Zaman sekarang, web scraping dan web crawling merupakan hal yang wajib untuk melakukan ekstraksi dan analisis data. IPv6 sebagai versi Protokol Internet terbaru telah mengubah banyak hal terkait proses web scraping dan web crawling.
Itu sebabnya, saya akan menunjukkan kepada Anda bagaimana cara menggunakan IPv6 untuk melakukan scraping dan crawling web. Anda akan melihat bagaimana cara melakukannya, apa manfaatnya, tantangan apa yang mungkin Anda hadapi, dan yang paling penting - bagaimana cara mengatasinya.

Daftar Isi
- TL:DR Web Scraping dan Web Crawling
- Bagaimana cara melakukan Web Scraping dan Web Crawling dengan IPv6
- Manfaat Menggunakan IPv6 untuk Web Scraping dan web Crawling
- Potensi tantangan yang akan ditemui ketika melakukan Web Scraping dan Web Crawling dengan IPv6
- Menggunakan IPv6 untuk Scraping Web - Kasus Penggunaan
- Kesimpulan.
1. TL:DR Web Scraping dan Web Crawling
Web scraping yaitu proses mengekstraksi data dari situs web, sedangkan web crawling mengacu pada proses penjelajahan web untuk mencari informasi yang baru diindeks.
2. Bagaimana cara melakukan Web Scraping dan Web Crawling dengan IPv6
Untuk web scraping yang efektif, IPv6 proxy sangatlah penting, Hal ini karena, IPv6 akan membantu melakukan bypass pembatasan berbasis IP dan menjaga anonimitas yang dibutuhkan untuk scraping.
a. Yang Kamu Perlu Siapkan
Sebelum memulai, pastikan scraping tools sudah siap untuk IPv6. Hal ini sangat penting untuk ekstraksi data bebas hambatan.
Distribusikan crawling budget-mu
Menggunakan berbagai IPv6 address akan mengurangi kemungkinan kamu diblokir oleh web tujuan secara signifikan.
b. Persiapan
- Pilih web scraping tool yang sesuai: Pilih tool atau software yang kompatibel dengan IPv6. Beberapa pilihan yang paling populer adalah Python library, seperti Scrapy dan BeautifulSoup.
- Kompatibilitas IPv6: Pastikan koneksi internetmu siap untuk IPv6. Hubungi penyedia layanan internetmu, jika kamu belum tahu dan yakin terkait koneksi IPv6 yang kamu miliki.
c. Dapatkan IPv6 Proxy
Proxy akan menyembunyikan IP address milikmu dan membantu menerobos pembatasan situs web dan menghindari pemblokiran. IPv6 proxy menawarkan berbagai macam alamat IP, sehingga ideal untuk melakukan scraping.
- Pilih penyedia proxy: Pilih penyedia yang menawarkan proxy IPv6 yang andal. Pertimbangkan faktor-faktor seperti biaya, kecepatan, dan anonimitas. Proxy dapat berupa HTTP atau SOCKS5.
- Konfigurasikan proxy: atur proxy-mu di scraping tool yang telah kamu pilih. Biasanya kamu harus memasukkan alamat dan port proxy ke dalam pengaturan tools yang dipilih. Tapi, hal itu hanyalah dasarnya saja. Untuk sebagian besar tools, kamu sebaiknya berkonsultasi dengan bagian dokumentasi tools pilihanmu atau proxy provider agar kamu bisa mengintegrasikan proxy dan tools dengan lancar.
d. Siapkan Scraping Script
- Basic coding: Menulis script yang dapat mengirimkan request ke situs web target dan mem-parsing HTML yang dikembalikan untuk mendapatkan data. Jika kamu menggunakan Python, silakan baca artikel ini: panduan untuk membuat skrip untuk mengikis dan mengurai teks.
- JavaScript handling: Untuk situs yang menggunakan JavaScript, pertimbangkan untuk menggunakan tools, seperti Selenium atau Puppeteer, yang dapat merender JavaScript seperti halnya browser.
e. Jalankan Scraper
- Lakukan test runs dulu: Untuk awalan, ada baiknya kamu melakukan uji coba skala kecil untuk memastikan scraper-mu berfungsi sebagaimana mestinya. Pantau kinerjanya dan, jika perlu, sesuaikan dengan script yang kamu buat.
