In this ultimate guide, we will explore the world of web scraping, a powerful technique to extract data from websites. rat
Whether you’re a beginner curious about the concept or an experienced programmer looking to enhance your skills, this guide has something valuable for everyone. From understanding the basics of HTML data extraction using CSS and XPath selectors to hands-on web scraping with Python, we’ve got you covered. Additionally, we’ll address the legal aspects, ethical considerations, and best practices to ensure responsible web scraping.

Tuyên bố miễn trừ trách nhiệm: Tài liệu này đã được phát triển nghiêm ngặt cho mục đích thông tin. Nó không cấu thành sự chứng thực cho bất kỳ hoạt động nào (bao gồm cả các hoạt động bất hợp pháp), sản phẩm hoặc dịch vụ. Bạn hoàn toàn chịu trách nhiệm tuân thủ luật hiện hành, bao gồm luật sở hữu trí tuệ, khi sử dụng dịch vụ của chúng tôi hoặc dựa vào bất kỳ thông tin nào ở đây. Chúng tôi không chấp nhận bất kỳ trách nhiệm pháp lý nào đối với thiệt hại phát sinh từ việc sử dụng các dịch vụ hoặc thông tin của chúng tôi ở đây dưới bất kỳ hình thức nào, trừ khi luật pháp yêu cầu rõ ràng.
Mục lục.
- What is Web Scraping and How it Works?
- Basics of HTML Data Extraction: CSS and XPath Selectors.
- Web Scraping with Python (+ Code).
- Is Web Scraping Legal?
- How do websites attempt to block web scraping?
- Ethical and Best Practices for Web Scraping.
- Web Scraping: Frequently Asked Questions (FAQ)
- Lời kết
1. What is Web Scraping and How it Works?
Web scraping (also known as web harvesting or data extraction) is the process of automatically extracting data from websites, web services, and web applications.
Web scraping helps save us from having to go into each website and manually pull data—a long and ineffective process. The process involves using automated scripts or programs. The script or program accesses the HTML structure of the web page, parses the data, and extracts the specific needed elements of the page for further analysis.
a. What is Web Scraping Used For?
Web scraping is fantastic if done responsibly. Generally, it can be used to research markets, such as gaining insights and learning about trends in a specific market. It is also popular in competition monitoring to keep track of their strategy, prices, etc.
More specific use cases are:
- Social platforms (Facebook and Twitter scraping)
- Online price change monitoring,
- Product reviews,
- SEO campaigns,
- Real estate listings,
- Tracking weather data,
- Tracking a website’s reputation,
- Monitoring availability and prices of flights,
- Test ads, regardless of geography,
- Monitoring financial resources,
b. How does Web Scraping work?
The typical elements involved in web scraping are the initiator and the target. The initiator (web scraper) uses automatic data extraction software to scrape websites. The targets, on the other hand, are generally the website’s content, contact information, forms, or anything publicly available on the web.
The typical process is as follows:
- STEP 1: The initiator uses the scraping tool — software (which can be either a cloud-based service or a homemade script) to start generating HTTP requests (used to interact with websites and retrieve data). This software can initiate anything from an HTTP GET, POST, PUT, DELETE, or HEAD, to an OPTIONS request to a target website.
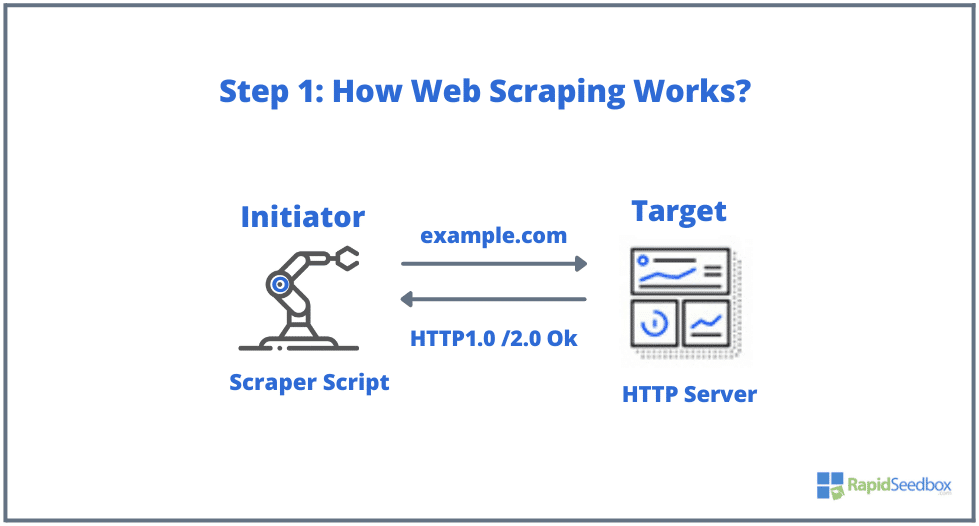
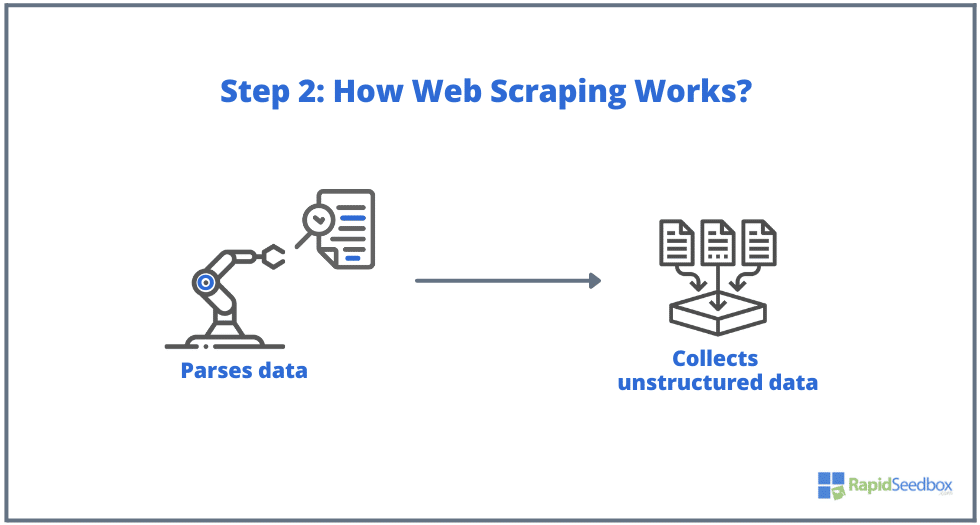
- STEP 2. If the page exists, the target website would respond to the scraper’s request with the HTTP/1.0 200 OK (the typical response to visitors.) When the scraper receives the HTML response (for example 200 OK), it would then proceed to parse the document and collect its unstructured data.
