In this ultimate guide, we will explore the world of web scraping, a powerful technique to extract data from websites. rat
سواء أكنت مبتدئًا لديه فضول لمعرفة هذا المفهوم أو مبرمجًا متمرسًا يتطلع إلى تعزيز مهاراتك، فإن هذا الدليل يحتوي على شيء قيّم للجميع. بدءًا من فهم أساسيات استخراج بيانات HTML باستخدام CSS و XPath إلى التدريب العملي على تجريف الويب باستخدام Python، سنقوم بتغطيتك. بالإضافة إلى ذلك، سنتناول الجوانب القانونية، والاعتبارات الأخلاقية، وأفضل الممارسات لضمان تجريف الويب بشكل مسؤول.

تنويه: تم تطوير هذاه المادة لأغراض معلوماتية فقط، وهي لا تشكل تأييدًا لأي أنشطة (بما في ذلك الأنشطة غير القانونية) أو منتجات أو خدمات. أنت وحدك مسؤول بشكل كامل عن الامتثال للقوانين المعمول بها، بما في ذلك قوانين حماية الملكية الفكرية، عند استخدام خدماتنا أو الاعتماد على أي معلومات هنا. نحن لا نتحمل أي مسؤولية عن الضرر الناشئ عن استخدام خدماتنا أو المعلومات الواردة هنا بأي شكل من الأشكال، إلا في الحالات التي يُشترط فيها وجود ذلك صراحة بموجب القانون.
جدول المحتويات.
- ما هو مسح الويب وكيف يعمل؟
- أساسيات استخراج بيانات HTML: محددات CSS و XPath.
- كشط الويب باستخدام بايثون (+ كود).
- هل تجزئة الويب قانونية؟
- كيف تحاول المواقع الإلكترونية حظر تجريف الويب؟
- الممارسات الأخلاقية والممارسات الفضلى لكشط الويب.
- كشط الويب: الأسئلة المتداولة (FAQ)
- كلمات أخيرة
1. ما هو مسح الويب وكيف يعمل؟
كشط الويب (المعروف أيضًا باسم حصاد الويب أو استخراج البيانات) هو عملية استخراج البيانات تلقائيًا من مواقع الويب وخدمات الويب وتطبيقات الويب.
تساعدنا عملية كشط الويب على توفير الاضطرار إلى الدخول إلى كل موقع إلكتروني وسحب البيانات يدويًا - وهي عملية طويلة وغير فعالة. تتضمن العملية استخدام نصوص أو برامج نصية أو برامج آلية. يصل البرنامج النصي أو البرنامج النصي إلى بنية HTML لصفحة الويب، ويحلل البيانات، ويستخرج العناصر المحددة المطلوبة من الصفحة لمزيد من التحليل.
a. فيمَ يُستخدم مسح الويب؟
يعد كشط الويب أمرًا رائعًا إذا تم القيام به بشكل مسؤول. بشكل عام، يمكن استخدامه بشكل عام في البحث في الأسواق، مثل اكتساب رؤى ومعرفة الاتجاهات في سوق معينة. كما أنه شائع أيضًا في مراقبة المنافسين لتتبع استراتيجيتهم وأسعارهم وما إلى ذلك.
حالات الاستخدام الأكثر تحديداً هي:
- المنصات الاجتماعية (كشط فيسبوك وتويتر)
- مراقبة تغير الأسعار عبر الإنترنت,
- مراجعات المنتج,
- حملات تحسين محركات البحث,
- قوائم العقارات,
- تتبع بيانات الطقس,
- تتبع سمعة الموقع الإلكتروني,
- مراقبة توافر رحلات الطيران وأسعارها,
- اختبار الإعلانات، بغض النظر عن الموقع الجغرافي,
- مراقبة الموارد المالية,
b. كيف يعمل كشط الويب؟
العناصر النموذجية المشاركة في كشط الويب هي البادئ والهدف. يستخدم البادئ (كاشط الويب) برنامج استخراج البيانات التلقائي لكشط المواقع الإلكترونية. أما الأهداف، من ناحية أخرى، فهي بشكل عام محتوى الموقع الإلكتروني، أو معلومات الاتصال، أو النماذج، أو أي شيء متاح للجمهور على الويب.
تتم العملية النموذجية على النحو التالي:
- الخطوة 1: يستخدم البادئ أداة الكشط - برنامج (يمكن أن يكون إما خدمة قائمة على السحابة أو برنامج نصي محلي الصنع) لبدء توليد طلبات HTTP (تُستخدم للتفاعل مع مواقع الويب واسترداد البيانات). يمكن لهذا البرنامج بدء أي شيء بدءًا من HTTP GET أو POST أو POST أو PUT أو DELETE أو HEAD، إلى طلب OPTIONS إلى موقع ويب مستهدف.