- Mematuhi aturan situs web: Jangan lupa untuk memeriksa
robots.txtdan mengikuti panduannya untuk menghindari potensi masalah hukum.
f. Mengelola Data yang Diperoleh
- Penyimpanan data: Tentukan bagaimana kamu akan menyimpan data dari scraping. Umumnya, kamu dapat memilih antara database, file CSV, atau JSON.
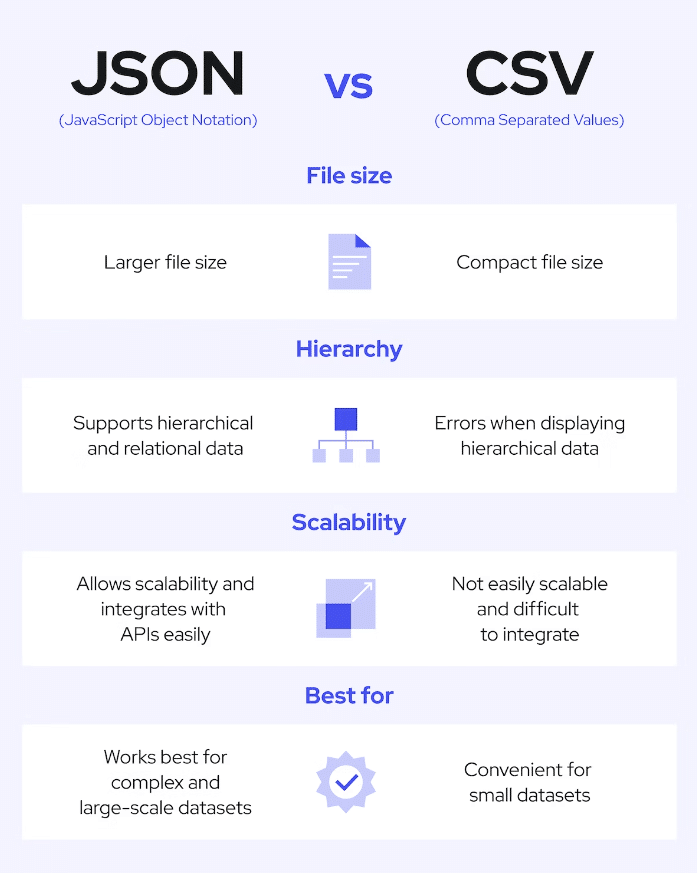
Kredit gambar: Coresignal
- Bersiaplah menghadapi potensi masalah: Secara teori, semua bisa berjalan dengan baik. Namun, kenyataanya scraping web bisa saja menemukan masalah, seperti CAPTCHA dan pelarangan IP. Menggunakan kumpulan proxy IPv6 yang terus berganti dapat membantu mengatasi masalah-masalah yang mungkin akan kita temui.
g. Scaling yang Tidak Bisa Dihindari
- Bersiaplah untuk melakukan scaling: Setelah kamu merasa lebih nyaman, kamu bisa meningkatkan skala scraping yang kamu lakukan. Berdasarkan pengalaman, Scaling melibatkan penggunaan proxy yang lebih banyak dan menjalankan beberapa scrapers secara bersamaan. Jika kamu tidak memiliki anggaran yang cukup, pertimbangkan strategimu dengan hati-hati.
- Maintenance: Hal ini sangat penting dalam dunia web yang terus berkembang. Perbarui dan lakukan maintenance script scraping secara rutin, terutama karena situs web sering kali mengubah tata letak dan strukturnya.
3. Manfaat Menggunakan IPv6 untuk Web Scraping dan web Crawling
Banyak faktor yang dapat mempengaruhi strategimu, kamu mungkin bertanya-tanya, apakah menggunakan IPv6 adalah strategi yang tepat?
Pertanyaan itu memang logis, apalagi mengingat bahwa IPv4 akan menghilangkan setidaknya satu potensi masalah, yaitu kompatibilitas. Bahkan, kurang dari 40% dari semua situs web tidak mendukung IPv6.
