In this ultimate guide, we will explore the world of web scraping, a powerful technique to extract data from websites. rat
このガイドブックには、HTMLの概念に興味がある初心者から、スキルアップを目指す経験豊富なプログラマーまで、誰にとっても有益な情報が掲載されています。CSSを使ったHTMLデータ抽出の基本を理解することから XPath セレクタからPythonを使った実践的なWebスクレイピングまで。さらに、法的側面、倫理的考察、責任あるウェブスクレイピングを保証するためのベストプラクティスも取り上げます。

免責事項: 本資料は、情報提供のみを目的として作成されたものです。いかなる活動(違法行為を含む)、製品、サービスを推奨するものではありません。当社のサービスを利用する場合、またはここに記載されている情報に依拠する場合は、知的財産権法を含む適用法を遵守する責任を負うものとします。当社は、法律で明示的に義務付けられている場合を除き、いかなる方法であれ、当社のサービスまたはここに含まれる情報の使用から生じる損害について一切の責任を負いません。
目次
- ウェブスクレイピングとは何か?
- HTMLデータ抽出の基礎CSSセレクタとXPathセレクタ
- PythonによるWebスクレイピング(+コード)。
- ウェブ・スクレイピングは合法か?
- ウェブサイトはどのようにしてウェブ・スクレイピングをブロックしようとしているのか?
- ウェブスクレイピングの倫理とベストプラクティス。
- ウェブスクレイピングよくある質問(FAQ)
- まとめ
1.ウェブ・スクレイピングとは何か?
ウェブスクレイピング(ウェブハーベスティング、データ抽出とも呼ばれる)とは、ウェブサイト、ウェブサービス、ウェブアプリケーションからデータを自動的に抽出するプロセスのことである。
Webスクレイピングは、各Webサイトに入って手動でデータを取得する手間を省くのに役立つ。このプロセスでは、自動化されたスクリプトやプログラムを使用します。スクリプトやプログラムは、ウェブページのHTML構造にアクセスし、データを解析し、さらに分析するためにページの特定の必要な要素を抽出します。
a.ウェブ・スクレイピングは何に使われるのか?
ウェブのスクレイピングは、責任を持って行えば素晴らしいものだ。一般的には、洞察力を得たり、特定の市場の動向を知るなど、市場調査に利用できる。また、競合他社の戦略や価格などを把握するためのモニタリングにも人気がある。
