In this ultimate guide, we will explore the world of web scraping, a powerful technique to extract data from websites. rat
无论你是对这一概念充满好奇的初学者,还是希望提高技能的资深程序员,本指南都能为每个人提供有价值的内容。从了解 HTML 数据提取的基础知识到使用 CSS 和 XPath 从选择器到使用 Python 进行网络搜刮的实践,我们都会为您一一介绍。此外,我们还将讨论法律问题、道德考虑因素和最佳实践,以确保负责任地进行网络搜刮。

免责声明: 免责声明:本材料仅供参考。它并不构成对任何活动(包括非法活动)、产品或服务的认可。在使用我们的服务或依赖此处的任何信息时,您全权负责遵守适用的法律,包括知识产权法。对于因以任何方式使用我们的服务或此处包含的信息而造成的损害,我们不承担任何责任,除非法律明确要求。
目录
- 什么是网络抓取及其工作原理?
- HTML 数据提取基础:CSS 和 XPath 选择器
- 用 Python 进行网络抓取(+ 代码)。
- 网络搜索合法吗?
- 网站如何阻止网络搜索?
- 网络抓取的道德和最佳实践。
- 网络抓取:常见问题 (FAQ)
- 结语。
1.什么是网络抓取及其工作原理?
网络搜刮(也称网络采集或数据提取)是从网站、网络服务和网络应用程序中自动提取数据的过程。
网络搜刮帮助我们免去了进入每个网站并手动获取数据的麻烦--这是一个漫长而无效的过程。这一过程需要使用自动脚本或程序。脚本或程序访问网页的 HTML 结构,解析数据,并提取网页中特定的所需元素,以便进一步分析。
a.网络抓取有什么用途?
如果以负责任的方式进行,网络搜索是非常好的。一般来说,它可用于研究市场,如洞察和了解特定市场的趋势。它在竞争监测中也很受欢迎,可以跟踪他们的战略、价格等。
更具体的使用案例有
- 社交平台 (Facebook 和 Twitter 搜索)
- 在线价格变化监控、
- 产品评论
- 搜索引擎优化活动、
- 房地产清单、
- 跟踪气象数据、
- 跟踪网站声誉、
