Dengan lebih dari 666 juta pengguna aktif, aplikasi Twitter, yang kini berganti menjadi Xadalah salah satu platform media sosial paling populer dan sumber informasi yang berharga bagi bisnis, peneliti, dan individu. Namun, mengekstrak dan menyaring data secara manual dari domain data Twitter yang sangat luas merupakan hal yang luar biasa dan tidak fungsional.

Untuk melakukan scraping pada Twitter, kamu perlu melibatkan penggunaan software atau script untuk mengumpulkan data dari platform tersebut. Kamu dapat menganalisis data ini untuk mendapatkan berbagai insight terkait topik dan hashtags yang sedang tren, juga obrolan, interaksi, dan perilaku pengguna.
Informasi yang terkumpul dapat dianalisis dengan cermat untuk berbagai tujuan, seperti analisis sentimen, riset pasar, dan pemantauan media sosial. Artikel ini akan membahas berbagai aspek dari scraping data Twitter menggunakan metode yang ada, mulai dari script hingga software tanpa coding, biaya yang akan kamu keluarkan, hingga legalitas dan etika
Disclaimer: Materi ini dikembangkan secara khusus untuk tujuan informasional semata. Panduan ini tidak menyiratkan dukungan terhadap aktivitas (termasuk aktivitas ilegal), produk, atau layanan apapun. Kamu sepenuhnya bertanggung jawab untuk mematuhi hukum yang berlaku, termasuk hukum kekayaan intelektual saat menggunakan layanan kami atau mengandalkan informasi di sini. Kami tidak menerima tanggung jawab atas kerusakan yang timbul dari penggunaan layanan kami atau informasi yang terkandung di sini dengan cara apapun, kecuali jika secara tegas diwajibkan oleh hukum.
Daftar Isi
Jenis Data Apa yang Dapat Diekstrak dari Twitter?
Anda dapat mengekstrak berbagai jenis data Twitter. Berikut ini tiga jenis data utama untuk pengikisan Twitter:
- Tweet: Kamu dapat mengambil data spesifik dari tweet yang difilter berdasarkan profil, seperti like, reply, retweet, dan URL tertentu.
- Profil Pengguna: Apapun yang ada di profil pengguna publik dapat kamu kumpulkan, seperti bio pengguna, deskripsi profil, jumlah tweet, retweet, jumlah pengikut/pengikut, dan foto profil.
- Keywords/Hashtags: Kamu dapat mengumpulkan kata kunci, hashtag, atau kombinasi dari keduanya. Kamu juga dapat mempersempit pencarian berdasarkan jumlah like atau dengan mencari tanggal dan waktu tertentu.
Ketentuan Legalitas dan Etika Penggunaan
Ketika mendalami data scraping, kamu harus memahami batasan hukum dan etika yang berlaku.
Menurut Persyaratan dan peraturan Twitter (Developer Agreement and Policy), scraping data tanpa izin eksplisit dilarang dan dinyatakan dalam kebijakan Twitter: "Scraping tanpa persetujuan sebelumnya dari Twitter secara tegas dilarang.
Setiap penyalahgunaan API Twitter untuk tujuan ini akan dikenakan tindakan penegakan hukum, yang mungkin termasuk penangguhan dan penghentian akses.
Panduan Umum untuk Scraping Twitter
Setelah pengenalan singkat tentang scraping Twitter, sekarang saatnya untuk menjelajahi proses scraping melalui data Twitter. Oleh karena itu, kami telah menyusun panduan sederhana dan komprehensif untuk scraping Twitter untuk Anda. Silakan ikuti langkah-langkah di bawah ini:
- Pertama, kamu harus memiliki scraping tools yang tepat. Ada banyak opsi yang bisa dipilih. Jadi, tentukan opsi mana yang sesuai dengan anggaran dan preferensimu.
- Unduh dan instal scraping tools.
- Pastikan ada banyak ruang penyimpanan tersedia di perangkat Anda dan Anda memiliki koneksi internet yang andal.
- Setelah menginstal, masuk menggunakan detail akun Twitter.
- Menyesuaikan parameter untuk scraping data dari Twitter adalah langkah penting agar kamu bisa mengekstrak data berdasarkan keyword, hashtag, tanggal dan waktu, lokasi, URL, dll.
