In this ultimate guide, we will explore the world of web scraping, a powerful technique to extract data from websites. rat
Baik Anda seorang pemula yang ingin tahu tentang konsep ini atau seorang programmer berpengalaman yang ingin meningkatkan kemampuan Anda, panduan ini memiliki sesuatu yang berharga untuk semua orang. Mulai dari memahami dasar-dasar ekstraksi data HTML menggunakan CSS dan XPath penyeleksi hingga praktik scraping web dengan Python, kami siap membantu Anda. Selain itu, kami akan membahas aspek hukum, pertimbangan etika, dan praktik terbaik untuk memastikan web scraping yang bertanggung jawab.

Disclaimer: Materi ini dikembangkan secara khusus untuk tujuan informasional semata. Panduan ini tidak menyiratkan dukungan terhadap aktivitas (termasuk aktivitas ilegal), produk, atau layanan apapun. Kamu sepenuhnya bertanggung jawab untuk mematuhi hukum yang berlaku, termasuk hukum kekayaan intelektual saat menggunakan layanan kami atau mengandalkan informasi di sini. Kami tidak menerima tanggung jawab atas kerusakan yang timbul dari penggunaan layanan kami atau informasi yang terkandung di sini dengan cara apapun, kecuali jika secara tegas diwajibkan oleh hukum.
Daftar Isi.
- Apa itu Web Scraping dan Bagaimana Cara Kerjanya?
- Dasar-dasar Ekstraksi Data HTML: CSS dan XPath Selector.
- Web Scraping dengan Python (+ Kode).
- Apakah Web Scraping Legal?
- Bagaimana Cara Situs Web Memblokir Web Scraping?
- Etika dan Praktik Terbaik untuk Web Scraping.
- Web Scraping: Yang Sering DItanyakan (FAQ)
- Kesimpulan.
1. Apa itu Web Scraping dan Bagaimana Cara Kerjanya?
Web scraping (juga dikenal sebagai web harvesting atau ekstraksi data) adalah proses mengekstraksi data secara otomatis dari situs web, layanan web, dan aplikasi web.
Web scraping membantu kita untuk tidak perlu masuk ke setiap situs web dan menarik data secara manual, karena proses itu panjang dan tidak efektif. Proses ini melibatkan penggunaan script atau program otomatis. Script atau program tersebut mengakses struktur HTML dari halaman web, mem-parsing data, dan mengekstraksi elemen-elemen tertentu yang diperlukan dari halaman untuk analisis lebih lanjut.
a. Untuk Apa Web Scraping Digunakan?
Web scraping sangat bermanfaat jika dilakukan secara bertanggung jawab. Secara umum, bisa digunakan untuk riset pasar dan belajar tentang tren di pasar tertentu. Hal Ini juga biasa digunakan dalam pemantauan strategi dan harga kompetitor, dll.
Contoh kasus yang lebih spesifik lagi adalah:
- Media Sosial (Scraping Facebook dan Twitter)
- Monitoring perubahan harga secara online,
- Ulasan produk,
- Kampanye SEO,
- Real estate listing
- Melacak data cuaca,
- Melacak reputasi situs web,
- Memantau ketersediaan dan harga penerbangan,
- Uji coba iklan tanpa terbatas lokasi,
- Memantau sumber daya keuangan,
b. Bagaimana cara kerja Web Scraping?
Hal-hal yang umumnya terlibat dalam web scraping adalah inisiator dan target. Inisiator (web scraper) menggunakan software ekstraksi data otomatis untuk men-scrape situs web. Sedangkan, targetnya adalah konten situs web, informasi kontak, formulir, atau apapun yang tersedia secara publik di web.
Umumnya, beginilah prosesnya:
- LANGKAH 1: Inisiator menggunakan software scraping (yang bisa berupa layanan berbasis cloud atau script buatan sendiri) untuk mulai menghasilkan HTTP request (digunakan untuk berinteraksi dengan situs web dan mengambil data). Software ini dapat memulai apa saja dari permintaan HTTP GET, POST, PUT, DELETE, atau HEAD, hingga permintaan OPTIONS ke situs web target.
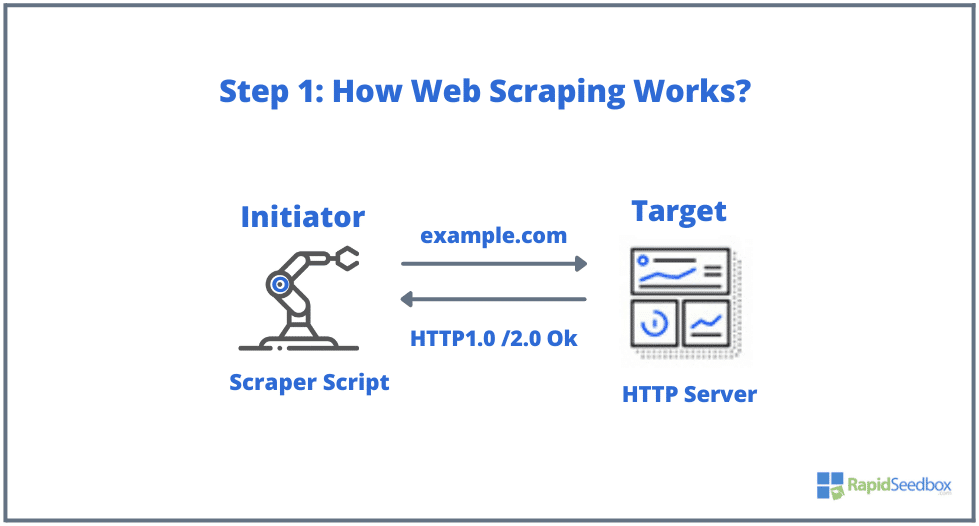
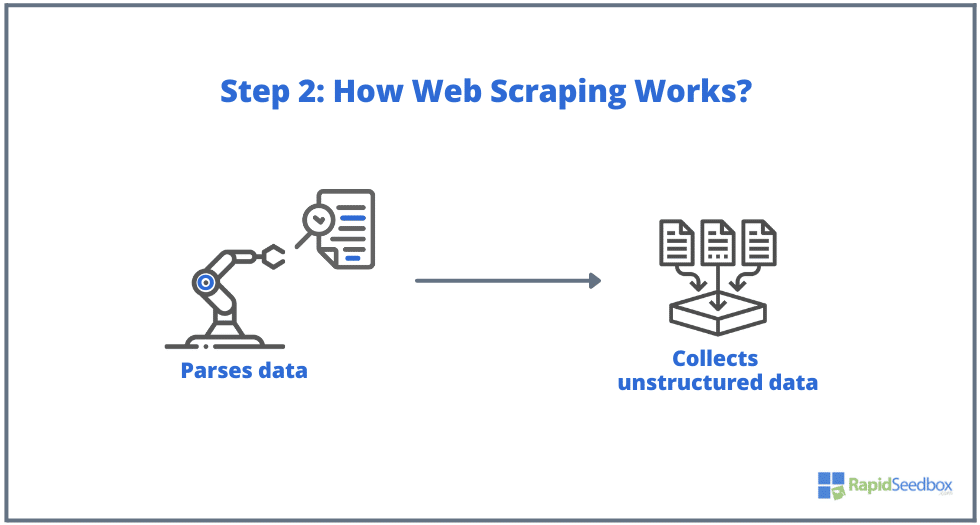
- LANGKAH 2. Jika halaman tersebut muncul, situs web target akan merespons permintaan scraper dengan HTTP/1.0 200 OK (respons umum untuk pengunjung.) Ketika scraper menerima respons HTML (misalnya 200 OK), scraper akan melanjutkan untuk menguraikan dokumen dan mengumpulkan data yang tidak terstruktur.