- 监测航班的可用性和价格、
- 测试广告,不受地域限制、
- 监督财政资源、
b.网络抓取是如何工作的?
网络搜刮涉及的典型要素是发起者和目标。发起者(网络搜刮者)使用自动数据提取软件对网站进行搜刮。另一方面,目标通常是网站内容、联系信息、表单或网络上任何公开的内容。
典型流程如下:
- 步骤 1: 发起者使用刮擦工具--软件(可以是基于云的服务,也可以是自制脚本)开始生成 HTTP 请求(用于与网站交互并检索数据)。该软件可以向目标网站发起任何 HTTP GET、POST、PUT、DELETE 或 HEAD 请求,也可以发起 OPTIONS 请求。
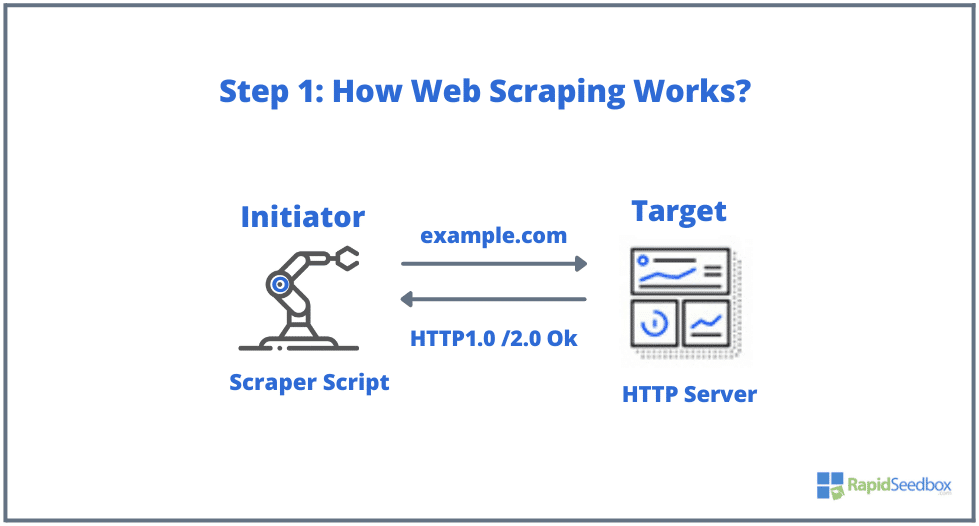
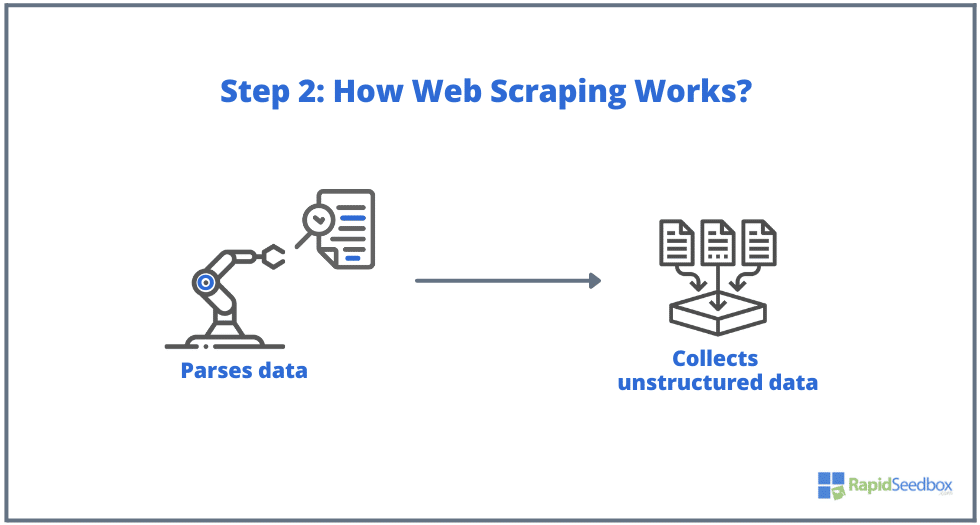
- 步骤 2. 如果页面存在,目标网站将以 HTTP/1.0 200 OK(对访问者的典型响应)响应刮擦程序的请求。刮擦程序收到 HTML 响应(例如 200 OK)后,将继续解析文档并收集其非结构化数据。
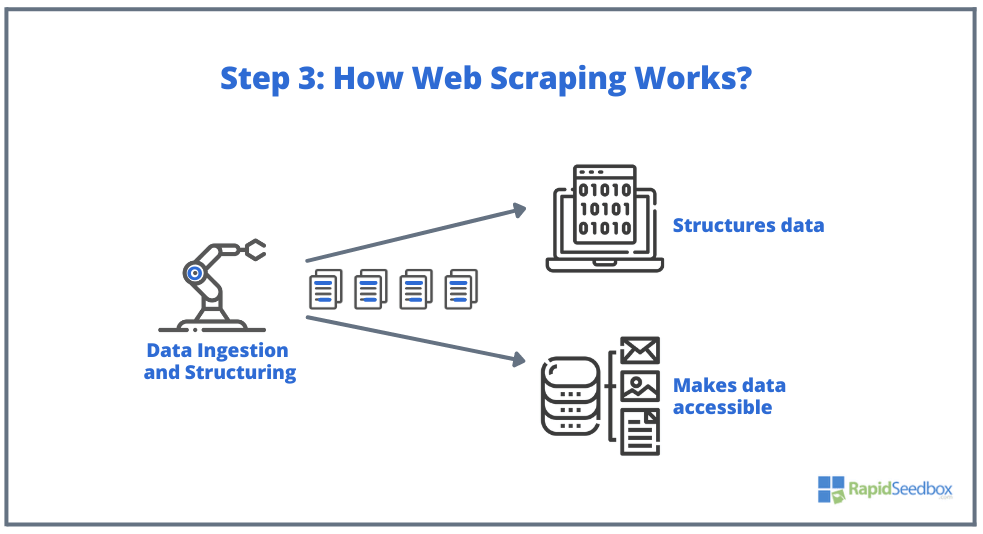
- 步骤 3.然后,刮板软件将提取原始数据,将其存储起来,并根据发起者的指定为数据添加结构(索引)。结构化数据可通过 XLS、CSV、SQL 或 XML 等可读格式访问。
2.HTML 数据提取基础CSS 和 XPath 选择器
您可能已经了解了基本知识: 网络抓取包括从网站上提取数据,而这一切都要从 HTML 开始。是网页的支柱。在 HTML 文件中,你可以找到类和 ID、表格、列表、块或容器--这些基本元素构成了网页的结构。
CSS 则是一种样式表语言,用于控制 HTML 文档的显示和布局。它定义了 HTML 元素在网页上的显示方式,如颜色、字体、边距和定位。CSS 在网络搜刮中起着关键作用,因为它有助于从所需元素中提取数据。
注意: 详细解释 HTML 和 CSS 及其工作原理不在本文讨论范围之内。我们假设你已经掌握了 HTML 和 CSS 的基本技能。