より具体的な使用例は以下の通り:
- ソーシャル・プラットフォームフェイスブックとツイッターのスクレイピング)
- オンライン価格変更監視
- 製品レビュー
- SEOキャンペーン、
- 不動産リスト
- 気象データを追跡する、
- ウェブサイトの評判を追跡する、
- フライトの空席状況と価格を監視する、
- 地域を問わず、広告をテストする、
- 財源を監視する、
b.ウェブ・スクレイピングはどのように機能するのか?
ウェブスクレイピングに関わる典型的な要素は、イニシエーターとターゲットである。イニシエーター(ウェブスクレイパー)は、自動データ抽出ソフトウェアを使用してウェブサイトをスクレイピングします。一方、ターゲットは、一般的にウェブサイトのコンテンツ、連絡先情報、フォーム、またはウェブ上で一般に公開されているものです。
典型的なプロセスは以下の通りである:
- ステップ1: イニシエータは、スクレイピングツール(クラウドベースのサービスでも自作のスクリプトでもよい)を使用して、HTTPリクエスト(ウェブサイトとやりとりしてデータを取得するために使用される)の生成を開始する。このソフトウェアは、HTTP GET、POST、PUT、DELETE、HEADから、ターゲットウェブサイトへのOPTIONSリクエストまで、あらゆるリクエストを開始することができる。
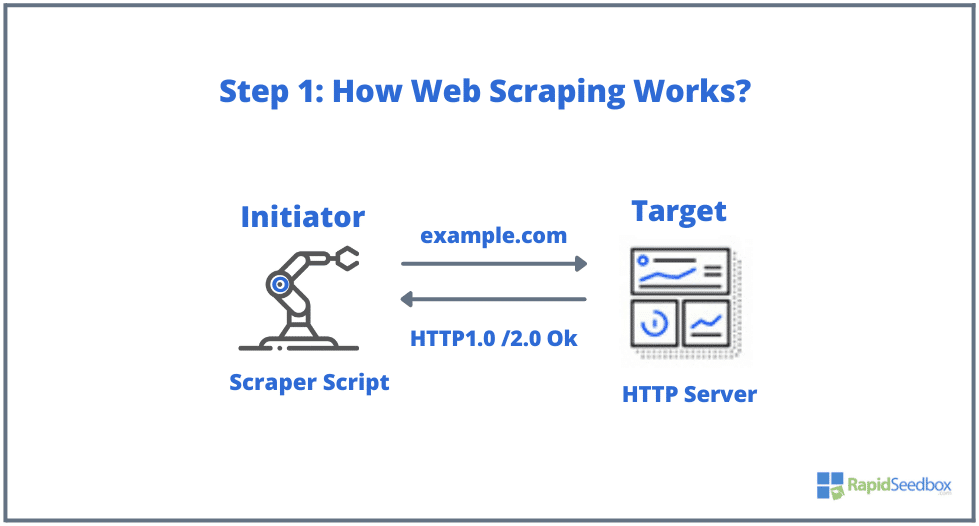
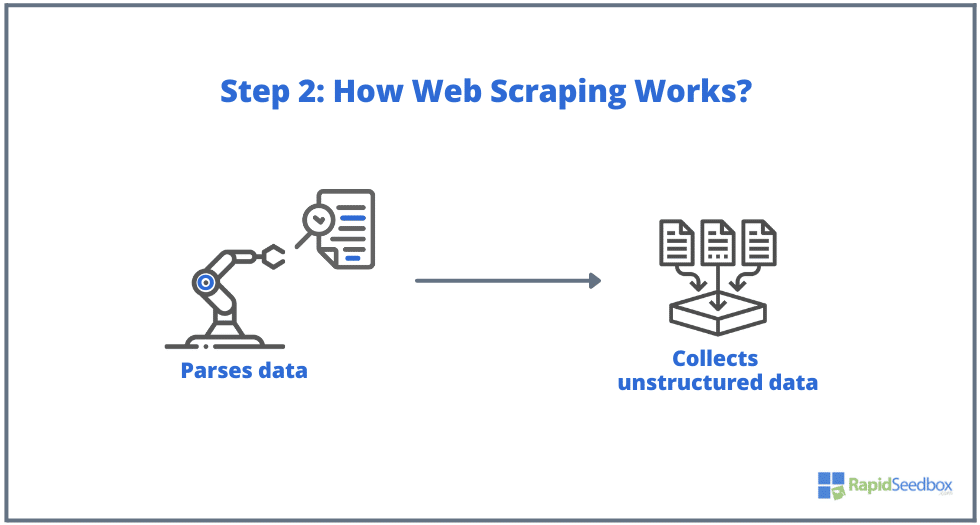
- ステップ2. ページが存在する場合、ターゲットのウェブサイトはスクレーパーのリクエストに対してHTTP/1.0 200 OK(訪問者に対する典型的なレスポンス)で応答する。スクレーパーはHTMLレスポンス(例えば200 OK)を受け取ると、ドキュメントの解析を進め、非構造化データを収集する。
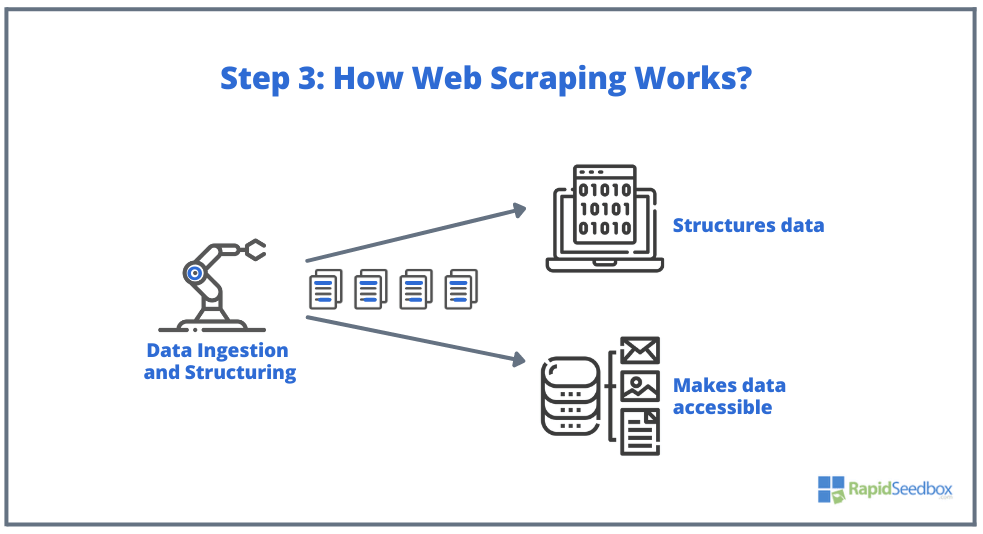
- ステップ3.スクレイパー・ソフトウェアは、生データを抽出し、それを保存し、イニシエータによって指定されたものであれば何でも、データに構造(インデックス)を追加する。構造化されたデータは、XLS、CSV、SQL、XMLのような読み取り可能なフォーマットでアクセスできる。
2.HTMLデータ抽出の基礎CSSセレクタとXPathセレクタ