- Setelah menjalankan scraping tools, kamu dapat mengekspor data ke berbagai format file (xlsx, CSV, JSON, dll.).
- Pada langkah terakhir, kamu harus menganalisis data yang telah diekspor untuk mendapatkan insight tentang topik yang kamu cari.
Tools dan Metode Scraping Twitter
Kami telah meninjau beberapa alat scraping yang tersedia di internet, dari yang resmi Pengikis Twitter ke layanan pihak ketiga dan bahkan pustaka Python sumber terbuka, dan mencantumkannya di bawah ini.
4.1. Pengikis Twitter Berbasis API
Metode pertama yang akan kita lihat adalah scraper Twitter berbasis API, yang meliputi Twitter API V2, Apify, Brightdata, dan Scrapingdog.
4.1.1. API Twitter V2
Twitter API v2 adalah versi terbaru dari API Twitter, API resmi dan salah satu API yang paling sering digunakan oleh para developer yang membuat aplikasi dengan interaksi sosial atau peneliti/individu yang mengumpulkan data untuk tujuan tertentu. Penggunaan API ini memungkinkan pemantauan dan analisis percakapan langsung di jejaring sosial dengan mudah.
Baru-baru ini, Twitter telah menambahkan beberapa fitur baru, seperti titik akhir, opsi muatan untuk posting tweet, set pengenal percakapan, dan anotasi. Perubahan ini cukup mengesankan. Namun, struktur harga yang baru telah menimbulkan kekhawatiran serius bagi para pengembang dan aplikasi pihak ketiga. Dengan struktur harga yang baru, akses ke layanan telah menurun secara dramatis, dan harga meningkat secara drastis.
Paket harga Twitter/X API v2 memiliki tiga tingkatan: Gratis, Dasardan Perusahaan.
- Di pilihan free, pengembang dapat memposting hingga 1500 tweet per bulan, yang dirancang untuk menulis dan menguji API Twitter.
- Pada opsi Basic, pengembang harus membayar $100 per bulan untuk mendapatkan hingga 3.000 tweet per bulan di tingkat pengguna dan 50.000 tweet (dengan batas baca 10.000) di tingkat aplikasi.
- Opsi pembayaran Enterprise memiliki fitur-fitur yang lebih canggih dan dirancang untuk kebutuhan bisnis. Namun, paket enterprise ini membebani developers/bisnis karena harganya yang sangat tinggi, yaitu hampir 42000$ per bulan.
4.1.2. Apify
Melalui Twitter Scraper dari Apify, kamu dapat mengekstrak informasi dari data Twitter yang tersedia untuk umum seperti hashtag, threads, reply, gambar, dan banyak lagi. Perubahan terbaru pada Twitter memberikan batasan baru dalam melihat dan scraping tweet di platform ini, karena pengguna hanya akan mengekstrak informasi publik hingga 100 tweet per profil. Scraper ini tidak dapat mengikis tweet terbaru tetapi dapat mengambil tweet yang paling disukai. Data yang diekstrak dapat diakses dalam format HTML, JSON, Excel, dan CSV.
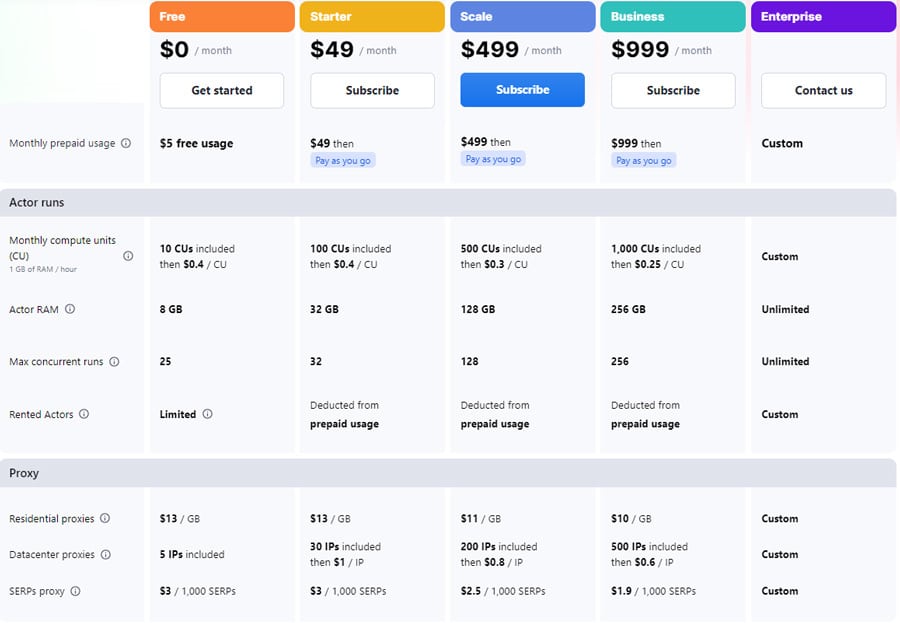
Gambar berikut ini mengilustrasikan biaya layanan bulanan dari Apify. Layanan ini juga menawarkan diskon 10% untuk paket tahunan. Untuk informasi lebih lanjut, kunjungi Penetapan harga Apify.
