In this article, we will guide you through the process of web scraping with R. We’ll cover key relevant topics such as setting up the environment, an R-based web scraper workflow, a real scraping example, tips and tricks, and more.

Disclaimer: This material has been developed strictly for informational purposes. It does not constitute endorsement of any activities (including illegal activities), products or services. You are solely responsible for complying with the applicable laws, including intellectual property laws, when using our services or relying on any information herein. We do not accept any liability for damage arising from the use of our services or information contained herein in any manner whatsoever, except where explicitly required by law.
Table of Contents.
- Introduction to Web Scraping.
- Setting up the Environment for Web Scraping with R.
- Workflow: Four-Step Process for Web Scraping with R.
- Scraping Web Pages with our R-based Script.
- Ten Tips and Tricks for Web Scraping with R.
- Final Words.
1. Introduction to Web Scraping.
Web scraping is a process for automatically collecting and analyzing data from websites and web applications. It uses software (or bots) to navigate and access websites, retrieve HTML code, and parse the code to extract unstructured data. Additionally, the web scraping software also stores and structures the data in readable formats like XLS, CSV, SQL, or XML.
The overall goal of data scraping is to support decision-making and customized applications. It provides the following benefits:
- Data availability: Data scraping is key to accessing and using valuable data sources that are only available through websites.
- Data diversity: Web scraping helps collect data from diverse sources, including social media (like Facebook and Twitter), e-commerce platforms, news websites, and more.
- Automation: Web scraping automates the data collection process. Compared to manual data extraction, automation saves time and effort.
- Real-time data: Web scraping is also useful for capturing real-time or frequently updated data. Real-time data is useful for making up-to-date analysis and decision-making easier.
- Competitive advantage: Extracting data from competitor websites can provide insights for market research, pricing strategies, and identifying industry trends.
For everything there is to learn about this topic, check our web scraping guide.
a. What are some Web scraping tools
Web scraping tools can be as simple as scripts designed to extract data from the HTML structure of web pages. Of course, they can get more complex as developers introduce more automation into the equation. Some more advanced web scraping tools can be used for automated browsing. They simulate “real user” interaction with websites in order to access and extract dynamic content. Some of these tools can also automatically interact with web services through APIs to retrieve data or use text- or keyword-pattern matching to find specific pieces of content and extract data.
b. Why is essential to understand HTML and CSS deeply before web scraping with R?
Knowing HTML and CSS beforehand is crucial for effective web scraping with R or any other programming language. HTML is the underlying markup language used to structure and present web content, so knowing about it, will help you identify the elements that contain the data you need. In the same case, knowing CSS, which is used to define the visual appearance and layout of the HTML elements, is also vital. CSS selectors are particularly relevant in web scraping. These selectors allow you to target specific elements based on their attributes, classes, or other properties. Identifying CSS selectors will also allow you to extract the desired data.
As an example, the following CSS code example (on the right), uses a CSS selector > [name=”email”] to target specific elements (based on attribute and value). The selector applies a visual style (Red) to the HTML input field with the name attribute set to “email”. So this is useful in web scraping because you can combine different CSS selectors with a scraping library or tool and target/extract the desired information from the identified elements.
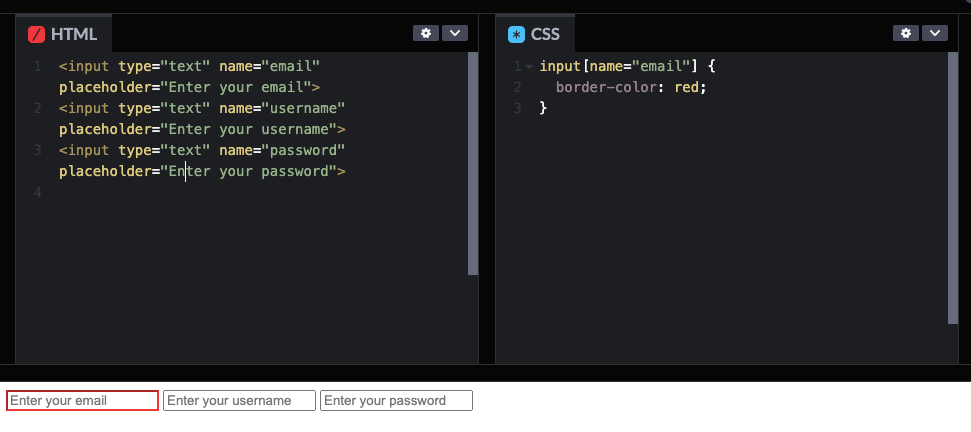
2. Setting up the Environment for Web Scraping with R
R (from the R project) is a powerful programming language for statistical computing and graphics. One of the advantages of using R for web scraping is that it provides various packages and libraries for web scraping tasks.