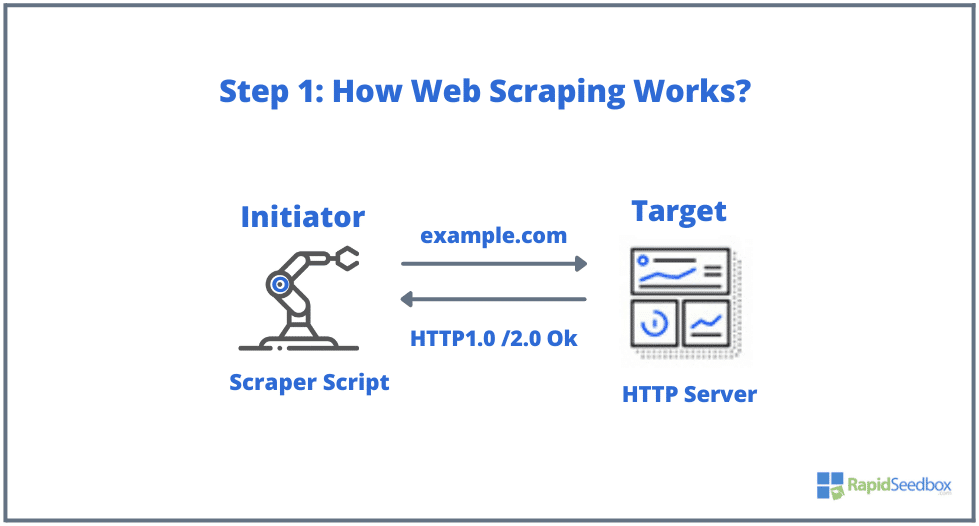
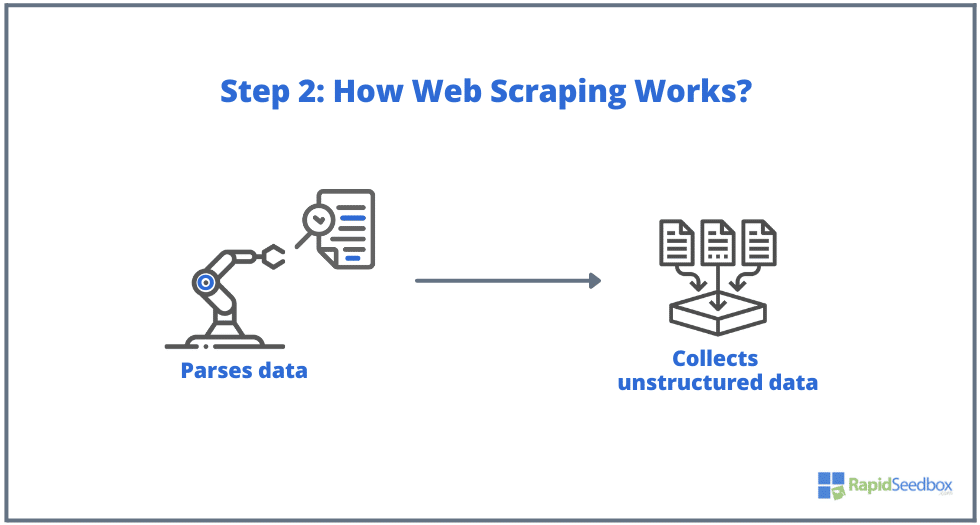
- الخطوة 2. إذا كانت الصفحة موجودة، فإن الموقع المستهدف سيستجيب لطلب الكاشطة ب HTTP/1.0 200 OK (الاستجابة النموذجية للزوار.) عندما تتلقى الكاشطة استجابة HTML (على سبيل المثال 200 OK)، ستشرع بعد ذلك في تحليل المستند وجمع بياناته غير المنظمة.
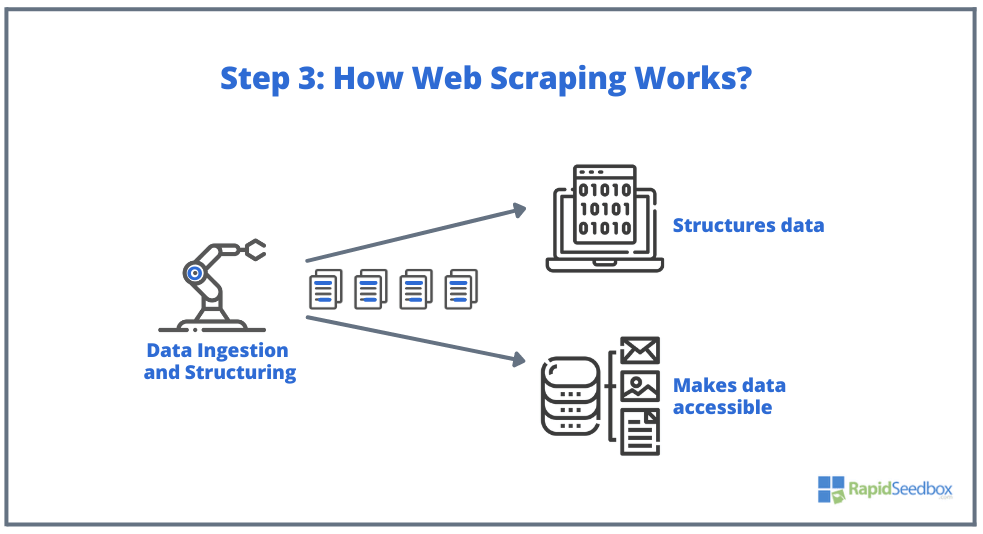
- الخطوة 3. يقوم برنامج الكاشطة بعد ذلك باستخراج البيانات الخام وتخزينها وإضافة بنية (فهارس) للبيانات إلى ما حدده البادئ. يمكن الوصول إلى البيانات المنظمة من خلال تنسيقات قابلة للقراءة مثل XLS أو CSV أو SQL أو XML.
2. أساسيات استخراج بيانات HTML: محددات CSS و XPath.
قد تكون تعرف الأساسيات بالفعل: يتضمن كشط الويب استخراج البيانات من مواقع الويب، ويبدأ كل ذلك باستخدام HTML-العمود الفقري لصفحات الويب. داخل ملف HTML، ستجد في ملف HTML فئات ومعرفات وجداول وقوائم وكتل أو حاويات - جميع العناصر الأساسية التي تشكل بنية الصفحة.
أما CSS فهي لغة ورقة أنماط تُستخدم للتحكم في عرض وتخطيط مستندات HTML. وهي تحدد كيفية عرض عناصر HTML على صفحة الويب، مثل الألوان والخطوط والهوامش وتحديد المواقع. يلعب CSS دورًا رئيسيًا في كشط الويب، حيث يساعد في استخراج البيانات من العناصر المطلوبة.
ملاحظة: الشرح الكامل لماهية HTML و CSS بالتفصيل وكيفية عملهما، خارج نطاق هذه المقالة. نفترض أن لديك بالفعل المهارات الأساسية ل HTML و CSS.
في حين أنه قد يكون من الممكن استخراج البيانات مباشرةً من HTML الخام باستخدام تقنيات مختلفة مثل التعبيرات العادية، إلا أن ذلك قد يستغرق وقتًا طويلاً وصعبًا حقًا. نظرًا لأن لغة HTML المهيكلة مصممة لتكون "قابلة للقراءة آليًا"، يمكن أن تصبح معقدة ومتنوعة حقًا. هذا هو المكان الذي تلعب فيه محددات CSS و XPath دورًا رئيسيًا.
a. تجميع وفحص HTML.