4.1.3. Brightdata
Bright Data adalah platform pengumpulan data yang menawarkan web scraping tools, seperti server proxy, API, dan no-code solutions. Web Scraper Bright Data memberikan pengguna kemampuan untuk mengekstrak data dari profil Twitter publik, termasuk gambar, video, tweet, hashtags, dan banyak lagi.
Harga mulai dari 500$ bulanan untuk 15.000 halaman. Bright Data Twitter scraper data collector kompatibel dengan semua layanan web dan hasil datanya berformat Excel. Layanan ini juga menawarkan uji coba 7 hari, dan kamu bisa mencoba gratis platform ini sebelum membayar 500 dolar.
Siap tingkatkan kemampuan Twitter Scraper?
4.1.4. Scrapingdog
Scrapingdog adalah API web scraping yang membantumu untuk scraping situs web apapun, termasuk Twitter. API ini dapat melakukan scraping tweet menggunakan ID tweet atau scraping berbagai laman publik untuk mengekstrak detail seperti follower, jumlah follower, dan website links.
Kamu akan dikenakan biaya 0,0009$ per halaman untuk scraping Twitter dalam paket standarnya saja sudah merupakan salah satu paket terbaik dari segi harga dibandingkan dengan Twitter scraper lainnya. Tool ini juga menyediakan uji coba gratis; kamu juga bisa membatalkan langgananmu kapan saja dan uangmu akan kembali dengan mudah. Untuk informasi lebih lanjut tentang cara scraping data menggunakan Scrapingdog, kamu dapat mengunjungi Dokumentasi Twitter Scraping API.
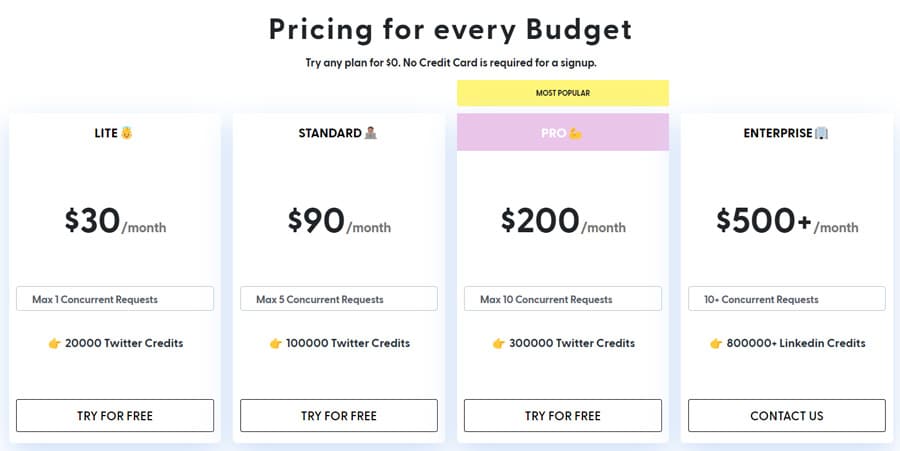
4.2. Python Libraries dan Packages untuk Scraping Twitter
Kamu sudah semakin mengenal API Twitter dan aplikasi seperti Apify, nah sekarang saatnya untuk melihat Python libraries dan packages untuk Twitter scraping.