基本的なことはすでにご存知かもしれない: ウェブスクレイピングは、ウェブサイトからデータを抽出することであり、すべてはHTMLから始まる。ウェブページの骨格となるものです。HTMLファイル内には、クラスやID、テーブル、リスト、ブロック、コンテナなど、ページの構造を構成する基本的な要素があります。
一方CSSは、HTML文書の表示やレイアウトを制御するために使用されるスタイルシート言語です。色、フォント、余白、配置など、HTML要素がウェブページ上でどのように表示されるかを定義します。CSSはウェブスクレイピングにおいて重要な役割を果たし、目的の要素からデータを抽出するのに役立ちます。
注意: HTMLとCSSとは何か、そしてそれらがどのように機能するのかを詳しく説明することは、この記事の範囲外である。HTMLとCSSの基本的なスキルはすでに持っているものとします。
正規表現のような様々なテクニックを使って生のHTMLから直接データを抽出することは可能だが、それは本当に時間がかかり、困難なことである。HTMLの構造化言語は "機械が読める "ように設計されているため、本当に複雑で多様になる可能性がある。 そこで重要な役割を果たすのが、CSSとXPathセレクタだ。
a.HTMLのコンパイルと検査。
次のセクションでは、いくつかの CSS と XPath セレクタの例(コンパイルと検査)を提供します。以下の HTML と CSS の例はすべて、オンラインエディターでコンパイルされています。 HTML-CSS-JS.
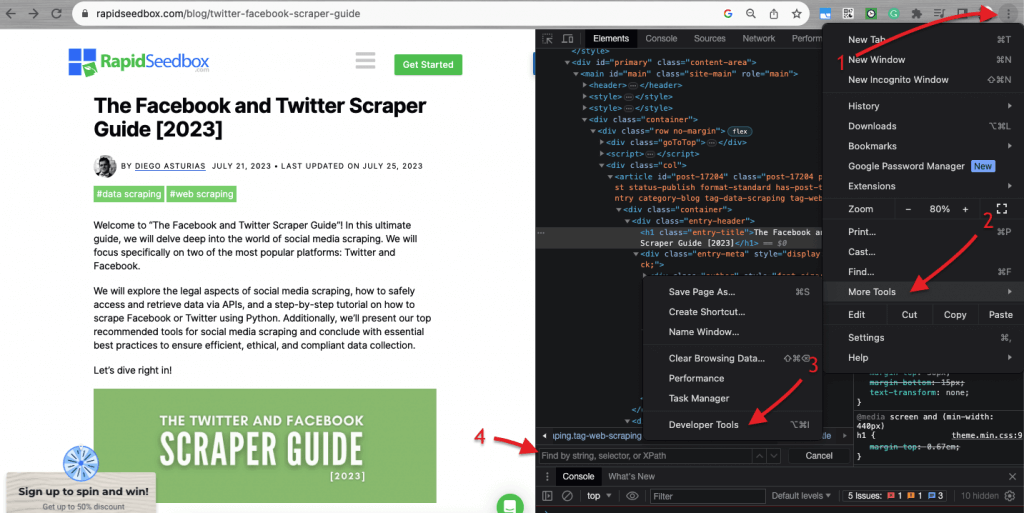
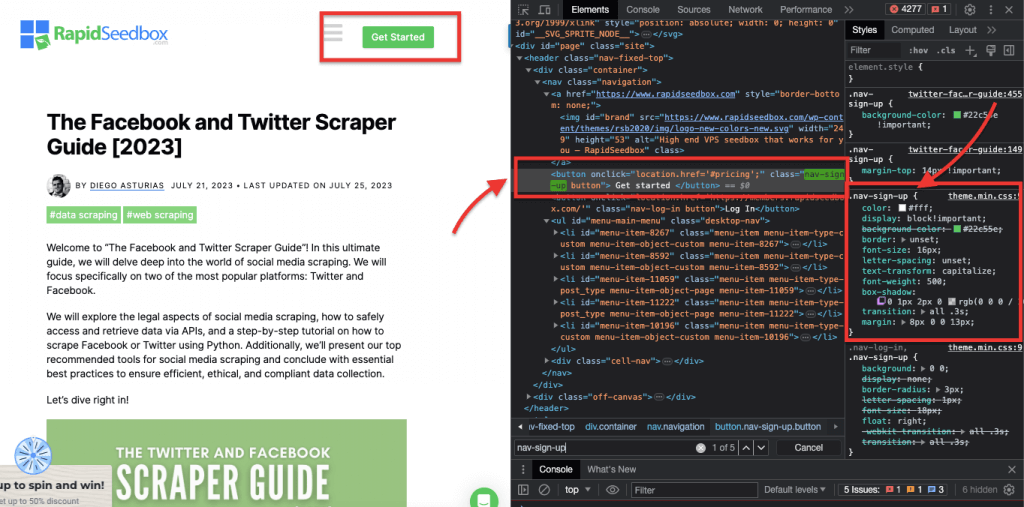
ウェブサイトのHTMLコードを検査する場合、 ウェブ・ブラウザにはデベロッパー・ツールが付属しているので、文字通り、どのウェブサイトでも公開されているHTMLやCSSを検査することができる。ウェブページ上で右クリックし、"Inspect"、"Inspect Element"、または "Inspect Source "を選択できます。ページとコードを並べてダイナミックに比較するには、Chromeブラウザー>左上の3つの点(1)>その他のツール(2)>デベロッパーツール(3)。
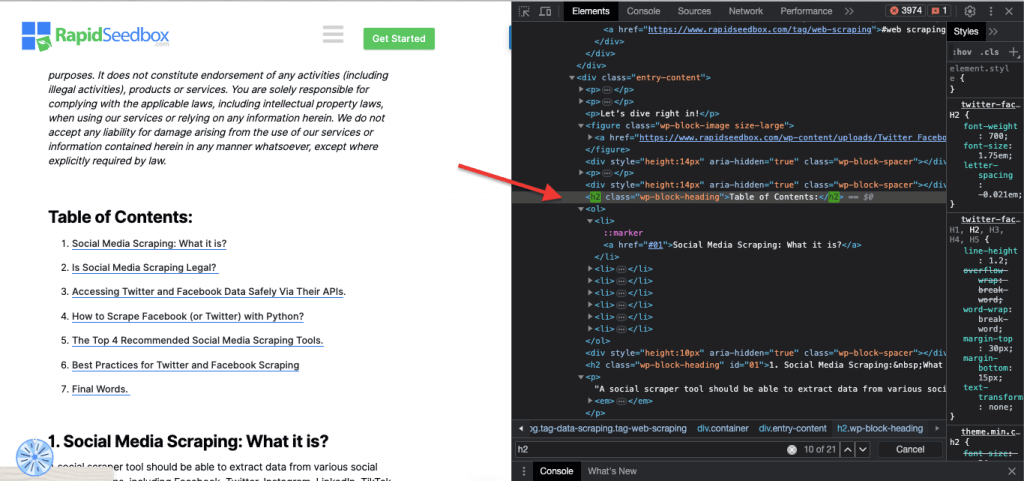
デベロッパー・ツールには、文字列、セレクタ、XPathで検索できる便利な検索フィルタ(4)が付属している。例として、https://www.rapidseedbox.com/blog/twitter-facebook-scraper-guide。
b.CSSセレクタ:
