Hoy en día, el web scraping y el crawling son imprescindibles para la extracción y el análisis de datos. IPv6, la última versión del Protocolo de Internet, ha revolucionado estos procesos.
Por eso, te mostraré cómo utilizar IPv6 para el web scraping y el crawling. Verá cómo se hace, cuáles son los beneficios, los retos a los que puede enfrentarse y, lo más importante, cómo abordarlos.

Tabla de Contenidos
- TL:DR Web Scraping y Web Crawling
- Web Scraping y Crawling con IPv6 - ¿Cómo hacerlo?
- Ventajas del uso de IPv6 para Web Scraping y Crawling
- Retos potenciales del Web Scraping y Crawling con IPv6
- Uso de IPv6 para Web Scraping - Casos prácticos
- Palabras finales
1. TL:DR Web Scraping y Web Crawling
Web scraping se refiere al proceso de extraer datos de sitios web, mientras que el rastreo web explora regularmente la web en busca de información recién indexada.
2. Web Scraping y Crawling con IPv6 - ¿Cómo hacerlo?
Para un raspado eficaz de la web, es necesario utilizar proxies IPv6. es crucial. Ayudan a eludir las restricciones basadas en la IP y a mantener el anonimato, algo esencial para el scraping.
a. Requisitos previos
Antes de empezar, asegúrese de que sus herramientas de scraping están preparadas para IPv6. Esta compatibilidad es esencial para extraer datos sin problemas.
Distribuya su presupuesto de rastreo:
Utilizando un variedad de direcciones IPv6 reducirá significativamente los posibles bloqueos impuestos por sus sitios web objetivo.
b. Puesta en marcha
- Elegir una herramienta adecuada de web scraping: Seleccione una herramienta o software compatible con IPv6. Algunas de las opciones más populares son las bibliotecas de Python como Chatarra y BeautifulSoup.
- Compatibilidad con IPv6: Asegúrese de que su conexión a Internet está preparada para IPv6. Póngase en contacto con su ISP si no está seguro de su conectividad IPv6.
c. Obtener proxies IPv6
Los proxies enmascaran su dirección IP, ayudándole a eludir las restricciones de los sitios web y evitar las prohibiciones. proxies IPv6. ofrecen una amplia gama de direcciones IP, lo que las hace ideales para el scraping.
- Seleccione un proveedor de proxy: Elija un proveedor que ofrezca proxies IPv6 fiables. Tenga en cuenta factores como el coste, la velocidad y el anonimato. Los proxies pueden ser HTTP or SOCKS5.
- Configure su proxy: Configure el proxy en su herramienta de scraping. Esto suele implicar introducir la dirección y el puerto del proxy en la configuración de la herramienta. Sin embargo, estos pasos son sólo los básicos, necesarios para la mayoría de las herramientas. Debes consultar la documentación de tu herramienta o a tu proveedor de proxy para integrarlos sin problemas.
d. Prepare su script de scraping
- Codificación básica: Escribe un script que envíe peticiones al sitio web de destino y analice el HTML devuelto en busca de datos. Si estás usando Python, puedes consultar esto guía para crear scripts de scraping y parseo de texto.
- JavaScript manejo de: Para sitios con mucho JavaScript, considere el uso de herramientas como Selenio or Titiriteroque puede procesar JavaScript como un navegador.
e. Ejecute su rascador
- Empezar con pruebas: Al principio, realiza pruebas a pequeña escala para asegurarte de que tu scraper funciona según lo previsto. Controla el rendimiento y, si es necesario, ajusta el script.
- Respetar las normas del sitio web: No hace falta decirlo, pero compruebe siempre el sitio web de
robots.txty siga sus directrices para evitar posibles problemas legales.
f. Gestionar los datos adquiridos
- Almacenamiento de datos: Decida cómo almacenará los datos raspados. En la mayoría de los casos, puedes elegir entre bases de datos, archivos CSV o JSON.