虽然可以使用正则表达式等各种技术直接从原始 HTML 中提取数据,但这确实非常耗时且具有挑战性。由于 HTML 的结构化语言是为 "机器可读 "而设计的,因此会变得非常复杂多样。 这就是 CSS 和 XPath 选择器发挥关键作用的地方。
a.编译和检查 HTML。
在下一节中,我们将提供一些 CSS 和 XPath 选择器示例(经过编译和检查)。以下所有 HTML 和 CSS 示例都是通过在线编辑器编译的 HTML-CSS-JS.
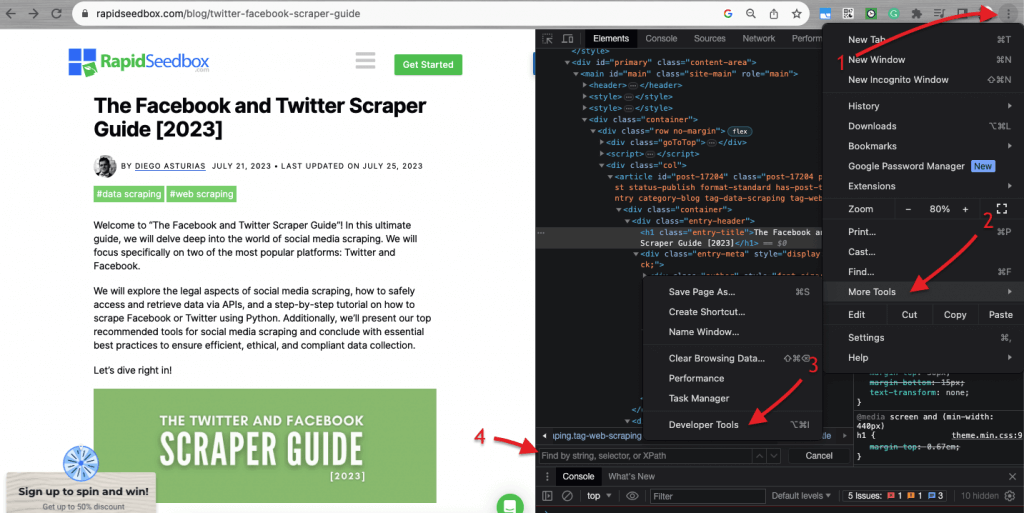
在检查网站的 HTML 代码时、 网页浏览器都带有开发工具,因此你可以检查任何网站上公开的 HTML 或 CSS。你可以右击网页,选择 "检查"、"检查元素 "或 "检查源代码"。要更好地并排比较页面和代码动态,请在 Chrome 浏览器 > 左上角的三个点 (1) > 更多工具 (2) > 开发人员工具 (3)。
开发人员工具带有一个方便的搜索过滤器 (4),可以通过字符串、选择器或 XPath 进行搜索。举例来说,我们将从 https://www.rapidseedbox.com/blog/twitter-facebook-scraper-guide 抓取一些数据。
b.CSS 选择器
CSS 选择器是用于选择和定位网页 HTML 元素的模式。由于 CSS 选择器提供了一种从 HTML 文档中获取数据的更高效、更有针对性的方法,因此对网络搜索(和样式设计)非常有用。虽然可以使用正则表达式等各种技术直接从原始 HTML 中提取数据,但 CSS 选择器具有多种优势,使其成为网络搜刮的首选。
在网页中定位和选择 HTML 元素的技术:
i.节点选择。
节点选择是根据 HTML 元素的节点名称选择元素的过程。例如,选择页面上所有的 "p "元素或所有的 "a "元素。这种技术可以让你锁定 HTML 文档中特定类型的元素。

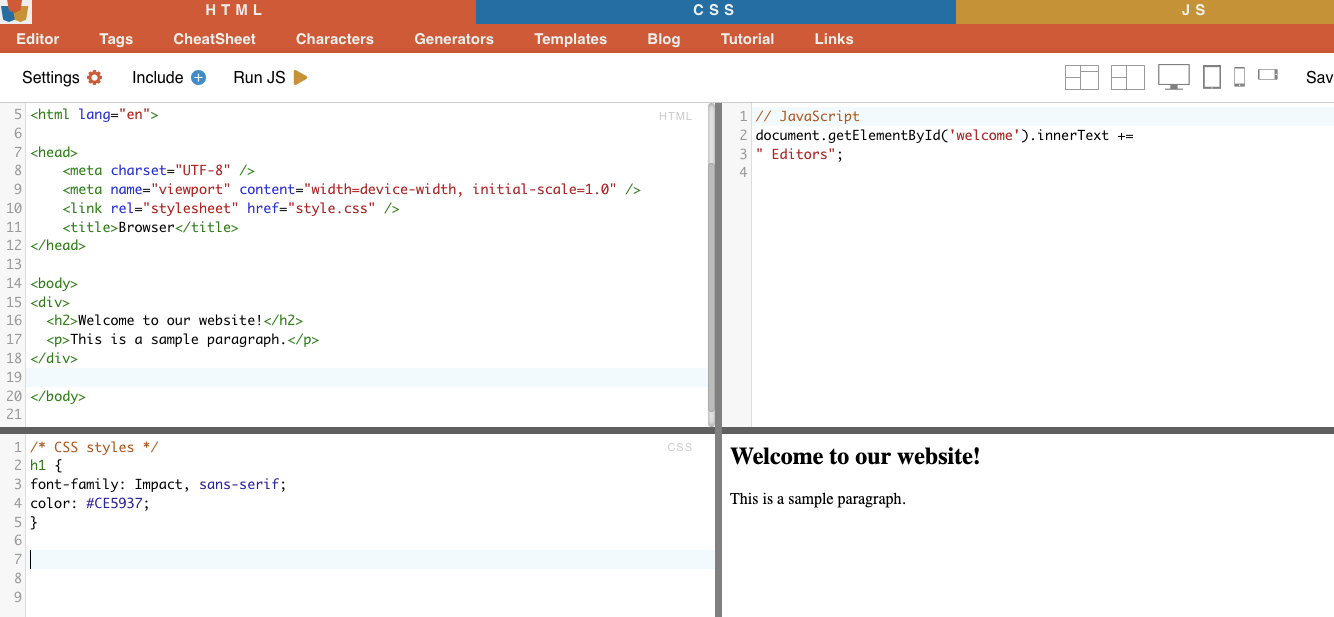
真实案例 手动搜索 H2。
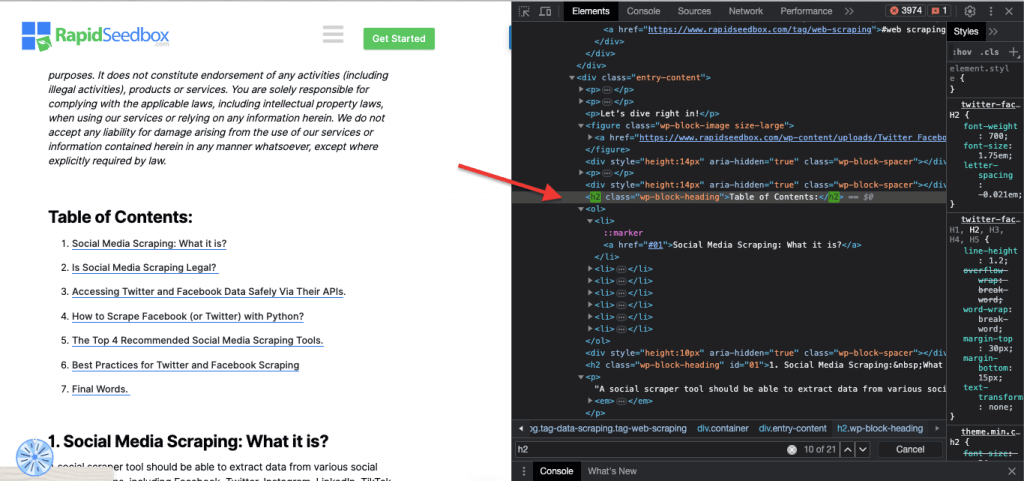
ii.班级