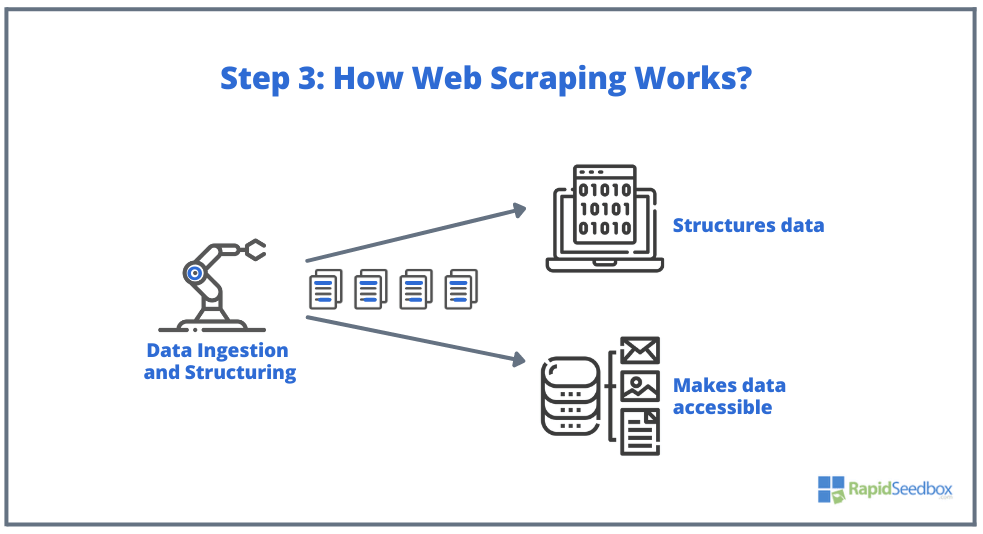
- STEP 3. The scraper software would then extract the raw data, stores it, and adds structure (indexes) to the data to whatever was specified by the initiator. The structured data is accessible through readable formats like XLS, CSV, SQL, or XML.
2. Basics of HTML Data Extraction: CSS and XPath Selectors.
You might already know the basics: Web scraping involves extracting data from websites, and it all begins with HTML—the backbone of web pages. Within an HTML file, you’ll find classes and IDs, tables, lists, blocks, or containers— all basic elements that make up the structure of a page.
CSS, on the other hand, is a style sheet language used to control the presentation and layout of HTML documents. It defines how HTML elements are displayed on a web page, like colors, fonts, margins, and positioning. CSS plays a key role in web scraping, as it helps extract data from the desired elements.
Lưu ý: Explaining in full detail what is HTML and CSS and how they work, is outside the scope of this article. We assume, you already have the fundamental skills of HTML and CSS.
While it would be possible to extract data directly from the raw HTML using various techniques like regular expressions, it can really time-consuming and challenging. Since HTML’s structured language was designed to be “machine-readable”, it can get really complex and varied. This is where CSS and XPath selectors play a key role.
a. Compiling and Inspecting HTML.
In the following section, we will provide a few CSS and XPath selector examples (compiled and inspected). All the following HTML and CSS examples have been compiled with the online editor HTML-CSS-JS.
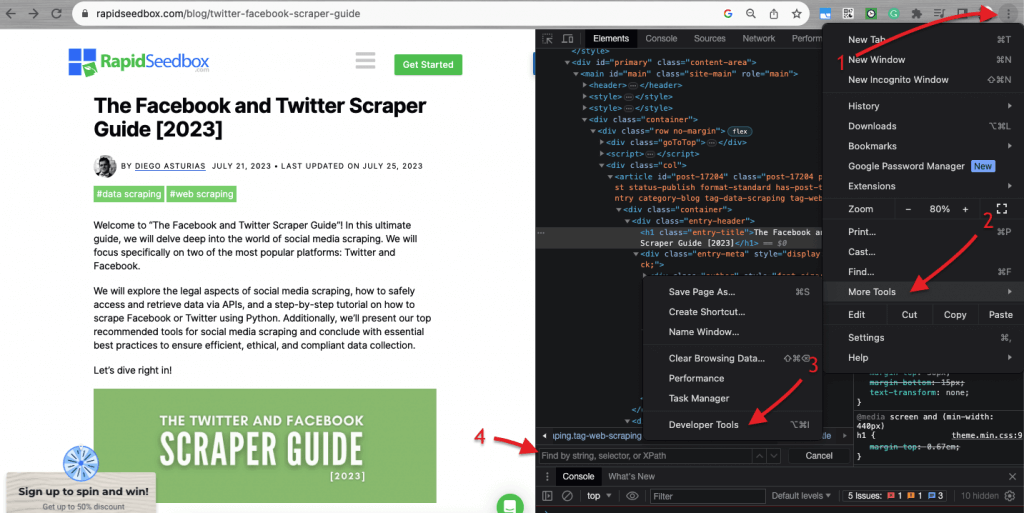
When it comes to inspecting HTML code in websites, web browsers come with Developer Tools, so you can literally inspect the HTML or CSS that is publicly available on any website. You can right-click on a web page and select “Inspect”, “Inspect Element”, or “Inspect Source”. For a better side-by-side page and code dynamic comparison, on Chrome Browser > go to the three dots on the top-left (1) > More Tools (2) > Developer Tools (3).
The Developer tools come with a handy search filter (4) that allows you to search by string, selector, or XPath. As an example, we will scrape some data out of: https://www.rapidseedbox.com/blog/twitter-facebook-scraper-guide.
b. CSS Selectors:
CSS selectors are patterns used to select and target a web page’s HTML elements. They are useful for web scraping (and styling) as they provide a more efficient and targeted way to get data from HTML documents. While it is possible to extract data directly from the raw HTML using various techniques like regular expressions, CSS selectors offer several advantages that make them a preferred choice for web scraping.
Techniques for targeting and selecting HTML elements within a web page:
i. Node Selection.
Node selection is the process of choosing HTML elements based on their node names. For example, selecting all ‘p’ elements or all ‘a ‘ elements on a page. This technique allows you to target specific types of elements in the HTML document.