4.2.1. Tweepy
Tweepy adalah open-source Python package yang memungkinkan developer untuk mengakses endpoint Twitter dengan lancar dan transparan. Namun, perlu kamu ketahui bahwa Twitter telah memberlakukan batasan pada jumlah permintaan yang dikirim ke API X/Twitter, di mana hanya 900 permintaan diperbolehkan setiap 15 menit. Pada bagian ini, kami bertujuan untuk melihat fungsionalitas Tweepy dan memberikan contoh sederhana.
Untuk memulai, instal paket Tweepy menggunakan perintah "pip install Tweepy" pada IDE Python dan kemudian impor Tweepy juga. Lalu, daftarkan aplikasi klienmu ke Twitter. Buatlah sebuah aplikasi baru. Setelah selesai, kamu akan menerima bearer token.
|
1 2 |
pip install tweepy import tweepy |
Selanjutnya, kamu harus membuat instance "Client" untuk meneruskan bearer token yang telah kamu dapatkan dari API Twitter.
Dalam variabel query, kami menentukan sebuah field, mention, dan hashtag seperti yang ditunjukkan.
|
1 2 3 |
client = tweepy.Client(bearer_token='bearer_token') query = 'query @mentions #hashtags' |
Untuk mencari tweet dari tujuh hari terakhir, kamu dapat menggunakan fitur search_recent_tweets yang tersedia di Tweepy. Untuk menentukan data yang kamu cari, kamu harus memasukkan query pencarian.
|
1 2 |
recent_tweets = client.search_recent_tweets(query=query, tweet_fields=['tweet_field_1', 'tweet_field_2'], max_results=100) |
Jika kamu memiliki akses ke produk penelitian akademis, kamu dapat mengambil tweet yang berusia lebih dari 7 hari dari arsip lengkap tweet yang tersedia untuk umum.
|
1 2 |
tweets = client.search_all_tweets(query=query, tweet_fields=['tweet_field_1', 'tweet_field_2'], max_results=100) |
Kamu dapat mengekspor hasilnya menggunakan kode berikut.
|
1 2 3 4 5 |
for tweet in tweets.data: print(tweet.text) if len(tweet.context_annotations) > 0: print(tweet.context_annotations) |
Ada juga banyak fungsi di Tweepy yang mampu melakukan berbagai tugas dalam kasus yang lebih kompleks dan spesifik.
4.2.2. Snscrape
Cara lain untuk mendapatkan informasi dari Twitter tanpa bergantung pada API adalah melalui Snscrape. Snscrape memungkinkan Anda untuk mengambil informasi dasar seperti profil pengguna, konten tweet, sumber, dll. Tidak seperti Tweepy, tidak ada batasan jumlah tweet yang dapat Anda kikis atau tanggal tweet, dan Anda dapat mengekstrak data Twitter lama. Karena Snscrape tidak terhubung ke API Twitter, maka Snscrape tidak memiliki fungsionalitas seperti Tweepy. Lihat panduan lengkap kami untuk Snscrape.
Pada bagian ini, kami juga mengulas contoh dasar untuk mengikis beberapa data dari Twitter menggunakan Snscrape di Python.
Pertama, kamu harus menginstal Snscrape. Perhatikan bahwa kamu harus menginstal Python 3.8 atau lebih tinggi.
|
1 2 |
pip install snscrape |
Pada langkah berikutnya, instal library berikut ini.
|
1 2 3 |
import snscrape.modules.twitter as sntwitter import pandas as pd |
Kami mengirim query (dalam contoh ini, "query") menggunakan fungsi "TwitterSearchScraper (query).get_items" dan mendapatkan elemen dari pencarian seperti halnya hasil dari kolom pencarian Twitter.
|
1 2 3 4 5 6 |
query = "query" for tweet in sntwitter.TwitterSearchScraper(query).get_items(): print(vars(tweet)) break |
Ada metode lain yang dapat digunakan untuk melakukan data scraping dari Twitter, seperti: TwitterSearchScraper, TwitterUserScraper, TwitterProfileScraper, TwitterHashtagScraper, TwitterTweetScraperMode, TwitterTweetScraper, TwitterListPostsScraper, TwitterTrendsScraper.