在 CSS 选择器中,类选择涉及根据指定的类属性来选择 HTML 元素。通过 class 属性,可以对一个或多个元素应用特定的类名。此外,在 CSS 样式或 JavaScript 中,它还可以应用于具有该类别的所有元素。类 "名称的例子包括按钮、表单元素、导航菜单、网格布局等。
例如 以下 CSS 选择器:"highlight "将选择所有 class 属性设置为 "highlight "的元素。


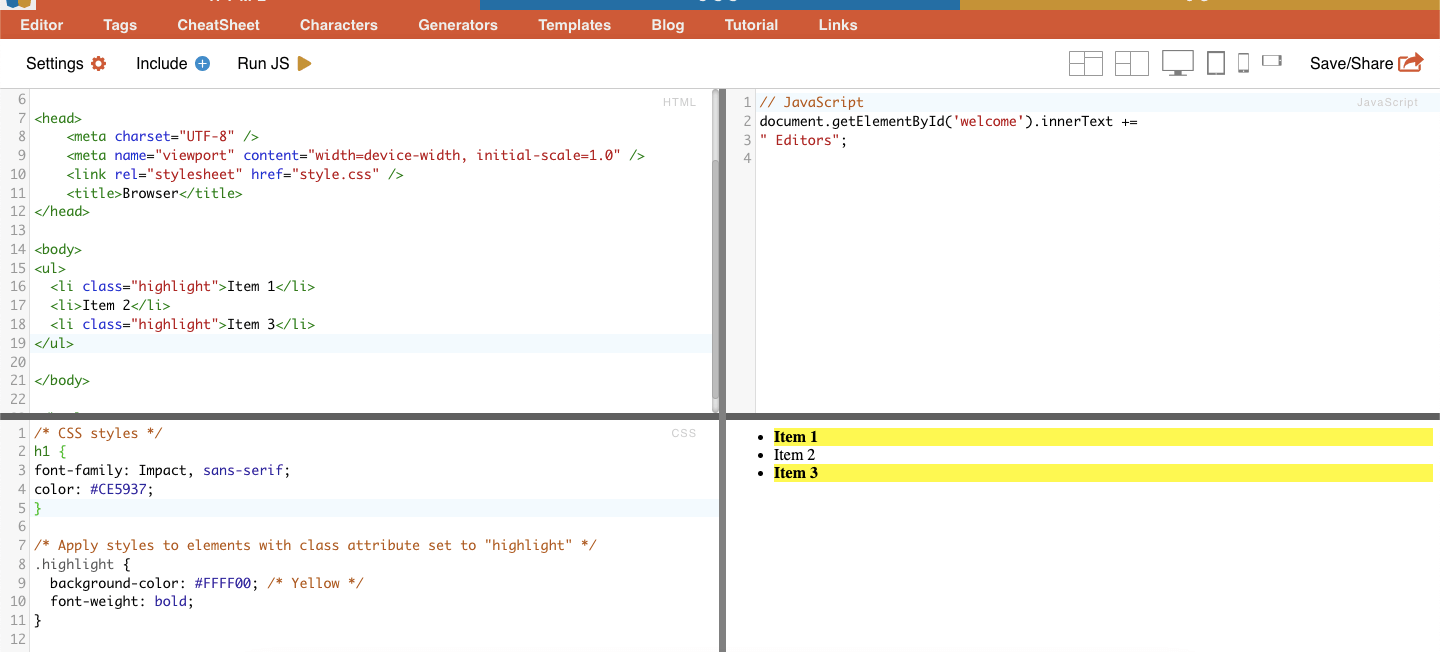
真实案例 手动搜索班级。
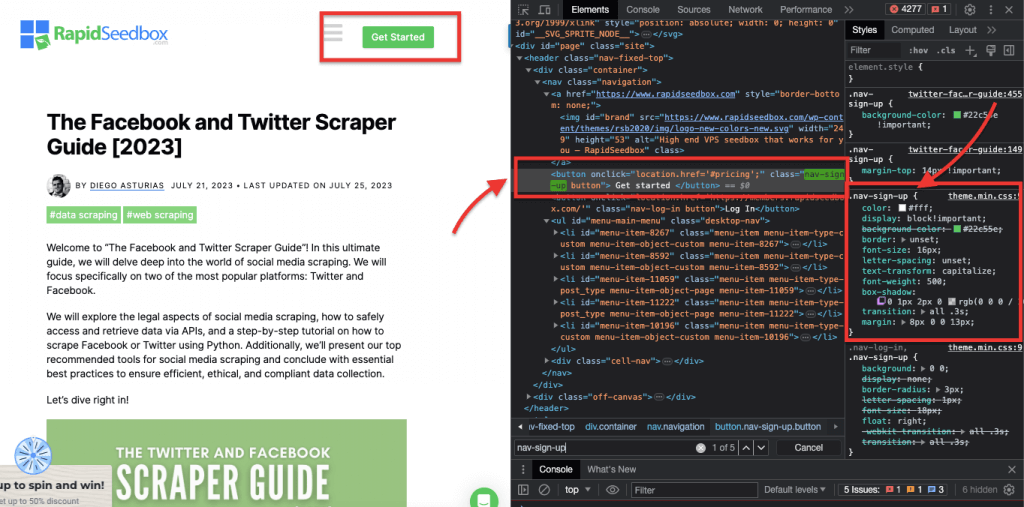
iii.ID 限制。
ID 约束有助于根据 HTML 元素的唯一 ID 属性选择该元素。ID 属性用于唯一标识网页上的单个元素。与可用于多个元素的类不同,ID 在网页中应该是唯一的。
例如 CSS 选择器 "#header "将选择 ID 属性设置为 "header "的元素。


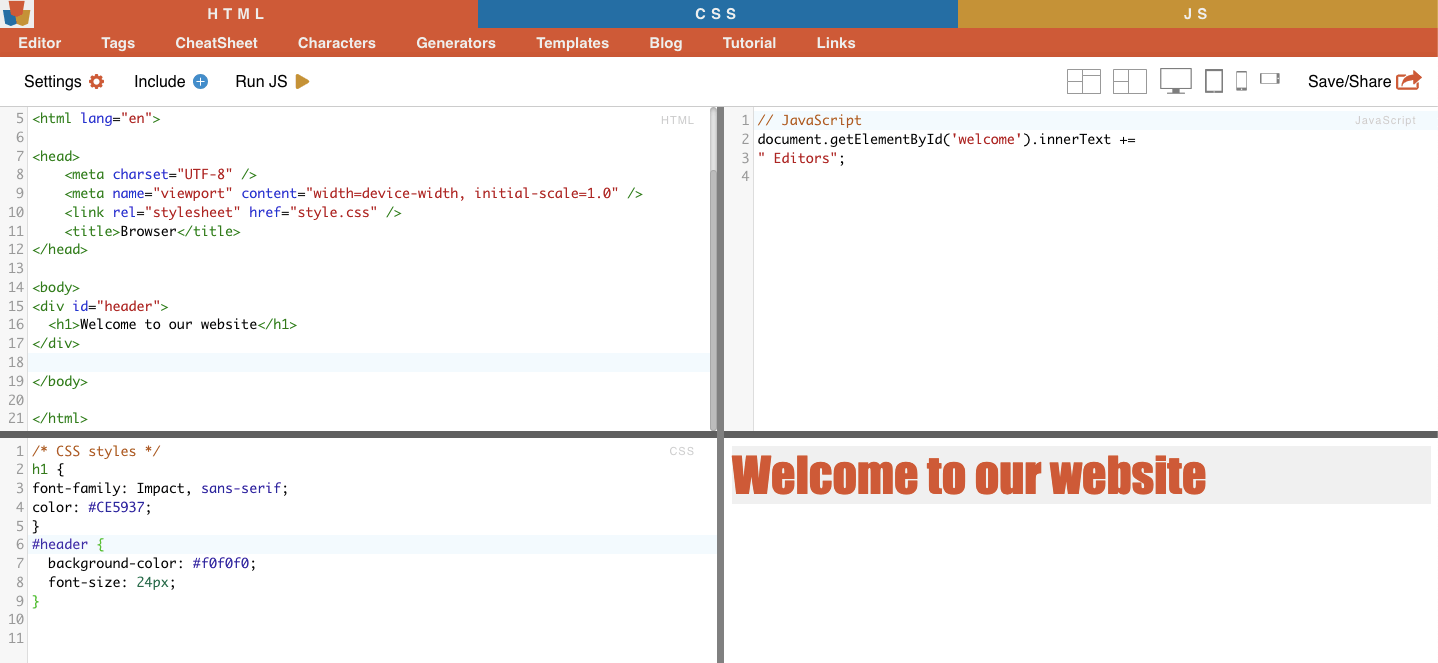
真实案例 手动搜索 ID。找到 #01 后,您需要找到 id="01
iv.属性匹配。
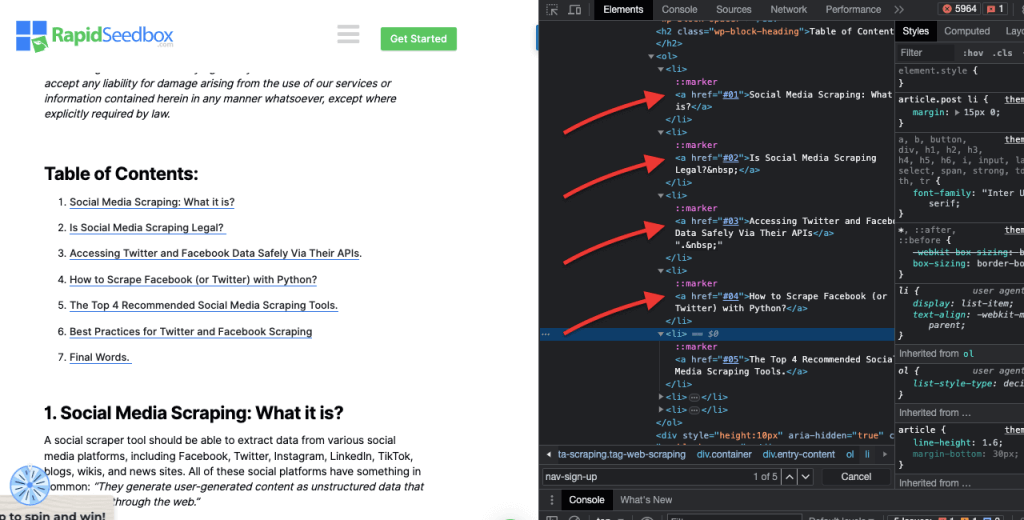
这种技术是根据特定属性及其值来选择 HTML 元素。它可以让你锁定具有特定属性或属性值的元素。属性匹配有多种类型,如精确匹配、子串匹配等。
例如 下面的示例显示了一个名为数据类型的自定义属性。要定位或样式化某些项目(例如标记为 "水果 "的列表项目),可以使用 CSS 选择器,根据属性值选择元素。
要只抓取标记为 "水果 "的项目,可以使用下面的 CSS 选择器:

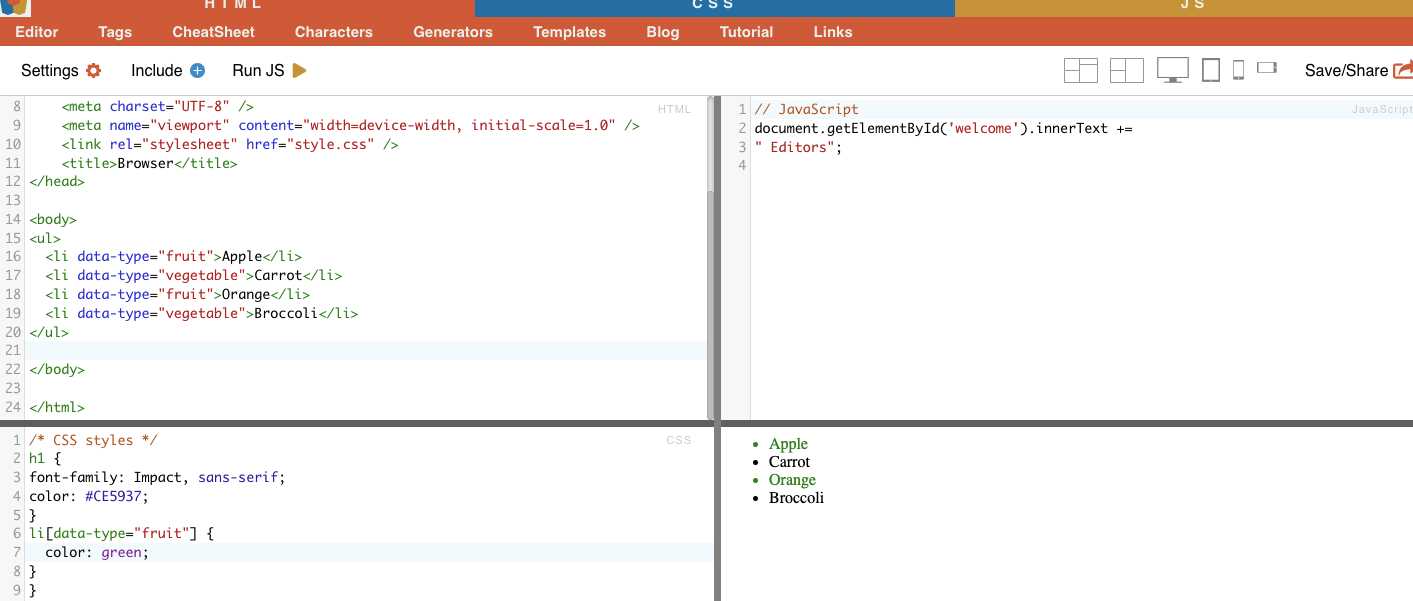
真实案例 手动搜索属性
c.Xpath 选择器:
CSS 选择器非常适合 HTML 结构相对简单的直接网络搜刮任务。但当 HTML 结构变得更加错综复杂时,就有了另一种解决方案:XPath 选择器。