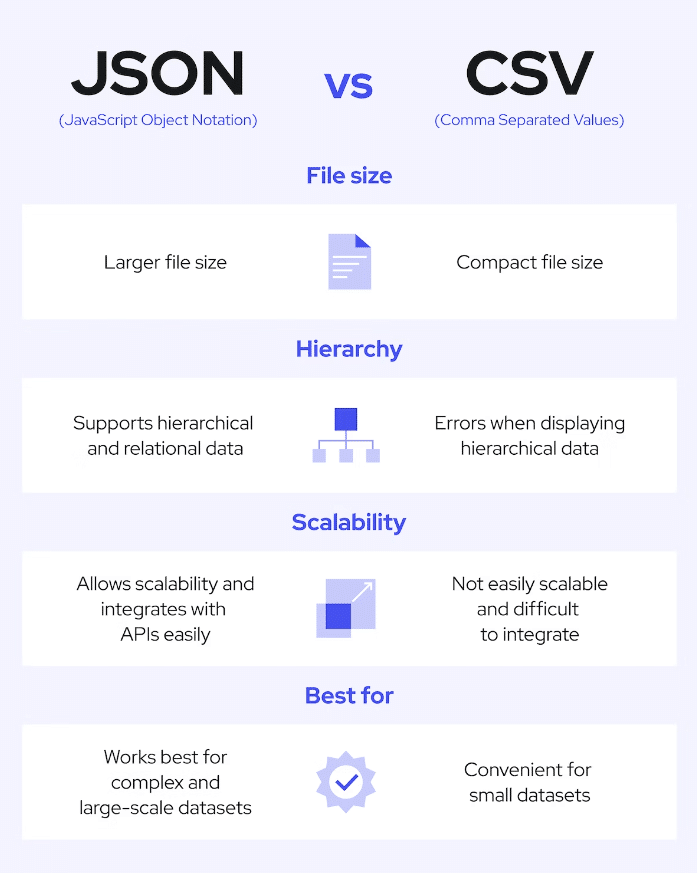
Crédito de la imagen: Coresignal
- Prepárese para los retos: En teoría, todo puede ser perfecto, pero el raspado web en el mundo real presenta desafíos. Dicho esto, prepárate para hacer frente a los problemas más comunes, como los CAPTCHA y las prohibiciones de IP. El uso de un grupo rotativo de proxies IPv6 puede ayudar con estos problemas potenciales.
g. La ampliación es inevitable
- Prepárese para escalar: A medida que te vayas sintiendo más cómodo, podrás ampliar tus operaciones de scraping. Según mi experiencia siempre el caso. La ampliación implica utilizar más proxies y ejecutar varios scrapers simultáneamente. Si no dispone de presupuesto, considere cuidadosamente su estrategia.
- Mantenimiento: Esto es crucial en un mundo web en constante evolución. Actualice y mantenga regularmente sus scripts de scraping, sobre todo porque los sitios web cambian a menudo su diseño y estructura.
3. Ventajas del uso de IPv6 para Web Scraping y Crawling
Teniendo en cuenta cuántos factores pueden influir en su estrategia y la incertidumbre, quizá se pregunte por qué IPv6 es una buena idea.
Es una pregunta lógica, teniendo en cuenta que IPv4, eliminará al menos un problema potencial - compatibilidad. De hecho, menos del 40% de todos los sitios web no admiten IPv6.
Tabla comparativa IPv4 vs IPv6
| Característica | Proxies IPv4 | Proxies IPv6 |
|---|---|---|
| Dirección Pool | ~4.300 millones de direcciones (agotadas) | Prácticamente ilimitado (3,4×10³⁸) |
| Coste | Caro, escaso | Más asequible y abundante |
| Compatibilidad | Apoyado en todas partes | ~60% de sitios actualmente soportan |
| Rendimiento | Protocolo más antiguo, enrutamiento más lento | Cabeceras más sencillas, encaminamiento más rápido |
| El mejor caso de uso | Sistemas heredados, acceso universal | Raspado a gran escala, a prueba de futuro |
Aun así, IPv6 ofrece varias ventajas que no puede ignorar.
- Mayor anonimato y seguridad: IPv6 es compatible con IPsec, que ofrece conexiones cifradas y seguras. Esto es crucial para la privacidad durante el scraping de sitios web.
- Asequibilidad: Sorprendentemente, las direcciones IPv6 son más baratas que las IPv4. Esto reducirá los costes operativos.
- Mejor rendimiento: El formato de cabecera más sencillo de IPv6 y un encaminamiento más eficaz (en comparación con IPv4) mejoran el rendimiento general de la red.
- Estrategia a largo plazo: Empezar con IPv6 garantiza la compatibilidad y pertinencia a largo plazo a medida que Internet transita hacia este protocolo. Cada vez más plataformas considerarán obsoleto IPv4, así que más vale prepararse para el futuro.
¿Qué es mejor para el scraping? ¿IPv6 o IPv4? Más información sobre este tema en: IPv4 frente a IPv6 para el scraping
¿Quiere mejorar el rastreo y el scraping web con IPv6?
Aumente su eficiencia con los fiables servicios proxy IPv6 de RapidSeedbox. Disfrute de un raspado y rastreo web más rápido y seguro, respaldado por un rendimiento excepcional y un soporte sólido.