Tabel Perbandingan IPv4 vs IPv6
| Fitur | Proksi IPv4 | Proksi IPv6 |
|---|---|---|
| Kumpulan Alamat | ~4,3 miliar alamat (habis) | Hampir tidak terbatas (3,4×10³⁸) |
| Biaya | Mahal, langka | Lebih terjangkau, berlimpah |
| Kompatibilitas | Didukung di mana-mana | ~60% situs saat ini mendukung |
| Kinerja | Protokol yang lebih tua, perutean yang lebih lambat | Header yang lebih sederhana, perutean yang lebih cepat |
| Kasus Penggunaan Terbaik | Sistem lama, akses universal | Pengikisan berskala besar, bukti masa depan |
Meski begitu, IPv6 tetap bisa menawarkan banyak manfaat lain, lho!
- Anonimitas dan keamanan yang lebih baik: IPv6 mendukung IPsec, yang menawarkan koneksi terenkripsi dan aman. Hal ini sangat penting untuk privasi saat melakukan scraping suatu web.
- Terjangkau: Nyatanya, IPv6 lebih murah daripada IPv4. Tentunya hal Ini akan mengurangi biaya operasional.
- Performa yang lebih baik: Format header IPv6 yang lebih sederhana dan perutean yang lebih efisien (dibandingkan dengan IPv4) menghasilkan kinerja jaringan yang lebih baik secara keseluruhan.
- Strategi jangka panjang: Memulai dengan IPv6 memastikan kompatibilitas dan relevansi jangka panjang seiring transisi internet ke protokol ini. Semakin banyak platform yang akan menganggap IPv4 sudah usang, jadi sebaiknya Anda bersiap untuk masa depan.
Jadi, apa yang terbaik untuk melakukan scraping? IPv6 atau IPv4? Pelajari lebih lanjut tentang topik ini di: IPv4 vs IPv6 untuk Scraping
Ingin meningkatkan penggalian dan perayapan web dengan IPv6?
Tingkatkan efisiensi Anda dengan layanan proxy IPv6 yang andal dari RapidSeedbox. Nikmati scraping dan crawling web yang lebih cepat dan lebih aman, didukung oleh kinerja luar biasa dan dukungan yang kuat.
4. Potensi tantangan yang akan ditemui ketika melakukan Web Scraping dan Web Crawling dengan IPv6
a. Adopsi IPv6 Terbatas
Masalahnya:
Terlepas dari kelebihannya, IPv6 belum diadopsi secara besar-besaran. Banyak situs web dan penyedia layanan internet yang masih mengandalkan IPv4, yang dapat membatasi efektivitas scraping berbasis IPv6 dalam skenario tertentu.
Bagaimana cara mengatasinya:
Use dual-stack systems that support both IPv4 dan IPv6. This hybrid approach ensures compatibility with all types of networks and websites. Furthermore, using a layanan proxy yang menawarkan alamat IPv4 dan IPv6 akan menawarkan lebih banyak fleksibilitas.
b. Kompleksitas Teknis
Masalahnya:
The transisi dari IPv4 ke IPv6 secara teknis dapat menjadi tantangan bagi beberapa bisnis. IPv6 memiliki skema pengalamatan yang berbeda dan membutuhkan pembaruan pada infrastruktur jaringan dan perangkat lunak. Hal ini akan membutuhkan lebih banyak biaya dan manajemen jaringan yang memadai.
Bagaimana cara mengatasinya:
Berinvestasilah dalam pelatihan tim untuk memahami IPv6 secara lebih dalam. Selain itu, pilihlah tools dan software web scraping yang dirancang untuk bekerja secara mulus dengan IPv4 dan IPv6. Hal ini akan mengurangi beban teknis dan memastikan operasi yang lebih lancar.
Selain itu, pastikan anggota tim memiliki pengetahuan yang memadai tentang cara mengatasi potensi masalah kompatibilitas IPv6.
c. Masalah Kompatibilitas
Masalahnya:
Sebagian besar sistem lama, peralatan, dan sebagian besar situs web mungkin tidak kompatibel dengan IPv6, yang bisa menghambat upaya scraping yang kamu lakukan. Perlu diingat bahwa sebagian besar situs terkenal umumnya pasti compatible, tetapi jika kamu membutuhkan data dari niche tertentu yang ada ada di web skala kecil, kebanyakan mereka hanya mendukung IPv4 saja.