في القسم التالي، سنقدم بعض الأمثلة على محددات CSS و XPath (تم تجميعها وفحصها). تم تجميع جميع أمثلة HTML و CSS التالية باستخدام المحرر عبر الإنترنت HTML-CSS-JSS.
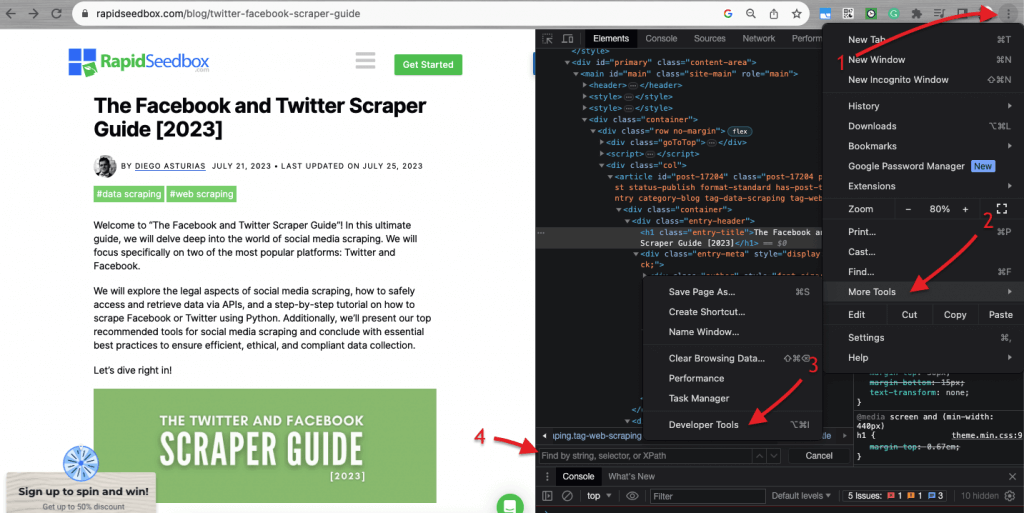
عندما يتعلق الأمر بفحص كود HTML في المواقع الإلكترونية, تأتي متصفحات الويب مزودة بأدوات المطورين، بحيث يمكنك فحص HTML أو CSS المتاح للعامة على أي موقع ويب. يمكنك النقر بزر الماوس الأيمن على صفحة ويب واختيار "فحص" أو "فحص العنصر" أو "فحص المصدر". للحصول على مقارنة ديناميكية أفضل للصفحة والشفرة جنبًا إلى جنب، في متصفح كروم > انتقل إلى النقاط الثلاث في أعلى اليسار (1) > المزيد من الأدوات (2) > أدوات المطور (3).
تأتي أدوات المطور مع فلتر بحث مفيد (4) يسمح لك بالبحث حسب السلسلة أو المحدد أو XPath. على سبيل المثال، سنقوم بكشط بعض البيانات من: https://www.rapidseedbox.com/blog/twitter-facebook-scraper-guide.
b. محددات CSS:
محددات CSS هي أنماط تُستخدم لتحديد عناصر HTML لصفحة ويب واستهدافها. وهي مفيدة لكشط الويب (والتصميم) لأنها توفر طريقة أكثر كفاءة واستهدافًا للحصول على البيانات من مستندات HTML. في حين أنه من الممكن استخراج البيانات مباشرةً من HTML الخام باستخدام تقنيات مختلفة مثل التعبيرات العادية، إلا أن محددات CSS تقدم العديد من المزايا التي تجعلها الخيار المفضل لكشط الويب.
تقنيات استهداف عناصر HTML واختيارها داخل صفحة ويب:
i. اختيار العقدة.
اختيار العقدة هي عملية اختيار عناصر HTML بناءً على أسماء العقد الخاصة بها. على سبيل المثال، اختيار جميع العناصر "p" أو جميع العناصر "a" في الصفحة. تتيح لك هذه التقنية استهداف أنواع محددة من العناصر في مستند HTML.

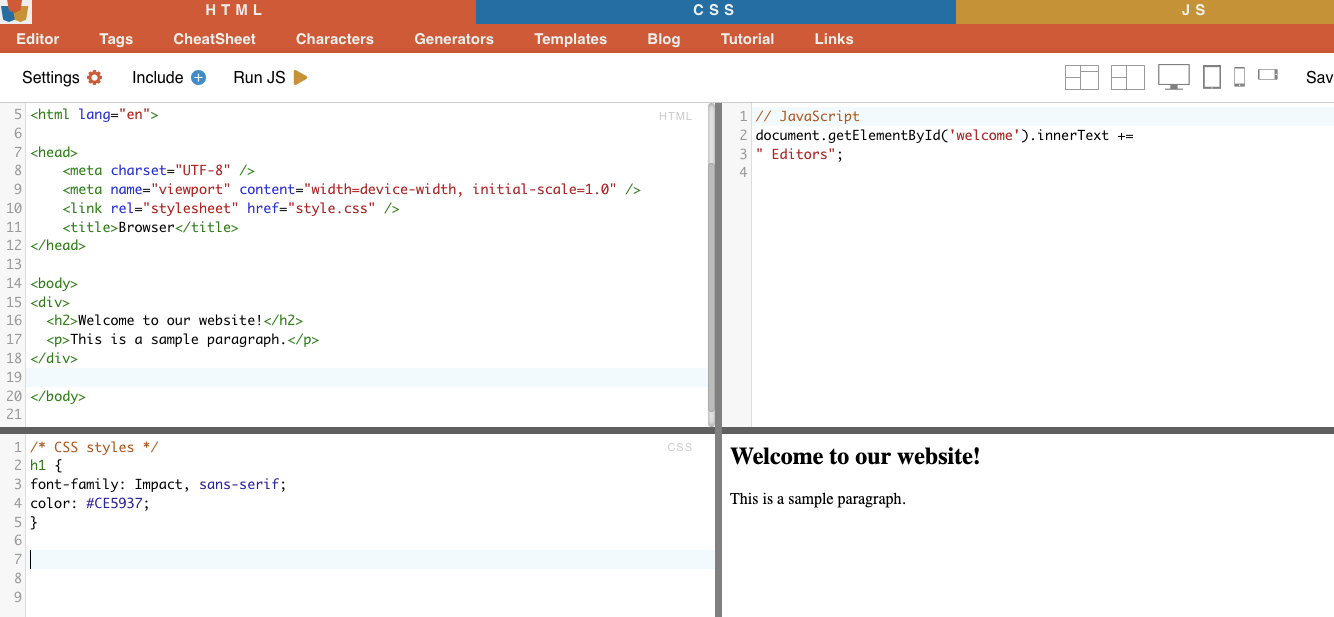
مثال من واقع الحياة الواقعية: البحث يدوياً عن H2s.