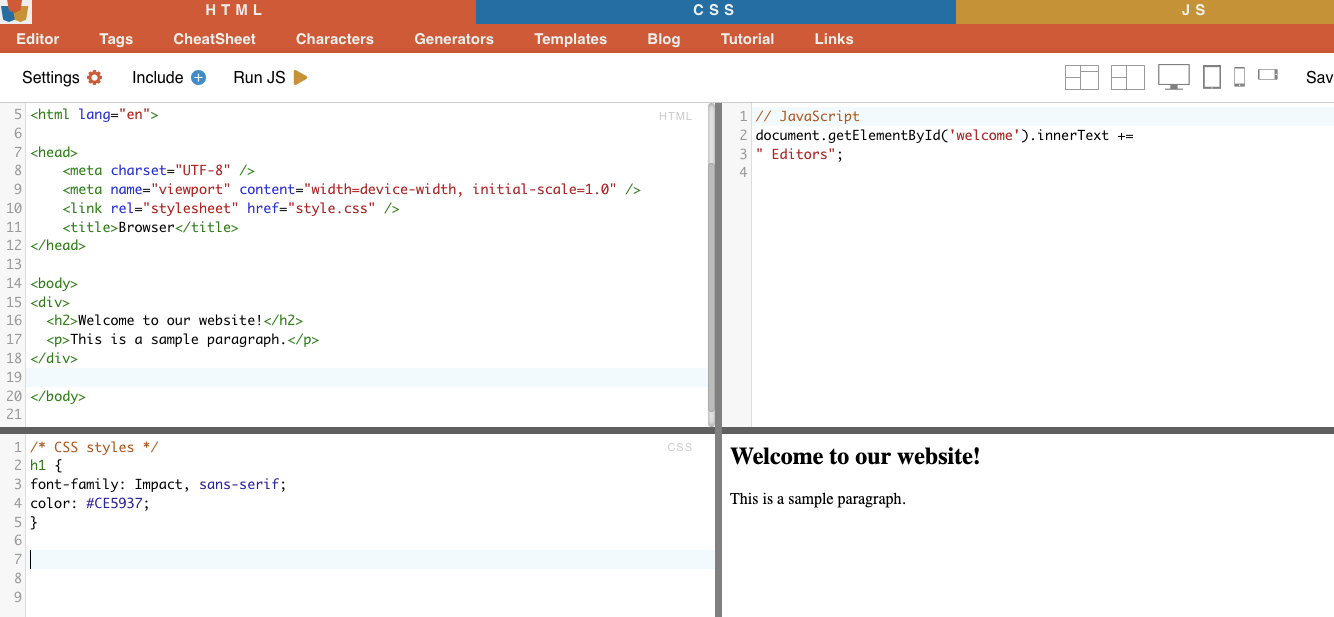
Real-Life Example: Manually searching for H2s.
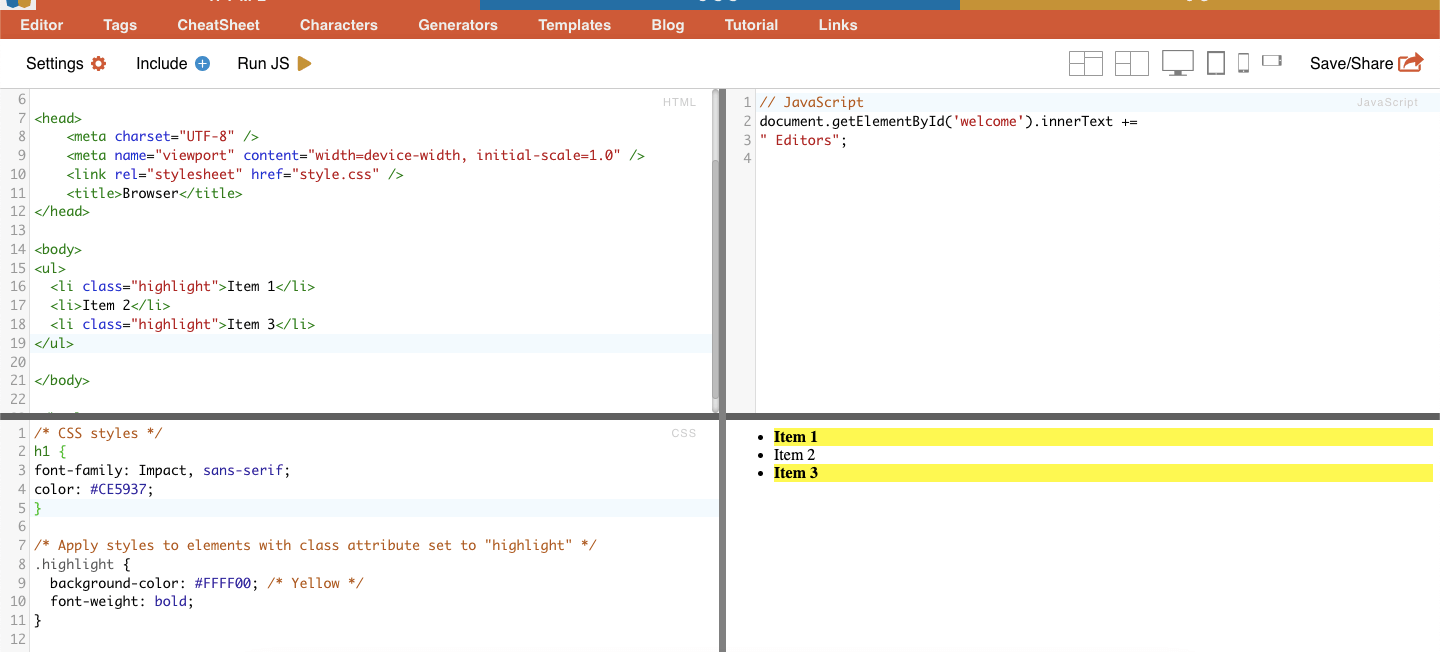
ii. Class.
In CSS Selectors, class selection involves selecting HTML elements based on their assigned class attribute. The class attribute allows you to apply a specific class name to one or more elements. Additionally in the CSS styles or JavaScript, it can be applied to all elements with that class. Examples of ‘class’ names are buttons, form elements, navigation menus, grid layouts, and more.
Example: The following CSS Selector: ‘highlight’ will select all elements with the class attribute set to “highlight”.


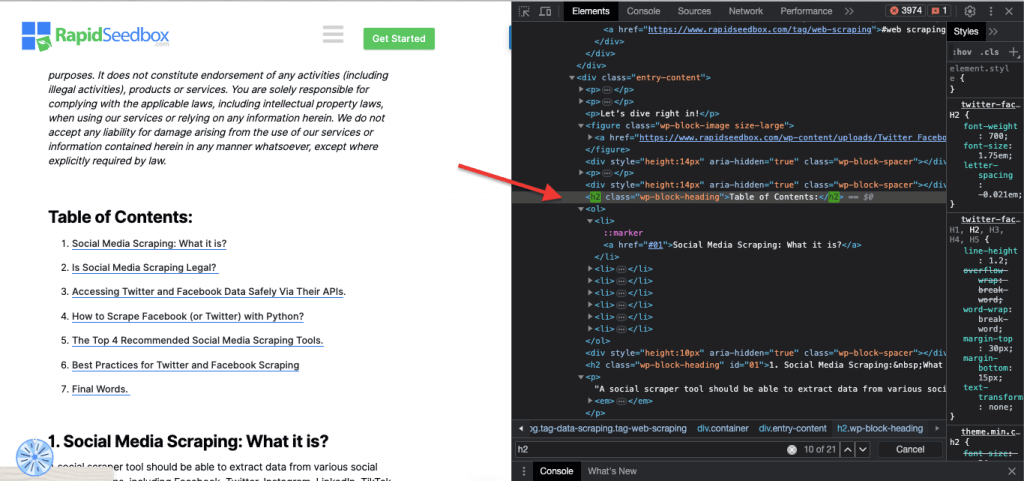
Real-Life Example: Manually searching for classes.
iii. ID Constraints.