Bagaimana cara mengatasinya:
Perbarui peralatan dan sistemmu secara bertahap agar kompatibel dengan IPv6. Untuk sementara, gunakan layanan proxy yang dapat menerjemahkan alamat IPv6 kembali ke IPv4 bila perlu, yang akan memastikan akses tanpa gangguan ke semua jenis situs web. Ini akan sangat berguna saat kamu akan meningkatkan skala web scraping yang dilakukan.
d. Manajemen IP Address
Masalahnya:
Meskipun IPv6 menawarkan IP Address yang sangat besar, mengelola alamat-alamat ini untuk web scraping bisa jadi rumit, terutama ketika melakukan scaling.
Bagaimana cara mengatasinya:
Gunakan proxy management tools yang dapat mengotomatiskan alokasi dan rotasi alamat IPv6. Hal ini akan membantu mengelola sejumlah besar IP secara efisien dan mengurangi risiko diblokir oleh situs web target.
Sebagai contoh, RapidSeedbox menawarkan 100 alamat IPv6 yang berbeda pada paket termurahnya.
e. Keamanan
Masalahnya:
With the increased adoption of IPv6, there might be concerns about security and privacy, especially when scraping sensitive data.
Bagaimana cara mengatasinya:
Pastikan bahwa proses scraping mematuhi undang-undang perlindungan data. Gunakan koneksi yang aman dan terenkripsi untuk operasi scraping. Selain itu, pilihlah penyedia proxy yang memprioritaskan keamanan dan privasi. Terakhir, pastikan kamu telah memeriksa aturan situs web yang ditargetkan.
f. Tindakan Deteksi dan Anti-Scraping
Masalahnya:
Situs web semakin banyak menggunakan langkah-langkah anti-pengikisan yang canggih yang dapat mendeteksi dan memblokir aktivitas pengikisan, bahkan dengan menggunakan proxy. Langkah-langkah pencegahan ini telah meningkat sejak dirilisnya ChatGPT.
Bagaimana cara mengatasinya:
Gunakan teknik scraping yang lebih canggih seperti merotasi user agents, memvariasikan interval request, dan menggunakan scraping tools yang lebih canggih yang dapat meniru pola penelusuran manusia.
Selain itu, terapkan praktik scraping yang etis untuk menghormati ketentuan situs web dan mengurangi risiko pemblokiran.
5. Menggunakan IPv6 untuk Scraping Web - Contoh Penggunaan
Using IPv6 proxies for web scraping opens up a range of possibilities due to their unique features. IPv6 enables massive, low-cost IP rotation for large-scale list crawling, reducing blocks and improving scraping success rates.
Here are the most common potential use cases:
a. Pengumpulan data berskala besar
IPv6 proxy memiliki kumpulan IP adress yang sangat besar, sehingga cocok untuk pengumpulan data berskala besar. Ini sangat berguna untuk bisnis dan peneliti yang perlu mengumpulkan kumpulan data yang luas dari berbagai situs web tanpa dibatasi oleh batasan IP.
b. Riset pasar
Perusahaan dan spesialis SEO menggunakan web scraping dengan proksi IPv6 untuk memantau pesaing mereka, melacak peringkat SEO, dan memahami tren pasar. Banyaknya jumlah IP yang tersedia membantu dalam mengumpulkan data secara efisien dari berbagai wilayah dan mesin pencari tanpa memicu tindakan anti-scraping. Sebagian besar alat SEO di pasaran seperti Ahrefs, Semrush, dan lainnya, mengandalkan pengikisan web IPv6 untuk memantau posisi SERP klien mereka.
c. Pemantauan SEO
Dengan IPv6 proxyAnda bisa melacak peringkat dan menjalankan kueri SERP dalam skala besar. Dan proxy IPv6 juga sempurna untuk mengawasi para pesaing tanpa menyalakan alarm. Karena kumpulan alamat hampir tidak terbatas, perputaran IP menjadi mulus. Itu berarti data yang lebih bersih di seluruh wilayah dan perangkat - sempurna untuk audit kata kunci, riset pasar, dan pelacakan SEO berskala besar tanpa menemui hambatan IP.