4. Retos potenciales del Web Scraping y Crawling con IPv6
a. Adopción limitada de IPv6
El problema:
A pesar de sus ventajas, IPv6 aún no se ha adoptado masivamente. Muchos sitios web y proveedores de servicios de Internet siguen utilizando IPv4, lo que puede limitar la eficacia del scraping basado en IPv6 en determinadas situaciones.
Cómo abordarlo:
Use dual-stack systems that support both IPv4 e IPv6. This hybrid approach ensures compatibility with all types of networks and websites. Furthermore, using a servicio proxy que ofrece direcciones IPv4 e IPv6 ofrecerá más flexibilidad.
b. Complejidad técnica
El problema:
El transición de IPv4 a IPv6 puede suponer un reto técnico para algunas empresas. IPv6 tiene un esquema de direccionamiento diferente y requiere actualizaciones de la infraestructura y el software de la red. Esto exigirá más gastos y una gestión adecuada de la red.
Cómo abordarlo:
Invierta en formación para que su equipo entienda el IPv6. Además, elija herramientas y software de web scraping diseñados para funcionar sin problemas tanto con IPv4 como con IPv6. Así se reduce la carga técnica y se garantiza un funcionamiento más fluido.
Además, asegúrese de que su equipo tiene los conocimientos adecuados sobre cómo abordar los posibles problemas de compatibilidad con IPv6.
c. Problemas de compatibilidad
El problema:
Es posible que los sistemas y herramientas más antiguos y la mayoría de los sitios web no sean compatibles con IPv6, lo que puede impedir tus esfuerzos de scraping. Ten en cuenta que la mayoría de los sitios conocidos lo soportan, pero si necesitas conocimientos específicos de algún nicho, la mayoría de los sitios web más pequeños solo soportan IPv4.
Cómo abordarlo:
Actualice gradualmente sus herramientas y sistemas para que sean compatibles con IPv6. Mientras tanto, utilice un servicio proxy que pueda traducir las direcciones IPv6 de nuevo a IPv4 cuando sea necesario, lo que garantizará un acceso ininterrumpido a todo tipo de sitios web. Esto le resultará muy útil cuando se amplíe.
d. Gestión de direcciones IP
El problema:
Aunque IPv6 ofrece un enorme conjunto de direcciones IP, la gestión de estas direcciones para el web scraping puede resultar complicada, sobre todo cuando se amplían las operaciones.
Cómo abordarlo:
Utilice herramientas avanzadas de gestión de proxy que puedan automatizar la asignación y rotación de direcciones IPv6. Esto ayuda a gestionar eficazmente un gran número de IP y reduce el riesgo de ser bloqueado por los sitios web de destino.
Por ejemplo, RapidSeedbox ofrece 100 direcciones IP IPv6 diferentes en su plan más barato.
e. Seguridad
El problema:
With the increased adoption of IPv6, there might be concerns about security and privacy, especially when scraping sensitive data.
Cómo abordarlo:
Asegúrese de que sus operaciones de scraping cumplen la legislación sobre protección de datos. Utilice conexiones seguras y cifradas para sus operaciones de scraping. Además, elija proveedores de proxy que den prioridad a la seguridad y la privacidad. Por último, pero no por ello menos importante, asegúrate de que has comprobado las normas de los sitios web objetivo.
f. Medidas de detección y antiscraping
El problema:
Los sitios web utilizan cada vez más sofisticadas medidas anti-scraping capaces de detectar y bloquear las actividades de scraping, incluso con el uso de proxies. Estas medidas de prevención han aumentado desde la publicación de ChatGPT.
Cómo abordarlo:
Utilice técnicas de scraping más sofisticadas, como la rotación de agentes de usuario, la variación de los intervalos de solicitud y el uso de herramientas de scraping más avanzadas que puedan imitar los patrones de navegación humana.
Además, aplique prácticas éticas de scraping para respetar las condiciones del sitio web y reducir el riesgo de ser bloqueado.
5. Uso de IPv6 para Web Scraping - Casos de uso
El uso de proxies IPv6 para el web scraping abre un abanico de posibilidades gracias a sus características únicas. IPv6 permite una rotación de IP masiva y de bajo coste para rastreo de listas a gran escalareduciendo los bloqueos y mejorando las tasas de éxito del raspado.
