Aujourd'hui, le web scraping et le crawling sont indispensables à l'extraction et à l'analyse des données. L'IPv6, la dernière version du protocole Internet, a révolutionné ces processus.
C'est pourquoi je vais vous montrer comment utiliser IPv6 pour le scraping et le crawling. Vous verrez comment cela se fait, quels sont les avantages, quels sont les défis auxquels vous pourriez être confronté et, surtout, comment les relever.

Table des matières
- TL:DR Web Scraping et Web Crawling
- Web Scraping et Crawling avec IPv6 - Comment faire ?
- Avantages de l'utilisation d'IPv6 pour le scraping et le crawling sur le web
- Difficultés potentielles liées à l'utilisation d'IPv6 pour la recherche et l'exploration de sites web
- Utilisation d'IPv6 pour l'exploration du Web - Cas d'utilisation
- Conclusion
1. TL:DR Web Scraping et Web Crawling
Récupération de données sur Internet se réfère au processus d'extraction de données à partir de sites web, tandis que le web crawling parcourt régulièrement le web à la recherche d'informations nouvellement indexées.
2. Web Scraping et Crawling avec IPv6 - Comment faire ?
Pour un scraping web efficace, l'utilisation de proxys IPv6 est crucial. Ils permettent de contourner les restrictions basées sur l'IP et de préserver l'anonymat, ce qui est essentiel pour le scraping.
a. Conditions préalables
Avant de commencer, assurez-vous que vos outils de scraping sont compatibles avec IPv6. Cette compatibilité est essentielle pour une extraction transparente des données.
Répartissez votre budget d'exploration :
L'utilisation d'un variété d'adresses IPv6 réduira considérablement les blocages éventuels imposés par les sites web ciblés.
b. Mise en place
- Choisir un outil de scraping web adapté: Sélectionnez un outil ou un logiciel compatible avec IPv6. Parmi les options les plus populaires, on trouve les bibliothèques Python telles que Ferraille et BeautifulSoup.
- Compatibilité IPv6: Assurez-vous que votre connexion internet est prête pour l'IPv6. Contactez votre fournisseur d'accès à Internet si vous n'êtes pas sûr de votre connectivité IPv6.
c. Obtenir des proxys IPv6
Les proxys masquent votre adresse IP, ce qui vous permet de contourner les restrictions imposées par les sites web et d'éviter les interdictions. proxys IPv6 offrent un large éventail d'adresses IP, ce qui les rend idéales pour le scraping.
- Sélectionner un fournisseur de proxy: Choisissez un fournisseur qui propose des proxys IPv6 fiables. Tenez compte de facteurs tels que le coût, la vitesse et l'anonymat. Les serveurs mandataires peuvent être HTTP ou SOCKS5..
- Configurez votre proxy: Configurez le proxy dans votre outil de scraping. Il s'agit généralement de saisir l'adresse et le port du proxy dans les paramètres de votre outil. Cependant, ces étapes ne sont que les bases, requises pour la plupart des outils. Vous devriez consulter la documentation de votre outil ou votre fournisseur de proxy pour les intégrer de manière transparente.
d. Préparez votre script de scraping
- Codage de base: Écrire un script qui envoie des requêtes au site web cible et analyse le code HTML retourné pour en extraire des données. Si vous utilisez Python, vous pouvez consulter la page suivante guide pour la création de scripts de scraping et d'analyse de texte.
- JavaScript manipulation: Pour les sites à forte composante JavaScript, envisagez d'utiliser des outils tels que Sélénium ou Marionnettistequi peut interpréter JavaScript comme un navigateur.
e. Faites fonctionner votre grattoir
- Commencez par des essais: Au début, lancez des tests à petite échelle pour vous assurer que votre scraper fonctionne comme prévu. Surveillez les performances et, si nécessaire, adaptez votre script.
- Respecter les règles du site: Cela va sans dire, mais il faut toujours vérifier les conditions d'utilisation du site.
robots.txtet de suivre ses lignes directrices afin d'éviter d'éventuels problèmes juridiques.
f. Gérer les données acquises
- Stockage des données: Décidez de la manière dont vous stockerez les données extraites. Dans la plupart des cas, vous avez le choix entre des bases de données, des fichiers CSV ou JSON.