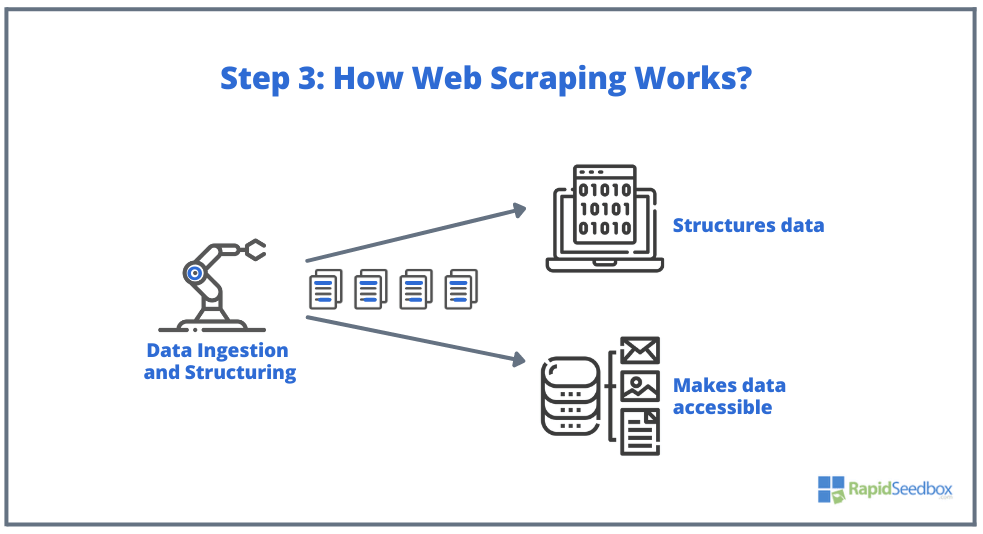
- LANGKAH 3. Scraper Software kemudian akan mengekstrak data mentah, menyimpannya, dan menambahkan struktur (indeks) pada data sesuai dengan apa pun yang ditentukan oleh inisiator. Data tersebut dapat diakses melalui format yang dapat dibaca seperti XLS, CSV, SQL, atau XML.
2. Dasar-dasar Ekstraksi Data HTML: CSS dan XPath Selector.
Kamu mungkin sudah mengetahui dasar-dasarnya: Web scraping melibatkan ekstraksi data dari situs web, dan semuanya dimulai dengan HTML—pondasi halaman web. Dalam sebuah file HTML, kamu akan menemukan kelas dan ID, tabel, daftar, blok, atau kontainer—semua elemen dasar yang membentuk struktur sebuah halaman.
Di sisi lain, CSS adalah bahasa style sheet yang digunakan untuk mengontrol presentasi dan tata letak dokumen HTML. CSS menentukan bagaimana elemen-elemen HTML ditampilkan di halaman web, seperti warna, font, margin, dan posisi. CSS memainkan peran penting dalam web scraping, karena membantu mengekstraksi data dari elemen-elemen yang diinginkan.
Catatan: Penjelasan secara lengkap apa itu HTML dan CSS dan bagaimana cara kerjanya, berada di luar cakupan artikel ini. Kami berasumsi bahwa kamu sudah memiliki keterampilan dasar HTML dan CSS.
Meskipun memungkinkan untuk mengekstraksi data langsung dari HTML mentah menggunakan berbagai teknik seperti ekspresi reguler, hal ini bisa sangat memakan waktu dan menantang. Karena bahasa terstruktur HTML dirancang untuk dapat "dibaca oleh mesin", maka bahasa bisa menjadi sangat kompleks dan bervariasi. Di sinilah CSS dan XPath Selector memainkan peranan penting. Di sinilah CSS dan XPath selector memainkan peran kunci.
a. Mengkompilasi dan Memeriksa HTML.
Pada bagian berikut ini, kami akan memberikan beberapa contoh CSS dan XPath Selector (dikompilasi dan diperiksa). Semua contoh HTML dan CSS berikut ini telah dikompilasi dengan editor online HTML-CSS-JS.
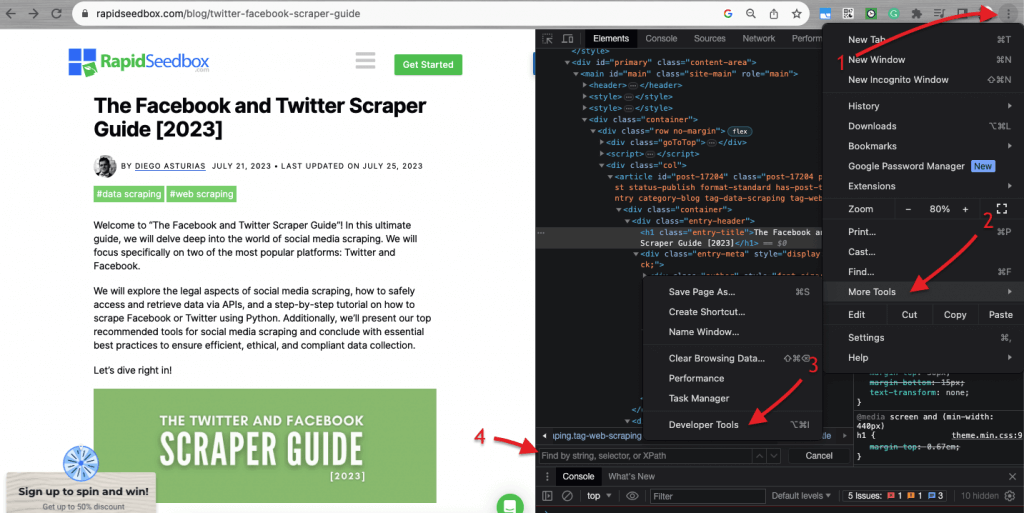
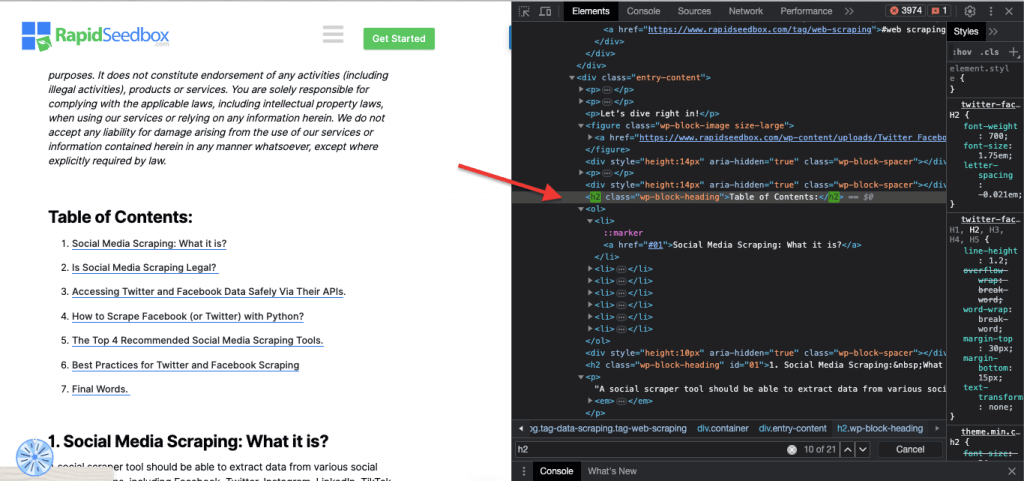
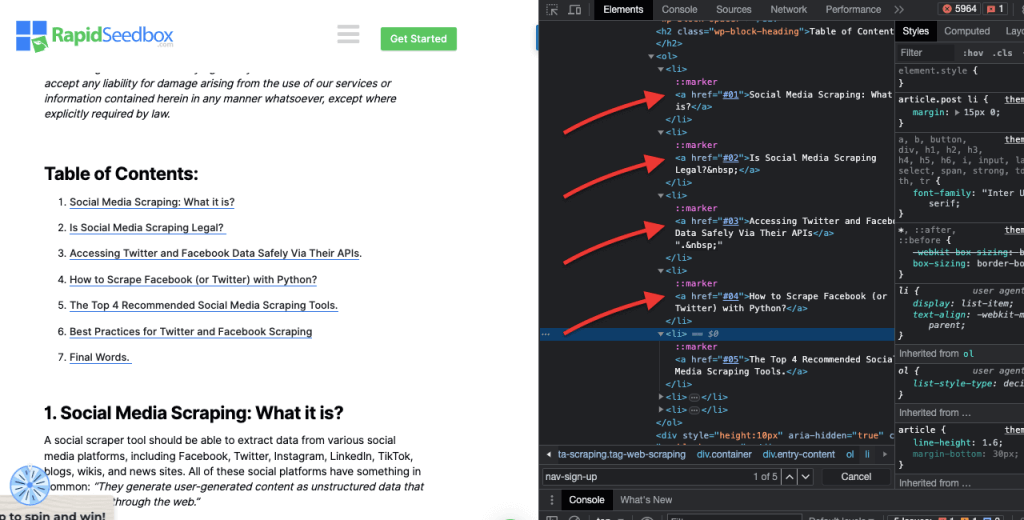
Ketika membahas inspeksi kode HTML di situs web, Browser web dilengkapi dengan Developer Tools, sehingga kamu dapat memeriksa HTML atau CSS yang tersedia secara publik di situs web mana pun. Kamu dapat klik kanan pada halaman web dan pilih "Inspect," "Inspect Element," atau "Inspect Source." Untuk perbandingan yang lebih baik antara halaman dan kode, di Chrome Browser, klik tiga titik di bagian kiri atas (1) > More Tools (2) > Developer Tools (3).