XPath 选择器(XML 路径语言选择器) 是一种灵活的路径语言,用于浏览 XML 或 HTML 文档中的元素。 它们有助于根据位置、名称、属性或内容选择 HTML 代码中的特定节点。XPath 选择器还可用于根据元素的类和 ID 属性选择元素。
下面是三个用于网络搜索的 XPath 选择器示例。
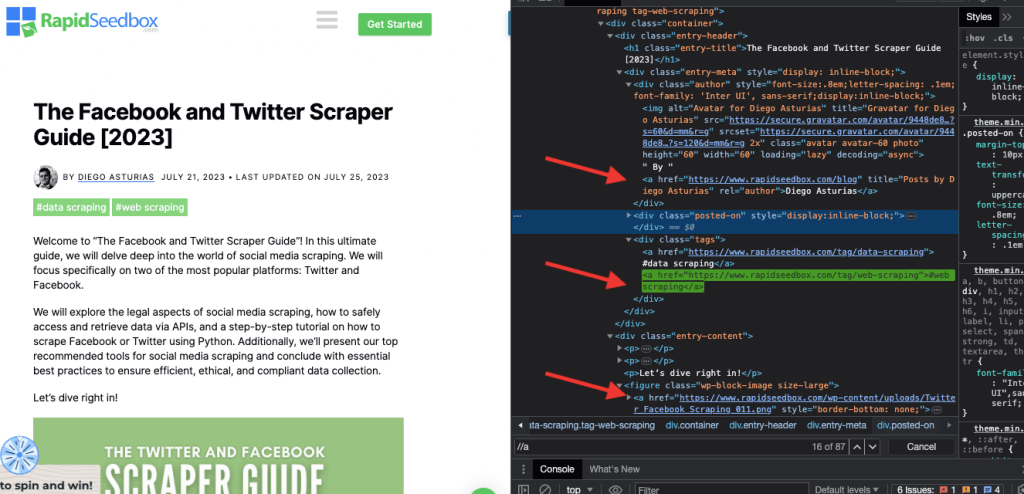
i.例 1:XPath 表达式:' //a
XPath 表达式"//a "会选择页面上的所有""元素,无论它们在文档中的位置如何。下面的截图显示了手动定位页面上所有""元素的过程。
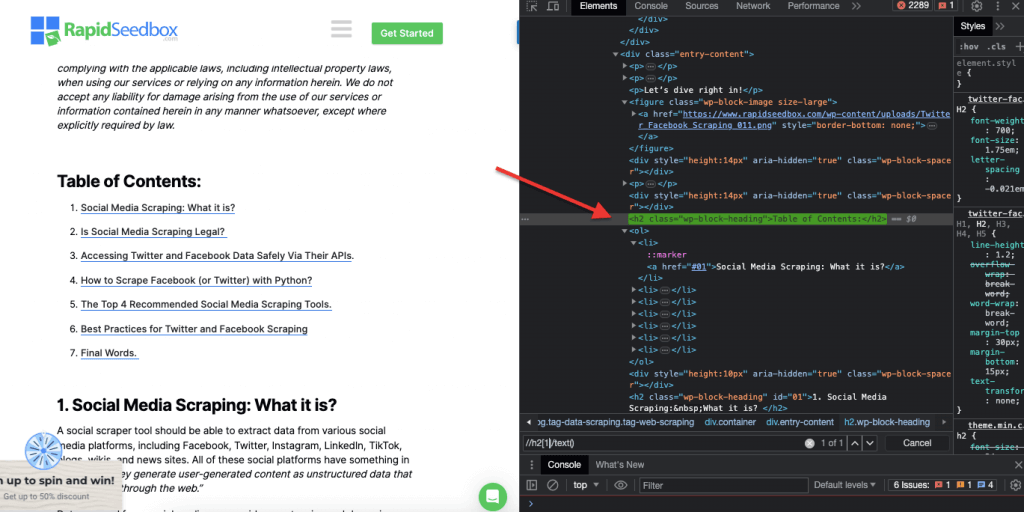
ii.例 2:"//h2[1]/text()
XPath 表达式
' //h2[1]/text() '
它将选择页面上第一个 h2 标题的文本内容。索引'[1]'用于指定第一个出现的 h2 元素,也可以用索引'[2]'指定第二个出现的 h2 元素,以此类推。下面的截图显示了使用此 XPath 选择器手动定位页面上第一个标题 h2 的过程。
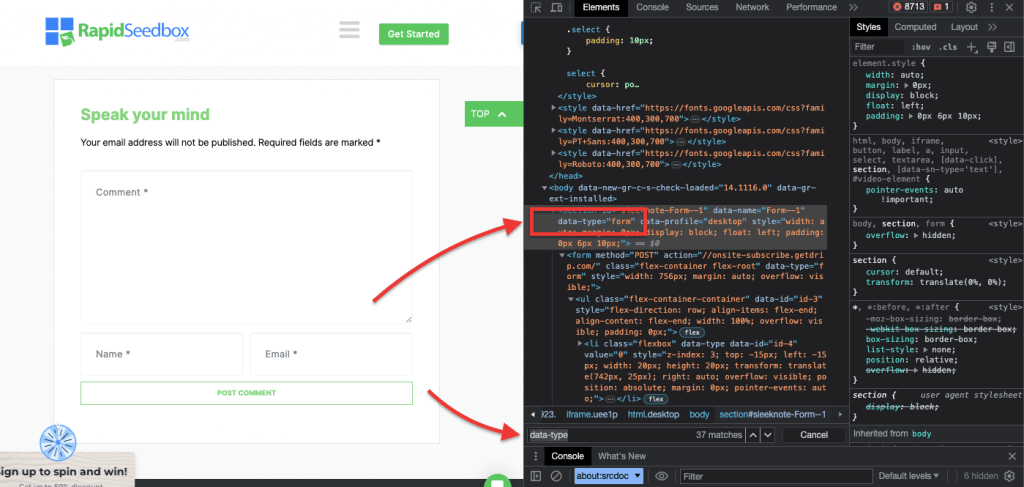
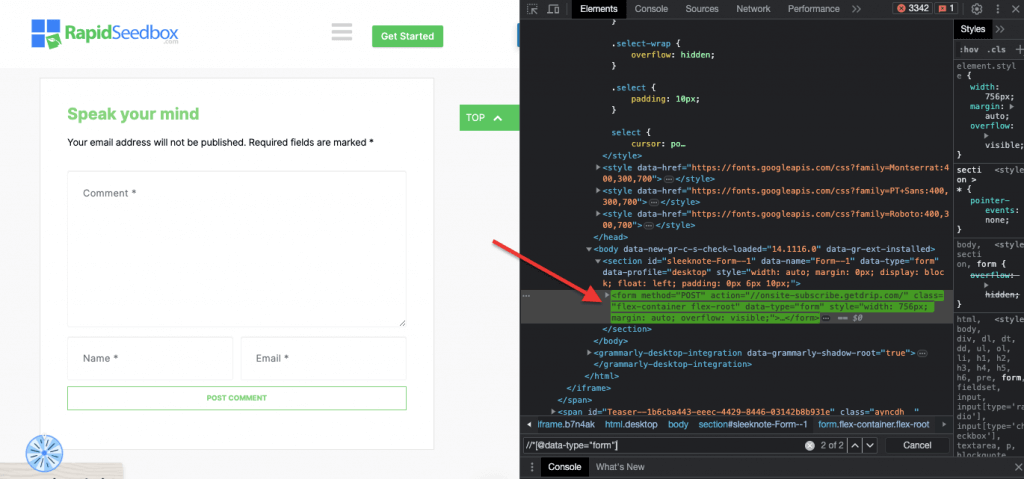
iii.例 3.' //* [@data-type="form"]'
XPath 表达式 //* [@data-type="form"] 会选择所有数据属性值为 "form "的元素。选择 * 符号表示将选择任何具有指定数据属性的元素,无论其节点名称如何。下面的截图显示了手动查找值为 "form "的元素的过程。
使用这些 CSS 和 XPath 选择器从 HTML 页面手动目测和提取数据不仅耗时,而且容易出错。此外,手动或可视化提取数据完全不适合大规模数据收集或重复性刮擦任务。这正是脚本和编程的优势所在。
使用 RapidSeedbox 快速、安全和匿名的代理服务器,提高您的网络搜刮能力。
哪些编程语言最适合网络搜索?