CSSセレクタは、ウェブページのHTML要素を選択し、ターゲットとするために使用されるパターンです。CSSセレクタは、HTML文書からデータを取得するための、より効率的で的を絞った方法を提供するため、ウェブスクレイピング(およびスタイリング)に役立ちます。正規表現のようなさまざまなテクニックを使って生の HTML から直接データを抽出することも可能ですが、CSS セレクタにはウェブスクレイピングに適したいくつかの利点があります。
ウェブページ内のHTML要素をターゲットとし、選択するテクニック:
i.ノードの選択。
ノード選択とは、ノード名に基づいてHTML要素を選択するプロセスです。例えば、ページ上のすべての'p'要素やすべての'a'要素を選択します。このテクニックを使えば、HTML文書内の特定のタイプの要素をターゲットにすることができます。

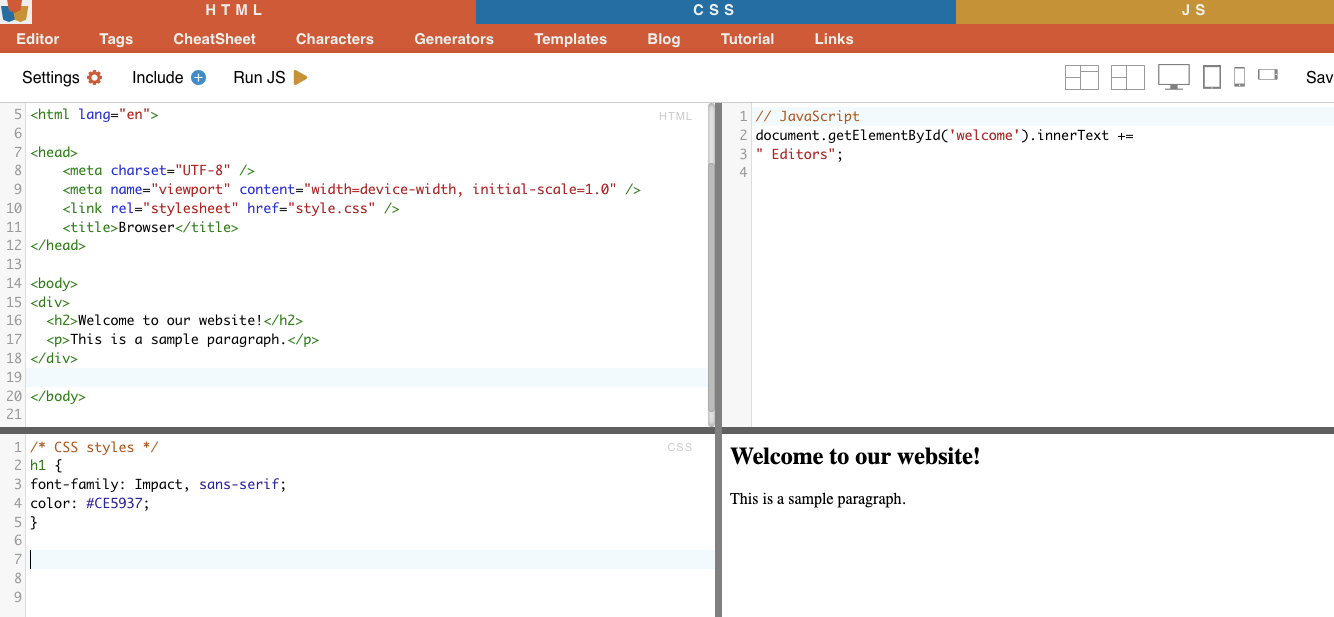
実例: 手動でH2を探す。
ii.クラス。
CSSセレクタのクラス選択では、割り当てられたclass属性に基づいてHTML要素を選択します。class属性は、1つまたは複数の要素に特定のクラス名を適用することができます。さらにCSSスタイルやJavaScriptでは、そのクラスを持つすべての要素に適用することができます。class」名の例としては、ボタン、フォーム要素、ナビゲーション・メニュー、グリッド・レイアウトなどがあります。
例 次のCSSセレクタ: 'highlight' は、class属性が "highlight "に設定されているすべての要素を選択します。


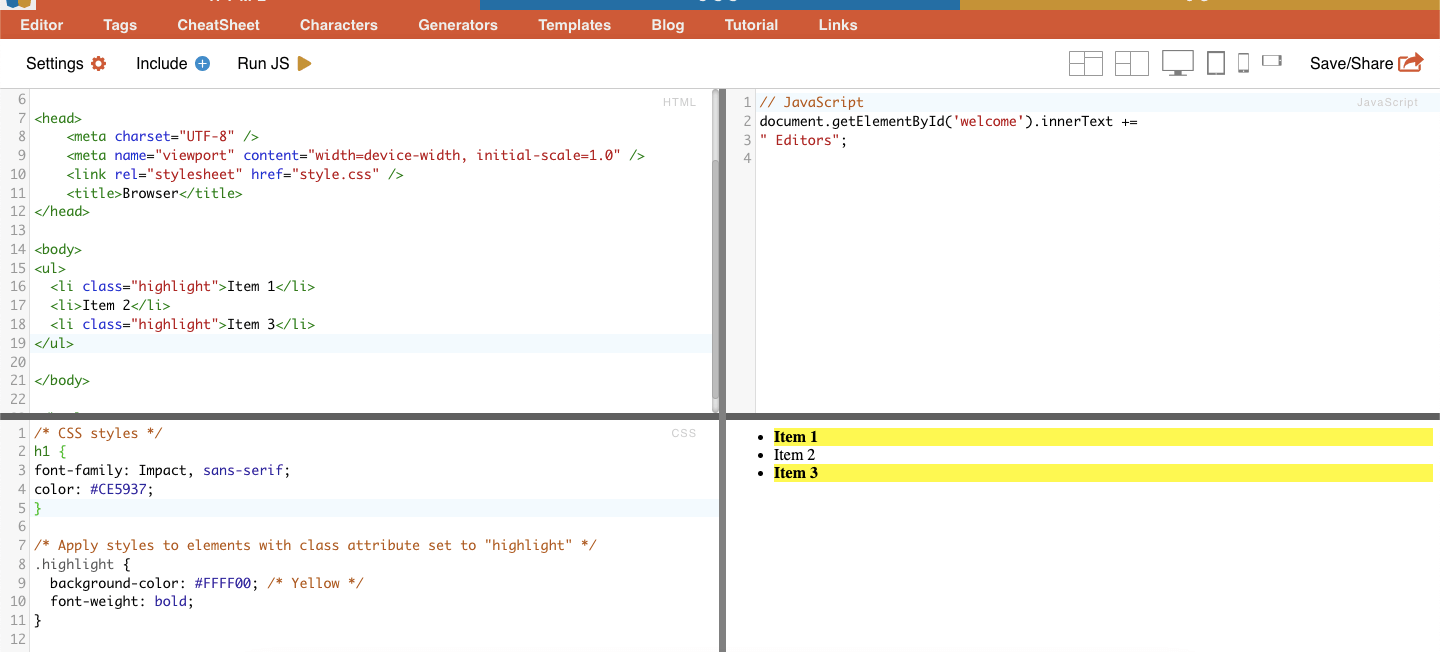
実例: 手動でクラスを検索
iii.IDの制約。
ID制約は、固有のID属性に基づいてHTML要素を選択するのに役立ちます。このID属性は、ウェブ・ページ上の一つの要素を一意に識別するのに使われます。複数の要素で使えるクラスとは違い、IDはページ内で一意でなければなりません。
例 CSSセレクタ「#header」は、ID属性が「header」に設定された要素を選択します。


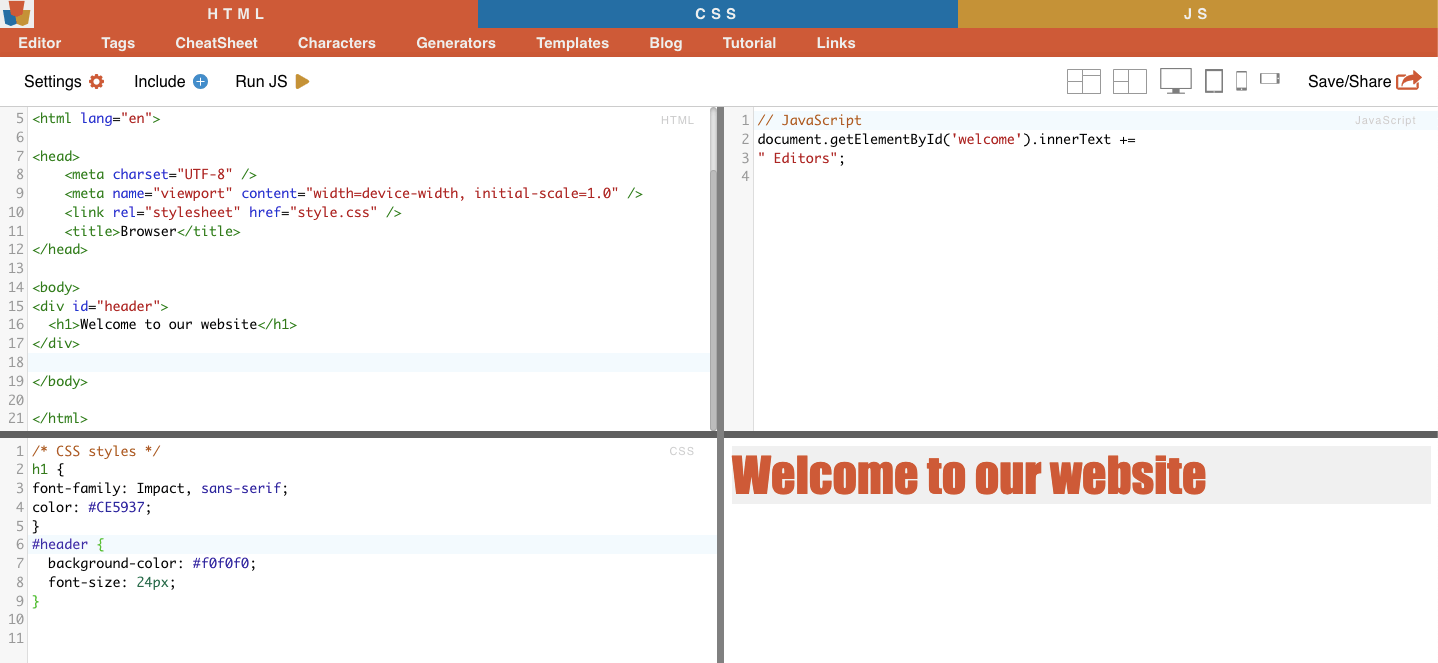
実例: 手動でIDを探す#01を見つけたら、id="01″を探す必要がある。
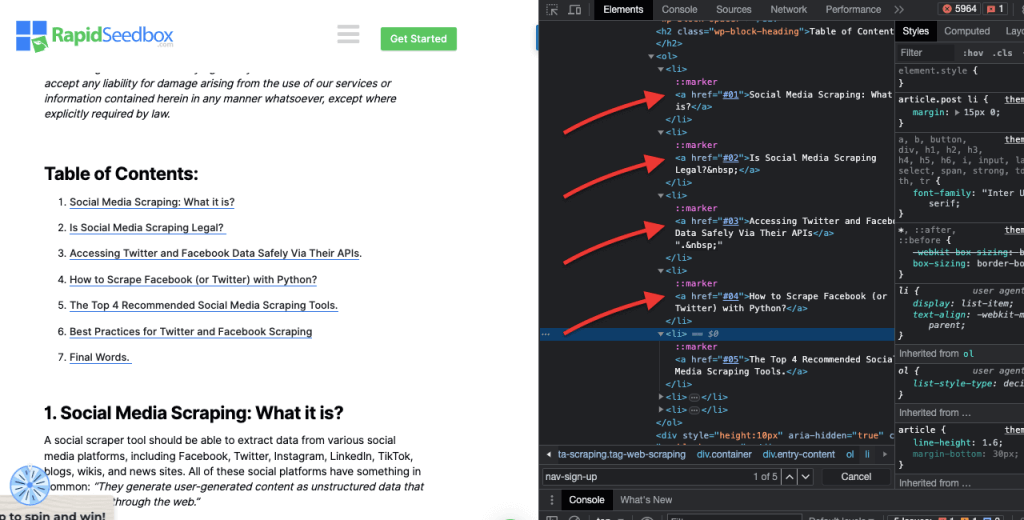
iv.属性マッチング。
このテクニックでは、特定の属性とその値に基づいてHTML要素を選択します。特定の属性や属性値を持つ要素を対象とすることができます。属性マッチングには、完全マッチングや部分文字列マッチングなど、さまざまなタイプがあります。