Developer Tools dilengkapi dengan filter pencarian yang berguna (4) yang memungkinkanmu untuk mencari berdasarkan string, selector, atau XPath. Sebagai contoh, kita akan melakukan web scraping pada: https://www.rapidseedbox.com/blog/twitter-facebook-scraper-guide.
b. CSS Selectors:
CSS selectors adalah pola yang digunakan untuk memilih dan menargetkan elemen HTML pada halaman web. Hal ini berguna untuk scraping (dan styling) web karena menyediakan cara yang lebih efisien dan tepat sasaran untuk mendapatkan data dari dokumen HTML. Meskipun bisa mengekstrak data secara langsung dari HTML mentah menggunakan berbagai teknik seperti regular expressions, CSS selectors menawarkan banyak keuntungan yang cocok untuk web scraping.
Teknik untuk targeting dan selecting elemen HTML pada halaman web:
i. Node Selection
Pemilihan node adalah proses memilih elemen HTML berdasarkan nama node. Misalnya, memilih semua elemen 'p' atau semua elemen 'a' pada sebuah halaman. Teknik ini memungkinkan Anda untuk menargetkan jenis elemen tertentu dalam dokumen HTML.

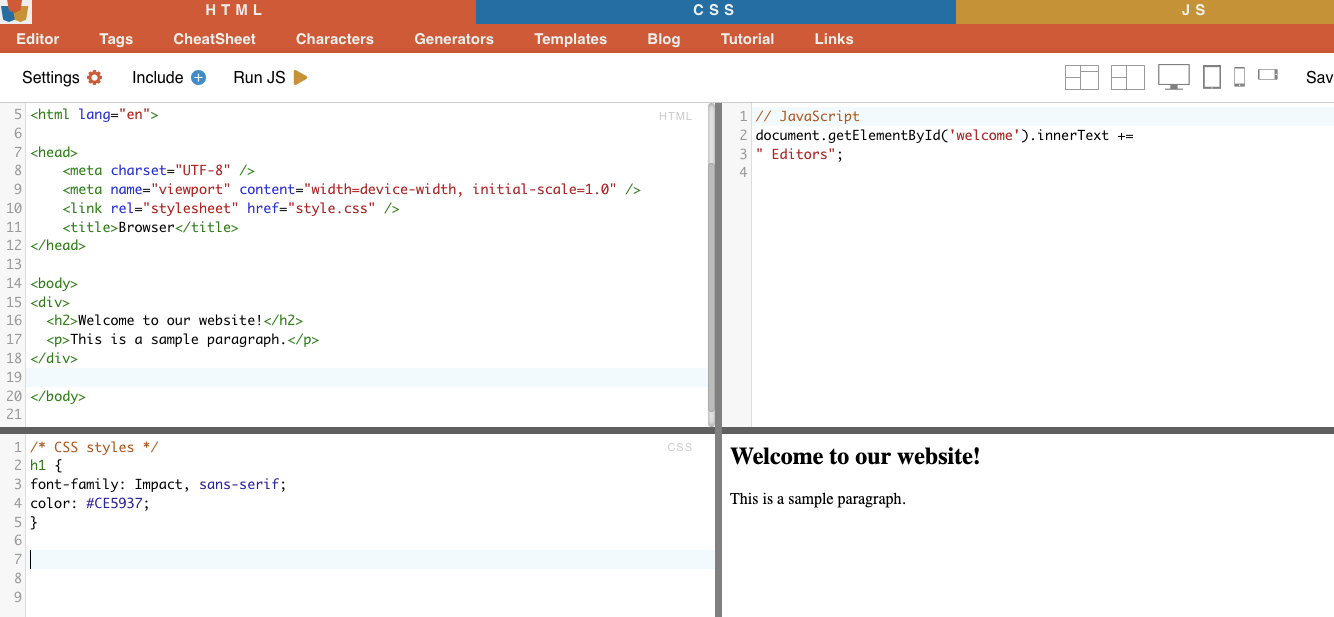
Contoh: Mencari H2 secara manual.
ii. Class.
Dalam CSS Selectors, class selection melibatkan pemilihan elemen HTML berdasarkan class attribute yang ditetapkan. Class attribute memungkinkanmu untuk menerapkan class name tertentu pada satu atau lebih elemen. Selain itu, dalam CSS atau JavaScript, atribut ini dapat diterapkan pada semua elemen dengan class tersebut. Contoh dari nama 'class' adalah tombol, elemen formulir, menu navigasi, tata letak grid, dan lainnya.
Contoh: CSS Selector berikut: 'highlight' akan memilih semua elemen dengan class attribute yang diatur ke "highlight".


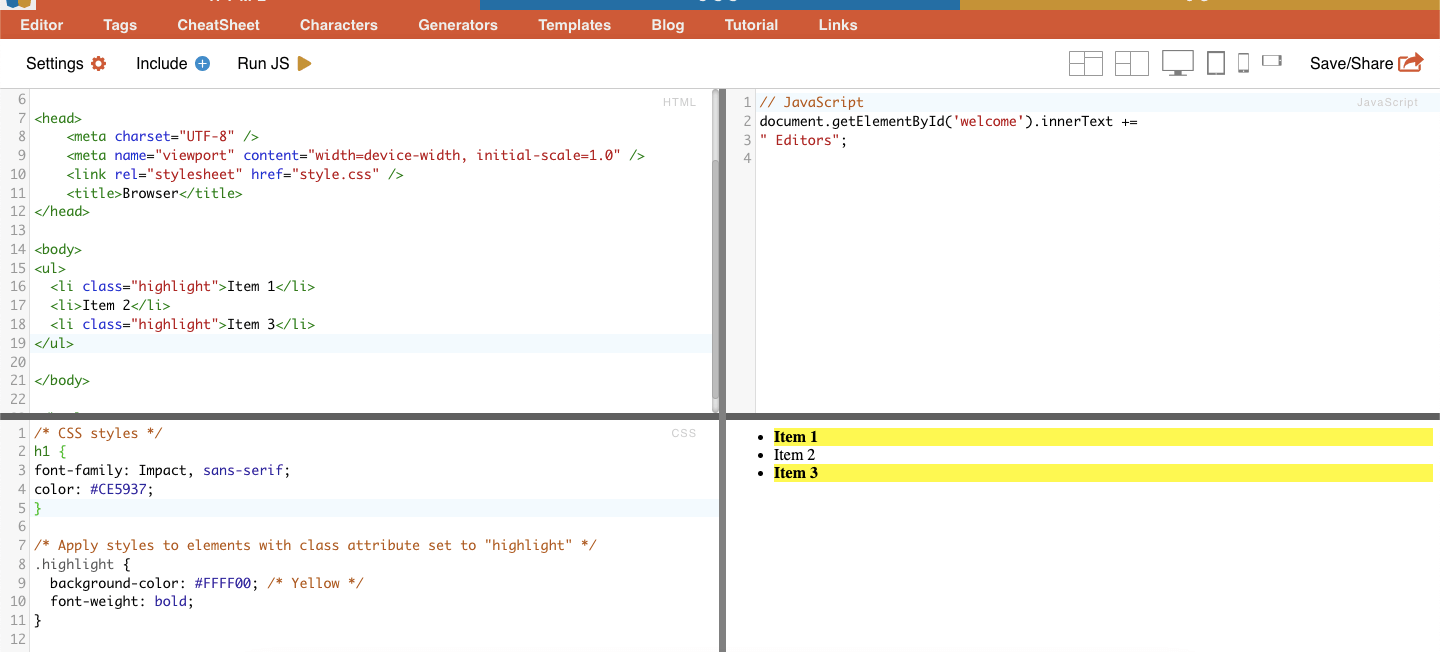
Contoh: Mencari kelas secara manual.