由于 Python 库和软件包的存在,它是最流行的刮擦编程语言(下一节将详细介绍)。 网络搜索是 R因为它也有一套非常棒的支持库和框架。 此外,值得一提的还有 C#,这是一种流行的编程语言,许多网络刮刮卡都使用这种语言。ZenRows 等网站有关于以下方面的综合指南 如何在 C# 中刮擦网站这使开发人员更容易了解流程并开始自己的项目。
为简单起见,本网络搜索指南将重点介绍使用 Python 进行网络搜索。请继续阅读!
3.用 Python 进行网络抓取(附代码)。
既然可以通过编程语言系统地自动使用 CSS 选择器或 XPath 选择器,为什么还要使用 CSS 选择器或 XPath 选择器对 HTML 数据进行目视检查和手动提取呢?
有许多流行的网络搜刮库和框架都支持 CSS 选择器,以便更轻松地提取数据。最流行的网络搜刮编程语言之一是 Python其图书馆,如 美丽汤, 要求, CSS 选择, 硒,和 废料. 这些库使网络刮擦程序能够利用 CSS 和 XPath 选择器高效地提取数据。
美丽汤
BeautifulSoup 是专为解析 HTML 和 XML 文档而设计的最流行、功能最强大的 Python 软件包之一。该软件包可创建网页的解析树,让您轻松地从 HTML 中提取数据。
| 有趣的事实! 在抗击 COVID-19 的斗争中、 林家宝的 DXY-COVID-19-Crawler 使用 BeautifulSoup 从一个中国医疗网站上提取有价值的数据。这样做有助于研究人员监测和了解病毒的传播情况。[资料来源] |
请求。
Python 的 要求 是一个简单但功能强大的 HTTP 库。它可用于发出 HTTP 请求,从网站上获取数据。"Requests "简化了在网络搜刮 Python 项目中发送 HTTP 请求和处理响应的过程。
a.使用 Python 进行网络抓取的教程(+ 代码)
在本教程中,我们将使用 Python 代码中的 "requests "和 BeautifulSoup 库从目标 HTML 网站获取数据。
先决条件
确保满足以下前提条件:
- Python 环境: 确保您有 Python 安装在您的计算机上。此外,请确保您能在首选的 Python 环境中运行脚本(例如,......)、 空闲 或 Jupyter 笔记本).