例 次の例では、データ型と呼ばれるカスタム属性を示しています。特定の項目(例えば、"fruit "とマークされたリスト項目)をターゲットにしたり、スタイルを設定するには、その属性値に基づいて要素を選択するCSSセレクタを使用することができます。
フルーツ」とマークされたアイテムだけをスクレイピングするには、以下のCSSセレクタを使用します:

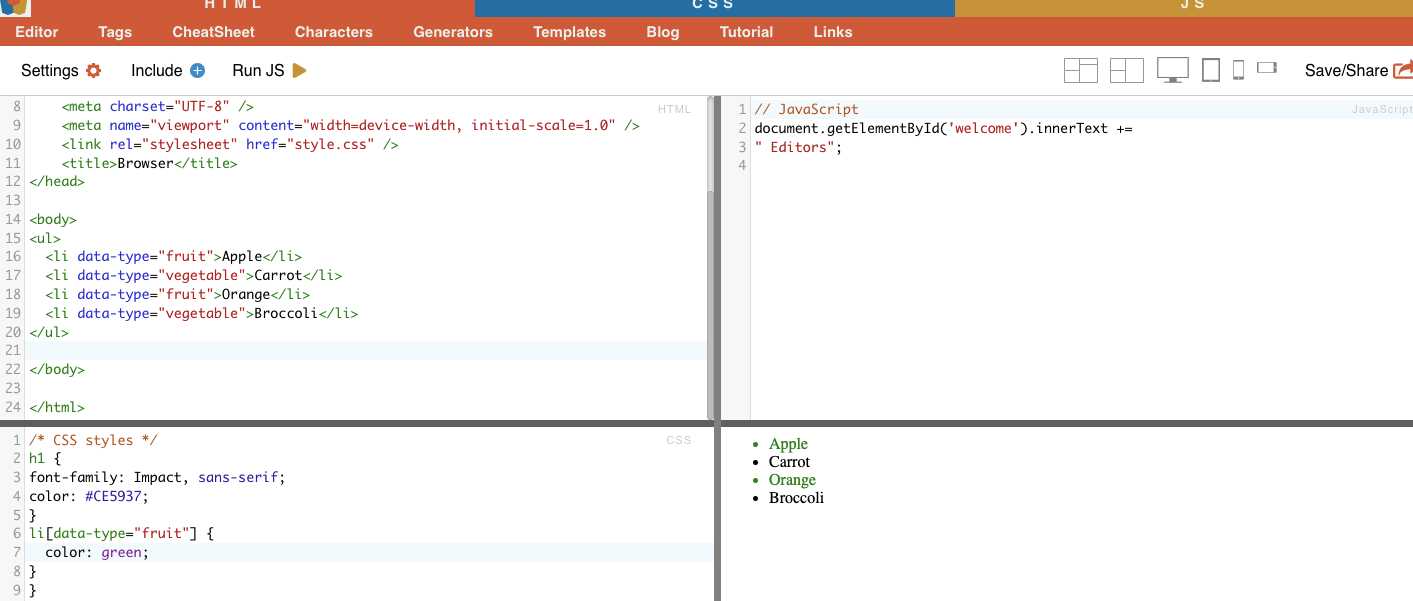
実例: 手動で属性を検索する
c.Xpathセレクタ:
CSSセレクタは、HTML構造が比較的単純なウェブ・スクレイピング作業に最適です。しかし、HTMLの構造が複雑になってくると、別の解決策があります:XPathセレクタです。
XPath セレクタ (XML パス言語セレクタ) は、XMLやHTMLドキュメントの要素をナビゲートするために使われる柔軟なパス言語である。 XPathセレクタは、位置、名前、属性、内容に基づいてHTMLコード内の特定のノードを選択するのに役立ちます。XPathセレクタは、class属性やID属性に基づいて要素をターゲットするのにも便利です。
ウェブスクレイピングのためのXPathセレクタの例を3つ紹介しよう。
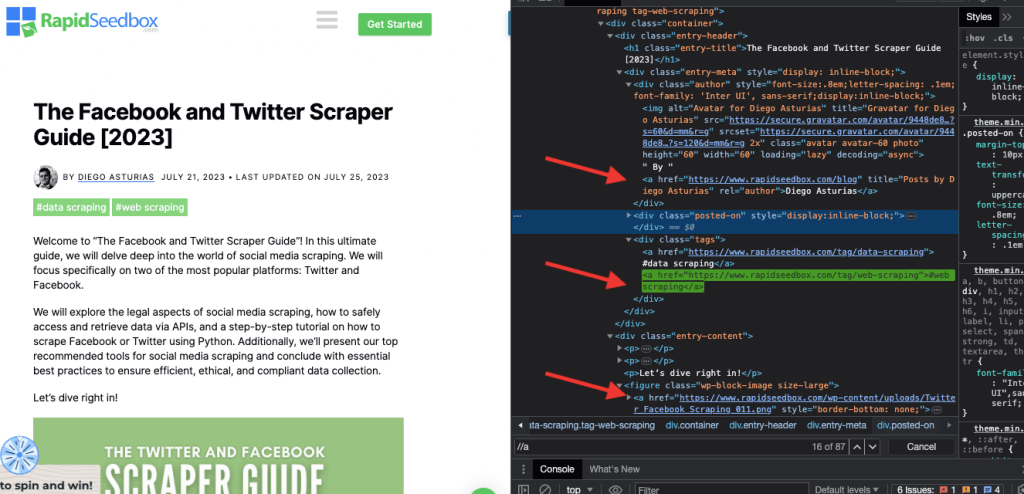
i.例1: XPath式: ' //a
XPath式 ' //a' は、ドキュメント内の位置に関係なく、ページ上のすべての '' 要素を選択します。次のスクリーンショットは、ページ上のすべての '' 要素を手動で検索しています。
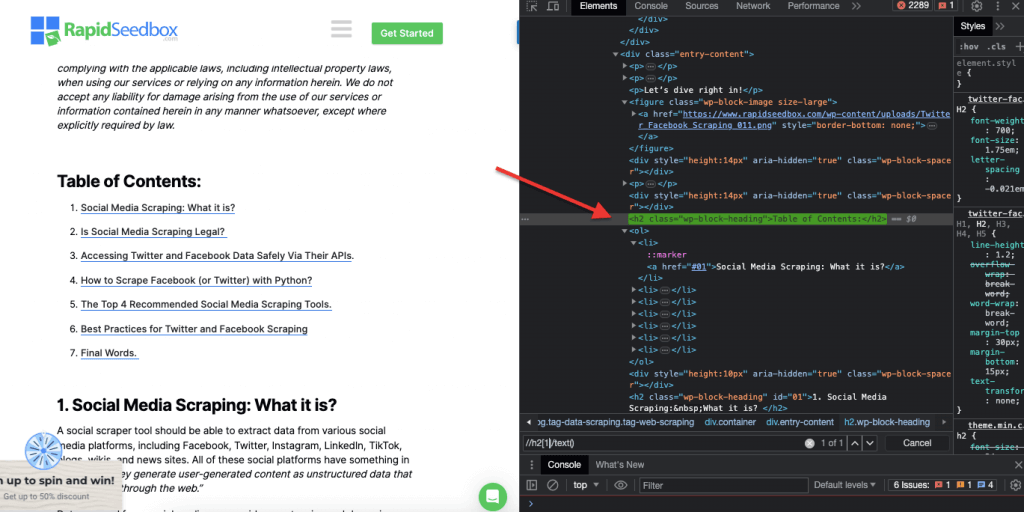
ii.例2:「//h2[1]/text()
XPath式:
' //h2[1]/text() '
これはページ上の最初のh2見出しのテキストコンテンツを選択します。'[1]'インデックスはh2要素の最初の出現箇所を指定するために使用され、'[2]'インデックスで2番目の出現箇所を指定することもできます。次のスクリーンショットは、このXPathセレクタを使用して、ページ上の最初の見出しh2を手動で検索しています。
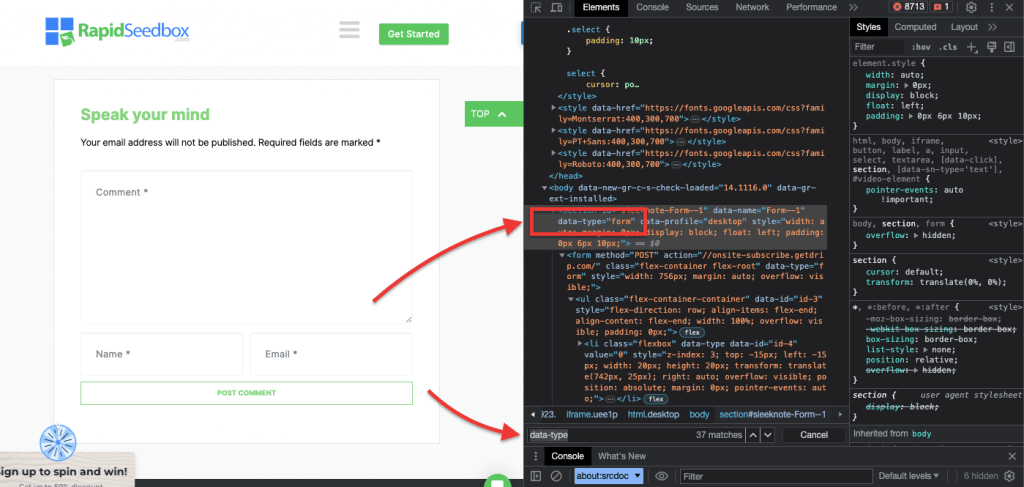
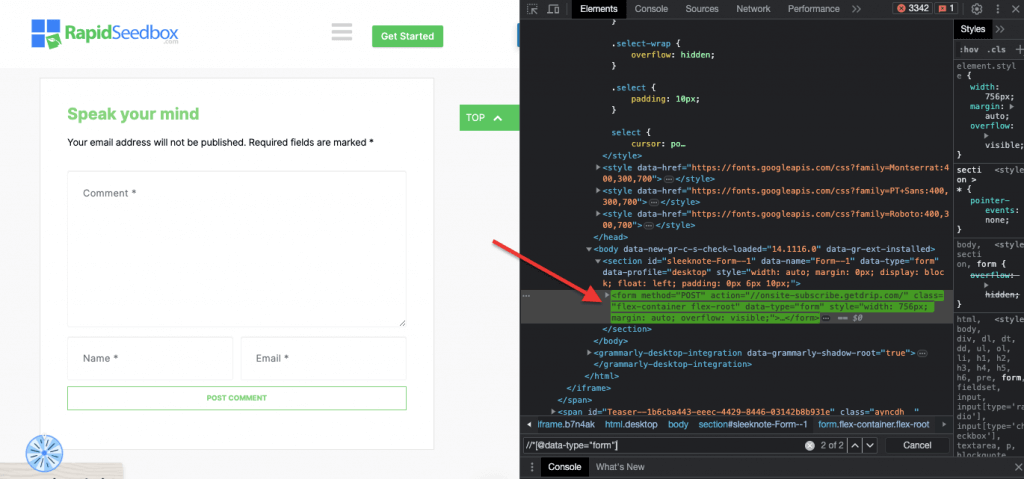
iii.例3.' //* [@data-type="form"]'.