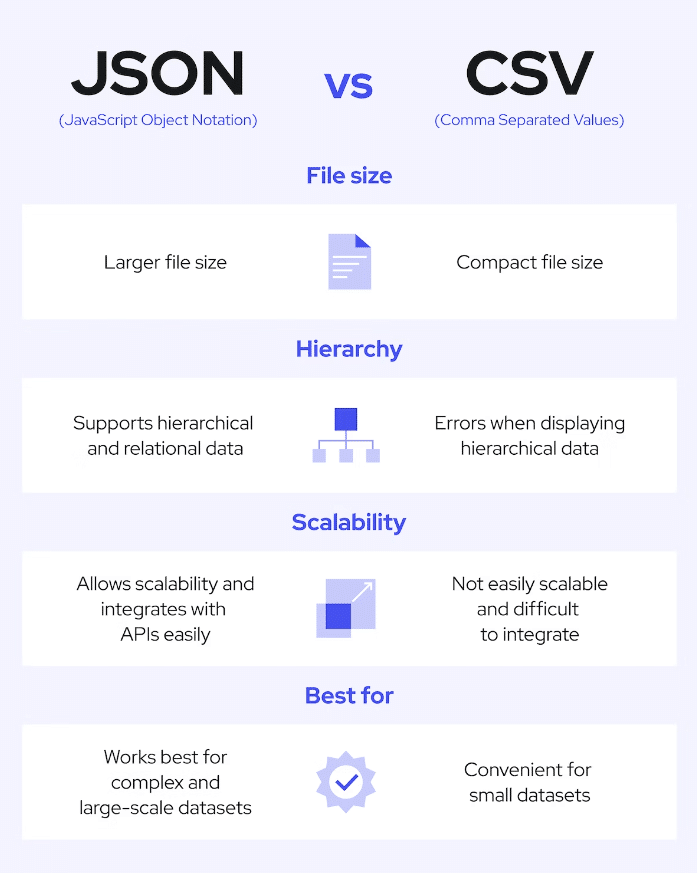
Crédit d'image : Coresignal
- Se préparer à relever des défis: En théorie, tout peut être parfait, mais le web scraping dans le monde réel comporte des défis. Cela dit, il faut être prêt à relever les défis les plus courants, tels que les CAPTCHA et les interdictions d'IP. L'utilisation d'un pool tournant de serveurs mandataires IPv6 peut aider à résoudre ces problèmes potentiels.
g. Le changement d'échelle est inévitable
- Être prêt à passer à l'échelle: Au fur et à mesure que vous vous sentez plus à l'aise, vous pouvez faire évoluer vos opérations de scraping. D'après mon expérience, c'est toujours l'affaire. La mise à l'échelle implique l'utilisation d'un plus grand nombre de proxys et l'exécution simultanée de plusieurs scrapers. Si vous ne disposez pas du budget nécessaire, réfléchissez bien à votre stratégie.
- Entretien: Ce point est crucial dans le monde en constante évolution du web. Mettez régulièrement à jour et entretenez vos scripts de scraping, d'autant plus que les sites web changent souvent de présentation et de structure.
3. Avantages de l'utilisation d'IPv6 pour le scraping et le crawling sur le web
Compte tenu du nombre de facteurs pouvant influencer votre stratégie et de l'incertitude, vous vous demandez peut-être pourquoi l'IPv6 est une bonne idée.
Il s'agit d'une question logique, étant donné que l'IPv4 éliminera au moins un problème potentiel. la compatibilité. En effet, moins de 40% de tous les sites web ne prennent pas en charge l'IPv6.
IPv4 vs IPv6 Comparison Table
| Fonctionnalité | IPv4 Proxies | Proxy IPv6 |
|---|---|---|
| Address Pool | ~4.3 billion addresses (exhausted) | Virtually unlimited (3.4×10³⁸) |
| Coût | Expensive, scarce | More affordable, abundant |
| Compatibilité | Supported everywhere | ~60% of sites currently support |
| La performance | Older protocol, slower routing | Simpler headers, faster routing |
| Meilleur cas d'utilisation | Legacy systems, universal access | Large-scale scraping, future-proof |
Néanmoins, l'IPv6 offre plusieurs avantages que vous ne pouvez pas ignorer.
- Amélioration de l'anonymat et de la sécurité: IPv6 prend en charge IPsec, qui offre des connexions cryptées et sécurisées. Ceci est crucial pour la protection de la vie privée lors du scraping de sites web.
- Abordabilité: Étonnamment, les adresses IPv6 sont moins chères que les adresses IPv4. Cela permettra de réduire les coûts opérationnels.