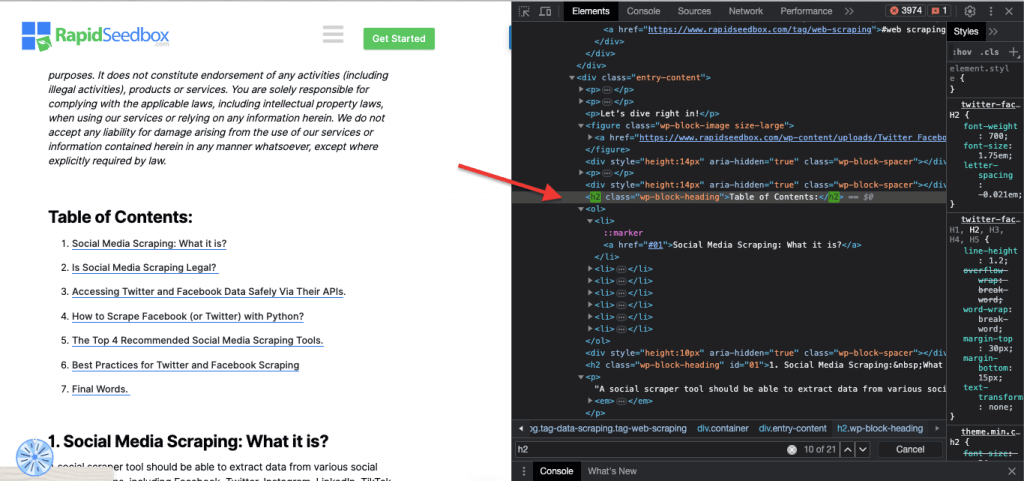
ii. الفصل.
في محددات CSS، يتضمن تحديد الفئة تحديد عناصر HTML استنادًا إلى سمة الفئة المعينة لها. تسمح لك سمة الفئة بتطبيق اسم فئة معينة على عنصر واحد أو أكثر. بالإضافة إلى ذلك في أنماط CSS أو جافا سكريبت، يمكن تطبيقها على جميع العناصر التي تحمل تلك الفئة. من أمثلة أسماء "الفئات" الأزرار وعناصر النماذج وقوائم التنقل وتخطيطات الشبكة وغيرها.
مثال على ذلك: سيقوم محدد CSS التالي: "تمييز" بتحديد جميع العناصر التي تم تعيين سمة الفئة لها على "تمييز".


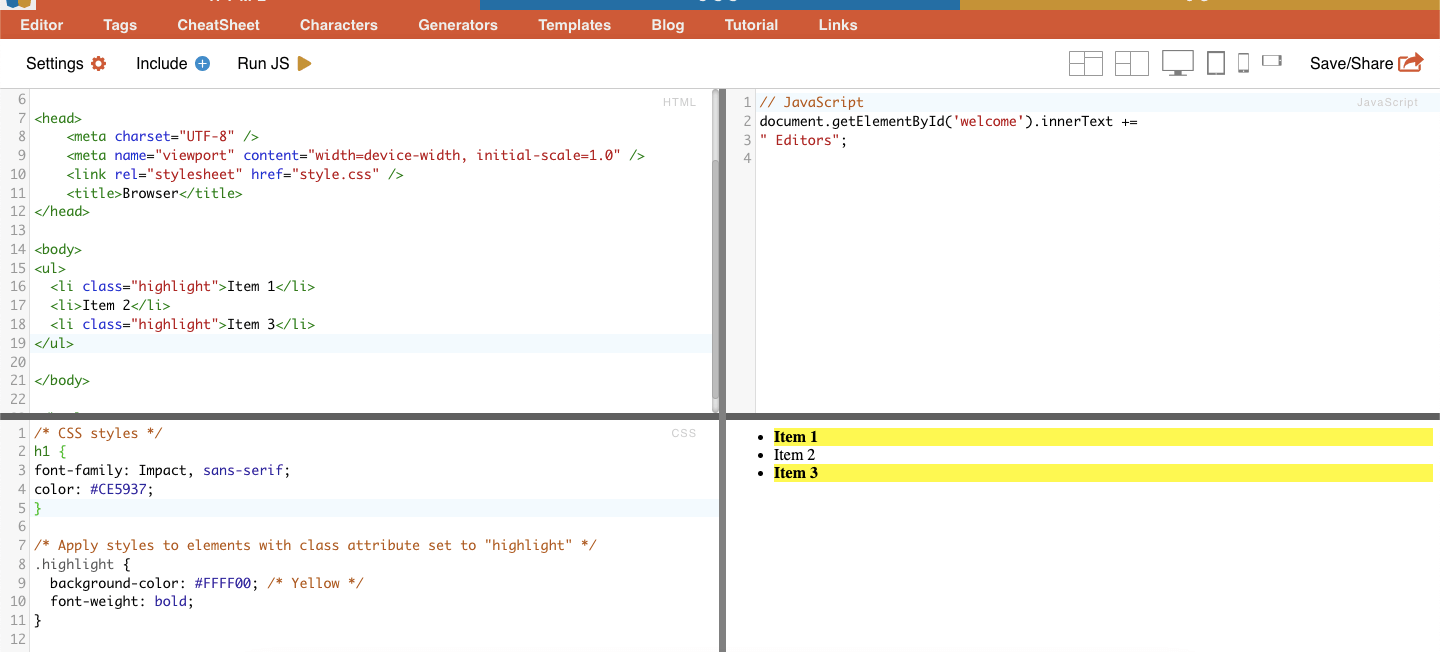
مثال من واقع الحياة الواقعية: البحث يدوياً عن الفصول الدراسية.