Note: Setting up the entire environment for R, is outside the scope of this article. We’ll however provide a checklist of all the things you need to get started with web scraping
a. How to start?
- To start web scraping with R, you’ll need to set up your environment properly. Obviously, your system must be already running R. Download R from the R project‘s homepage. We also recommend you check out RStudio— an IDE for R.
- You’ll also need to have the necessary tools and libraries installed and ready to use.
- Once you have your environment running and tested, you’ll need to install the necessary web scraping R packages (rvest, xml2, RSelenium, etc).
b. R-based libraries for web scraping.
- Rvest. Rvest is an R package for web scraping. It provides you with a convenient and expressive way to perform common scraping tasks while respecting website rules using features like polite. To install rvest package, run the following command in the R console.
| install.packages(“rvest”) |
- xml2: xml2 is an R package for parsing XML and HTML data. This package leverages the ‘libxml2‘ C library. It provides various functions for handling XML data in R programming. Install the xml2 package by running the following command:
| install.packages(“xml2”) |
- RSelenium: RSelenium is an R package that provides bindings for the Selenium WebDriver. It enables you to automate a web browser locally or remotely and drive browser actions programmatically.
c. Importing the libraries.
Once you have the necessary packages installed, you will need to import them into your R script or RStudio session. For importing libraries, use the library() function. As an example, here’s how to import the rvest and xml2 libraries:
| library(rvest) library(xml2) |
With access to these libraries, their functions and features will be available for you to use in your R-based web scraping project. You can include these library import statements at the beginning of your R script or in your RStudio session.
3. Workflow: Four-Step Process for Web Scraping with R:
In the following four-step workflow we provide a general overview of the web scraping with R. Each of these workflow steps includes a flow chart diagram and code example.
It’s important to note that each step can involve specific R functions or libraries based on your requirements and the structure of the web page you are scraping.
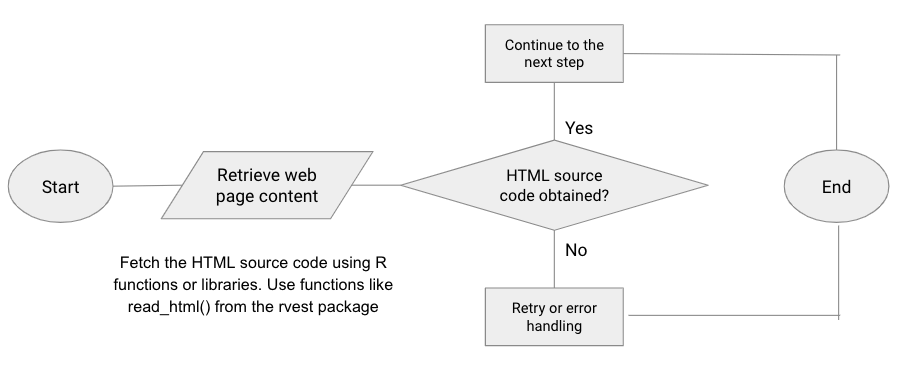
a. Retrieving web page content (with flow chart diagram + R code)
Use R functions or libraries to fetch the HTML source code of the desired web page. This can be done using functions like read_html() from the rvest package or GET() from the httr package. The retrieved HTML code contains the data you want to scrape.
Example Flowchart
Example R Code.
| library(rvest) # Specify the URL of the desired web page url <- “https://www.example.com” # Retrieve the HTML source code of the web page html <- read_html(url) # Print the retrieved HTML code print(html) |
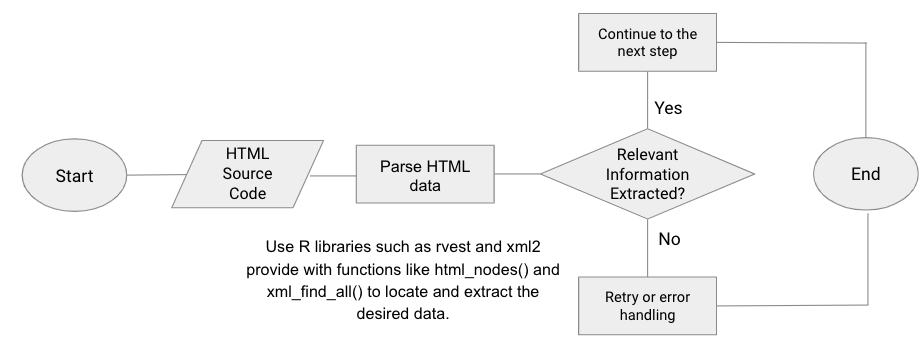
b. Parsing HTML data (with flow chart diagram).