iii. ID Constraints.
ID Constraints. membantu memilih elemen HTML berdasarkan ID attribute uniknya. ID attribute ini digunakan untuk mengidentifikasi sebuah elemen pada halaman web. Tidak seperti 'class' yang dapat digunakan pada beberapa elemen, ID pada halaman haruslah unik.
Contoh: CSS Selector '#header' akan memilih elemen dengan ID attribute yang diatur menjadi "header".


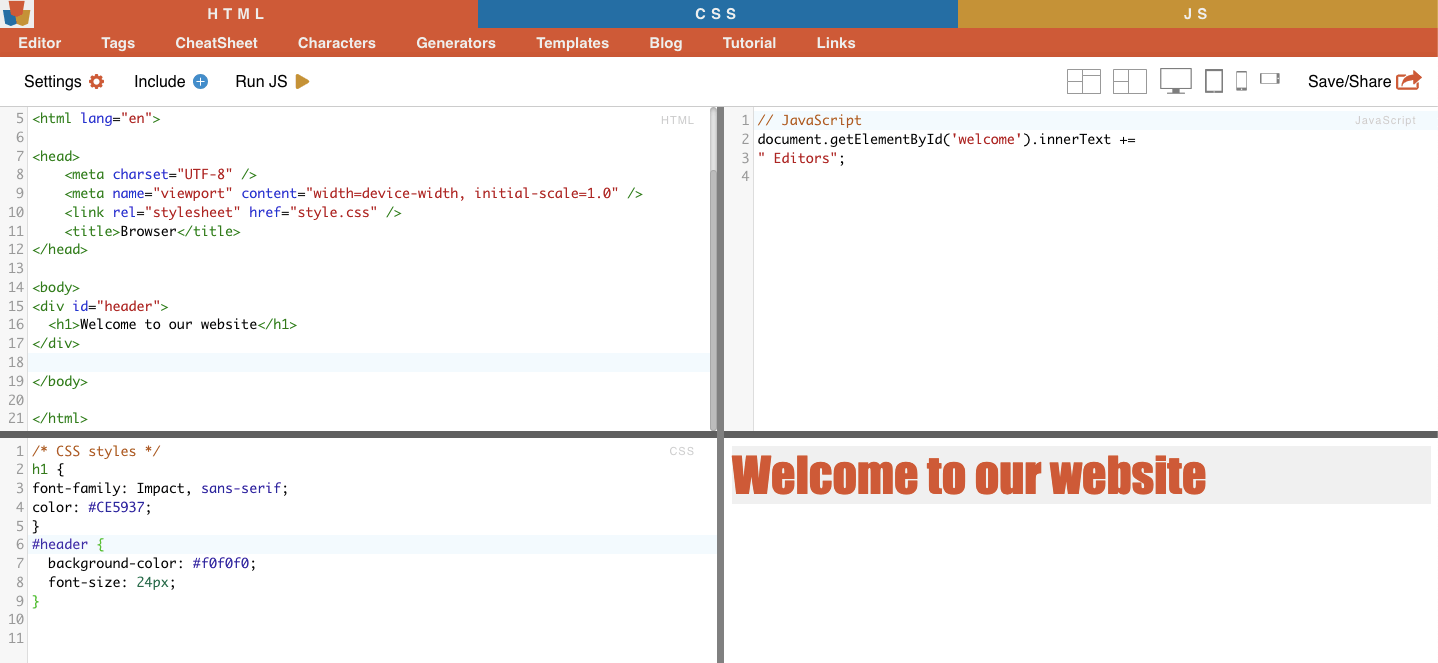
Contoh: Mencari ID secara manual. Setelah menemukan #01, kamu harus mencari id=”01″
iv. Attribute Matching
Teknik ini melibatkan pemilihan elemen HTML berdasarkan atribut khusus dan nilai-nilainya. Dengan ini, kamu bisa menargetkan elemen yang memiliki atribut atau nilai atribut tertentu. Ada berbagai jenis attribute matching seperti exact matching, substring matching, dan lain-lain.
Contoh: Contoh berikut ini menunjukkan atribut khusus yang disebut tipe data. Untuk menargetkan atau menata item tertentu (misalnya item daftar yang ditandai sebagai "buah"), Anda dapat menggunakan pemilih CSS yang memilih elemen berdasarkan nilai atributnya.
Untuk scraping item yang hanya ditandai sebagai "fruit", Kamu dapat menggunakan CSS selector berikut:

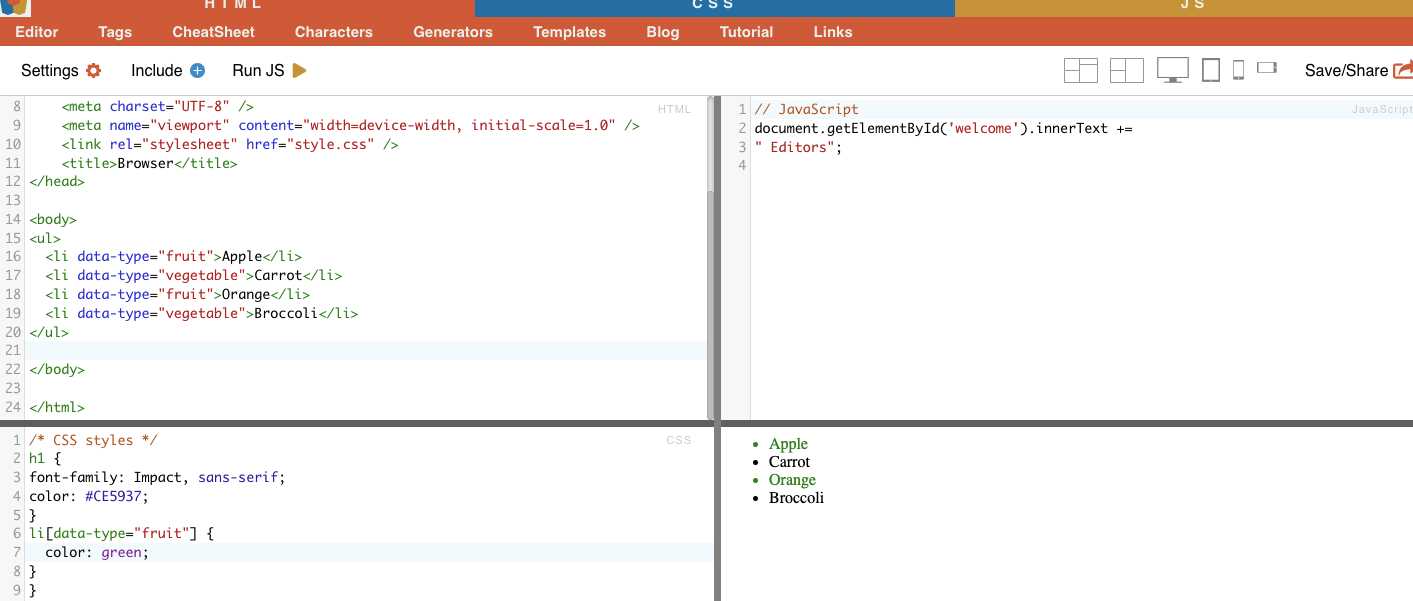
Contoh: Mencari atribut secara manual.
c. Xpath Selector:
CSS selector sangat cocok untuk web scraping yang mudah di mana struktur HTML relatif sederhana. Tetapi ketika struktur HTML lebih kompleks, ada solusi lain: XPath selector.