He aquí los posibles casos de uso más comunes:
a. Recogida de datos a gran escala
Los proxies IPv6 disponen de un enorme conjunto de direcciones IP, lo que los hace ideales para la recopilación de datos a gran escala. Esto es especialmente útil para empresas e investigadores que necesitan recopilar amplios conjuntos de datos de varios sitios web sin verse restringidos por las limitaciones de IP.
b. Estudios de mercado
Las empresas y los especialistas en SEO utilizan el web scraping con proxies IPv6 para supervisar a sus competidores, rastrear los rankings SEO y comprender las tendencias del mercado. El gran número de IPs disponibles ayuda a recopilar datos de forma eficiente desde diferentes regiones y motores de búsqueda sin activar medidas anti-scraping. La mayoría de las herramientas SEO del mercado, como Ahrefs, Semrush y otras, se basan en el raspado web IPv6 para supervisar las posiciones SERP de sus clientes.
c. Seguimiento SEO
Con proxies IPv6.Con el proxy IPv6, puede realizar un seguimiento de las clasificaciones y ejecutar consultas SERP a escala. Y el proxy IPv6 también es perfecto para vigilar a los competidores sin hacer saltar las alarmas. Dado que el conjunto de direcciones es prácticamente ilimitado, la rotación de IP se realiza sin problemas. Eso significa datos más limpios en todas las regiones y dispositivos - perfecto para auditorías de palabras clave, estudios de mercado y seguimiento SEO a gran escala sin encontrar bloqueos de IP.
d. Zapatillas de deporte
En el copiado de zapatillas, cada milisegundo y cada IP cuentan. Los proxies IPv6 residenciales dirigen el tráfico a través de dispositivos reales, haciéndole parecer un comprador auténtico en lugar de un bot. Esto ayuda a eludir los filtros anti-bot y aumenta las probabilidades de conseguir ofertas limitadas. Si se combinan con herramientas de automatización, los distribuidores pueden ampliarse, rotar entre cientos de direcciones IPv6 residenciales y aumentar sus posibilidades de conseguir más pares. Más información en: proxies de zapatillas
e. Comercio electrónico y comparación de precios
No sé si has vendido Nike recientemente, pero la gente está ganando literalmente millones de dólares vendiendo zapatillas. Los minoristas y las plataformas de comercio electrónico pueden utilizar el web scraping para controlar los precios de la competencia, la disponibilidad de los productos y las opiniones de los consumidores. Los proxies IPv6 les permiten hacer un amplio scraping de los sitios web de la competencia sin riesgo de ser bloqueados, lo que les garantiza disponer de los datos más recientes para sus estrategias de precios competitivos.
f. Social análisis de los medios de comunicación
Para el análisis de las redes sociales, los proxies IPv6 permiten recopilar grandes volúmenes de datos en todas las plataformas. Estos datos facilitan el análisis de opiniones, el seguimiento de tendencias y la comprensión del comportamiento de los consumidores. Redes como Facebook, Instagramy Twitter detectan rápidamente cualquier actividad inusual, por lo que los proxies residenciales IPv6 son especialmente valiosos. Al camuflarse como usuarios reales, permiten a vendedores, analistas e investigadores recopilar métricas precisas de participación y tendencias sociales a gran escala sin provocar bloqueos de seguridad.
Nota: En la mayoría de los casos, el scraping de redes sociales puede ser considerado ilegal y una violación de los derechos de autor en algunas jurisdicciones, así que tenga en cuenta los posibles problemas legales. Más información en: ¿es legal el web scraping?
g. Investigación académica:
Se trata de un caso de uso poco frecuente, pero los investigadores pueden recopilar grandes cantidades de datos de diversas fuentes en línea para sus estudios. Los proxies IPv6 facilitan el acceso ininterrumpido y anónimo a sitios web, lo que es crucial para recopilar conjuntos de datos imparciales y completos.
h. Agregación de contenidos
El web scraping es utilizado por agregadores de noticias y curadores de contenidos para recopilar artículos, entradas de blog y noticias de toda la web. Los proxies IPv6 ayudan a acceder a diversas fuentes sin verse limitados por restricciones basadas en la IP.
Sin embargo, si planea crear un sitio web de este tipo, tenga en cuenta que a menudo se consideran spam y pueden tener dificultades para posicionarse en las SERP. Mi consejo es que utilices este tipo de tácticas solo para compartir noticias.
i. Listados de bienes inmuebles y propiedades
Con el auge del mercado inmobiliario en los últimos años, no es de extrañar que el rastreo de sitios web de anuncios inmobiliarios proporcione datos valiosos sobre las tendencias del mercado, los precios de las propiedades y su disponibilidad.