XPath式 //* [@data-type="form"]。 は、値 "form "のdata属性を持つすべての要素を選択します。そのため * 記号は、ノード名に関係なく、指定されたデータ属性を持つ要素が選択されることを示します。次のスクリーンショットは、値 "form "を持つ要素を手動で探すプロセスを示しています。
これらのCSSセレクタやXPathセレクタを使用して、HTMLページからデータを視覚的に検査し、手動で抽出することは、時間がかかるだけでなく、エラーが発生する可能性があります。さらに、手作業や目視によるデータ抽出は、大規模なデータ収集や反復的なスクレイピング作業にはまったく適していません。そこで、スクリプトとプログラミングが非常に有益なのです。
RapidSeedboxの高速、安全、匿名プロキシでウェブスクレイピングを強化しましょう。
ウェブスクレイピングに最適なプログラミング言語は?
スクレイピングに最もよく使われるプログラミング言語はPythonで、ライブラリやパッケージが充実しているからだ。 ウェブスクレイピングはRこれもまた、サポートされているライブラリとフレームワークのセットが素晴らしいからだ。 さらに、多くのウェブスクレイパーが利用している一般的なプログラミング言語であるC#についても触れておきましょう。ZenRowsのようなサイトには、C#に関する包括的なガイドがあります。 C#でウェブサイトをスクレイピングする方法これにより、開発者はプロセスを理解しやすくなり、自身のプロジェクトを開始しやすくなる。
このウェブスクレイピングガイドでは、わかりやすくするために、Pythonを使ったウェブスクレイピングに焦点を当てます。読み進めてください!
3.PythonによるWebスクレイピング(コード付き)。
CSSセレクタやXPathセレクタを使えば、プログラミング言語を使って体系的かつ自動的にHTMLデータを抽出できるのに、なぜ視覚的に検査し、手作業でHTMLデータを抽出するのだろうか?
データ抽出を容易にするCSSセレクタをサポートする、人気のあるウェブスクレイピング・ライブラリやフレームワークは数多くある。ウェブスクレイピングのための最も人気のあるプログラミング言語の1つは パイソンのようなライブラリのためのものである。 ビューティフル・スープ, リクエスト, CSSセレクト, セレン、 スクラップ. これらのライブラリにより、ウェブスクレイパーはCSSとXPathセレクタを活用して効率的にデータを抽出することができる。
ビューティフル・スープ
BeautifulSoupは、HTMLやXMLドキュメントを解析するために設計された、最もポピュラーで強力なPythonパッケージの一つである。このパッケージはページの解析ツリーを作成し、HTMLから簡単にデータを抽出できるようにします。
| 興味深い事実だ! COVID-19との戦いで 林家宝のDXY-COVID-19クローラー はBeautifulSoupを使って中国の医療サイトから貴重なデータを抽出した。そうすることで、研究者がウイルスの蔓延を監視し理解するのに役立った。[ソース] |
リクエスト
パイソンの リクエスト はシンプルかつ強力なHTTPライブラリである。ウェブサイトからデータを取得するためにHTTPリクエストを行うのに便利です。"Requests "は、WebスクレイピングPythonプロジェクトでHTTPリクエストを送信し、レスポンスを処理するプロセスを簡素化します。
a.PythonによるWebスクレイピングのチュートリアル (+ コード)
Pythonを使ったWebスクレイピングのチュートリアルでは、"requests "とBeautifulSoupライブラリを使ったPythonコードを使って、対象のHTMLサイトからデータを取得します。
前提条件
以下の前提条件が満たされていることを確認する:
- Python環境: を持っていることを確認する。 パイソン をインストールしてください。また、お好みのPython環境でスクリプトを実行できることを確認してください(例. アイドル や、 ジュピター・ノートブック).
- リクエストライブラリー をインストールします。
リクエストライブラリで使用されます。指定したURLにHTTP GETリクエストを送信するために使用します。インストールするにはピップ走ってpip install リクエストをコマンドプロンプトまたはターミナルに入力する。 - ビューティフル・スープ・ライブラリー をインストールします。
ビューティフルスープ4ライブラリを使用してインストールできます。インストールするにはピップ走ってpip install beautifulsoup4を端末に入力する。
ページからデータをスクレイピングするためのPythonコード(BeautifulSoup付き)
以下のスクリプトは、指定されたURLを取得し、BeautifulSoupを使用してHTMLコンテンツを解析し、ウェブページ上のトップニュース記事のタイトルを表示します。

IDLE Shell上でスクリプトを実行すると、対象となるウェブサイトから収集されたすべての「news_titles」が画面に表示される。

b.ウェブスクレイピングのためのPythonコードのバリエーション。
前回のウェブスクレイピングのPythonコードを使って、異なるタイプのデータをスクレイピングするためにいくつかのバリエーションを行うことができる。
例えば、こうだ:
- イメージを見つける ウェブページ上のすべての画像タグ(
)を見つけるには、タグ名 'img' を指定して find_all() メソッドを使用します:

- リンクを見つける ウェブページ上のリンクを表すすべてのアンカー・タグ()を見つけるには、タグ名 'a' を指定して find_all() メソッドを使用します:

提供されるスクリプトは(バリエーションとともに)基本的なウェブ・スクレイピング・スクリプトである。指定されたURLからトップニュース記事のタイトルを抽出して表示するだけである。しかし残念ながら、このシンプルなスクリプトには、より包括的なウェブスクレイピング・プロジェクトを構成する多くの機能が欠けている。 データ保存、エラー処理、ページネーション/クローリング、ユーザーエージェントとヘッダーの使用、スロットリングと丁寧さ対策、動的コンテンツの処理能力など、追加を検討したい要素がいくつかある。
4.ウェブ・スクレイピングは合法か?