XPath Selector (XML Path Language Selectors) adalah bahasa flexible path yang digunakan untuk menavigasi elemen-elemen dokumen XML atau HTML. Selektor ini membantu memilih node tertentu di dalam kode HTML berdasarkan lokasi, nama, atribut, atau konten. XPath selector juga dapat berguna untuk menargetkan elemen berdasarkan atribut kelas dan ID-nya.
Berikut adalah tiga contoh XPath selector untuk web scraping.
i. Contoh 1: Ekspresi XPath: ' //a
Ekspresi XPath ' //a' memilih semua elemen '' pada halaman, terlepas dari lokasinya dalam dokumen. Tangkapan layar berikut ini menunjukkan lokasi semua elemen '' secara manual pada halaman.
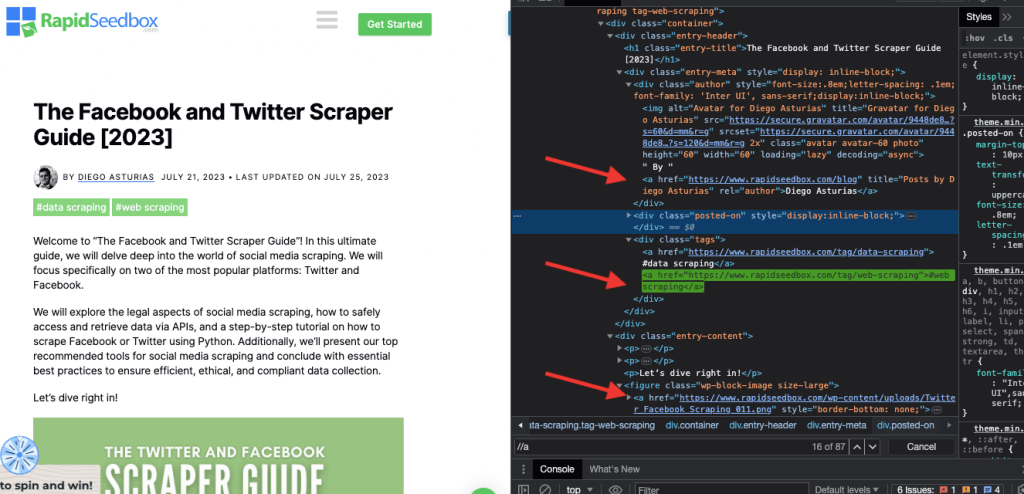
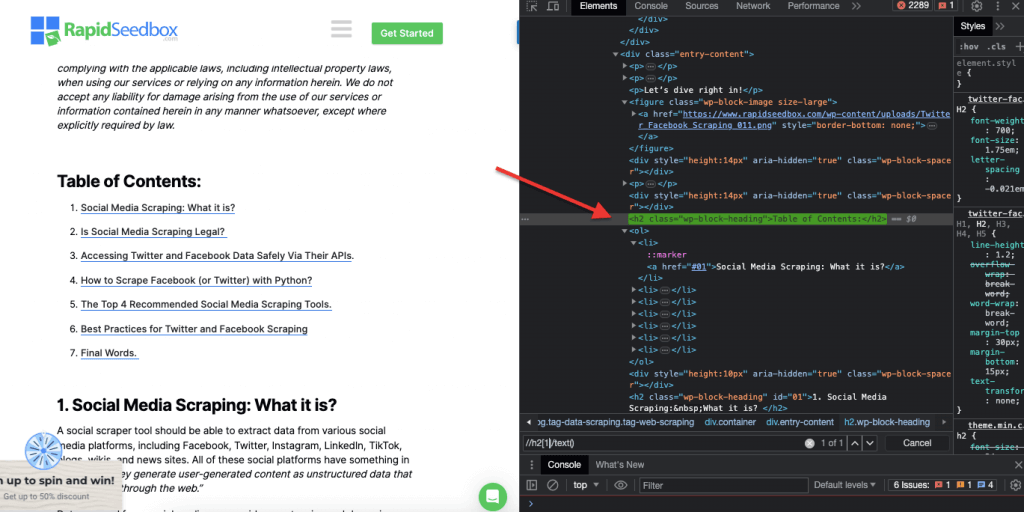
ii. Contoh 2: '//h2[1]/text()'
Ekspresi XPath:
' //h2[1]/text() '
Ini akan memilih konten teks dari judul h2 pertama pada halaman. Indeks '[1]' digunakan untuk menentukan kemunculan pertama elemen h2, Anda juga dapat menentukan kemunculan kedua dengan indeks '[2]', dan seterusnya. Tangkapan layar berikut ini menunjukkan secara manual menemukan judul h2 pertama pada halaman menggunakan pemilih XPath ini.
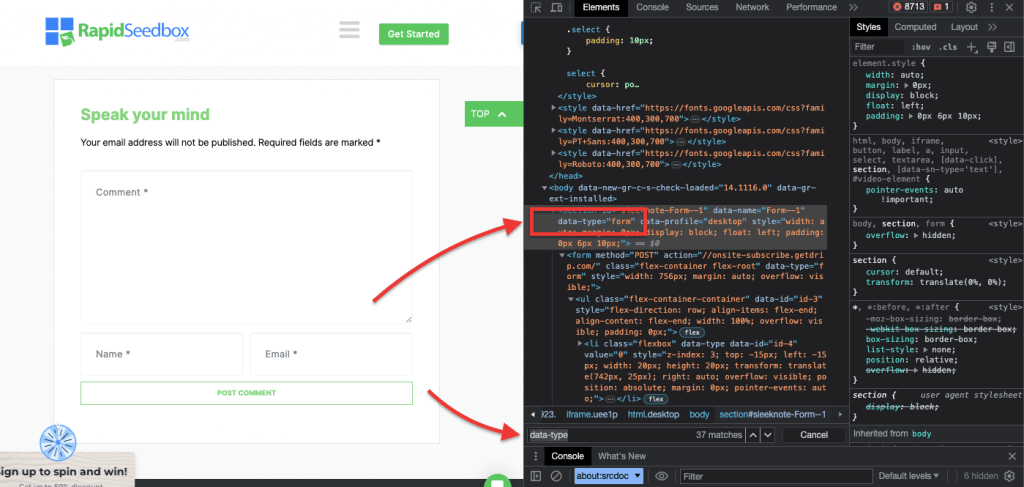
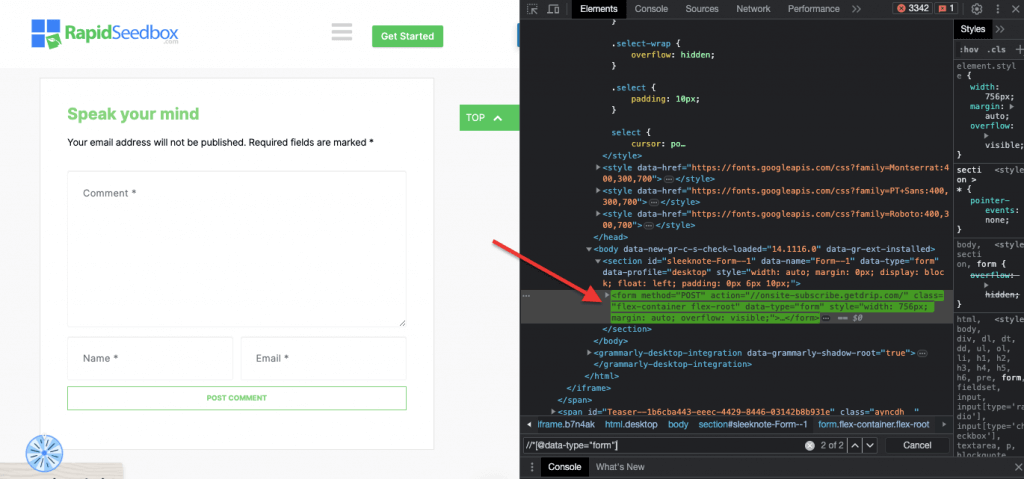
iii. Contoh 3. ' //* [@tipe data = "form"]'
XPath expression //* [@data-type="form"] memilih semua elemen yang memiliki atribut data dengan value "form". Simbol * menunjukan bahwa elemen apapun dengan atribut data yang ditentukan akan dipilih, terlepas dari apapun node name-nya. Screenshot berikut ini menunjukkan proses untuk menemukan elemen secara manual dengan value "form".