d. Sepatu kets
Dalam pencurian sepatu, setiap milidetik dan setiap IP sangat berarti. Proksi IPv6 residensial merutekan lalu lintas melalui perangkat asli, membuat Anda terlihat seperti pembeli asli, bukan bot. Hal ini membantu menerobos filter anti-bot dan meningkatkan peluang Anda untuk mendapatkan diskon terbatas. Dipasangkan dengan alat otomatisasi, pengecer dapat meningkatkan skala, memutar ratusan alamat IPv6 residensial, dan meningkatkan peluang mereka untuk mendapatkan lebih banyak pasangan. Pelajari lebih lanjut di: proksi sepatu kets
e. E-commerce dan perbandingan harga
Saya tidak tahu apakah Anda pernah menjual Nike baru-baru ini, tetapi orang-orang benar-benar menghasilkan jutaan dolar dengan menjual sepatu kets. Peritel dan platform e-commerce dapat menggunakan pengikisan web untuk memantau harga pesaing, ketersediaan produk, dan ulasan konsumen. Proksi IPv6 memungkinkan mereka untuk mengikis situs web pesaing secara ekstensif tanpa risiko diblokir, memastikan mereka memiliki data terbaru untuk strategi penetapan harga yang kompetitif.
f. Sosial analisis media
Untuk analisis media sosial, proksi IPv6 memungkinkan untuk mengumpulkan data dalam jumlah besar di seluruh platform. Data ini mendukung analisis sentimen, pelacakan tren, dan wawasan perilaku konsumen. Karena jaringan seperti Facebook, Instagramdan Twitter dengan cepat menandai aktivitas yang tidak biasa, proksi IPv6 residensial sangat berharga. Dengan menyatu sebagai pengguna asli, mereka memungkinkan pemasar, analis, dan peneliti untuk mengumpulkan metrik keterlibatan yang akurat dan tren sosial dalam skala besar tanpa memicu pemblokiran keamanan.
Catatan: Pada sebagian besar kasus, scraping media sosial mungkin dianggap ilegal dan pelanggaran hak cipta di beberapa yurisdiksi, jadi berhati-hatilah terhadap potensi masalah hukum. Pelajari lebih lanjut di dalam: apakah web scraping legal?
g. Penelitian akademis:
Ini adalah kasus penggunaan yang jarang terjadi, tetapi para peneliti dapat mengumpulkan sejumlah besar data dari berbagai sumber online untuk studi mereka. Proksi IPv6 memfasilitasi akses tanpa gangguan dan anonim ke situs web, yang sangat penting untuk mengumpulkan kumpulan data yang tidak bias dan komprehensif.
h. Agregasi konten
Web scraping digunakan oleh agregator berita dan kurator konten untuk mengumpulkan artikel, blog, dan berita dari seluruh web. Proxy IPv6 membantu mengakses beragam sumber tanpa dibatasi oleh batasan berbasis IP.
Namun, jika kamu berencana untuk membangun situs web seperti itu, perlu diingat bahwa situs web tersebut sering dianggap sebagai spam dan dapat mengalami kesulitan untuk mendapatkan peringkat di SERP. Saran saya adalah menggunakan taktik seperti itu hanya untuk berbagi berita.
i. Daftar real estat dan properti
Dengan meledaknya pasar perumahan dalam beberapa tahun terakhir, tidak mengherankan jika menelusuri situs-situs daftar properti memberikan data berharga tentang tren pasar, harga properti, dan ketersediaan.
IPv6 proxy memungkinkan penggalian situs-situs ini dalam skala besar tanpa terdeteksi.
j. Mengikis tarif perjalanan
Agen perjalanan dan situs perbandingan tarif dapat menggunakan web scraping untuk mengumpulkan data tentang harga penerbangan, hotel, dan mobil sewaan. Pasca-Covid, taktik ini menjadi sangat efektif. IPv6 proxy memungkinkan agregator semacam itu untuk mengakses informasi ini dari berbagai penyedia secara bersamaan dan memberikan pengalaman pengguna yang luar biasa.
k. Verifikasi iklan
Saat ini ads sangatlah powerful (dan lebih mahal) dari sebelumnya. Perusahaan harus menggunakan web scraping untuk memverifikasi apakah iklan online mereka ditampilkan sebagaimana mestinya dan memeriksa penipuan iklan. IPv6 proxy memungkinkan mereka untuk memeriksa iklan secara anonim di berbagai wilayah dan platform.
l. Keamanan siber
Dari pengalaman saya sebagai pakar keamanan siber, scraping sering digunakan untuk mengumpulkan data tentang potensi ancaman keamanan, seperti situs web phishing atau aktivitas penipuan. Proxy IPv6 menyediakan anonimitas yang diperlukan untuk operasi sensitif semacam itu dalam skala besar.