Once you have the HTML source code, you would need to extract the relevant (or desired) information from it. This can be done using CSS selectors or XPath expressions to identify and select specific elements or attributes within the HTML structure. R libraries such as rvest and xml2 provide functions like html_nodes() and xml_find_all() to locate and extract this kind of desired data.
Example Flowchart.
Example R Code.
| library(rvest) # Specify the CSS selector to target specific elements css_selector <- “h1” # Extract the desired data using the CSS selector data <- html_nodes(html, css_selector) # Print the extracted data print(data) |
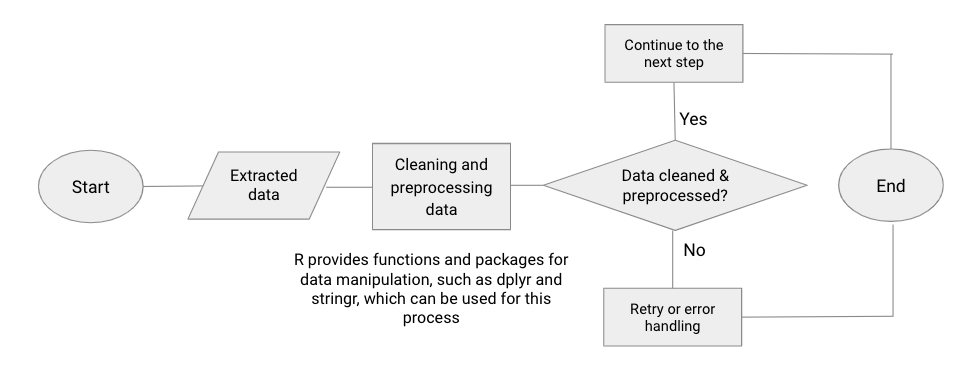
c. Cleaning and preprocessing data (with flow chart diagram + example code).
After extracting the data, it may require some cleaning and preprocessing to ensure its consistency. This involves handling inconsistencies, removing unnecessary characters or HTML tags, and converting data types if necessary. To accomplish this, R provides a wide range of functions and packages for data manipulation, such as dplyr and stringr.
Example Flowchart.
Example R Code.
| library(dplyr) library(stringr) # Assuming you have extracted the data and stored it in the ‘data’ variable # Handling inconsistencies or missing values cleaned_data <- na.omit(data) # Removing unnecessary characters or HTML tags cleaned_data <- str_remove_all(cleaned_data, “<.*?>”) # Converting data types if necessary cleaned_data <- mutate(cleaned_data, numeric_column = as.numeric(numeric_column)) # Further data cleaning and manipulation using dplyr functions cleaned_data <- cleaned_data %>% mutate(text_column = str_trim(text_column)) %>% filter(numeric_column > 0) %>% select(text_column, numeric_column) # Print the cleaned and preprocessed data print(cleaned_data) |
Want to enhance your web scraping with R?
Boost your web scraping efficiency with RapidSeedbox’s high-quality proxy services. Enjoy fast, secure, and anonymous scraping, supported by exceptional performance and reliability.
d. Storing scraped data (with flow chart diagram).
After cleaning and processing data, you can store it for further analysis or future reference. R allows you to store data, by exporting it to various file formats such as CSV, Excel, or JSON using functions like write.csv() or write.xlsx(). Additionally, you can also save the data to databases like MySQL or PostgreSQL using appropriate R packages such as RMySQL or RPostgreSQL.
Example Flowchart.