Memeriksa dan mengekstrak data secara visual dan manual dari halaman HTML menggunakan CSS dan XPath selector ini tidak hanya memakan waktu, tetapi juga rentan eror. Selain itu, mengekstrak data secara manual atau visual sama sekali tidak cocok untuk pengumpulan data berskala besar atau scraping yang berulang-ulang. Oleh karena itu, penting untuk menggunakan script dan pemrograman.
Tingkatkan scraping web Anda dengan proksi yang cepat, aman, dan anonim dari RapidSeedbox.
Apa bahasa pemrograman terbaik untuk web scraping?
Bahasa pemrograman yang paling populer untuk scraping adalah Python karena library dan paketnya (bahasan tentang ini akan ada di bagian berikutnya.) Bahasa pemrograman populer lainnya untuk web scraping adalah R,karena memiliki library dan framework yang mendukung. Selain itu, perlu juga disebutkan C# - bahasa pemrograman populer yang digunakan oleh banyak web scraper. Situs web seperti ZenRows memiliki panduan lengkap tentang cara scraping situs web dengan C#yang memudahkan para developer untuk memahami proses dan memulai proyek mereka sendiri.
Agar lebih sederhana, panduan web scraping ini akan berfokus pada web scraping dengan Python. Lanjut baca, ya!
3. Scraping Web dengan Python (dengan Kode).
Mengapa kamu harus memeriksa secara visual dan mengekstrak data HTML secara manual dengan CSS selector atau XPath selector kalau kamu dapat menggunakan bahasa pemrograman yang sistematis dan otomatis?
Ada banyak library dan framework dari web scraping populer yang mendukung CSS selector untuk ekstraksi data yang lebih mudah. Salah satu bahasa pemrograman yang paling populer untuk web scraping adalah Python, untuk library seperti BeautifulSoup, Request, Pilih CSS, Selenium, dan Scrapy. Library ini memungkinkan web scraper untuk memanfaatkan CSS dan XPath selector untuk mengekstrak data secara efisien.
BeautifulSoup.
BeautifulSoup adalah salah satu paket Python yang paling populer dan handal yang dirancang untuk mem-parsing dokumen HTML dan XML. Paket ini membuat parse tree dari sebuah halaman, sehingga memungkinkanmu untuk mengekstrak data dari HTML dengan mudah.
| Fakta Menarik! Dalam perang melawan COVID-19, Crawler DXY-COVID-19 milik Jiabao Lin menggunakan BeautifulSoup untuk mengekstrak data berharga dari situs web medis Tiongkok. Dengan demikian, hal ini membantu para peneliti dalam memantau dan memahami penyebaran virus. [Sumber] |
Request.
Python Request adalah HTTP library yang sederhana namun handal. Berguna untuk membuat HTTP request untuk mengambil data dari situs web. "Requests" menyederhanakan proses pengiriman HTTP request dan menangani respons dalam proyek web scraping Python-mu.
a. Tutorial untuk Web Scraping dengan Python (+ Kode)
Dalam tutorial web scraping dengan Python ini, kita akan mengambil data dari situs web HTML target menggunakan kode Python dengan "request" dan BeautifulSoup library.
Syarat:
Pastikan syarat berikut terpenuhi:
- Python environment: Pastikan kamu memiliki Python yang terinstal di komputermu. Selain itu, pastikan kamu dapat menjalankan skrip di Python environment pilihanmu (contoh, IDLE atau Jupyter Notebook).
- Requests Library: Instal aplikasi
requestslibrary. Hal ini digunakan untuk mengirim request HTTP GET ke URL yang ditentukan. Kamu dapat menginstalnya menggunakanpipdengan menjalankanpip install requestsdi command prompt atau terminalmu. - BeautifulSoup Library: Instal aplikasi
beautifulsoup4library. Kamu dapat menginstalnya menggunakanpipdengan menjalankanpip install beautifulsoup4di terminalmu.
Kode Python untuk scraping data web dari sebuah halaman (dengan BeautifulSoup)
Script berikut ini akan mengambil URL yang ditentukan, mem-parsing konten HTML menggunakan BeautifulSoup, dan mencetak judul-judul artikel berita teratas di halaman web.

Saat menjalankan script pada IDLE Shell, layar akan mencetak semua "news_title" yang dikumpulkan dari situs web yang ditargetkan.

b. Variasi kode Python untuk web scraping.
Kita dapat mengambil kode Python web scraping sebelumnya dan melakukan beberapa variasi untuk scraping berbagai jenis data.
Contohnya:
- Menemukan Gambar: Untuk menemukan semua tag gambar (
) di halaman web, Anda dapat menggunakan metode find_all() dengan nama tag 'img':

- Menemukan LInk: Untuk menemukan semua tag jangkar () yang mewakili tautan di halaman web, Anda dapat menggunakan metode find_all() dengan nama tag 'a':

Script yang disediakan (beserta variasinya) adalah web scraping dasar. Script ini hanya mengekstrak dan mencetak judul-judul artikel berita teratas dari URL yang ditentukan. Sayangnya, script sederhana ini tidak memiliki banyak fitur yang dapat digunakan untuk membuat proyek web scraping yang lebih komprehensif. Ada beberapa elemen yang perlu pertimbangkan untuk menambahkan penyimpanan data, penanganan eror, pagination/crawling, penggunaan user-agen dan header, throttling dan politeness measures, serta kemampuan untuk menangani konten dinamis.
4. Apakah Web Scraping Legal?
Web scraping secara umum dianggap sebagai sesuatu yang kontroversial atau ilegal. Namun pada kenyataannya, Hal ini merupakan praktik yang sah jika kita mematuhi batas-batas etika dan hukum tertentu.
Legalitas web scraping bergantung pada sifat data yang diekstrak dan metode yang digunakan. Web scraping dianggap sah jika digunakan untuk mengumpulkan informasi yang tersedia untuk umum dari internet. Namun, tetap harus hati-hati terutama saat berurusan dengan data pribadi atau konten dengan hak cipta.
Catatan:
- Jangan scrape data pribadi. Mengekstrak data yang tidak tersedia untuk umum itu melanggar hukum. Scraping data di balik halaman login, dengan login pengguna dan password melanggar hukum di AS, Kanada, dan sebagian besar Eropa.
- Bagaimana sebuah data bisa menyebabkan masalah. Web scraping yang etis memerlukan perhatian terhadap data yang dikumpulkan sesuai tujuan yang tepat. Perhatian khusus harus diberikan pada data pribadi dan kekayaan intelektual. Pastikan kamu mematuhi peraturan seperti GDPR dan CCPA, yang mengatur penanganan data pribadi. Misalnya, menggunakan kembali atau menjual kembali konten atau mengunduh materi dengan hak cipta adalah tindakan ilegal (dan harus dihindari).