Teknik dan Tantangan Pengikisan Tingkat Lanjut
Ketika metode pengikisan dasar mencapai batasnya dengan pertahanan Twitter yang canggih, teknik-teknik canggih menjadi sangat penting. Antarmuka modern Twitter sangat bergantung pada rendering JavaScript dan mengimplementasikan beberapa lapisan deteksi bot, sehingga permintaan HTTP tradisional tidak cukup untuk pengumpulan data yang andal.
Menangani Konten Dinamis dengan Browser Tanpa Kepala
Linimasa Twitter dimuat secara dinamis melalui JavaScript, yang berarti konten yang Anda lihat tidak ada dalam respons HTML awal. Browser tanpa kepala mensimulasikan interaksi pengguna yang sebenarnya, merender JavaScript dan menangani pemuatan konten dinamis.
Playwright vs Selenium: Playwright menawarkan kinerja yang lebih baik dan penanganan yang lebih andal untuk aplikasi web modern, sementara Selenium tetap menjadi pilihan yang mapan dengan dukungan komunitas yang luas.
Berikut ini contoh praktis menggunakan Playwright untuk mengikis tweet yang dimuat secara dinamis:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
import asyncio dari penulis naskah.async_api import async_playwright import json async def mengikis_twitter_profil(nama pengguna): async dengan async_playwright() as p: # Meluncurkan browser tanpa kepala browser = menunggu p.kromium.peluncuran(tanpa kepala=Benar) konteks = menunggu browser.new_context( user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36" ) halaman = menunggu konteks.new_page() mencoba: # Menavigasi ke profil menunggu halaman.goto(f"https://twitter.com/{nama pengguna}") # Tunggu hingga tweet dimuat menunggu halaman.tunggu_untuk_pemilih('[data-testid="tweet"]', batas waktu=10000) # Gulir untuk memuat lebih banyak tweet for i in jangkauan(3): menunggu halaman.mengevaluasi("window.scrollTo(0, document.body.scrollHeight)") menunggu halaman.tunggu_untuk_waktu_berakhir(2000) # Mengekstrak data tweet tweets = menunggu halaman.mengevaluasi(""" () => { const tweetElements = document.querySelectorAll('[data-testid="tweet"]'); return Array.from(tweetElements).map(tweet => { const textElement = tweet.querySelector('[data-testid="tweetText"]'); const timeElement = tweet.querySelector('time'); kembali { text: textElement ? textElement.innerText : '', timestamp: timeElement ? timeElement.getAttribute('datetime') : '', url: window.location.href }; }); } """) kembali tweets kecuali Pengecualian as e: print(f"Kesalahan penggosokan {nama pengguna}: {e}") kembali [] akhirnya: menunggu browser.tutup() Penggunaan # tweets = asyncio.jalankan(mengikis_twitter_profil("elonmusk")) print(json.dumps(tweets[:3], indentasi=2)) |
Keunggulan utama browser tanpa kepala termasuk menangani rendering JavaScript, mengelola cookie dan sesi secara otomatis, dan mem-bypass deteksi bot dasar melalui sidik jari browser yang realistis.
Pertimbangan sumber daya: Browser tanpa kepala mengkonsumsi lebih banyak memori dan CPU secara signifikan dibandingkan dengan permintaan HTTP sederhana. Untuk operasi berskala besar, pertimbangkan untuk menjalankan beberapa contoh browser di server yang berbeda atau menggunakan kumpulan browser.
Melewati Tindakan Anti-Gores
Twitter menggunakan deteksi bot yang canggih yang lebih dari sekadar pembatasan laju. Memahami langkah-langkah ini membantu mengembangkan tindakan pencegahan yang efektif.
Teknik Anti-Gores yang Umum
Pembatasan Tarif: Twitter monitors request frequency per IP address, implementing both short-term (requests per minute) and long-term (daily quotas) limits. Learn more in Web Scraping Rate Limiting: The Fix.
Pemblokiran IP: Alamat IP yang mencurigakan akan diblokir sementara atau permanen. IP pusat data menghadapi lebih banyak pengawasan daripada alamat tempat tinggal.
Tantangan CAPTCHA: Penyajian CAPTCHA otomatis ketika perilaku seperti bot terdeteksi. CAPTCHA modern menggunakan analisis perilaku di luar pengenalan gambar sederhana.