- De meilleures performances: Le format d'en-tête plus simple d'IPv6 et le routage plus efficace (par rapport à IPv4) permettent d'améliorer les performances globales du réseau.
- Stratégie à long terme: Commencer avec IPv6 garantit une compatibilité et une pertinence à long terme au fur et à mesure que l'internet passe à ce protocole. De plus en plus de plateformes trouveront IPv4 obsolète, il vaut donc mieux se préparer pour l'avenir.
So what is best for scraping? IPv6 or IPv4? Learn more about this topic in: IPv4 vs. IPv6 pour le scraping
Vous souhaitez améliorer le scraping et le crawling sur le web avec IPv6 ?
Augmentez votre efficacité avec les services de proxy IPv6 fiables de RapidSeedbox. Profitez d'un scraping et d'un crawling plus rapides et plus sûrs, soutenus par des performances exceptionnelles et un support solide.
4. Difficultés potentielles liées à l'utilisation d'IPv6 pour la recherche et l'exploration de sites web
a. Adoption limitée d'IPv6
Le problème :
Malgré ses avantages, L'IPv6 n'est pas encore adopté massivement. De nombreux sites web et fournisseurs de services internet utilisent encore le protocole IPv4, ce qui peut limiter l'efficacité du scraping basé sur le protocole IPv6 dans certains scénarios.
Comment y remédier ?
Use dual-stack systems that support both IPv4 et IPv6. This hybrid approach ensures compatibility with all types of networks and websites. Furthermore, using a service proxy qui offre des adresses IPv4 et IPv6 offrira une plus grande flexibilité.
b. Complexité technique
Le problème :
Le passage de l'IPv4 à l'IPv6 peut représenter un défi technique pour certaines entreprises. L'IPv6 a un schéma d'adressage différent et nécessite des mises à jour de l'infrastructure du réseau et des logiciels. Cela nécessitera davantage de dépenses et une gestion adéquate du réseau.
Comment y remédier ?
Investissez dans la formation de votre équipe pour qu'elle comprenne l'IPv6. En outre, choisissez des outils et des logiciels de web scraping conçus pour fonctionner de manière transparente avec IPv4 et IPv6. Cela réduit la charge technique et garantit des opérations plus fluides.
En outre, assurez-vous que votre équipe dispose des connaissances nécessaires pour résoudre les problèmes potentiels liés à la compatibilité avec l'IPv6.
c. Questions de compatibilité
Le problème :
La plupart des anciens systèmes et outils, ainsi que la majorité des sites web, peuvent ne pas être compatibles avec l'IPv6, ce qui peut entraver vos efforts de scraping. Gardez à l'esprit que la plupart des sites connus le supportent, mais si vous avez besoin d'une connaissance spécifique d'une niche, la plupart des petits sites web ne supportent que l'IPv4.
Comment y remédier ?
Mettez progressivement à jour vos outils et systèmes pour qu'ils soient compatibles avec l'IPv6. Dans l'intervalle, utilisez un service proxy capable de retranscrire les adresses IPv6 en IPv4 si nécessaire, ce qui garantira un accès ininterrompu à tous les types de sites web. Cela s'avérera extrêmement utile lors de la mise à l'échelle.
d. Gestion des adresses IP
Le problème :
Bien que l'IPv6 offre une réserve massive d'adresses IP, la gestion de ces adresses pour le web scraping peut s'avérer compliquée, en particulier lors de l'extension des opérations.
Comment y remédier ?
Utilisez des outils de gestion de proxy avancés qui peuvent automatiser l'attribution et la rotation des adresses IPv6. Cela permet de gérer efficacement un grand nombre d'adresses IP et de réduire le risque d'être bloqué par les sites web cibles.
Par exemple, RapidSeedbox offre 100 adresses IPv6 différentes sur son plan le moins cher.
e. Sécurité
Le problème :
With the increased adoption of IPv6, there might be concerns about security and privacy, especially when scraping sensitive data.
Comment y remédier ?
Assurez-vous que vos opérations de scraping sont conformes aux lois sur la protection des données. Utilisez des connexions sécurisées et cryptées pour vos opérations de scraping. En outre, choisissez des fournisseurs de proxy qui accordent la priorité à la sécurité et à la protection de la vie privée. Enfin, assurez-vous d'avoir vérifié les règles des sites web ciblés.
f. Mesures de détection et de lutte contre le pillage
Le problème :
Les sites web utilisent de plus en plus des mesures anti-scraping sophistiquées qui peuvent détecter et bloquer les activités de scraping, même avec l'utilisation de proxys. Ces mesures de prévention se sont multipliées depuis la publication de ChatGPT.