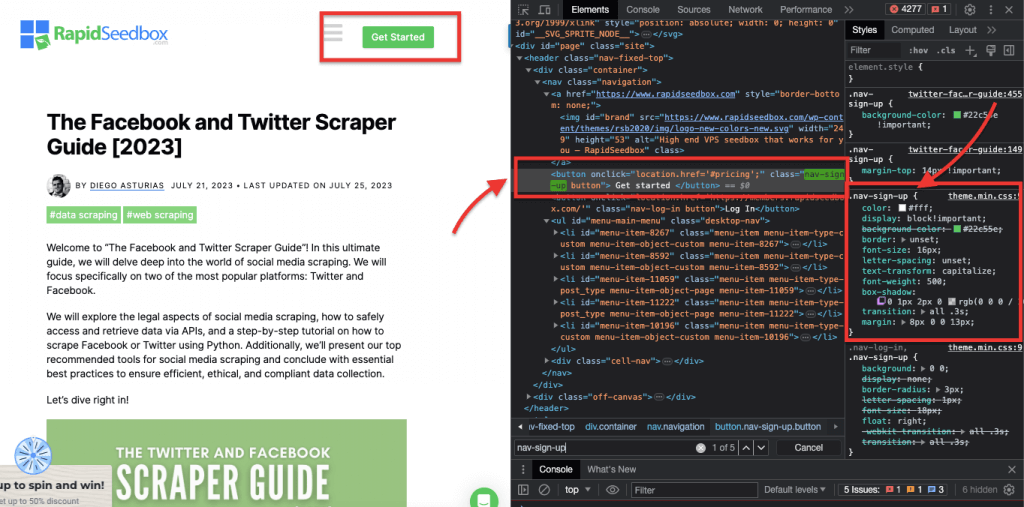
ثالثاً. قيود الهوية.
تساعد قيود المعرف في تحديد عنصر HTML بناءً على سمة المعرف الفريدة الخاصة به. تُستخدم سمة المعرف هذه لتعريف عنصر واحد على صفحة الويب بشكل فريد. على عكس الفئات التي يمكن استخدامها على عناصر متعددة، يجب أن تكون المعرفات فريدة داخل الصفحة.
مثال على ذلك: سيحدد محدد CSS "#header" العنصر الذي تم تعيين سمة المعرف له على "رأس".


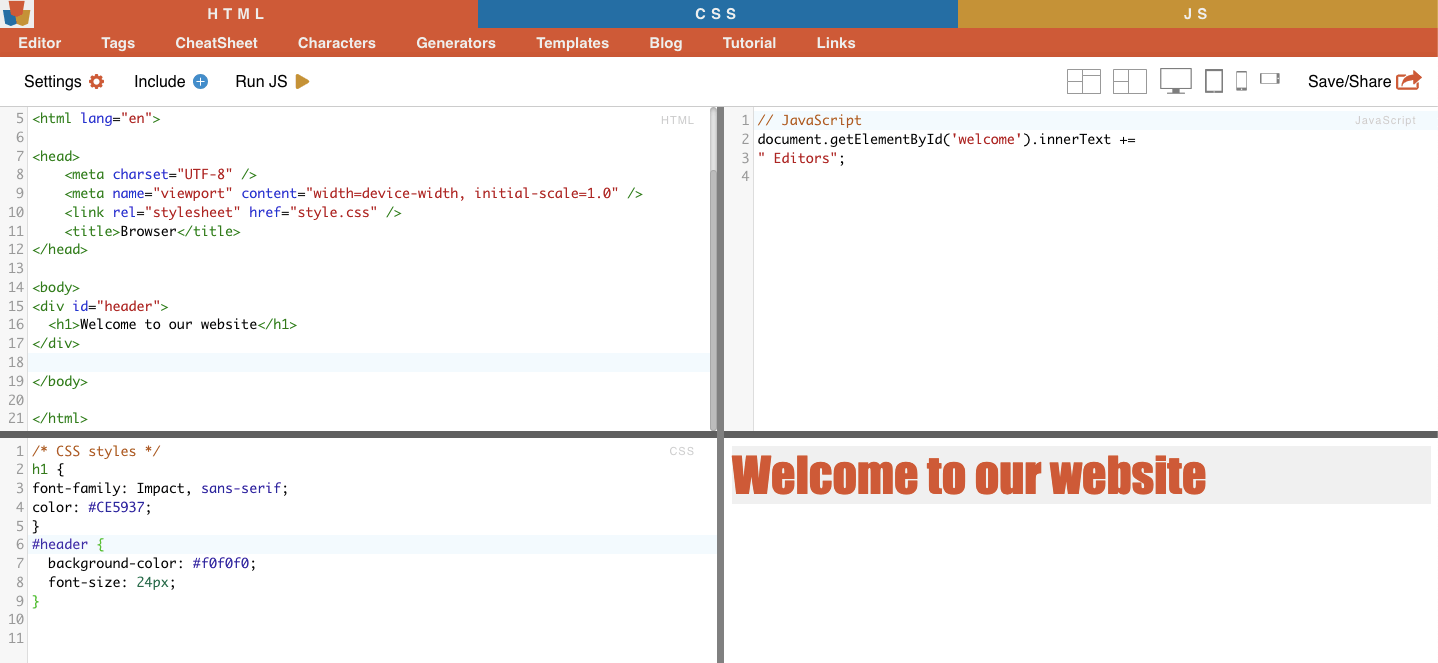
مثال واقعي: البحث يدوياً عن المعرفات. بعد العثور على #01 ستحتاج إلى تحديد موقع المعرف ="01
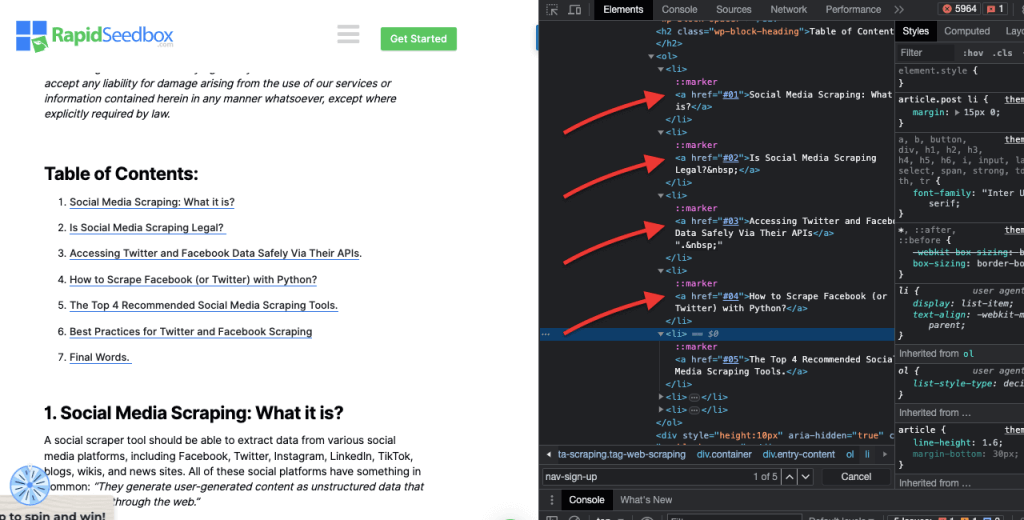
iv. مطابقة السمات.