Sidik Jari Peramban: Analisis karakteristik peramban termasuk agen pengguna, resolusi layar, plugin yang diinstal, dan pola eksekusi JavaScript.
Tindakan Penanggulangan yang Efektif
Strategi Rotasi Proxy: Menggunakan layanan seperti RapidSeedbox menyediakan akses ke kumpulan IP perumahan yang muncul sebagai lalu lintas pengguna yang sah. Proxy perumahan dari 6,9+ juta jaringan IP mereka secara signifikan mengurangi deteksi dibandingkan dengan proxy pusat data.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
import acak import waktu dari itertools import siklus Pengaturan rotasi Proxy # proxy_list = [ "http://user:[email protected]:8080" ] proxy_cycle = siklus(proxy_list) def get_next_proxy(): kembali berikutnya(proxy_cycle) # Menerapkan di scraper Anda async def mengikis_dengan_rotasi(): for i in jangkauan(10): proxy = get_next_proxy() # Konfigurasikan browser/sesi Anda dengan proxy baru # Melakukan permintaan pengikisan # Tambahkan penundaan acak menunggu asyncio.tidur(acak.seragam(5, 15)) |
Rotasi Agen Pengguna: Variasikan tanda tangan peramban untuk menghindari deteksi pola. Gunakan string agen pengguna nyata dari browser dan sistem operasi yang berbeda.
|
1 2 3 4 5 6 7 8 9 |
USER_AGENTS = [ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, seperti Gecko) Chrome/120.0.0.0 Safari/537.36", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, seperti Gecko) Chrome/120.0.0.0 Safari/537.36", "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:121.0) Gecko/20100101 Firefox/121.0" ] def get_random_user_agent(): kembali acak.pilihan(USER_AGENTS) |
Pola Perilaku: Meniru perilaku penjelajahan manusia dengan penundaan yang bervariasi, pola pengguliran yang realistis, dan sesekali melakukan aktivitas tanpa menggores.
Manajemen Sesi: Pertahankan sesi yang konsisten dengan penanganan cookie yang tepat dan hindari membuat terlalu banyak sesi baru dari IP yang sama.
Penghindaran Deteksi Tingkat Lanjut
Permintaan Waktu: Menerapkan backoff eksponensial ketika menemui batas laju. Mulailah dengan penundaan yang lebih lama dan secara bertahap kurangi penundaan tersebut berdasarkan tingkat keberhasilan.
Konsistensi Geolokasi: Saat menggunakan proxy, pastikan permintaan Anda mempertahankan konsistensi geografis. Jangan berpindah-pindah negara dengan cepat.
Manajemen Sidik Jari Browser: Gunakan alat bantu seperti undetected-chromedriver atau plugin siluman untuk mengurangi efektivitas sidik jari peramban.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
dari selenium import webdriver dari selenium_stealth import siluman def membuat_stealth_driver(): pilihan = webdriver.ChromeOptions() pilihan.add_argument("--tanpa kepala") pilihan.add_argument("--tanpa-kotak-pasir") pilihan.add_argument("--nonaktifkan-penggunaan-dev-shm") pengemudi = webdriver.Chrome(pilihan=pilihan) siluman(pengemudi, bahasa=["en-US", "en"], vendor="Google Inc.", platform="Win32", webgl_vendor="Intel Inc.", penyaji="Mesin Intel Iris OpenGL", perbaiki_garis_rambut=Benar, ) kembali pengemudi |
Penanganan Kesalahan: Menerapkan penanganan kesalahan yang baik yang dapat membedakan antara pemblokiran sementara, pemblokiran permanen, dan masalah teknis.
Kombinasi proksi residensial dari layanan seperti RapidSeedbox, teknik penyamaran peramban yang tepat, dan pola perilaku yang realistis menciptakan fondasi yang kuat untuk pengumpulan data Twitter berskala besar sekaligus meminimalkan risiko deteksi.
Ingatlah bahwa tindakan anti-bot Twitter terus berkembang, sehingga keberhasilan scraping membutuhkan adaptasi berkelanjutan dari teknik-teknik ini berdasarkan perilaku platform saat ini.