ID constraints help select an HTML element based on its unique ID attribute. This ID attribute is used to uniquely identify a single element on the web page. Unlike classes, which can be used on multiple elements, IDs should be unique within the page.
Example: The CSS Selector ‘#header’ will select the element with the ID attribute set to “header”.


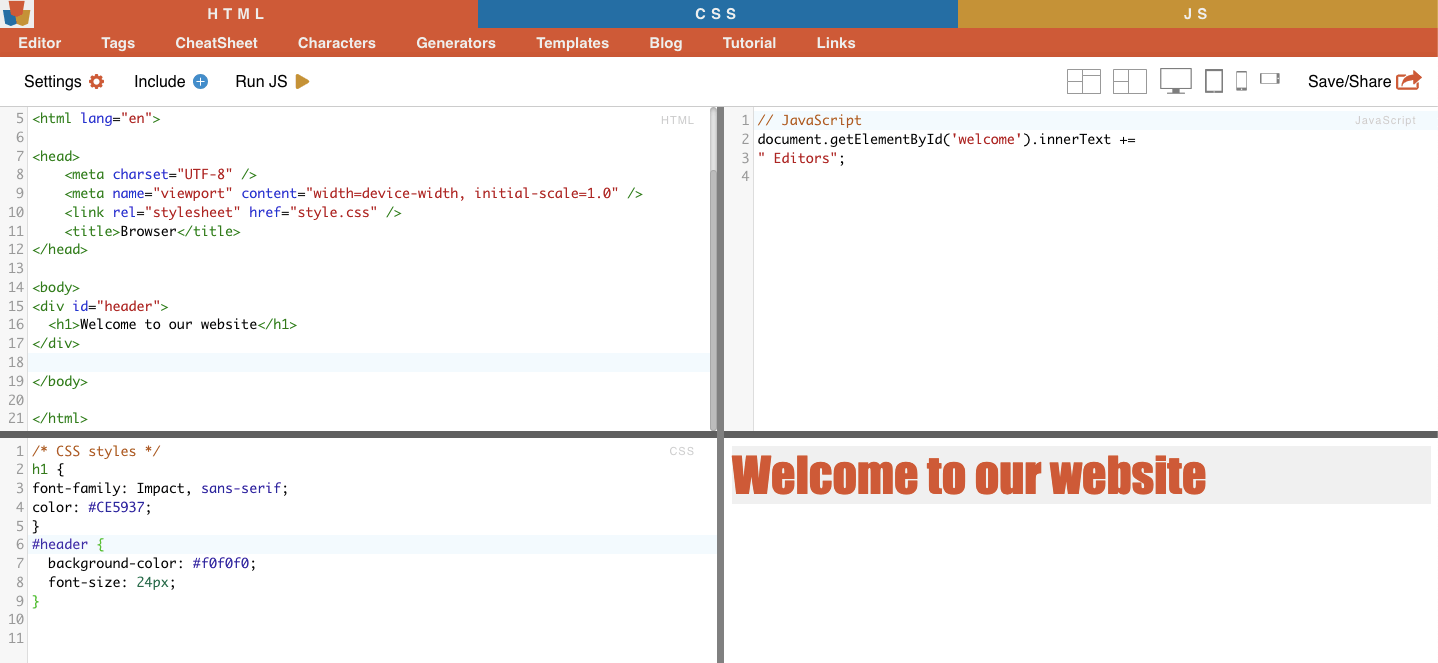
Real-life Example: Manually searching for IDs. After finding the #01 you’ll need to locate the id=”01″
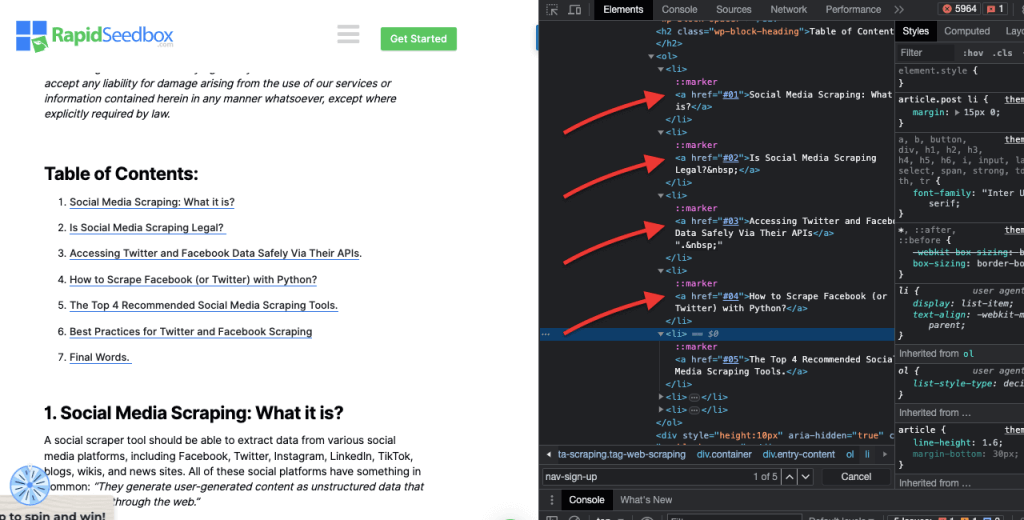
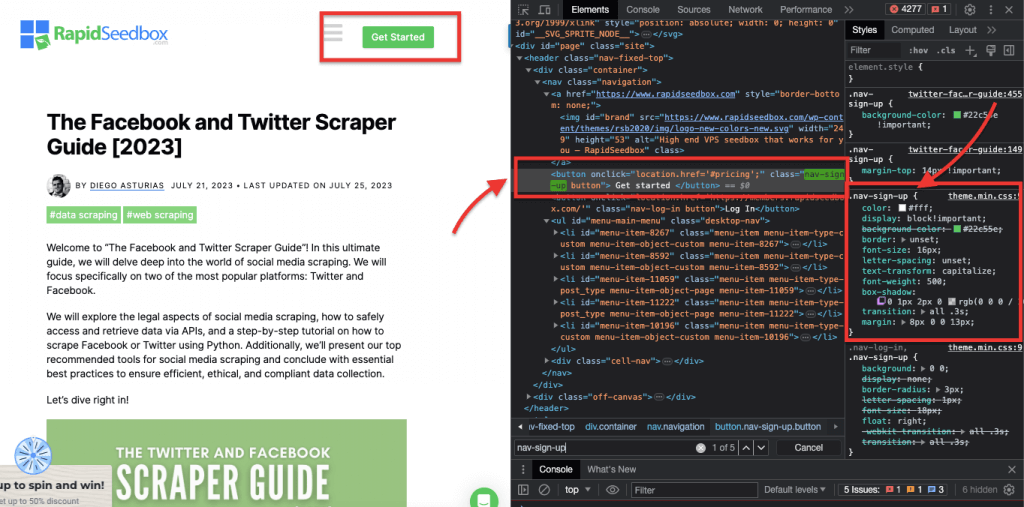
iv. Attribute Matching.