- Penting juga untuk meninjau Ketentuan Layanan di situs web. Dokumen ini biasanya akan mengarahkan siapa pun yang menggunakan layanan atau konten mereka tentang bagaimana mereka bisa menggunakan suatu sumber daya dalam web.
- Selalu pastikan alternatif lain seperti menggunakan API yang disediakan secara resmi. Beberapa situs web seperti lembaga Pemerintah, Cuaca, dan platform media sosial membuat beberapa data mereka dapat diakses oleh publik melalui API.
- Periksa file robots.txt. This file is saved on the web server and gives directions to web crawlers and web scraping about what parts of a website to avoid and what parts are authorized. It also gives directions about the rate limits.
- Jangan melakukan serangan web scraping. Tergantung pada konteksnya, terkadang web scraping disebut sebagai serangan scraping. Ketika spammer menggunakan botnet (pasukan bot) untuk menargetkan sebuah situs web dengan permintaan yang besar dan cepat, maka seluruh layanan situs web bisa gagal. Web scraping berskala besar dapat membuat seluruh situs lumpuh.
Berita terbaru tentang aspek hukum web scraping.
Keputusan hukum baru-baru ini telah mengklarifikasi bahwa data scraping yang tersedia untuk umum pada umumnya tidak dianggap sebagai pelanggaran. Sebuah keputusan penting dari pengadilan banding AS menegaskan kembali legalitas web scraping, yang menyatakan bahwa data scraping yang dapat diakses publik di internet tidak melanggar Undang-Undang Penipuan dan Penyalahgunaan Komputer (CFAA) [sumber: TechCrunch].
Dalam berita lain, tuntutan hukum baru-baru ini terhadap OpenAI dan Microsoft menyoroti kekhawatiran tentang privasi, kekayaan intelektual, dan undang-undang anti peretasan, menurut berita baru-baru ini [Bloomberg]. Meskipun CFAA memiliki efektivitas yang terbatas, klaim pelanggaran kontrak dan undang-undang privasi negara bagian sedang dieksplorasi. Interaksi antara hak cipta dan hukum kontrak masih belum terselesaikan, meninggalkan banyak pertanyaan yang belum terjawab dalam konteks web scraping.
Dalam berita terbaru, [sumber: IndiaTimes] Elon Musk mengubah peraturan Twitter untuk mencegah data scraping yang berlebihan. Menurut Musk, web scraping yang ekstrem berdampak negatif pada pengalaman pengguna. Dia menyatakan bahwa organisasi yang menggunakan Large Language Model untuk generative AI adalah penyebabnya.
5. Bagaimana Situs Web Memblokir Web Scraping?
Perusahaan ingin beberapa data mereka dapat diakses oleh pengunjung manusia. Tetapi ketika perusahaan atau pengguna menggunakan skrip otomatis atau bot untuk mengekstrak data dari situs secara agresif, mungkin ada banyak penyalahgunaan privasi dan sumber daya pada server web dan halaman target. Situs-situs korban ini lebih memilih untuk menghalangi jenis lalu lintas ini.
Teknik Anti-Scraping
- Trafik yang banyak dan di luar normal dari satu sumber. Server web dapat menggunakan WAF (Web Application Firewalls) dengan blacklist noisy IP address untuk memblokir trafik, menyaring kecepatan dan ukuran permintaan yang "tidak normal", dan mekanisme filtering. Beberapa situs menggunakan kombinasi WAF dan CDN (Content Delivery Networks) untuk memfilter seluruhnya atau mengurangi noise dari IP seperti itu.
- Beberapa situs web dapat mendeteksi pola browsing seperti bot. Mirip dengan teknik sebelumnya, situs web juga memblokir permintaan berdasarkan User-Agent (header HTTP). Bot tidak menggunakan peramban biasa. Bot ini memiliki string agen-pengguna yang berbeda (yaitu, perayap, laba-laba, atau bot), kurangnya variasi, tidak adanya header (browser tanpa kepala), tarif permintaan, dan banyak lagi.
- Situs web juga sering mengubah markup HTML mereka. Bot scraping web mengikuti rute "markup HTML" yang konsisten saat menelusuri konten situs web. Beberapa situs web mengubah elemen HTML dalam markup secara teratur dan acak. Teknik ini membuat bot keluar dari kebiasaan atau jadwal scraping regulernya. Mengubah markup HTML tidak menghentikan web scraping tetapi membuatnya jauh lebih menantang.
- Penggunaan CAPTCHA dan sejenisnya. Untuk menghindari bot yang menggunakan headless browser, beberapa situs web membutuhkan tambahan CAPTCHA. Bot yang menggunakan headless browser mengalami kesulitan untuk menyelesaikan hambatan jenis ini. CAPTCHA dibuat untuk bisa dipecahkan oleh pengguna (melalui browser) dan bukan oleh robot.
- Beberapa situs merupakan perangkap (honeypot) untuk scraping bot. Beberapa situs web dibuat hanya untuk menjebak bot scraping - ini adalah teknik yang disebut sebagai honeypot. Honeypots ini hanya terlihat oleh scraping bot (bukan oleh pengunjung manusia biasa) dan dibuat untuk menggiring scraper web ke dalam perangkap.
6. Etika dan Praktik Terbaik untuk Web Scraping.
Web scraping harus dilakukan secara bertanggung jawab dan etis. Seperti yang telah disebutkan sebelumnya, membaca Syarat dan Ketentuan atau ToS akan memberikan Anda gambaran tentang batasan yang harus Anda patuhi. Jika Anda ingin mendapatkan gambaran tentang aturan untuk perayap web, periksa ROBOTS.txt-nya.
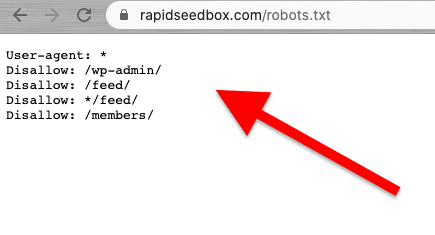
Jika web scraping sepenuhnya dilarang atau diblokir, gunakan API mereka (jika tersedia).
Selain itu, perhatikan juga bandwidth situs web target untuk menghindari beban server dengan terlalu banyak request. Mengotomatiskan permintaan dengan kecepatan dan batas waktu yang tepat untuk menghindari beban server target sangatlah penting. Mensimulasikan pengguna secara real-time haruslah optimal. Selain itu, jangan pernah scraping data di balik halaman login.
Ikuti aturannya dan kamu akan aman.
Praktik Terbaik Web Scraping
- Gunakan Proxy. Proxy adalah server perantara yang meneruskan request. Ketika melakukan web scraping dengan proxy, kamu merutekan original request melaluinya. Jadi, proxy memetakan request dengan IP-nya sendiri dan meneruskannya ke situs web target. Gunakan proxy untuk:
- Menghilangkan kemungkinan IP-mu masuk dalam blacklist atau diblokir. Selalu buat permintaan melalui berbagai proxy- IPv6 proxy adalah contoh yang bagus. Proxy pool dapat membantumu melakukan volume request yang lebih besar tanpa diblokir.
- Bypass konten yang disesuaikan menurut lokasi. Proxy di wilayah tertentu berguna untuk scraping data menurut wilayah geografis tertentu. Hal ini berguna ketika situs web dan layanan berada di belakang CDN.
- Rotating Proxy. Rotating Proxy mengambil (rotate) IP baru dari pool untuk setiap koneksi baru. Ingatlah bahwa VPN bukanlah proxy. Meskipun ia dapat memberikan anonimitas yang mirip, tetapi beda levelnya.
- Rotasikan UA (User Agents) dan HTTP Request Headers. Untuk merotasikan UA dan header HTTP, kamu perlu mengumpulkan daftar string UA dari web browser yang sebenarnya. Letakkan daftar tersebut dalam kode web scraping-mu di Python dan atur request untuk memilih string secara acak.