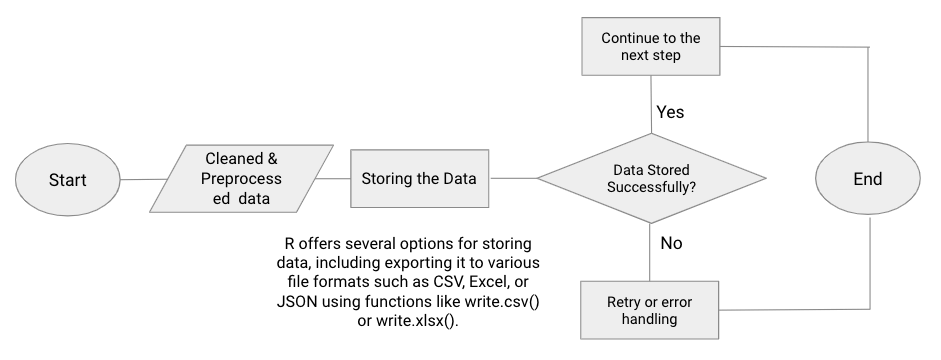
Example R Code.
| # Assuming you have cleaned and processed data stored in the ‘cleaned_data’ variable # Exporting data to CSV file write.csv(cleaned_data, “data.csv”, row.names = FALSE) # Exporting data to Excel file library(openxlsx) write.xlsx(cleaned_data, “data.xlsx”, row.names = FALSE) # Exporting data to JSON file library(jsonlite) write_json(cleaned_data, “data.json”) # Saving data to a MySQL database library(RMySQL) con <- dbConnect(RMySQL::MySQL(), dbname = “your_database”, host = “localhost”, port = 3306, user = “your_username”, password = “your_password”) dbWriteTable(con, “data_table”, cleaned_data) # Closing the database connection dbDisconnect(con) |
4. Scraping Web Pages with our R-based Script.
When we put everything together, our R script will perform basic data retrieval from a web page. It uses three pre-installed packages: rvest, stringr, and dplyr. These packages provide functions for web scraping, data manipulation, and string operations (respectively).
The four-step process script will begin by retrieving web page content (the desired URL). Once, the web page data is retrieved, the script will parse the HTML/CSS data. It uses the html_nodes() or html_text() functions to retrieve CSS selectors. In addition, the script can also be used to retrieve XPath expressions. The script will move on to the cleaning and preprocessing data process. It uses the str_replace_all() function to remove HTML tags. And finally, “the storing of the cleaned data” is processed by the write.csv() function.
The R-based script.
| library(rvest) library(stringr) library(dplyr) # 1. Retrieving web page content url <- “https://example.com” # Replace with the desired web page URL html <- read_html(url) # 2. Parsing HTML/CSS data # Example using CSS selectors data <- html %>% html_nodes(“.css_selector”) %>% # Replace “CSS_SELECTOR” with your desired selector html_text() # Example using XPath expressions # data <- html %>% # html_nodes(xpath = “XPATH_EXPRESSION”) %>% # Replace “XPATH_EXPRESSION” with your desired expression # html_text() # 3. Cleaning and preprocessing data cleaned_data <- str_replace_all(data, “<[^>]+>”, “”) # Remove HTML tags # Additional cleaning and preprocessing steps can be added as needed # 4. Storing scraped data # Example: Exporting data to a CSV file write.csv(cleaned_data, file = “scraped_data.csv”, row.names = FALSE) |
Running the script.
If you executed the script in RStudio, you can view the results and output in different ways.
- You can inspect the HTML object to see the retrieved HTML source code. Simply type HTML in the console and press Enter to display the content.
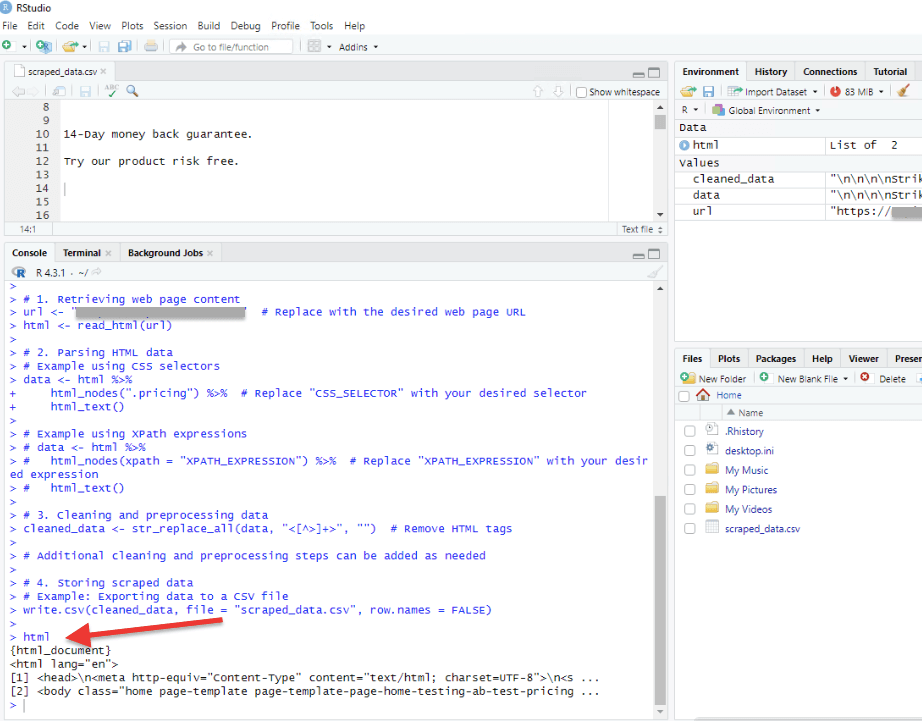
- After executing the lines under the “Parsing HTML/CSS Data” section, the script will extract the data and store it in the ‘data’ variable.