ウェブスクレイピングは、一般的に物議を醸す、あるいは違法であると認識されている。しかし実際には、一定の倫理的・法的境界線を守れば、ウェブスクレイピングは完全に合法的な合法行為です。
ウェブスクレイピングの合法性は、抽出されるデータの性質と使用される方法によって異なります。 ウェブスクレイピングは、インターネットから一般に入手可能な情報を収集するために使用される場合、合法的であるとみなされます。 しかし、特に個人データや著作権のあるコンテンツを扱う場合は、常に注意が必要です。
以下は、留意すべきいくつかのポイントである:
- 個人情報をスクレイピングしないでください。 また、一般に公開されていないデータを抽出することも違法である。ユーザーとパスワードでログインするログインページの背後にあるデータをスクレイピングすることは、米国、カナダ、ヨーロッパの大部分では法律違反です。
- そのデータを使って何をするかで、トラブルに巻き込まれる可能性がある。 倫理的なウェブスクレイピングには、収集されるデータとその意図される目的に留意することが必要である。個人データと知的財産には特に注意を払う必要がある。GDPRやCCPAのような個人データの取り扱いを規定する規制を遵守していることを確認する。例えば、コンテンツの再利用や転売、著作権で保護された素材のダウンロードは違法です(避けるべきです)。
- ウェブサイトの利用規約を確認することも欠かせない。 これは、そのサービスやコンテンツを利用する人が、リソースとどのように接するべきか、また接するべきでないかを指示する文書です。
- 公式に提供されているAPIを使うなど、常に代替手段を確保すること。 政府機関、天気予報、ソーシャルメディア・プラットフォームのようないくつかのウェブサイトは、APIを通じてデータの一部を一般に公開している。
- robots.txtファイルのチェックを検討してください。 This file is saved on the web server and gives directions to web crawlers and web scraping about what parts of a website to avoid and what parts are authorized. It also gives directions about the rate limits.
- ウェブスクレイピング攻撃を避ける。 文脈によっては、ウェブスクレイピングをスクレイピング攻撃と呼ぶこともある。スパマーがボットネット(ボットの軍団)を使って、大量かつ高速なリクエストでウェブサイトを標的にすると、ウェブサイト全体のサービスが停止することがある。大規模なデータスクレイピングにより、サイト全体がダウンすることもある。
ウェブスクレイピングの法的側面に関する最近のニュース。
最近の法的判決により、一般に公開されているデータのスクレイピングは一般に違反とは見なされないことが明らかになった。米国の控訴裁判所による画期的な判決では、インターネット上の一般にアクセス可能なデータをスクレイピングしても、コンピュータ詐欺乱用法(CFAA)に違反しないとし、ウェブスクレイピングの合法性が再確認された[出典]: テッククランチ].
最近のニュースによると、OpenAIとマイクロソフトに対する最近の訴訟は、プライバシー、知的財産、ハッキング防止法に関する懸念を浮き彫りにしている。ブルームバーグ].CFAAの効果は限定的であるが、契約違反の申し立てや州のプライバシー法が検討されている。著作権法と契約法の相互作用は未解決のままであり、ウェブスクレイピングの文脈では多くの疑問が残されている。
最新のニュースでは、 [出典 インドタイムズ]イーロン・マスクがTwitterのルールを変更し、極端なレベルのデータスクレイピングを防止しようとしている。マスクによると、極端なウェブスクレイピングはユーザーエクスペリエンスに悪影響を与えるという。彼は、生成AIのために大規模な言語モデルを使用している組織が原因であることを示唆した。
5.ウェブサイトはどのようにウェブ・スクレイピングをブロックしようとしているのか?
企業は、人間の訪問者がデータの一部にアクセスできることを望んでいる。しかし、企業やユーザーが自動化されたスクリプトやボットを使用してサイトから積極的にデータを抽出する場合、ターゲットとなるウェブサーバーやページで多くのプライバシーやリソースの乱用が発生する可能性があります。このような被害サイトは、この種のトラフィックを抑止することを好む。
スクレイピング対策。
- 単一のソースからの異常で大量のトラフィック。 ウェブサーバーは、トラフィックをブロックするためのノイズの多いIPアドレスのブラックリスト、リクエストの「異常な」レートとサイズに関するフィルター、およびフィルタリング機構を備えたWAF(ウェブアプリケーションファイアウォール)を使用することができる。一部のサイトでは、WAFとCDN(コンテンツ・デリバリー・ネットワーク)を組み合わせて使用し、そのようなIPからのノイズを完全にフィルタリングしたり、低減したりしています。
- ウェブサイトによっては、ボットのような閲覧パターンを検出することができる。 前のテクニックと同様に、ウェブサイトもUser-Agent(HTTPヘッダー)に基づいてリクエストをブロックする。ボットは通常のブラウザを使いません。これらのボットは、異なるユーザーエージェント文字列(クローラー、スパイダー、ボットなど)を持ち、バリエーションがなく、ヘッダー(ヘッドレスブラウザ)、リクエスト料金など。
- ウェブサイトもHTMLマークアップを頻繁に変更する。 ウェブスクレイピングのボットは、ウェブサイトのコンテンツを巡回する際、一貫した「HTMLマークアップ」のルートをたどる。ウェブサイトの中には、マークアップ内のHTML要素を定期的かつランダムに変更するものがある。このテクニックは、ボットの定期的なスクレイピングの習慣やスケジュールを狂わせる。HTMLマークアップを変更してもウェブ・スクレイピングは止まらないが、はるかに困難になる。
- CAPTCHAのようなチャレンジの使用。 ヘッドレス・ブラウザを使用するボットを避けるために、ウェブサイトによってはCAPTCHAチャレンジを要求するものがあります。ヘッドレス・ブラウザを使用するボットは、この種の課題を解くのに苦労します。CAPTCHAは、ロボットではなく、ユーザーレベル(ブラウザ経由)で解けるように作られています。
- いくつかのサイトは、スクレイピング・ボットの罠(ハニーポット)になっている。 ウェブサイトの中には、スクレイピング・ボットを捕捉するためだけに作られたものがある-これはハニーポットと呼ばれる手法だ。このようなハニーポットは、スクレイピング・ボットにしか見えず(普通の人間の訪問者には見えない)、ウェブスクレイパーを罠にはめるように作られています。
6.ウェブスクレイピングの倫理とベストプラクティス。
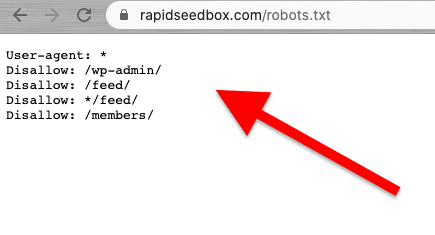
ウェブスクレイピングは、責任を持って倫理的に行われるべきである。.前述したように、利用規約やToSを読めば、遵守しなければならない制限について知ることができるはずだ。もしウェブクローラーのルールを知りたければ、ROBOTS.txtをチェックしてください。
ウェブスクレイピングが完全に許可されていないか、ブロックされている場合は、そのAPIを使用する(利用可能な場合)。
また、ターゲットのウェブサイトの帯域幅に気を配り、多すぎるリクエストでサーバーに負荷がかからないようにする。ターゲットのサーバーに負担をかけないように、レートを決めて適切なタイムアウトでリクエストを自動化することが重要です。リアルタイムのユーザーをシミュレートすることが最適です。また、ログインページの裏側でデータをスクレイピングしてはならない。
ルールを守れば大丈夫だ。
ウェブスクレイピングのベストプラクティス
- プロキシを使う。 プロキシはリクエストを転送する仲介サーバーです。プロキシを使ってウェブスクレイピングを行う場合、元のリクエストをプロキシ経由で転送することになる。そのため、プロキシは自身のIPでリクエストをマッピングし、ターゲットのウェブサイトに転送します。プロキシを使う
- あなたのIPがブラックリストに載ったり、ブロックされたりする可能性をなくします。 常に様々なプロキシを通してリクエストする IPv6プロキシ が良い例だ。プロキシプールは、ブロックされることなく大容量のリクエストを実行するのに役立つ。
- 地域に合わせたコンテンツをバイパスする。 特定の地域のプロキシは、その特定の地域に従ってデータをスクレイピングするのに便利である。これは、ウェブサイトやサービスがCDNの背後にある場合に便利です。
- プロキシを回転させる。 ローテーティング・プロキシは、新しい接続ごとにプールから新しいIPを取得(ローテート)します。以下の点に注意してください。 VPNはプロキシではない。 匿名性を提供するという点ではよく似ているが、両者は異なるレベルで機能している。
- 回転 UA(ユーザーエージェント)とHTTPリクエストヘッダ。 UAとHTTPヘッダーを回転させるには、実際のウェブブラウザからUA文字列のリストを収集する必要がある。そのリストをPythonのWebスクレイピングコードに入れ、ランダムな文字列を選ぶようにリクエストを設定する。
- 限界に挑戦するな。 リクエストの数を減らし、回転させ、ランダムにする。ウェブサイトへのリクエストが多い場合は、ランダムにすることから始めましょう。各リクエストがランダムで人間のように見えるようにする。まず、プロキシをローテーションさせてリクエストのIPを変える。また、異なるHTTPヘッダーを使用して、リクエストが他のブラウザから来ているように見せかける。
RapidSeedboxの高速、安全、匿名プロキシでウェブスクレイピングを強化しましょう。
7.ウェブスクレイピング FAQ:よくある質問。
a.robots.txtとは何ですか?また、ウェブスクレイピングにおいてどのような役割を果たしますか?