تتضمن هذه التقنية تحديد عناصر HTML بناءً على سمات معينة وقيمها. تسمح لك باستهداف العناصر التي تحتوي على سمة أو قيمة سمة معينة. هناك أنواع مختلفة من مطابقة السمات، مثل المطابقة التامة ومطابقة السلسلة الفرعية وغيرها.
مثال على ذلك: يعرض المثال التالي سمة مخصصة تسمى نوع البيانات. لاستهداف عناصر معينة أو تصميم عناصر معينة (على سبيل المثال عناصر القائمة التي تحمل علامة "فاكهة") يمكنك استخدام محدد CSS الذي يحدد العناصر بناءً على قيم السمات الخاصة بها.
لكشط العناصر التي تحمل علامة "فاكهة" فقط، يمكنك استخدام محدد CSS التالي:

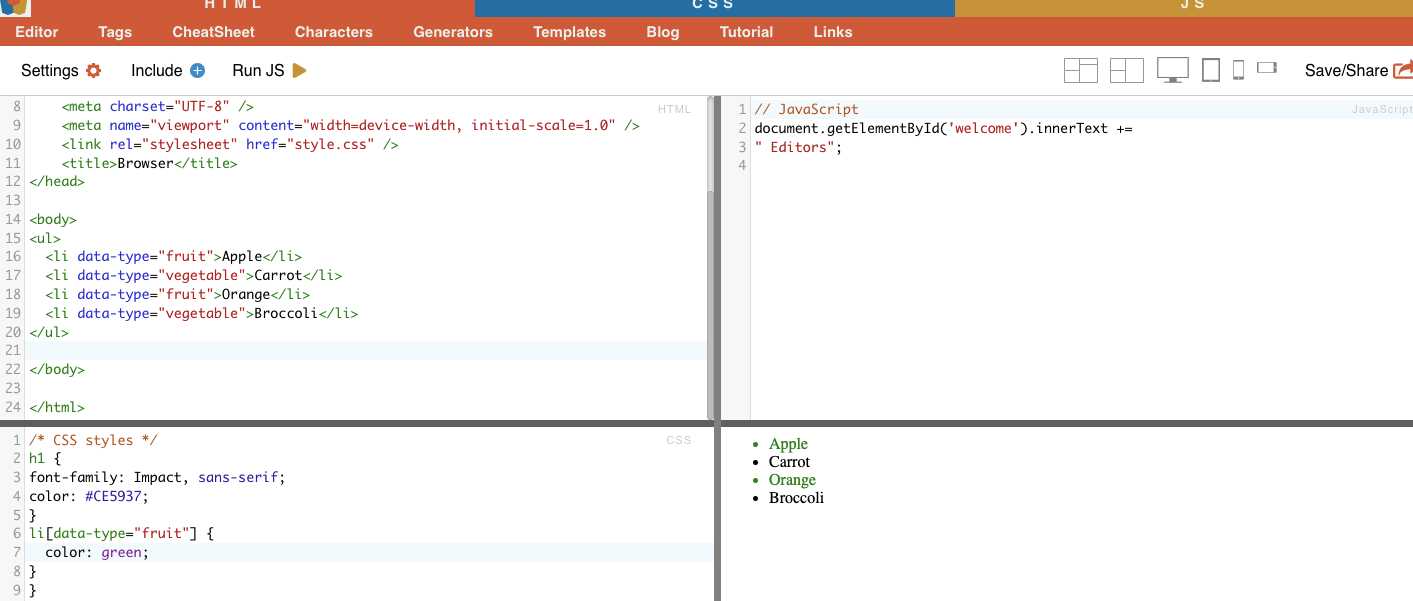
مثال من واقع الحياة الواقعية: البحث يدوياً عن السمات.
c. محددات Xpath:
تعتبر محددات CSS مثالية لمهام كشط الويب المباشرة حيث تكون بنية HTML بسيطة نسبيًا. ولكن عندما تصبح بنية HTML أكثر تعقيدًا وتعقيدًا، فهناك حل آخر: محددات XPath.
محددات XPath (محددات لغة مسار XML) هي لغة مسار مرنة تُستخدم للتنقل عبر عناصر مستند XML أو HTML. فهي تساعد في تحديد عقد محددة داخل كود HTML بناءً على الموقع أو الأسماء أو السمات أو المحتوى. يمكن أن تكون محددات XPath مفيدة أيضًا لاستهداف العناصر استنادًا إلى سمات الفئة والمعرف الخاصة بها.
فيما يلي ثلاثة أمثلة على محددات XPath لكشط الويب.