This technique involves selecting HTML elements based on specific attributes and their values. It allows you to target elements that have a particular attribute or attribute value. There are different types of attribute matching, such as exact matching, substring matching, and more.
Example: The following example shows a custom attribute called data type. To target or style certain items (for example list items marked as “fruit”) you can use the CSS selector that selects elements based on their attribute values.
To scrape only the items marked as “fruit,” you can use the following CSS selector:

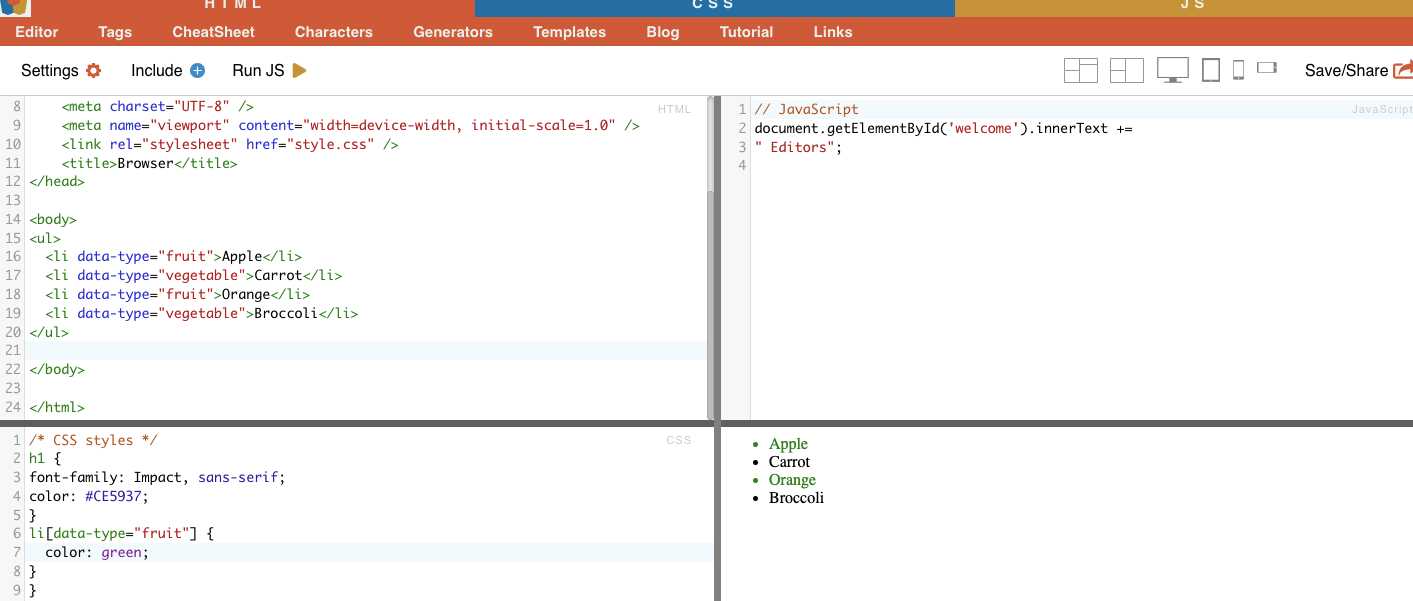
Real-Life Example: Manually searching for attributes.
c. Xpath Selectors:
CSS selectors are ideal for straightforward web scraping tasks where the HTML structure is relatively simple. But when the HTML structure gets more intricate and complex, there is another solution: XPath selectors.
XPath Selectors (XML Path Language Selectors) is a flexible path language used to navigate through the elements of an XML or HTML document. They help select specific nodes within the HTML code based on location, names, attributes, or content. XPath selectors can also be useful for targeting elements based on their class and ID attributes.
Here are three examples of XPath selectors for web scraping.
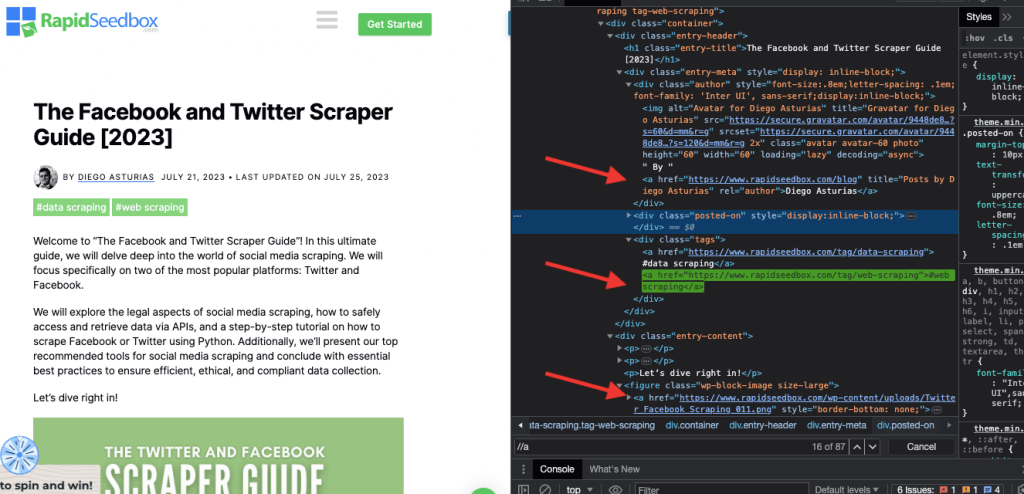
i. Example 1: XPath Expression: ‘ //a
The XPath expression ‘ //a’ selects all ‘< a >’ elements on the page, regardless of their location in the document. The following screenshot shows manually locating all ‘< a >’ elements on the page.