- 请求图书馆: 安装
要求库。它用于向指定 URL 发送 HTTP GET 请求。您可以使用核心通过跑步pip install requests在命令提示符或终端中。 - BeautifulSoup 图书馆: 安装
beautifulsoup4库。您可以使用核心通过跑步pip install beautifulsoup4在您的终端中。
从网页中抓取数据的 Python 代码(使用 BeautifulSoup)
下面的脚本将获取指定的 URL,使用 BeautifulSoup 解析 HTML 内容,并打印网页上热门新闻文章的标题。

在 IDLE Shell 上运行该脚本时,屏幕会打印出从目标网站收集到的所有 "news_titles"。

b.对我们的 Python 代码进行改动,以便进行网络搜索。
我们可以使用之前的网络搜刮 Python 代码,并进行一些改动,以搜刮不同类型的数据。
例如
- 寻找图像 要查找网页上的所有图像标记(
),可以使用带有标记名 "img "的 find_all() 方法:

- 寻找链接: 要查找网页上代表链接的所有锚标记(),可以使用标记名为 "a "的 find_all() 方法:

所提供的脚本(及其变体)是一个基本的网络搜索脚本。它只需从指定的 URL 中提取并打印热门新闻文章的标题。但遗憾的是,这个简单的脚本缺乏构成更全面的网络搜索项目的许多功能。 您可能需要考虑添加数据存储、错误处理、分页/抓取、用户代理和标题使用、节流和礼貌措施以及处理动态内容的能力等几个要素。
4.网络抓取合法吗?
网络搜索通常被认为是有争议的或非法的。但实际上,这是一种合法的做法,如果遵守一定的道德和法律界限,网络搜索是完全合法的。
网络搜索的合法性取决于所提取数据的性质和所使用的方法。 从互联网上收集可公开获得的信息时,网络搜索被认为是合法的。 不过,在处理个人数据或受版权保护的内容时,尤其需要谨慎。
这里有几个要点需要牢记:
- 请勿抓取私人数据。 提取未公开的数据也是违法行为。在美国、加拿大和欧洲大部分国家,在登录页面(用户和密码登录)后面抓取数据是违法行为。
- 如何处理这些数据会给你带来麻烦。 合乎道德的网络搜索需要注意所收集的数据及其预期目的。应特别注意个人数据和知识产权。确保遵守 GDPR 和 CCPA 等有关个人数据处理的法规。例如,重复使用或转售内容或下载受版权保护的资料均属违法行为(应避免)。
- 查看网站的服务条款也很重要。 这些文件指导任何使用其服务或内容的人应该和不应该如何与资源互动。
- 始终确保使用官方提供的应用程序接口等替代方法。 一些网站(如政府机构、天气预报和社交媒体平台)通过应用程序接口向公众开放部分数据。
- 考虑检查 robots.txt 文件。 This file is saved on the web server and gives directions to web crawlers and web scraping about what parts of a website to avoid and what parts are authorized. It also gives directions about the rate limits.
- 避免发起网络刮擦攻击。 根据上下文的不同,有时网络刮擦也被称为刮擦攻击。当垃圾邮件发送者使用僵尸网络(僵尸大军)向网站发送大量快速请求时,整个网站的服务可能会瘫痪。大规模数据搜刮可能导致整个网站瘫痪。
有关网络搜索法律问题的最新消息。
最近的法律裁决明确指出,一般来说,刮擦可公开获取的数据不被视为违法行为。美国上诉法院做出的一项具有里程碑意义的裁决重申了网络搜刮的合法性,指出在互联网上搜刮可公开访问的数据并不违反《计算机欺诈和滥用法》(CFAA)[资料来源:美国上诉法院]: TechCrunch].
另据最近的新闻报道,针对 OpenAI 和微软的诉讼凸显了人们对隐私、知识产权和反黑客法律的担忧。彭博社].虽然《美国版权法》的效力有限,但违反合同的索赔和各州的隐私法也在探索之中。版权法和合同法之间的互动问题仍未解决,因此在网络搜刮方面还有许多问题没有答案。
最新消息,[消息来源 印度时报]埃隆-马斯克(Elon Musk)正在改变 Twitter 的规则,以防止极端的数据搜刮行为。马斯克认为,极端的网络搜刮会对用户体验产生负面影响。他认为,使用大型语言模型进行生成式人工智能的组织难辞其咎。
5.网站如何阻止网络抓取?
公司希望其部分数据能被人类访问者访问。但是,当公司或用户使用自动脚本或机器人从网站上积极提取数据时,目标网站服务器和页面上可能会出现大量隐私和资源滥用现象。这些受害网站更希望阻止这类流量。
防窃听技术
- 来自单一来源的不寻常的高流量。 网络服务器可能会使用 WAF(网络应用防火墙),其中包含阻止流量的噪声 IP 地址黑名单、"异常 "请求速率和大小过滤器以及过滤机制。有些网站会将 WAF 和 CDN(内容分发网络)结合使用,以完全过滤或减少来自此类 IP 的噪音。
- 有些网站可以检测到类似机器人的浏览模式。 与前一种技术类似,网站也会根据用户代理(HTTP 标头)阻止请求。机器人不使用普通浏览器。这些机器人有不同的用户代理字符串(即爬虫、蜘蛛或机器人),缺乏变化,没有标头(HTTP 标头)。无头浏览器)、申请费率等。
- 网站也会经常更改 HTML 标记。 网络抓取机器人在遍历网站内容时会遵循一致的 "HTML 标记 "路线。有些网站会定期随机更改标记中的 HTML 元素。这种技术会使机器人偏离其正常的搜索习惯或计划。更改 HTML 标记并不能阻止网络刮擦,但会使其更具挑战性。
- 使用验证码等挑战。 为了避免机器人使用无头浏览器,一些网站要求验证码挑战。使用无头浏览器的机器人很难解决这类问题。验证码是在用户层面(通过浏览器)而不是由机器人来解决的。
- 有些网站是搜索机器人的陷阱(蜜罐)。 有些网站是专为诱捕搜刮机器人而创建的,这种技术被称为 "蜜罐"。这些 "巢穴 "只有搜刮机器人才能看到(普通人类访问者看不到),其目的是将网络搜刮者引入陷阱。
6.网络抓取的道德和最佳实践。
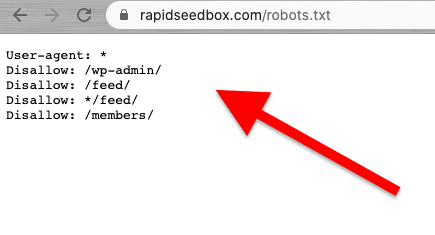
网络搜索应负责任地、合乎道德地进行.如前所述,阅读 "条款和条件 "或 "服务条款 "应能让您了解必须遵守的限制。如果你想了解网络爬虫的规则,可以查看它的 ROBOTS.txt。
如果完全不允许或阻止网络搜刮,则使用其应用程序接口(如果可用)。
此外,还要注意目标网站的带宽,避免过多的请求使服务器超负荷。自动请求的速率和正确的超时对避免给目标服务器造成压力至关重要。最好模拟实时用户。此外,切勿在登录页面后搜索数据。
遵守规则,你就会没事。
网络抓取最佳实践
- 使用代理。 代理是转发请求的中间服务器。当使用代理进行网络搜刮时,你会通过代理转发原始请求。因此,代理会将请求与自己的 IP 映射,并转发到目标网站。使用代理可以
- 消除您的 IP 被列入黑名单或屏蔽的可能性。 总是通过各种代理提出申请-- IPv6代理服务器 就是一个很好的例子。代理池可以帮助你执行更大量的请求,而不会被阻止。
- 绕过地理定制内容。 特定区域的代理对于根据该特定地理区域搜索数据非常有用。这在网站和服务位于 CDN 后方时非常有用。
- 轮流代理。 旋转代理为每一个新连接从池中获取(旋转)一个新 IP。请注意 VPN 不是代理服务器。 虽然它们的作用非常相似,都是提供匿名性,但它们在不同层面上发挥作用。
- 旋转 UA(用户代理)和 HTTP 请求头。 要旋转 UA 和 HTTP 头信息,您需要从真实网络浏览器中收集 UA 字符串列表。将该列表放入 Python 中的网络抓取代码中,并设置请求以随机选取字符串。
- 不要突破极限。 减缓请求数量、轮换和随机化。如果你对一个网站提出了大量请求,首先要随机处理。让每个请求看起来都是随机的,像人一样。首先,借助旋转代理改变每次请求的 IP。此外,使用不同的 HTTP 标头,让请求看起来像是来自其他浏览器。
使用 RapidSeedbox 快速、安全和匿名的代理服务器,提高您的网络搜刮能力。
7.网络抓取常见问题:常见问题。
a.什么是 robots.txt,它在网络搜索中起什么作用?
