websites often change their layout and structure.
3. Benefits of Using IPv6 for Web Scraping and Crawling
Considering how many factors can influence your strategy and the uncertainty, you may be wondering why IPv6 is a good idea.
This is a logical question, considering that IPv4, will eliminate at least one potential problem – compatibility. In fact, less than 40% of all websites don’t support IPv6.
IPv4 vs IPv6 Comparison Table
| Feature | IPv4 Proxies | IPv6 Proxies |
|---|---|---|
| Address Pool | ~4.3 billion addresses (exhausted) | Virtually unlimited (3.4×10³⁸) |
| Cost | Expensive, scarce | More affordable, abundant |
| Compatibility | Supported everywhere | ~60% of sites currently support |
| Performance | Older protocol, slower routing | Simpler headers, faster routing |
| Best Use Case | Legacy systems, universal access | Large-scale scraping, future-proof |
Still, IPv6 offers several benefits you can’t ignore.
- Improved anonymity and security: IPv6 supports IPsec, which offers encrypted and secure connections. This is crucial for privacy during scraping websites.
- Affordability: Surprisingly, IPv6 addresses are cheaper than IPv4 ones. This will reduce the operational costs.
- Better performance: IPv6’s simpler header format and more efficient routing (compared to IPv4) lead to better overall network performance.
- Long-term strategy: Starting with IPv6 ensures long-term compatibility and relevance as the internet transitions to this protocol. More and more platforms will find IPv4 obsolete, so you’d better prepare for the future.
So what is best for scraping? IPv6 or IPv4? Learn more about this topic in: IPv4 vs. IPv6 for Scraping
Looking to enhance web scraping and crawling with IPv6?
Boost your efficiency with RapidSeedbox’s reliable IPv6 proxy services. Enjoy faster, more secure web scraping and crawling, supported by exceptional performance and robust support.
4. Potential Challenges When Web Scraping and Crawling with IPv6
a. Limited IPv6 Adoption
The problem:
Despite its advantages, IPv6 is not yet adopted massively. Many websites and internet service providers still rely on IPv4, which can limit the effectiveness of IPv6-based scraping in certain scenarios.
How to address it:
Use dual-stack systems that support both IPv4 and IPv6. This hybrid approach ensures compatibility with all types of networks and websites. Furthermore, using a proxy service that offers both IPv4 and IPv6 addresses will offer more flexibility.
b. Technical Complexity
The problem:
The transition from IPv4 to IPv6 can be technically challenging for some businesses. IPv6 has a different addressing scheme and requires updates to network infrastructure and software. This will require more expenses and adequate network management.
How to address it:
Invest in training for your team to understand IPv6. Additionally, choose web scraping tools and software that are designed to work seamlessly with both IPv4 and IPv6. This reduces the technical burden and ensures smoother operations.
Furthermore, make sure your team has adequate knowledge on how to address potential issues with IPv6 compatibility.
c. Compatibility Issues
The problem:
Most older systems, tools, and the majority of websites may not be compatible with IPv6, which can prevent your scraping efforts. Keep in mind that most well-known sites support it, but if you need some specific niche knowledge, most smaller websites support only IPv4.
How to address it:
Gradually update your tools and systems to be IPv6-compatible. In the interim, use a proxy service that can translate IPv6 addresses back to IPv4 when necessary, which will ensure uninterrupted access to all types of websites. This will come in extremely handy when you scale.
d. IP Address Management
The problem:
Although IPv6 offers a massive pool of IP addresses, managing these addresses for web scraping can be complicated, especially when scaling operations.
How to address it:
Use advanced proxy management tools that can automate the allocation and rotation of IPv6 addresses. This helps in efficiently managing a large number of IPs and reduces the risk of being blocked by target websites.
For example, RapidSeedbox offers 100 different IPv6 IP addresses on its cheapest plan.
e. Security
The problem:
With the increased adoption of IPv6, there might be concerns about security and privacy, especially when scraping sensitive data.
How to address it:
Make sure that your scraping runs comply with data protection laws. Use secure, encrypted connections for your scraping operations. Additionally, choose proxy providers that prioritize security and privacy. Last, but not least, ensure you’ve checked the targeted websites’ rules.
f. Detection and Anti-Scraping Measures
The problem:
Websites are increasingly using sophisticated anti-scraping measures that can detect and block scraping activities, even with the use of proxies. These prevention measures have increased since the release of ChatGPT.
How to address it:
Use more sophisticated scraping techniques such as rotating user agents, varying request intervals, and using more advanced scraping tools that can mimic human browsing patterns.
Furthermore, apply ethical scraping practices to respect website terms and reduce the risk of being blocked.
5. Using IPv6 for Web Scraping – Use Cases
Using IPv6 proxies for web scraping opens up a range of possibilities due to their unique features. IPv6 enables massive, low-cost IP rotation for large-scale list crawling, reducing blocks and improving scraping success rates.