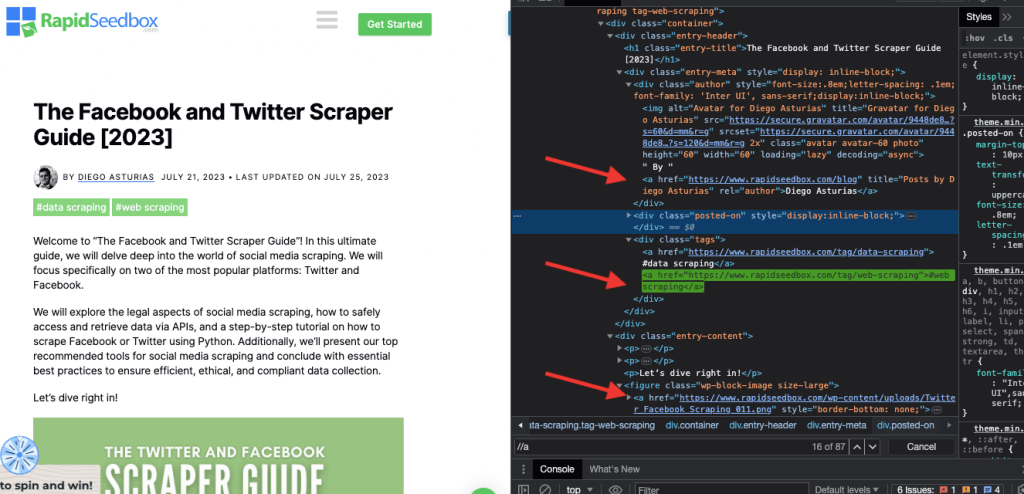
i. مثال 1: تعبير XPath: ' //a
يقوم تعبير XPath " //a" بتحديد جميع عناصر على الصفحة، بغض النظر عن موقعها في المستند. تُظهر لقطة الشاشة التالية تحديد موقع جميع عناصر يدويًا على الصفحة.
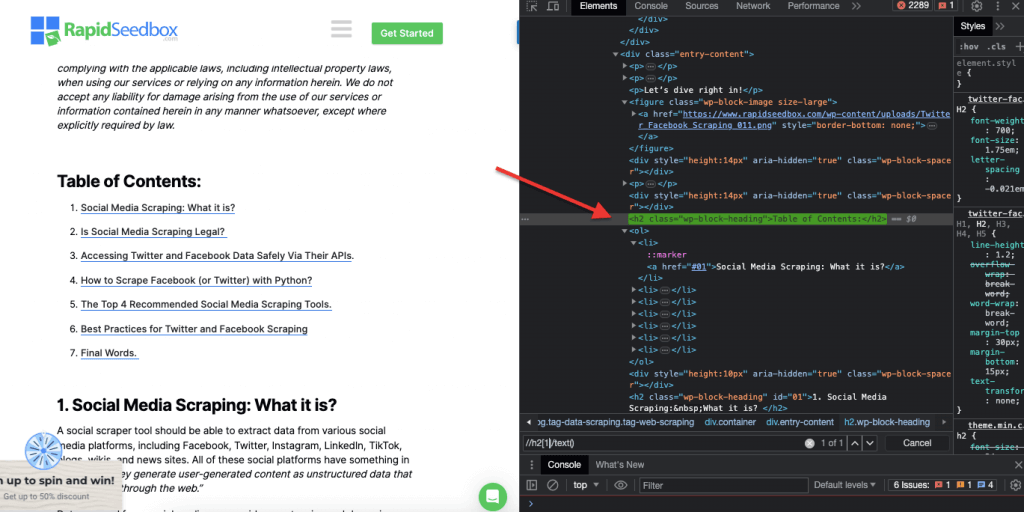
ii. المثال 2: " //h2[1]/ text()
تعبير XPath:
' //h2[1]/نص()
سيحدد المحتوى النصي للعنوان h2 الأول في الصفحة. يُستخدم فهرس "[1]" لتحديد التكرار الأول للعنصر h2، ويمكنك أيضًا تحديد التكرار الثاني باستخدام فهرس "[2]"، وهكذا دواليك. توضح لقطة الشاشة التالية تحديد موقع العنوان الأول h2 يدويًا على الصفحة باستخدام محدد XPath هذا.
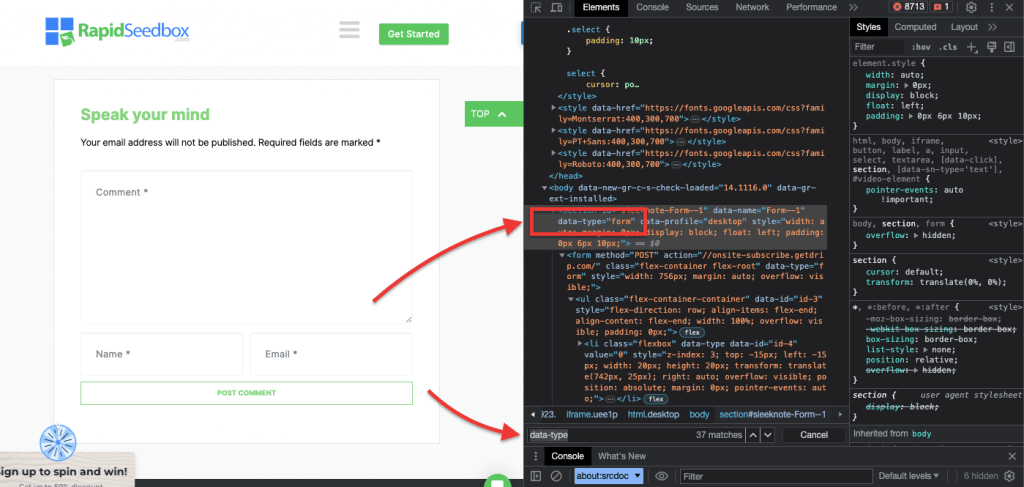
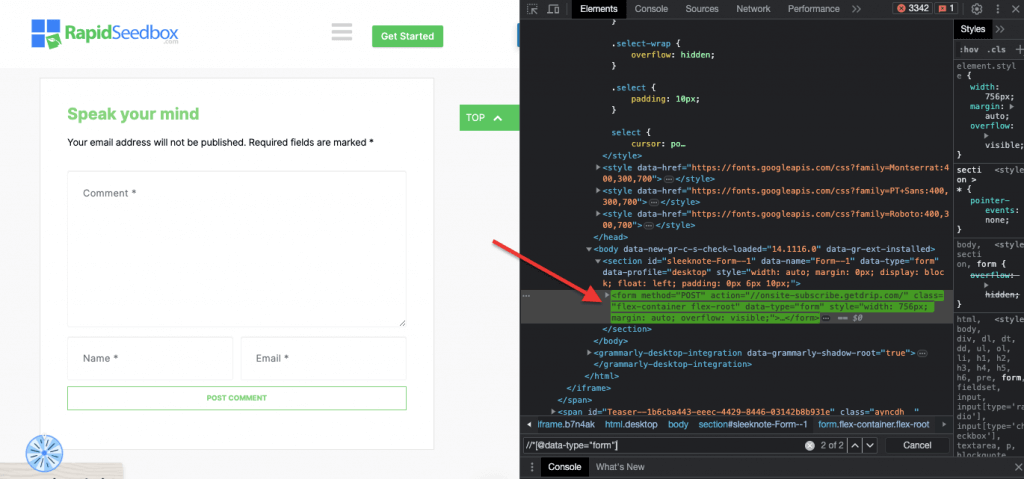
iii. مثال 3. ' //* [@* [@data-type="نموذج"]
تعبير XPath //* [@ [@data-type="نموذج"] جميع العناصر التي تحتوي على سمة بيانات بقيمة "نموذج". يتم تحديد * يشير الرمز إلى أنه سيتم تحديد أي عنصر يحتوي على سمة البيانات المحددة، بغض النظر عن اسم العقدة الخاصة به. تُظهر لقطة الشاشة التالية عملية تحديد موقع العناصر ذات القيمة "نموذج" يدويًا.
قد لا يكون الفحص البصري واستخراج البيانات يدويًا من صفحة HTML باستخدام محددات CSS و XPath هذه مستهلكًا للوقت فحسب، بل قد يكون عرضة للأخطاء أيضًا. بالإضافة إلى ذلك، فإن استخراج البيانات يدويًا أو بصريًا غير مناسب تمامًا لجمع البيانات على نطاق واسع أو مهام الكشط المتكررة. هذا هو المكان الذي تكون فيه البرمجة النصية والبرمجة مفيدة للغاية.
عزز عملية كشط الويب باستخدام وكلاء سريعين وآمنين ومجهولين من RapidSeedbox.
ما هي أفضل لغات البرمجة لكشط الويب؟
أكثر لغات البرمجة شيوعًا في مجال الكشط هي بايثون بسبب مكتباتها وحزمها (المزيد عن هذا في القسم التالي.) لغة برمجة أخرى شائعة في كشط الويب هو R، حيث يحتوي هذا أيضًا على مجموعة رائعة من المكتبات والأطر المدعومة. بالإضافة إلى ذلك، تجدر الإشارة أيضًا إلى C# - وهي لغة برمجة شائعة يستخدمها العديد من كاشطات الويب. تحتوي مواقع الويب مثل ZenRows على أدلة شاملة حول كيفية كشط موقع ويب في C#مما يسهل على المطورين فهم العملية وبدء مشاريعهم الخاصة.