- Jangan melampaui batas. Memperlambat jumlah request, merotasikan, dan mengacak. Jika kamu ingin membuat banyak request untuk sebuah situs web, acaklah terlebih dulu. Buat setiap request tampak acak dan terlihat seperti manusia. Pertama, ubah IP setiap request dengan bantuan rotating proxy. Selain itu, gunakan header HTTP yang berbeda untuk membuatnya terlihat seperti request yang datang dari browser lain.
Tingkatkan scraping web Anda dengan proksi yang cepat, aman, dan anonim dari RapidSeedbox.
7. Yang Sering Ditanyakan tentang Web Scraping
a. Apa itu robots.txt dan apa perannya dalam web scraping?
The robots.txt berfungsi sebagai alat komunikasi antara pemilik situs web, perayap web, dan "pengikis". Ini adalah file teks yang ditempatkan di server situs web yang memberikan instruksi kepada robot web (perayap, laba-laba web, dan bot otomatis lainnya) tentang bagian situs web mana yang diizinkan untuk diakses dan dikikis, dan bagian mana yang harus mereka hindari. Perayap web yang "berperilaku baik" (seperti Googlebot) dirancang untuk secara otomatis membaca robots.txt. Scraper tidak dirancang untuk membaca file ini. Jadi, mengetahui robots.txt sangat penting untuk menghormati keinginan pemilik situs web.
b. Teknik apa yang digunakan admin situs web untuk menghindari upaya web scraping yang "kasar" atau "tidak sah"?
Tidak semua scraper mengekstrak data secara etis dan legal. Mereka tidak mengikuti Ketentuan Layanan situs atau panduan robots.txt. Jadi, admin situs web dapat mengambil langkah-langkah tambahan untuk melindungi data dan sumber daya mereka, seperti menggunakan pemblokiran IP atau CAPTCHA. Mereka juga dapat menggunakan langkah-langkah pembatasan kecepatan, verifikasi user-agent (untuk mengidentifikasi potensi bot), melacak sesi, menggunakan otentikasi berbasis token, menggunakan CDN (Jaringan Pengiriman Konten), atau bahkan menggunakan sistem deteksi berbasis perilaku.
c. Web Scraping vs Web Crawling?
Meskipun web scraping dan web crawling sama-sama merupakan teknik ekstraksi data web, keduanya memiliki tujuan, cakupan, otomatisasi, dan aspek hukum yang berbeda. Di satu sisi, teknik web scraping bertujuan untuk mengekstrak data spesifik dari situs tertentu. Mereka ditargetkan dan memiliki ruang lingkup yang spesifik dan terbatas. Web scraping menggunakan skrip otomatis atau alat pihak ketiga untuk meminta, menerima, mengurai, mengekstrak, dan menyusun data. Teknik perayapan web (seperti daftar merangkak), di sisi lain, digunakan untuk mencari di web secara sistematis. Mereka populer di antara mesin pencari (cakupan yang lebih luas), platform media sosial, peneliti, agregator konten, dll. Perayap web dapat mengunjungi banyak situs secara otomatis (melalui bot, perayap, atau laba-laba), membuat daftar, mengindeks data (membuat salinan), dan menyimpannya dalam basis data. Perayap web biasanya memeriksa file ROBOTS.txt.
d. Data mining vs Data scraping: Apa saja perbedaan dan persamaannya?
Baik data mining maupun penggalian data melibatkan ekstraksi data. Namun, data mining berfokus pada penggunaan teknik statistik dan machine-learning untuk menganalisis kumpulan data terstruktur. Hal ini bertujuan untuk mengidentifikasi pola, hubungan, dan wawasan dalam kumpulan data terstruktur yang besar dan kompleks. Data scraping, di sisi lain, berfokus pada "bagian pengumpulan" informasi spesifik dari halaman web dan situs web. Kedua teknik dan alat ini dapat digunakan secara bersamaan. Web scraping dapat menjadi langkah awal untuk mengumpulkan data dari web, yang kemudian dimasukkan ke dalam algoritme penggalian data untuk analisis mendalam dan penemuan wawasan.
e. Apa itu Screen Scraping? Bagaimana hubungannya dengan Data Scraping?
Kedua teknik ini berfokus pada ekstraksi data, tetapi berbeda dalam jenis data yang diekstrak. Pengikisan layar bertujuan untuk menangkap dan mengekstrak data visual yang ditampilkan di situs web dan dokumen secara "otomatis", termasuk teks layar. Tidak seperti web scraping, yang mengurai data dari HTML (sehingga mengekstrak berbagai macam data web), screen scraping membaca data teks langsung dari tampilan layar.
f. Apakah Web Harvesting sama dengan Web Scraping?
Data scraping dan web harvesting sangat terkait dan sering digunakan secara bergantian, tetapi keduanya bukanlah konsep yang sama. Pemanenan web memiliki konotasi yang lebih luas. Ini mencakup berbagai metode ekstraksi data dari web, termasuk berbagai mekanisme ekstraksi web otomatis, seperti web scraping. Perbedaan yang jelas adalah bahwa web harvesting sering kali digunakan ketika API dilibatkan, daripada secara langsung mem-parsing kode HTML dari halaman web (seperti yang dilakukan oleh web scraping).
g. Pemilih CSS vs Pemilih XPath: Apa saja perbedaannya saat melakukan scraping?
Selektor CSS adalah cara yang efisien untuk mengekstrak data selama pengikisan web. Mereka menawarkan sintaks yang mudah dan bekerja dengan baik di sebagian besar skenario scraping. Namun, dalam kasus yang lebih kompleks atau ketika berhadapan dengan struktur bersarang, penyeleksi XPath dapat memberikan fleksibilitas dan fungsionalitas tambahan.
h. Bagaimana cara menangani situs web dinamis dengan Selenium?
Selenium adalah sebuah tool scraping situs web yang handal dan dinamis. Tool ini memungkinkanmu untuk berinteraksi dengan elemen-elemen di halaman web seperti yang dilakukan oleh pengguna manusia. Kemampuan ini memungkinkan script-mu untuk menavigasi konten yang dibuat secara dinamis. Dengan menggunakan WebDriver Selenium. Kamu dapat menunggu elemen halaman dimuat, berinteraksi dengan elemen AJAX, dan scraping data dari situs web yang sangat bergantung pada JavaScript.
i. Bagaimana cara menangani AJAX dan JavaScript saat Web Scraping?
Ketika berurusan dengan AJAX dan JavaScript selamaweb scraping, Library tradisional seperti Requests dan Beautiful Soup mungkin tidak cukup. Untuk menangani request AJAX dan konten yang di-render dengan JavaScript, kamu bisa menggunakan alat bantu seperti Selenium atau headless browser seperti Puppeteer.
Kesimpulan.
Hore! Kamu telah menyelesaikan panduan untuk web scraping!
Kami berharap panduan ini bisa membekalimu dengan pengetahuan dan tools untuk memanfaatkan potensi web scraping.
Ingatlah bahwa dengan kemampuanmu yang besar ini, semakin besar juga tanggung jawabmu. Saat memulai web scraping, selalu prioritaskan praktik yang etis, hormati persyaratan layanan situs web, dan perhatikan privasi data.
Kita telah menyentuh puncak gunung es. Web Scraping bisa menjadi topik yang cukup komprehensif. Tapi, hei, Anda sudah pernah melakukan scraping pada sebuah situs web!
Dengan terus belajar, mengikuti perkembangan teknologi dan hukum terbaru, kamu dapat mendalami dunia web scraping yang lumayan rumit ini.
Memeriksa dan mengekstrak data secara visual dan manual dari halaman HTML menggunakan CSS dan XPath selector ini tidak hanya memakan waktu, tetapi juga rentan eror. Selain itu, mengekstrak data secara manual atau visual sama sekali tidak cocok untuk pengumpulan data berskala besar atau scraping yang berulang-ulang. Oleh karena itu, penting untuk menggunakan script dan pemrograman.
0Komentar