について robots.txt ファイルは、ウェブサイトの所有者、ウェブ・クローラー、および "スクレイパー "間のコミュニケーション・ツールとして機能します。robots.txtは、ウェブサイトのサーバーに置かれるテキストファイルで、ウェブロボット(クローラー、ウェブスパイダー、その他の自動化されたボット)に対して、ウェブサイトのどの部分へのアクセスやスクレイピングが許可され、どの部分は避けるべきかを指示するものです。「お行儀の良い」ウェブ・クローラー(Googlebotなど)は、robots.txtを自動的に読むように設計されています。スクレイパーはこのファイルを読むようには設計されていない。したがって、robots.txtを意識することは、ウェブサイト所有者の意思を尊重するために非常に重要である。
b.ウェブサイト管理者は、"悪用 "または "無許可 "のウェブスクレイピングの試みを避けるために、どのようなテクニックを使っていますか?
すべてのスクレイパーが倫理的かつ合法的にデータを抽出しているわけではありません。彼らはサイトのTOS(利用規約)やrobots.txtガイドラインに従わない。そのため、ウェブサイトの管理者は、IPブロックやCAPTCHAチャレンジの使用など、データやリソースを保護するための追加措置を講じることがある。また、レート制限、ユーザーエージェントの検証(潜在的なボットを特定するため)、セッションの追跡、トークンベースの認証の使用、CDN(コンテンツデリバリーネットワーク)の使用、行動ベースの検出システムの使用なども考えられます。
c.ウェブ・スクレイピングとウェブ・クローリング?
ウェブスクレイピングとウェブクローリングはどちらもウェブデータの抽出技術であるが、その目的、範囲、自動化、法的側面は異なる。一方、ウェブスクレイピング技術は、特定のサイトから特定のデータを抽出することを目的としている。これらはターゲットを絞り、特定の限定された範囲を持つ。ウェブ・スクレイピングは、自動化されたスクリプトやサード・パーティのツールを使って、データを要求、受信、解析、抽出、構造化する。ウェブクローリング技術 リストクローリング)は、ウェブを体系的に検索するために使用される。検索エンジン(より広い範囲)、ソーシャルメディア・プラットフォーム、研究者、コンテンツ・アグリゲーターなどに人気がある。ウェブ・クローラーは、(ボット、クローラー、スパイダーを経由して)自動的に多くのサイトを訪問し、リストを作成し、データをインデックス化し(コピーを作成し)、データベースに保存することができる。ウェブ・クローラーは通常、ROBOTS.txtファイルをチェックする。
d.データマイニングとデータスクレイピング:その違いと共通点は?
データマイニングとデータスクレイピングはどちらもデータ抽出を伴う。しかし、データマイニングは、構造化されたデータセットを分析するために統計的および機械学習技術を使用することに重点を置いている。大規模で複雑な構造化データセットの中から、パターン、関係、洞察を特定することを目的としている。一方、データスクレイピングは、ウェブページやウェブサイトから特定の情報を「収集する部分」に焦点を当てている。どちらの技術やツールも一緒に使うことができる。ウェブスクレイピングは、ウェブからデータを収集するための予備的なステップであり、その後、詳細な分析と洞察の発見のためにデータマイニングアルゴリズムに供給される。
e.スクリーン・スクレイピングとは何か? また、データ・スクレイピングとの関連は?
どちらの手法もデータ抽出に重点を置いているが、抽出するデータの種類が異なる。 スクリーン研磨 ツールは、画面のテキストを含め、ウェブサイトや文書に表示される視覚データを「自動的に」キャプチャし、抽出することを目的としている。HTMLからデータを解析するウェブスクレイピング(その結果、幅広いウェブデータを抽出する)とは異なり、スクリーンスクレイピングは、画面表示から直接テキストデータを読み取る。
f.ウェブ・ハーベスティングはウェブ・スクレイピングと同じですか?
データ・スクレイピングとウェブ・ハーベスティングは強く関連しており、しばしば同じ意味で使われるが、同じ概念ではない。ウェブ・ハーベスティングはより広い意味合いを持つ。これは、ウェブスクレイピングのような様々な自動ウェブ抽出メカニズムを含む、ウェブからデータを抽出する様々な方法を包含する。明確な違いは、ウェブハーベスティングは、(ウェブスクレイピングが行うように)ウェブページからHTMLコードを直接解析するのではなく、APIが関与する場合に使用されることが多いということです。
g.CSSセレクタとXPathセレクタ: スクレイピング時の違いは?
CSSセレクタは、Webスクレイピング中にデータを抽出する効率的な方法です。CSSセレクタはわかりやすい構文を提供し、ほとんどのスクレイピングシナリオでうまく機能します。しかし、より複雑なケースや入れ子構造を扱う場合は、XPath セレクタを使用することで、さらなる柔軟性と機能を提供することができます。
h.Seleniumで動的なウェブサイトを扱うには?
Seleniumは、動的なウェブサイトをウェブスクレイピングするための強力なツールです。Seleniumを使えば、ウェブページ上の要素を人間のユーザーと同じように操作することができる。この機能により、「スクリプト」は動的に生成されたコンテンツをナビゲートすることができます。Seleniumを使うことで SeleniumのWebDriverページ要素のロードを待ったり、AJAX要素とやりとりしたり、JavaScriptに大きく依存するウェブサイトからデータをスクレイピングしたりできる。
i. ウェブスクレイピング中にAJAXとJavaScriptを扱うには?
ウェブスクレイピングでAJAXやJavaScriptを扱う場合、RequestsやBeautiful Soupのような従来のライブラリでは不十分かもしれない。AJAXリクエストやJavaScriptでレンダリングされたコンテンツを扱うには、Seleniumのようなツールや、以下のようなヘッドレスブラウザを使うことができる。 人形遣い.
8.まとめ
おめでとう!あなたはウェブスクレイピングの究極のガイドを完成させた!
このガイドが、あなたのプロジェクトにウェブスクレイピングの可能性を活用するための知識とツールを提供できたことを願っています。
大きな力には大きな責任が伴うことを忘れないでほしい。 ウェブスクレイピングの旅を始めるにあたり、常に倫理的慣行を優先し、ウェブサイトの利用規約を尊重し、データプライバシーに留意すること。
我々は氷山の一角に触れた。ウェブ・スクレイピングはかなり包括的なトピックになる。しかし、あなたはすでにウェブサイトをスクレイピングしている!
継続的に学習し、最新のテクノロジーや法的動向を把握することで、この複雑な世界を乗り切ることができます。
これらのCSSセレクタやXPathセレクタを使用して、HTMLページからデータを視覚的に検査し、手動で抽出することは、時間がかかるだけでなく、エラーが発生する可能性があります。さらに、手作業や目視によるデータ抽出は、大規模なデータ収集や反復的なスクレイピング作業にはまったく適していません。そこで、スクリプトとプログラミングが非常に有益なのです。
0コメント