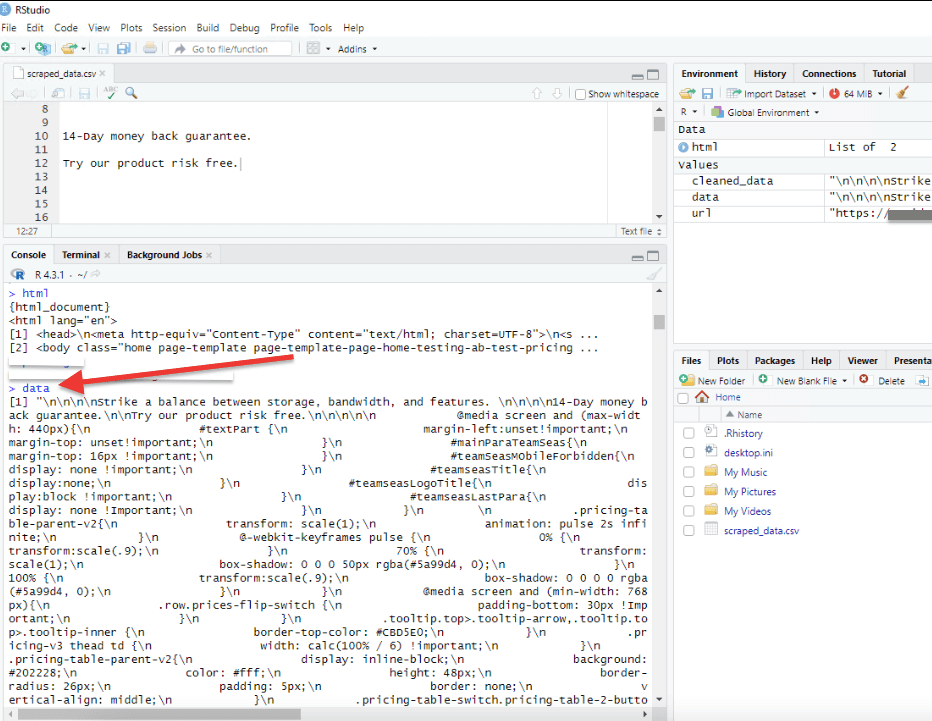
- Type ‘data’ in the console to display the extracted data. The results will show the data but in an unstructured and ‘uncleaned’ manner.
- Since our script also cleans and pre-processes the data, the results: ‘cleaned data’ will be stored in the cleaned_data variable. Type ‘cleaned_data’ in the console to see the cleaned data.