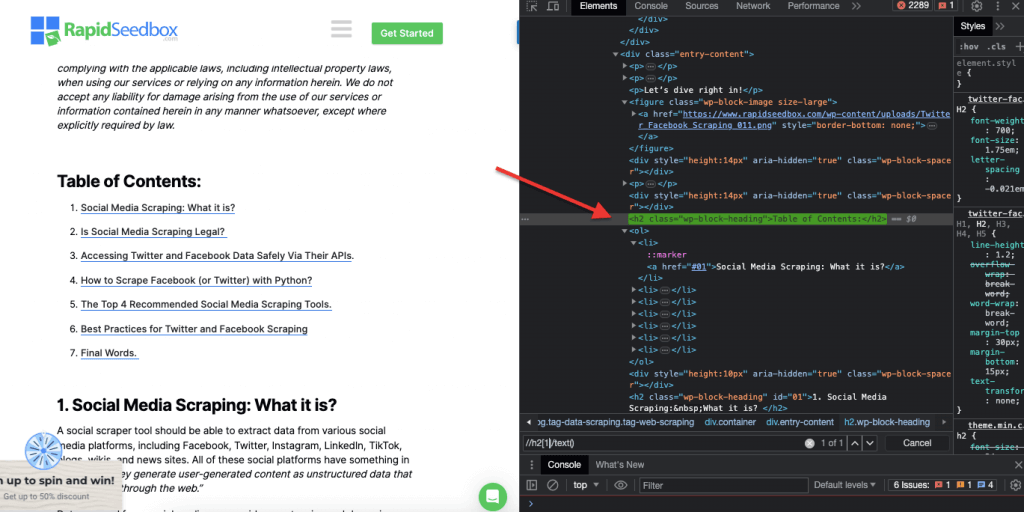
ii. Example 2: ’ //h2[1]/text()’
The XPath Expression:
‘ //h2[1]/text() ‘
It will select the text content of the first h2 heading on the page. The ‘[1]’ index is used to specify the first occurrence of the h2 element, you can also specify the second occurrence with ‘[2]’ index, and so forth. The following screenshot shows manually locating the first heading h2 on the page using this XPath selector.
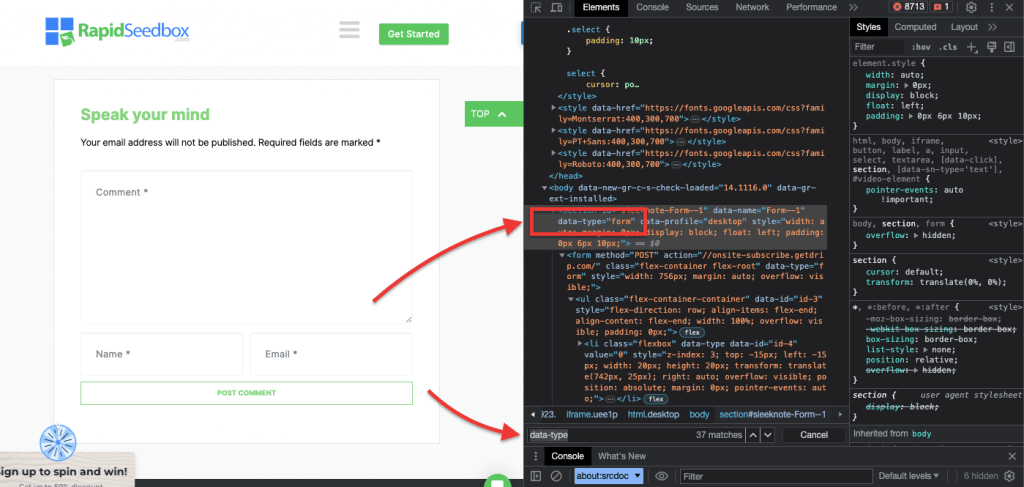
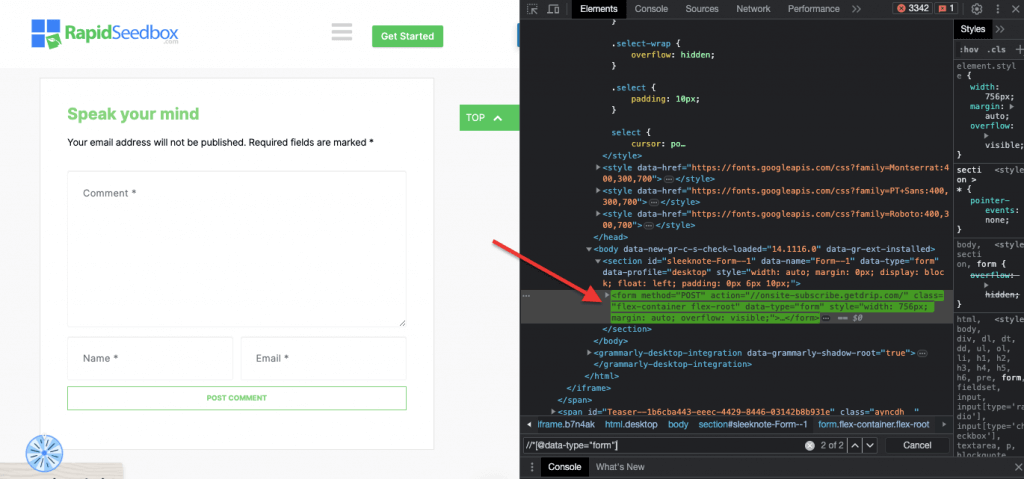
iii. Example 3. ‘ //* [@data-type=”form”]’
The XPath expression //* [@data-type="form"] selects all elements that have a data attribute with the value “form”. The * symbol indicates that any element with the specified data attribute will be selected, regardless of its node name. The following screenshot shows the process for manually locating the elements with the value “form”.
Visually inspecting and extracting data manually from an HTML page using these CSS and XPath selectors can be not only time-consuming but also prone to errors. In addition, manually or visually extracting data is completely unsuitable for large-scale data collection or repetitive scraping tasks. This is where scripting and programming is highly beneficial.
Boost your web scraping with fast, secure, and anonymous proxies from RapidSeedbox.
What are the best programming languages for web scraping?
The most popular programming language for scraping is Python due to its libraries and packages (more on this in the next section.) Another popular programming language for web scraping is R, as this also has a fantastic set of supported libraries and frameworks. Additionally, it is also worth mentioning C# – a popular programming language many web scrapers utilize. Websites such as ZenRows have comprehensive guides on how to scrape a website in C#, which makes it easier for developers to understand the process and start their own projects.
For the sake of simplicity, this web scraping guide will focus on web scraping with Python. Keep on reading!
3. Web Scraping with Python (with Code).
Why would you visually inspect and manually extract HTML data using CSS selectors or XPath selectors when you can use them in a systematic and automatic way with programming languages?
There are many popular web scraping libraries and frameworks that support CSS selectors for easier data extraction. One of the most popular programming languages for web scraping is Python, for its libraries like BeautifulSoup, Requests, CSS-Select, Selenium, và Scrapy. These libraries enable web scrapers to leverage CSS and XPath selectors to extract data efficiently.
BeautifulSoup.