Comment y remédier ?
Utiliser des techniques de scraping plus sophistiquées telles que la rotation des agents utilisateurs, la variation des intervalles de requête et l'utilisation d'outils de scraping plus avancés capables d'imiter les schémas de navigation humains.
En outre, appliquez des pratiques de scraping éthiques afin de respecter les conditions du site web et de réduire le risque d'être bloqué.
5. Utilisation d'IPv6 pour l'exploration du Web - Cas d'utilisation
Using IPv6 proxies for web scraping opens up a range of possibilities due to their unique features. IPv6 enables massive, low-cost IP rotation for large-scale list crawling, reducing blocks and improving scraping success rates.
Here are the most common potential use cases:
a. Collecte de données à grande échelle
Les proxys IPv6 disposent d'une réserve massive d'adresses IP, ce qui les rend idéaux pour la collecte de données à grande échelle. Cela est particulièrement utile pour les entreprises et les chercheurs qui ont besoin de collecter des ensembles de données étendus à partir de différents sites web sans être limités par des restrictions d'IP.
b. Market research
Companies and SEO specialists use web scraping with IPv6 proxies to monitor their competitors, track SEO rankings, and understand market trends. The large number of available IPs helps in efficiently gathering data from different regions and search engines without triggering anti-scraping measures. Most SEO tools on the market like Ahrefs, Semrush, and others, rely on IPv6 web scraping to monitor their clients’ SERP positions.
c. SEO Monitoring
Avec proxys IPv6, you can track rankings and run SERP queries at scale. And IPv6 proxy is also perfect for keeping an eye on competitors without setting off alarms. Because the address pool is virtually unlimited, rotating IPs becomes seamless. That means cleaner data across regions and devices — perfect for keyword audits, market research, and large-scale SEO tracking without hitting IP roadblocks.
d. Sneaker Copping
In sneaker copping, every millisecond and every IP counts. Residential IPv6 proxies route traffic through real devices, making you look like a genuine shopper instead of a bot. That helps bypass anti-bot filters and increases your odds of grabbing limited drops. Paired with automation tools, resellers can scale up, rotate through hundreds of residential IPv6 addresses, and boost their chances of landing more pairs. Learn more in: sneaker proxies
e. E-commerce and price comparison
I don’t know if you’ve sold Nike’s recently, but people are literally making millions of dollars selling sneakers. Retailers and e-commerce platforms can use web scraping to monitor competitor pricing, product availability, and consumer reviews. IPv6 proxies enable them to scrape competitor websites extensively without the risk of being blocked, ensuring they have the latest data for competitive pricing strategies.
f. Social media analysis
For social media analytics, IPv6 proxies make it possible to collect large volumes of data across platforms. This data powers sentiment analysis, trend tracking, and consumer behavior insights. Because networks like Facebook, Instagram, and Twitter are quick to flag unusual activity, residential IPv6 proxies are especially valuable. By blending in as real users, they allow marketers, analysts, and researchers to gather accurate engagement metrics and social trends at scale without triggering security blocks.
Note : Dans la majorité des cas, le scraping des médias sociaux peut être considérée comme illégale et une violation des droits d'auteur dans certaines juridictions, il convient donc d'être attentif aux problèmes juridiques potentiels. En savoir plus : is web scraping legal?
g. Academic research:
This is a rare use case, but researchers can gather vast amounts of data from various online sources for their studies. IPv6 proxies facilitate uninterrupted and anonymous access to websites, which is crucial for collecting unbiased and comprehensive data sets.
h. Content aggregation
Le web scraping est utilisé par les agrégateurs d'actualités et les conservateurs de contenu pour rassembler des articles, des billets de blog et des nouvelles provenant de l'ensemble du web. Les proxys IPv6 permettent d'accéder à diverses sources sans être limité par des restrictions basées sur l'IP.
Toutefois, si vous envisagez de créer un tel site, gardez à l'esprit que ces sites sont souvent considérés comme du spam et qu'ils peuvent avoir du mal à se classer dans les SERP. Je vous conseille de n'utiliser ce type de tactique que pour partager des informations.
i. Real estate and property listings
Avec le boom du marché immobilier de ces dernières années, il n'est pas surprenant que l'exploration des sites d'annonces immobilières fournisse des données précieuses sur les tendances du marché, les prix des biens immobiliers et leur disponibilité.