Here are the most common potential use cases:
a. Large-scale data collection
IPv6 proxies have a massive pool of IP addresses, making them ideal for large-scale data collection. This is particularly useful for businesses and researchers who need to gather extensive datasets from various websites without being restricted by IP limitations.
b. Market research
Companies and SEO specialists use web scraping with IPv6 proxies to monitor their competitors, track SEO rankings, and understand market trends. The large number of available IPs helps in efficiently gathering data from different regions and search engines without triggering anti-scraping measures. Most SEO tools on the market like Ahrefs, Semrush, and others, rely on IPv6 web scraping to monitor their clients’ SERP positions.
c. SEO Monitoring
With IPv6 proxies, you can track rankings and run SERP queries at scale. And IPv6 proxy is also perfect for keeping an eye on competitors without setting off alarms. Because the address pool is virtually unlimited, rotating IPs becomes seamless. That means cleaner data across regions and devices — perfect for keyword audits, market research, and large-scale SEO tracking without hitting IP roadblocks.
d. Sneaker Copping
In sneaker copping, every millisecond and every IP counts. Residential IPv6 proxies route traffic through real devices, making you look like a genuine shopper instead of a bot. That helps bypass anti-bot filters and increases your odds of grabbing limited drops. Paired with automation tools, resellers can scale up, rotate through hundreds of residential IPv6 addresses, and boost their chances of landing more pairs. Learn more in: sneaker proxies
e. E-commerce and price comparison
I don’t know if you’ve sold Nike’s recently, but people are literally making millions of dollars selling sneakers. Retailers and e-commerce platforms can use web scraping to monitor competitor pricing, product availability, and consumer reviews. IPv6 proxies enable them to scrape competitor websites extensively without the risk of being blocked, ensuring they have the latest data for competitive pricing strategies.
f. Social media analysis
For social media analytics, IPv6 proxies make it possible to collect large volumes of data across platforms. This data powers sentiment analysis, trend tracking, and consumer behavior insights. Because networks like Facebook, Instagram, and Twitter are quick to flag unusual activity, residential IPv6 proxies are especially valuable. By blending in as real users, they allow marketers, analysts, and researchers to gather accurate engagement metrics and social trends at scale without triggering security blocks.
Note: In the majority of cases, social media scraping might be considered illegal and a copyright violation in some jurisdictions, so be mindful of potential legal issues. Learn more in: is web scraping legal?
g. Academic research:
This is a rare use case, but researchers can gather vast amounts of data from various online sources for their studies. IPv6 proxies facilitate uninterrupted and anonymous access to websites, which is crucial for collecting unbiased and comprehensive data sets.
h. Content aggregation
Web scraping is used by news aggregators and content curators to gather articles, blog posts, and news stories from across the web. IPv6 proxies help in accessing diverse sources without being limited by IP-based restrictions.
However, if you plan on building such a website, keep in mind that those are often considered spammy and can have a hard time ranking on the SERPs. My advice is to use such tactics only for sharing news.
i. Real estate and property listings
With the housing market boom in the last several years, it’s no surprise that scraping property listing sites provides valuable data on market trends, property prices, and availability.
IPv6 proxies enable scraping these sites on a large scale without being detected.
j. Scraping travel fares
Travel agencies and fare comparison sites can use web scraping to collect data on flight, hotel, and rental car prices. Post-Covid, this tactic has become extremely effective. IPv6 proxies allow such aggregators to access this information from various providers simultaneously and provide a great user experience.
k. Ad verification
Ads are more powerful (and more expensive) than ever, and companies should use web scraping to verify if their online advertisements are displayed as intended and check for ad fraud. IPv6 proxies allow them to anonymously check ads across different regions and platforms.
l. Cybersecurity
From my experience as a cybersecurity expert, scraping is often used to gather data on potential security threats, such as phishing websites or fraudulent activities. IPv6 proxies provide the anonymity needed for such sensitive operations at a scale.
| Final Verdict: In all of the above-mentioned cases, the key advantage of using IPv6 proxies is the ability to perform web scraping on a much larger scale and with greater efficiency compared to IPv4. This is due to the significantly larger address space and lower likelihood of encountering IP bans or rate limits. |
FAQ: Scraping with IPv6 Proxies
IPv6 proxies work as middlemen, hiding your real IP behind an IPv6 address. They’re key for scraping because they help dodge bans, slip past restrictions, and pull data at scale. With the massive supply of IPv6 addresses, you can rotate IPs far more efficiently than with IPv4.
Yes. Residential IPv6 proxies route traffic through real devices and internet providers instead of data centers. That makes them tougher to flag or block, which is especially useful for scraping social media, e-commerce, or other sensitive sites. If you need authenticity, stealth, and better success rates, residential IPv6 is the way to go.
Free options sound appealing, but they often come with headaches: slow speeds, unstable connections, poor anonymity, and security risks. Paid proxies, on the other hand, deliver reliability, speed, and support. If you’re running a serious project, use free proxies only for testing — not live scraping.
The best setups balance speed, security, scalability, and price. Go for providers with big IP pools, options for both rotating and static proxies, 24/7 support, and clear pricing. For advanced use cases — SEO tracking, ad verification, sneaker copping — the top choice is often a mix of residential and data center IPv6 proxies.
Yes. Most scraping tools and APIs — like Scrapy, Puppeteer, or Selenium — support IPv6 proxies. Using them helps spread out requests, cut down on rate limits, and smooth out data extraction. This is especially useful when an API limits or blocks IPv4 traffic.
6. Final Words
Web scraping and crawling with IPv6 represent a significant advancement in data extraction.
If you manage to understand and take advantage of this technology, you or your business can achieve a much more efficient, secure, and cost-effective data collection.
The transition to IPv6 is not just a technical upgrade but it also requires a strategic plan that aims to achieve a certain goal.
Looking to enhance web scraping and crawling with IPv6?
Boost your efficiency with RapidSeedbox’s reliable IPv6 proxy services. Enjoy faster, more secure web scraping and crawling, supported by exceptional performance and robust support.
Disclaimer: This material has been developed strictly for informational purposes. It does not constitute endorsement of any activities (including illegal activities), products or services. You are solely responsible for complying with the applicable laws, including intellectual property laws, when using our services or relying on any information herein. We do not accept any liability for damage arising from the use of our services or information contained herein in any manner whatsoever, except where explicitly required by law.
0Comments