BeautifulSoup is one of the most popular and powerful Python packages designed to parse HTML and XML documents. This package creates a parse tree of the pages, enabling you to easily extract data from HTML.
| Sự thật thú vị! In the fight against COVID-19, Jiabao Lin’s DXY-COVID-19-Crawler used BeautifulSoup to extract valuable data from a Chinese medical website. By doing so, it helped researchers in monitoring and understanding the spread of the virus. [Source] |
Requests.
Python’s Requests is a simple yet powerful HTTP library. It is useful for making HTTP requests to retrieve data from websites. “Requests” simplifies the process of sending HTTP requests and handling responses in your web scraping Python project.
a. Tutorial for Web Scraping with Python (+ Code)
In this tutorial for web scraping with Python, we will get data from a target HTML website using Python code with the “requests” and the BeautifulSoup library.
Điều kiện tiên quyết:
Ensure the following prerequisites are met:
- Python environment: Make sure you have Python installed on your computer. Also, ensure that you can run the script in your preferred Python environment (e.g., IDLE hoặc Jupyter Notebook).
- Requests Library: Install the
requestslibrary. It is used to send HTTP GET requests to the specified URL. You can install it usingpipby runningpip install requestsin your command prompt or terminal. - BeautifulSoup Library: Install the
beautifulsoup4library. You can install it usingpipby runningpip install beautifulsoup4in your terminal.
The Python code for web scraping data from a page (w/ BeautifulSoup)
The following script will fetch the specified URL, parse the HTML content using BeautifulSoup, and print the titles of the top news articles on the webpage.

When running, the script on IDLE Shell, the screen prints out all gathered “news_titles” from the targeted website.

b. Variations to our Python code for web scraping.
We can take our previous web scraping Python code and do some variations to scrape different types of data.
Ví dụ:
- Finding Images: To find all image tags (< img >) on the webpage, you can use the find_all() method with the tag name ‘img’:

- Finding Links: To find all anchor tags (< a >) that represent links on the webpage, you can use the find_all() method with the tag name ‘a’:

The script provided (along with variations) is a basic web scraping script. It simply extracts and prints the titles of the top news articles from the specified URL. But, unfortunately, this simple script lacks a lot of features that make up a more comprehensive web scraping project. There are several elements that you might want to consider adding data storage, error handling, pagination/crawling, user-agent and headers usage, throttling and politeness measures, and the ability to handle dynamic content.
4. Is Web Scraping Legal?
Web scraping is generally perceived as controversial or illegal. But in reality, it is a legitimate practice that if adhered to certain ethical and legal boundaries, web scraping is perfectly legal.
The legality of web scraping depends on the nature of the data being extracted and the methods used. Web scraping is considered lawful when it is used to gather publicly available information from the internet. However, caution is always needed especially when dealing with personal data or copyrighted content.
Here are a few pointers to keep in mind:
- Do not scrape private data. It is also unlawful to extract data that is not publicly available. Scraping data behind a login page, with user and password login, is against the law in the US, Canada, and most of Europe.
- What you do with the data is what can get you into trouble. Ethical web scraping entails being mindful of the data being collected and its intended purpose. Special attention should be given to personal data and intellectual property. Ensure you are complying with regulations like GDPR and CCPA, which govern the handling of personal data. For example, reusing or reselling content or downloading copyrighted material is illegal (and should be avoided).
- It is also essential to review the Terms of Service on websites. These are documents that direct anyone using their service or content to how they should and shouldn’t interact with the resources.
- Always ensure alternatives like using officially provided APIs. Some websites like Government agencies, Weather, and Social media platforms make some of their data accessible to the public via APIs.
- Consider checking the robots.txt file. This file is saved on the web server and gives directions to web crawlers and web scraping about what parts of a website to avoid and what parts are authorized. It also gives directions about the rate limits.
- Avoid initiating web scraping attacks. Depending on the context, sometimes web scraping is referred to as a scraping attack. When spammers use botnets (armies of bots) to target a website with large and fast requests, the entire website’s service may fail. Large-scale data scrapings may bring entire sites down.
Recent news about the legal aspects of web scraping.
Recent legal rulings have clarified that scraping publicly available data is generally not considered a violation. A landmark ruling by the US appeals court reaffirmed the legality of web scraping, stating that scraping publicly accessible data on the internet does not breach the Computer Fraud and Abuse Act (CFAA) [source: TechCrunch].
Trong một diễn biến khác, các vụ kiện gần đây chống lại OpenAI và Microsoft làm dấy lên lo ngại về quyền riêng tư, sở hữu trí tuệ và luật chống tấn công mạng, theo tin tức gần đây.Bloomberg]. While the CFAA has limited effectiveness, breach-of-contract claims and state privacy laws are being explored. The interaction between copyright and contract law remains unresolved, leaving many questions unanswered in the context of web scraping.
In the latest news, [source: IndiaTimes] Elon Musk is changing Twitter rules to prevent extreme levels of data scraping. According to Musk, extreme web scraping negatively impacts user experience. He suggested that organizations using large language models for generative AI were to blame.
5. How Do Websites Attempt to Block Web Scraping?
Companies want some of their data to be accessible to human visitors. But when companies or users use automated scripts or bots to aggressively extract data from the site, there may be much privacy and resource abuse on a target web server and page. These victim sites prefer to deter this type of traffic.
Anti-Scraping Techniques.
- Unusual and high amounts of traffic from a single source. Web servers may use WAFs (Web Application Firewalls) with blacklists of noisy IP addresses to block traffic, filters on “unusual” rates and sizes of requests, and filtering mechanisms. Some sites use a combination of WAF and CDN (Content Delivery Networks) to filter entirely or reduce the noise from such IPs.
- Some websites can detect bot-like browsing patterns. Similar to the previous technique, websites also block requests based on User-Agent (HTTP header). Bots do not use a regular browser. These bots have different user-agent strings (i.e., crawler, spider, or bot), a lack of variation, an absence of headers (headless browsers), request rates, and more.
- Websites also change their HTML markup often. Web scraping bots follow a consistent “HTML markup” route when traversing the content of a website. Some websites change HTML elements within the markup regularly and randomly. This technique throws a bot off of its regular scraping habit or schedule. Changing the HTML markup doesn’t stop web scraping but makes it far more challenging.
- The use of challenges like the CAPTCHA. To avoid bots using headless browsers, some websites require CAPTCHA challenges. Bots using headless browsers have a hard time solving these types of challenges. CAPTCHAs were made to be solved at a user level (via browser) and not by robots.
- Some sites are traps (honeypots) for scraping bots. Some websites are created only for trapping scraping bots— this is a technique referred to as honeypots. These honeypots are only visible by scraping bots (not by ordinary human visitors) and are built to lead web scrapers into a trap.