" robots.txt 文件是网站所有者、网络爬虫和 "搜刮者 "之间的通信工具。它是放置在网站服务器上的一个文本文件,向网络机器人(爬虫、网络蜘蛛和其他自动机器人)提供有关允许它们访问和抓取网站哪些部分以及应该避免哪些部分的指令。"乖巧的 "网络爬虫(如 Googlebot)会自动阅读 robots.txt。而抓取程序则不会读取该文件。因此,了解 robots.txt 对于尊重网站所有者的意愿非常重要。
b.网站管理员使用什么技术来避免 "滥用 "或 "未经授权 "的网络搜刮尝试?
并非所有刮擦程序都能以道德和合法的方式提取数据。它们不遵守网站的 TOS(服务条款)或 robots.txt 指南。因此,网站管理员可能会采取额外措施来保护数据和资源,例如使用 IP 拦截或验证码挑战。他们还可能使用速率限制措施、用户代理验证(以识别潜在的机器人)、跟踪会话、使用基于令牌的身份验证、使用 CDN(内容分发网络),甚至使用基于行为的检测系统。
c.网络抓取与网络爬取?
尽管网络刮擦和网络爬行都是网络数据提取技术,但它们的目的、范围、自动化程度和法律方面都不尽相同。一方面,网络刮擦技术旨在从特定网站提取特定数据。它们有针对性,范围具体而有限。网络抓取使用自动脚本或第三方工具来请求、接收、解析、提取和构造数据。网络抓取技术(如 列表抓取)则用于系统地搜索网络。它们在搜索引擎(范围更广)、社交媒体平台、研究人员、内容聚合者等中很受欢迎。网络爬虫可以自动访问许多网站(通过机器人、爬虫或蜘蛛),建立一个列表,索引数据(创建副本),并将其存储到数据库中。网络爬虫通常会检查 ROBOTS.txt 文件。
d.数据挖掘与数据搜刮:它们有何异同?
数据挖掘和数据刮擦都涉及数据提取。不过,数据挖掘侧重于使用统计和机器学习技术来分析结构化数据集。其目的是在大型复杂的结构化数据集中识别模式、关系和见解。另一方面,数据挖掘侧重于从网页和网站中 "收集部分 "特定信息。这两种技术和工具可以同时使用。网络搜刮可以作为从网络上收集数据的第一步,然后将数据输入数据挖掘算法,进行深入分析和洞察发现。
e.什么是屏幕抓取? 它与数据抓取有何关系?
这两种技术都侧重于数据提取,但提取的数据类型不同。 刮网 屏幕抓取工具旨在 "自动 "捕捉和提取网站和文档中显示的可视化数据,包括屏幕文本。与从 HTML 中解析数据(从而提取各种网络数据)的网络搜刮不同,屏幕搜刮直接从屏幕显示中读取文本数据。
f.网络收获是否等同于网络抓取?
数据搜刮和网络收获密切相关,经常被交替使用,但它们并不是同一个概念。网络采集具有更广泛的内涵。它包含从网络中提取数据的不同方法,包括各种自动网络提取机制,如网络刮擦。一个明显的区别是,网络采集通常用于涉及应用程序接口(API)的情况,而不是直接解析网页中的 HTML 代码(如网络搜刮)。
g.CSS 选择器与 XPath 选择器: 刮擦时有哪些区别?
CSS 选择器是一种在网络搜刮过程中提取数据的有效方法。它们提供了一种简单明了的语法,在大多数情况下都能很好地应用。不过,在更复杂的情况下或处理嵌套结构时,XPath 选择器可以提供额外的灵活性和功能。
h.如何使用 Selenium 处理动态网站?
Selenium 是一款强大的动态网站网络扫描工具。它允许你像人类用户一样与网页上的元素进行交互。这种能力使您的 "脚本 "能够浏览动态生成的内容。通过使用 Selenium 的 WebDriver您还可以使用 JavaScript,等待页面元素加载、与 AJAX 元素交互,以及从严重依赖 JavaScript 的网站上抓取数据。
i. 如何在网络抓取时处理 AJAX 和 JavaScript?
在网络搜刮过程中处理 AJAX 和 JavaScript 时,Requests 和 Beautiful Soup 等传统库可能无法满足要求。要处理 AJAX 请求和 JavaScript 渲染的内容,可以使用 Selenium 等工具或无头浏览器,如 木偶师.
8. 结语。
恭喜您您完成了网络搜索终极指南的学习!
我们希望本指南能为您提供相关知识和工具,帮助您在项目中发挥网络搜索的潜力。
请记住,权力越大,责任越大。 在您开始网络刮擦之旅时,请始终将道德实践放在首位,尊重网站的服务条款,并注意数据隐私。
我们只是触及了冰山一角。网络抓取是一个相当全面的话题。不过,嘿,你已经刮过一个网站了!
不断学习,掌握最新技术和法律发展动态,将使您能够驾驭这个复杂的世界。
使用这些 CSS 和 XPath 选择器从 HTML 页面手动目测和提取数据不仅耗时,而且容易出错。此外,手动或可视化提取数据完全不适合大规模数据收集或重复性刮擦任务。这正是脚本和编程的优势所在。
0评论