FAQ
Pengurasan Twitter berada di area abu-abu secara hukum. Meskipun Persyaratan Layanan Twitter melarang pengumpulan data otomatis, mengais data yang tersedia untuk umum tidak secara otomatis ilegal.
Risiko-risiko hukum meliputi:
1. Pelanggaran hak cipta atas konten pengguna
2. Pelanggaran CFAA di beberapa yurisdiksi
3. Masalah kepatuhan GDPR dengan data pribadi
Pendekatan yang lebih aman: Gunakan API resmi Twitter jika memungkinkan, konsultasikan dengan penasihat hukum untuk proyek-proyek besar, dan fokuslah pada data yang tersedia secara publik untuk tujuan penelitian yang sah.
Tidak, tetapi pengkodean memberikan hasil yang lebih baik.
Opsi tanpa kode: Alat bantu otomatisasi peramban dan pembangun alur kerja visual berfungsi untuk pengikisan dasar, tetapi kecepatan dan fleksibilitasnya terbatas.
Solusi pengkodean: Python dengan Selenium atau pustaka khusus menawarkan kontrol yang lebih besar, penanganan anti-bot yang lebih baik, dan tingkat keberhasilan yang lebih tinggi.
Pendekatan terbaik: Mulailah dengan alat tanpa kode untuk menguji kebutuhan Anda, lalu pelajari skrip Python dasar untuk pengumpulan data yang serius.
Tingkat API gratis Twitter memiliki batasan yang ketat:
1. Batas tarif: Kuota permintaan bulanan yang sangat rendah
2. Data historis: Terbatas pada tweet terbaru (biasanya seminggu terakhir)
3. Fitur: Tidak ada metrik analitik lanjutan atau metrik keterlibatan
4. Akses: Membutuhkan persetujuan aplikasi
Sebagian besar kasus penggunaan penelitian dan bisnis melebihi batas tingkat gratis, sehingga diperlukan paket berbayar atau metode alternatif.
Data historis Twitter memerlukan alat khusus karena penelusuran biasa hanya menampilkan konten terbaru.
Alat terbaik: Snscrape - Pustaka Python mengakses tweet dari beberapa tahun yang lalu dengan pemfilteran rentang tanggal.
Opsi lainnya:
1. Perpustakaan TwitterScraper
2. API Penelitian Akademik (diperlukan akses institusional)
3. Layanan data historis pihak ketiga
Tip: Pengikisan historis lebih lambat dan memerlukan pembatasan laju yang cermat untuk menghindari pemblokiran.
Praktik-praktik penting:
1. Pembatasan tarif: Minimum 1-2 detik di antara permintaan
2. Hormati robot.txt: Ikuti panduan platform
3. Minimalisasi data: Kumpulkan hanya informasi yang diperlukan
4. Penundaan yang tepat: Gunakan rotasi IP dan proxy tempat tinggal
5. Penanganan kesalahan: Berhenti menggores jika diblokir atau dibatasi kecepatannya
Prinsip utama: Selalu coba API resmi terlebih dahulu, lalu lakukan scraping secara bertanggung jawab dengan tetap menghormati infrastruktur Twitter dan privasi pengguna.
Kesimpulan
Twitter adalah sumber informasi sosiologis yang berharga di dunia maya. Dengan memanfaatkan informasi dari hasil scraping Twitter, kamu dapat merancang strategi penjualan dan meningkatkan pemasaran produkmu. Dalam artikel ini, kami telah menyajikan gambaran mendalam tentang berbagai aspek dan metode penguraian Twitter untuk mengekstraksi data yang dapat bermanfaat bagi bisnis atau penelitian.
Singkatnya, berdasarkan batasan baru yang diberlakukan pada Twitter API v2, bersama dengan biaya yang tinggi, memilih scraper terbaik akan menjadi tantangan. Anda dapat memanfaatkan fitur yang lebih canggih pada API Twitter atau aplikasi pihak ketiga dan pustaka Python (Tweepy) yang terhubung langsung ke API Twitter.
Tetapi jumlah permintaan yang bisa Anda buat sangat terbatas. Di sisi lain, jika Anda ingin mengikis data yang tersedia untuk umum dan fitur dasarnya memenuhi kebutuhan Anda, opsi seperti pustaka Python Snscrape bisa menjadi pilihan yang bagus.
0Komentar