6. Ethical and Best Practices for Web Scraping.
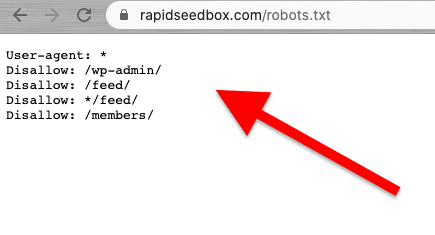
Web scraping should be done responsibly and ethically. As mentioned before, reading the Terms and Conditions or ToS should give you an idea of the restrictions you must adhere to. If you want to get an idea of the rules for a web crawler, check its ROBOTS.txt.
If web scraping is entirely disallowed or blocked, use their API (if it is available).
Also, be mindful of the target’s website bandwidth to avoid overloading a server with too many requests. Automating requests with a rate and right timeouts to avoid putting a strain on the target server is crucial. Simulating a real-time user should be optimal. Also, never scrape data behind login pages.
Follow the rules, and you should be ok.
Web Scraping Best Practices.
- Use a Proxy. A proxy is an intermediary server that forwards requests. When web scraping with a proxy, you are routing your original request through it. So, the proxy maps the request with its own IP and forwards it to the target website. Use a proxy to:
- Eliminate the chances of getting your IP blacklisted or blocked. Always make requests through various proxies— IPv6 proxies are a good example. A proxy pool can help you perform larger volume requests without being blocked.
- Bypass geo-tailored content. A proxy in a specific region is useful for scraping data according to that particular geographical region. This is useful when websites and services are behind a CDN.
- Rotating Proxies. Rotating Proxies take (rotate) a new IP from the pool for every new connection. Bear in mind that VPNs are not proxies. Although they do something very similar, which is to provide anonymity, they work at different levels.
- Rotate UA (User Agents) and HTTP Request Headers. To rotate UAs and HTTP headers, you would need to collect a list of UA strings from real web browsers. Put the list in your web scraping code in Python and set requests to pick random strings.
- Don’t push the limits. Slow down the number of requests, rotate, and randomize. If you are making a large number of requests for a website, start by randomizing things. Make each request seem random and human-like. First, change the IP of each request with the help of rotating proxies. Also, use different HTTP headers to make it look like the requests are coming from other browsers.
Boost your web scraping with fast, secure, and anonymous proxies from RapidSeedbox.
7. Web Scraping FAQ: Frequently Asked Questions.
a. What is robots.txt and what role does it play in web scraping?
Về robots.txt file serves as a communication tool between website owners, web crawlers, and “scrapers.” It is a text file placed on a website’s server that provides instructions to web robots (crawlers, web spiders, and other automated bots) about which parts of the website they are allowed to access and scrape, and which parts they should avoid. “Well-behaved” web crawlers (like Googlebot) are designed to automatically read the robots.txt. Scrapers are not designed to read this file. So, being aware of the robots.txt is highly important in order to respect the website owner’s wishes.
b. What techniques do website admins use in order to avoid “abusive” or “unauthorized” web scraping attempts?
Not all scrapers extract data ethically and legally. They do not follow the site’s TOS (Terms Of Service) or the robots.txt guidelines. So website admins may take additional measures to protect their data and resources, such as using IP blocking or CAPTCHA challenges. They may also use rate-limiting measures, user-agent verification (to identify potential bots), track sessions, use token-based authentication, use CDN (Content Delivery Networks), or even use behavior-based detection systems.
c. Web Scraping vs. Web Crawling?
Although web scraping and web crawling are both web data extraction techniques, they have different purposes, scopes, automation, and legal aspects. On the one hand, web scraping techniques aim to extract specific data from particular sites. They are targeted and have a specific, limited scope. Web scraping uses automated scripts or third-party tools to request, receive, parse, extract, and structure data. Web crawling techniques (like list crawling), on the other hand, are used to systematically search the web. They are popular among search engines (broader scope), social media platforms, researchers, content aggregators, etc. Web crawlers can visit many sites automatically (via bots, crawlers, or spiders), build a list, index data (create a copy), and store it in a database. Web crawlers usually check the ROBOTS.txt files.
d. Data mining vs Data scraping: What are their differences and similarities?
Both data mining and data scraping involve data extraction. However, data mining focuses on using statistical and machine-learning techniques to analyze structured data sets. It aims to identify patterns, relationships, and insights within large and complex structured data sets. Data scraping, on the other hand, focuses on “the gathering part” of specific information from web pages and websites. Both techniques and tools can be used together. Web scraping can be a preliminary step to gather data from the web, which is then fed into data mining algorithms for in-depth analysis and insight discovery.
e. What is Screen Scraping? And how does it relate to Data Scraping?
Both techniques focus on data extraction but differ in the type of data they extract. Screen scraping tools aim to “automatically” capture and extract visual data displayed on websites and documents, including screen text. Unlike web scraping, which parses data from HTML (thus extracting a wide range of web data), screen scraping reads text data directly from the screen display.
f. Is Web Harvesting the same as Web Scraping?
Data scraping and web harvesting are strongly related and often used interchangeably, but they are not the same concept. Web harvesting has a broader connotation. It encompasses different methods of extracting data from the web, including various automatic web extraction mechanisms, like web scraping. A clear distinction is that web harvesting is often used when an API is involved, rather than directly parsing HTML code from web pages (as web scraping does).
g. CSS Selector vs XPath Selector: What are the differences when scraping?
CSS selectors are an efficient way to extract data during web scraping. They offer a straightforward syntax and work well in most scraping scenarios. However, in more complex cases or when dealing with nested structures, XPath selectors can provide additional flexibility and functionality.
h. How to handle dynamic websites with Selenium?
Selenium is a powerful tool for web scraping dynamic websites. It allows you to interact with elements on the webpage as a human user would. This ability enables your “script” to navigate through dynamically generated content. By using Selenium’s WebDriver, you can wait for page elements to load, interact with AJAX elements, and scrape data from websites that heavily rely on JavaScript.
i. How to deal with AJAX and JavaScript while Web Scraping?
When dealing with AJAX and JavaScript during web scraping, traditional libraries like Requests and Beautiful Soup might not be sufficient. To handle AJAX requests and JavaScript-rendered content, you can use tools like Selenium or headless browsers such as Puppeteer.
8. Lời kết.
Congratulations! You completing the ultimate guide to web scraping!
We hope this guide has equipped you with the knowledge and tools to harness the potential of web scraping for your projects.
Remember, with great power comes great responsibility. As you begin your journey on web scraping, always prioritize ethical practices, respect websites’ terms of service, and be mindful of data privacy.
We touched the tip of the iceberg. Web Scraping can be quite a comprehensive topic. But hey, you have already scraped a website!
Continuous learning and staying up-to-date with the latest technologies and legal developments will enable you to navigate this complex world.
Visually inspecting and extracting data manually from an HTML page using these CSS and XPath selectors can be not only time-consuming but also prone to errors. In addition, manually or visually extracting data is completely unsuitable for large-scale data collection or repetitive scraping tasks. This is where scripting and programming is highly beneficial.
01 bình luận