Los proxies IPv6 permiten rastrear estos sitios a gran escala sin ser detectados.
j. Desguace de tarifas de viaje
Las agencias de viajes y los sitios de comparación de tarifas pueden utilizar el web scraping para recopilar datos sobre precios de vuelos, hoteles y coches de alquiler. Después de Covid, esta táctica se ha vuelto extremadamente eficaz. Los proxies IPv6 permiten a estos agregadores acceder a esta información desde varios proveedores simultáneamente y ofrecer una gran experiencia al usuario.
k. Verificación de anuncios
Los anuncios son más potentes (y más caros) que nunca, y las empresas deben utilizar el web scraping para verificar si sus anuncios en línea se muestran como es debido y comprobar si hay fraude publicitario. Los proxies IPv6 les permiten comprobar de forma anónima los anuncios en distintas regiones y plataformas.
l. Ciberseguridad
Por mi experiencia como experto en ciberseguridad, el scraping se utiliza a menudo para recopilar datos sobre posibles amenazas a la seguridad, como sitios web de phishing o actividades fraudulentas. Los proxies IPv6 proporcionan el anonimato necesario para este tipo de operaciones sensibles a escala.
| Veredicto final: En todos los casos mencionados, la principal ventaja de utilizar proxies IPv6 es la posibilidad de realizar web scraping a una escala mucho mayor y con mayor eficacia en comparación con IPv4. Esto se debe al espacio de direcciones significativamente mayor y a la menor probabilidad de encontrarse con prohibiciones de IP o límites de velocidad. |
FAQ: Scraping con proxies IPv6
Los proxies IPv6 actúan como intermediarios, ocultando tu IP real tras una dirección IPv6. Son clave para el scraping porque ayudan a esquivar prohibiciones, eludir restricciones y extraer datos a gran escala. Con el suministro masivo de direcciones IPv6, puedes rotar las IP de forma mucho más eficiente que con IPv4.
Sí. Los proxies IPv6 residenciales dirigen el tráfico a través de dispositivos y proveedores de Internet reales en lugar de centros de datos. Esto los hace más difíciles de marcar o bloquear, lo que es especialmente útil para el scraping de redes sociales, comercio electrónico u otros sitios sensibles. Si necesitas autenticidad, sigilo y mejores tasas de éxito, el IPv6 residencial es el camino a seguir.
Las opciones gratuitas suenan atractivas, pero a menudo vienen acompañadas de quebraderos de cabeza: velocidades lentas, conexiones inestables, escaso anonimato y riesgos de seguridad. En cambio, los proxies de pago ofrecen fiabilidad, velocidad y asistencia. Si estás llevando a cabo un proyecto serio, utiliza proxies gratuitos sólo para hacer pruebas, no para hacer scraping en directo.
Las mejores configuraciones equilibran velocidad, seguridad, escalabilidad y precio. Elija proveedores con grandes grupos de IP, opciones para proxies estáticos y rotatorios, soporte 24/7 y precios claros. Para casos de uso avanzados -seguimiento SEO, verificación de anuncios, copiado de zapatillas- la mejor opción suele ser una mezcla de proxies IPv6 residenciales y de centros de datos.
Sí. La mayoría de las herramientas y API de scraping, como Scrapy, Puppeteer o Selenium, admiten proxies IPv6. Su uso ayuda a distribuir las solicitudes, reducir los límites de velocidad y facilitar la extracción de datos. Esto es especialmente útil cuando una API limita o bloquea el tráfico IPv4.
6. Palabras finales
El web scraping y el crawling con IPv6 representan un avance significativo en la extracción de datos.
Si consigue comprender y aprovechar esta tecnología, usted o su empresa podrán conseguir una recogida de datos mucho más eficaz, segura y rentable.
El transición a IPv6 no es sólo una actualización técnica, sino que también requiere un plan estratégico para alcanzar un determinado objetivo.
¿Quiere mejorar el rastreo y el scraping web con IPv6?
Aumente su eficiencia con los fiables servicios proxy IPv6 de RapidSeedbox. Disfrute de un raspado y rastreo web más rápido y seguro, respaldado por un rendimiento excepcional y un soporte sólido.
Descargo de responsabilidad: Este material ha sido desarrollado estrictamente con fines informativos. No constituye respaldo de ninguna actividad (incluidas las actividades ilegales), productos o servicios. Usted es el único responsable de cumplir con las leyes aplicables, incluidas las leyes de propiedad intelectual, cuando utilice nuestros servicios o confíe en cualquier información contenida en este documento. No aceptamos ninguna responsabilidad por los daños que surjan del uso de nuestros servicios o la información contenida en este documento de ninguna manera, excepto cuando lo exija explícitamente la ley.
0Comentarios