Les proxys IPv6 permettent de gratter ces sites à grande échelle sans être détectés.
j. Scraping travel fares
Les agences de voyage et les sites de comparaison de tarifs peuvent utiliser le web scraping pour collecter des données sur les prix des vols, des hôtels et des voitures de location. Après l'affaire Covid, cette tactique est devenue extrêmement efficace. Les proxys IPv6 permettent à ces agrégateurs d'accéder simultanément à ces informations provenant de différents fournisseurs et d'offrir une excellente expérience à l'utilisateur.
k. Ad verification
Les publicités sont plus puissantes (et plus chères) que jamais, et les entreprises devraient utiliser le web scraping pour vérifier si leurs publicités en ligne s'affichent comme prévu et pour détecter les fraudes publicitaires. Les proxys IPv6 leur permettent de vérifier anonymement les publicités dans différentes régions et sur différentes plateformes.
l. Cybersecurity
D'après mon expérience en tant qu'expert en cybersécurité, le scraping est souvent utilisé pour recueillir des données sur des menaces potentielles pour la sécurité, telles que des sites de phishing ou des activités frauduleuses. Les proxys IPv6 offrent l'anonymat nécessaire à ces opérations sensibles à grande échelle.
| Verdict final: In all of the above-mentioned cases, the key advantage of using IPv6 proxies is the ability to perform web scraping on a much larger scale and with greater efficiency compared to IPv4. Cela est dû à l'espace d'adressage beaucoup plus grand et à la probabilité plus faible de rencontrer des interdictions d'IP ou des limites de débit. |
FAQ: Scraping with IPv6 Proxies
IPv6 proxies work as middlemen, hiding your real IP behind an IPv6 address. They’re key for scraping because they help dodge bans, slip past restrictions, and pull data at scale. With the massive supply of IPv6 addresses, you can rotate IPs far more efficiently than with IPv4.
Yes. Residential IPv6 proxies route traffic through real devices and internet providers instead of data centers. That makes them tougher to flag or block, which is especially useful for scraping social media, e-commerce, or other sensitive sites. If you need authenticity, stealth, and better success rates, residential IPv6 is the way to go.
Free options sound appealing, but they often come with headaches: slow speeds, unstable connections, poor anonymity, and security risks. Paid proxies, on the other hand, deliver reliability, speed, and support. If you’re running a serious project, use free proxies only for testing — not live scraping.
The best setups balance speed, security, scalability, and price. Go for providers with big IP pools, options for both rotating and static proxies, 24/7 support, and clear pricing. For advanced use cases — SEO tracking, ad verification, sneaker copping — the top choice is often a mix of residential and data center IPv6 proxies.
Yes. Most scraping tools and APIs — like Scrapy, Puppeteer, or Selenium — support IPv6 proxies. Using them helps spread out requests, cut down on rate limits, and smooth out data extraction. This is especially useful when an API limits or blocks IPv4 traffic.
6. Le mot de la fin
Le scraping et le crawling avec IPv6 représentent une avancée significative dans l'extraction de données.
Si vous parvenez à comprendre et à tirer parti de cette technologie, vous ou votre entreprise pouvez obtenir une collecte de données beaucoup plus efficace, sûre et rentable.
Le passage à l'IPv6 n'est pas seulement une mise à jour technique, elle nécessite également un plan stratégique visant à atteindre un certain objectif.
Vous souhaitez améliorer le scraping et le crawling sur le web avec IPv6 ?
Augmentez votre efficacité avec les services de proxy IPv6 fiables de RapidSeedbox. Profitez d'un scraping et d'un crawling plus rapides et plus sûrs, soutenus par des performances exceptionnelles et un support solide.
Clause de non-responsabilité : Ce document a été élaboré strictement à des fins d'information. Il ne constitue pas une approbation d'activités (y compris les activités illégales), de produits ou de services. Vous êtes seul responsable du respect des lois applicables, y compris les lois sur la propriété intellectuelle, lorsque vous utilisez nos services ou que vous vous fiez à toute information contenue dans le présent document. Nous n'acceptons aucune responsabilité pour les dommages résultant de l'utilisation de nos services ou des informations qu'ils contiennent, de quelque manière que ce soit, sauf lorsque la loi l'exige explicitement.
0Commentaires