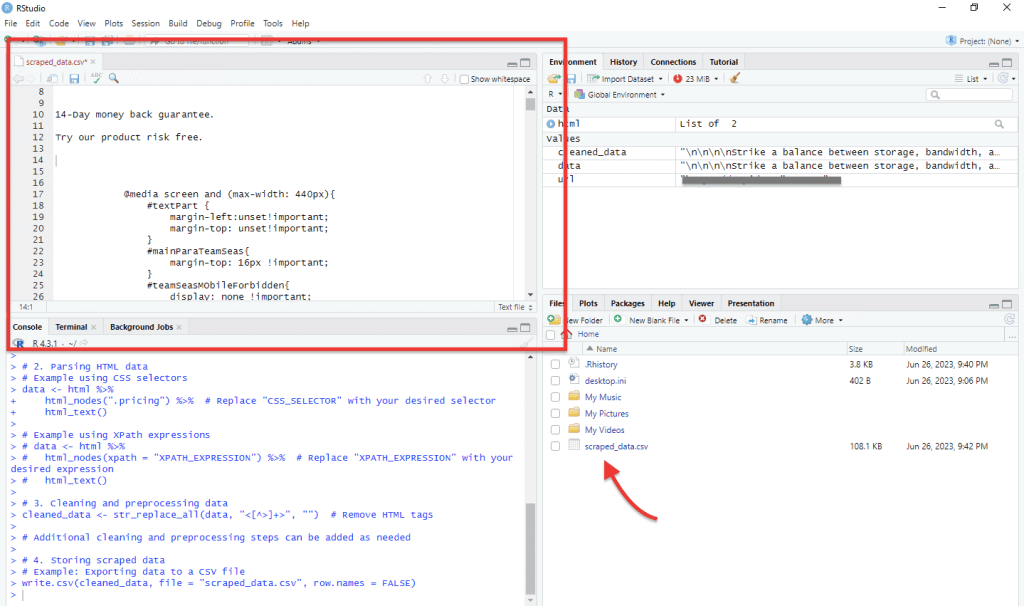
- And finally, the R script includes an example of exporting the cleaned data to a CSV file named “scraped_data.csv”. After executing the last line write.csv(cleaned_data, file = “scraped_data.csv”, row.names = FALSE), you can check the RStudio file viewer or your computer’s file explorer to locate the generated CSV file.
Additionally, you can use print() or cat() functions at various points in the script to display intermediate results or progress messages in the RStudio console. This can be helpful for debugging or monitoring the script’s execution.
5. Ten Tips and Tricks for Web Scraping with R.
The following ten tips and tricks are quite useful when developing your own web scraping project with R. By incorporating these into your workflow, you’ll be equipped to tackle various challenges, extract data efficiently, and conduct web scraping activities in an ethical and compliant manner.
a. Understand the HTML structure
Knowing your HTML and CSS 101’s is paramount. Gain a thorough understanding of the HTML structure of the target website to effectively locate and extract the desired data.
b. Use CSS selectors wisely.
CSS selectors are powerful tools for targeting specific elements. Learn about CSS selectors and understand how to utilize them to extract the required data accurately.
c. Know how to handle different types of data.
Web scraping involves extracting various types of data; not only text, but also tables, images, and links. Familiarize yourself with techniques to scrape each type effectively.
d. Write efficient and scalable web scraping code.
When writing web scraping code, learn how to optimize your code using efficient algorithms and data structures. Also, implement rate limiting to respect the website’s server capacity and use asynchronous scraping.
e. Clean and preprocess scraped data.
As shown in our previous example, data cleaning and preprocessing are paramount. Knowing how to do these efficiently will help you remove unwanted characters, handle missing data and outliers, and ensure data integrity.
f. Choose appropriate data storage options.
Export the scraped data to suitable file formats such as CSV, Excel, or databases based on your requirements. Consider using APIs to send scraped data to other applications.
g. Pagination and multiple pages.
Learn to develop strategies to handle pagination and scrape data from multiple pages efficiently. Identify patterns and elements that indicate page navigation. Adapt your scraping code accordingly.
h. Learn how to handle dynamic content.
Knowing about JavaScript and its role in dynamic web pages is crucial for web scraping. You’ll need to utilize tools like RSelenium to interact with JavaScript-driven websites and scrape data that requires user interaction.
i. Overcome anti-scraping measures.
Be aware of common anti-scraping techniques such as CAPTCHA and IP blocking. Implement strategies like using proxies or rotating user agents to bypass these measures when necessary.
j. Keep your ethical considerations.
Web scraping has a bad reputation and is often blocked by different sites and services. Always, adhere to website terms of service and legal boundaries while scraping. Practice crawler politeness by implementing rate limiting and respecting the server’s capacity. Ensure compliance with data privacy regulations and intellectual property rights to avoid any legal issues.
Want to enhance your web scraping with R?
Boost your web scraping efficiency with RapidSeedbox’s high-quality proxy services. Enjoy fast, secure, and anonymous scraping, supported by exceptional performance and reliability.
Final Words.
In this post, we only scratch the surface of everything you can do related to web scraping with R.
Remember before starting your project, to get to understand HTML structure and how to use CSS selectors effectively. Later on, it is paramount to learn how to handle different types of data, clean and preprocess scraped data, choose appropriate storage options, and learn how to overcome anti-scraping measures ethically.
Take the code example we used in this post and tweak it to your preferences. With this knowledge, you will extract valuable insights and automate the data collection process like a pro!
Happy scrapping!
0Comments