| Kesimpulan: Dalam semua kasus yang disebutkan di atas, keuntungan utama menggunakan proxy IPv6 adalah kemampuan untuk melakukan web scraping dalam skala yang jauh lebih besar dan dengan efisiensi yang lebih besar dibandingkan dengan IPv4. Hal ini disebabkan oleh ruang alamat yang jauh lebih besar dan kemungkinan yang lebih rendah untuk menghadapi IP bans atau rate limits. |
PERTANYAAN UMUM: Mengikis dengan Proksi IPv6
Proksi IPv6 bekerja sebagai perantara, menyembunyikan IP asli Anda di balik alamat IPv6. Mereka adalah kunci untuk mengikis karena mereka membantu menghindari pelarangan, lolos dari pembatasan, dan menarik data dalam skala besar. Dengan pasokan alamat IPv6 yang sangat banyak, Anda bisa merotasi IP jauh lebih efisien dibandingkan dengan IPv4.
Ya. Proksi IPv6 perumahan merutekan lalu lintas melalui perangkat nyata dan penyedia internet, bukan pusat data. Hal ini membuat mereka lebih sulit untuk ditandai atau diblokir, yang sangat berguna untuk mengikis media sosial, e-commerce, atau situs sensitif lainnya. Jika Anda membutuhkan keaslian, penyamaran, dan tingkat keberhasilan yang lebih baik, IPv6 residensial adalah pilihan yang tepat.
Opsi gratis terdengar menarik, tetapi sering kali disertai dengan masalah: kecepatan lambat, koneksi tidak stabil, anonimitas yang buruk, dan risiko keamanan. Sebaliknya, proksi berbayar memberikan keandalan, kecepatan, dan dukungan. Jika Anda menjalankan proyek yang serius, gunakan proksi gratis hanya untuk pengujian - bukan penggalian langsung.
Penyiapan terbaik menyeimbangkan kecepatan, keamanan, skalabilitas, dan harga. Pilihlah penyedia dengan kumpulan IP yang besar, opsi untuk proksi bergilir dan statis, dukungan 24/7, dan harga yang jelas. Untuk kasus penggunaan tingkat lanjut - pelacakan SEO, verifikasi iklan, sneaker copping - pilihan utama sering kali merupakan gabungan dari proxy IPv6 perumahan dan pusat data.
Ya. Sebagian besar alat pengikis dan API - seperti Scrapy, Puppeteer, atau Selenium - mendukung proksi IPv6. Menggunakannya membantu menyebarkan permintaan, mengurangi batas kecepatan, dan memperlancar ekstraksi data. Ini sangat berguna ketika API membatasi atau memblokir lalu lintas IPv4.
6. Kesimpulan
Web scraping dan web crawling dengan IPv6 merupakan sebuah kemajuan dalam ekstraksi data.
Jika kamu berhasil memahami dan memanfaatkan teknologi ini, kamu atau bisnismu dapat mengumpulkan data yang jauh lebih efisien, aman, dan hemat biaya.
The transisi ke IPv6 bukan hanya sekedar peningkatan teknis, tetapi juga membutuhkan rencana strategis yang bertujuan untuk mencapai tujuan tertentu.
Ingin meningkatkan penggalian dan perayapan web dengan IPv6?
Tingkatkan efisiensi Anda dengan layanan proxy IPv6 yang andal dari RapidSeedbox. Nikmati scraping dan crawling web yang lebih cepat dan lebih aman, didukung oleh kinerja luar biasa dan dukungan yang kuat.
Disclaimer: Materi ini dikembangkan secara khusus untuk tujuan informasional semata. Panduan ini tidak menyiratkan dukungan terhadap aktivitas (termasuk aktivitas ilegal), produk, atau layanan apapun. Kamu sepenuhnya bertanggung jawab untuk mematuhi hukum yang berlaku, termasuk hukum kekayaan intelektual saat menggunakan layanan kami atau mengandalkan informasi di sini. Kami tidak menerima tanggung jawab atas kerusakan yang timbul dari penggunaan layanan kami atau informasi yang terkandung di sini dengan cara apapun, kecuali jika secara tegas diwajibkan oleh hukum.
0Komentar