من أجل التبسيط، سيركز دليل كشط الويب هذا على كشط الويب باستخدام Python. تابع القراءة!
3. كشط الويب باستخدام Python (مع التعليمات البرمجية).
لماذا قد تفحص بصريًا وتستخرج بيانات HTML يدويًا باستخدام محددات CSS أو محددات XPath بينما يمكنك استخدامها بطريقة منهجية وتلقائية باستخدام لغات البرمجة؟
هناك العديد من مكتبات وأطر عمل تجريف الويب الشائعة التي تدعم محددات CSS لتسهيل استخراج البيانات. واحدة من أكثر لغات البرمجة شيوعًا لكشط الويب هي بايثونلمكتباتها مثل حساء جميل, الطلبات, CSS-Select, السيلينيومو سكرابي. تمكّن هذه المكتبات كاشطات الويب من الاستفادة من محددات CSS و XPath لاستخراج البيانات بكفاءة.
حساء جميل
BeautifulSoup هي واحدة من أشهر حزم Python وأكثرها قوةً وشهرةً والمصممة لتحليل مستندات HTML و XML. تنشئ هذه الحزمة شجرة تحليل للصفحات، مما يتيح لك استخراج البيانات بسهولة من HTML.
| حقيقة مثيرة للاهتمام! في مكافحة فيروس كورونا المستجد (كوفيد-19) زاحف جياباو لين DXY-COVID-19- الزاحف استخدم موقع BeautifulSoup لاستخراج بيانات قيّمة من موقع طبي صيني. وبذلك ساعد الباحثين في رصد وفهم انتشار الفيروس. [المصدر] |
الطلبات.
بايثون الطلبات هي مكتبة HTTP بسيطة لكنها قوية. وهي مفيدة لإجراء طلبات HTTP لاسترداد البيانات من مواقع الويب. تبسّط "الطلبات" عملية إرسال طلبات HTTP والتعامل مع الاستجابات في مشروع بايثون لكشط الويب الخاص بك.
a. برنامج تعليمي لكشط الويب باستخدام بايثون (+ كود)
في هذا البرنامج التعليمي لكشط الويب باستخدام Python، سنحصل على البيانات من موقع ويب HTML مستهدف باستخدام كود Python مع "الطلبات" ومكتبة BeautifulSoup.
المتطلبات الأساسية:
تأكد من استيفاء المتطلبات الأساسية التالية:
- بيئة بايثون: تأكد من أن لديك بايثون مثبتًا على حاسوبك. تأكد أيضًا من أنه يمكنك تشغيل البرنامج النصي في بيئة Python المفضلة لديك (على سبيل المثال, IDLE أو دفتر ملاحظات جوبيتر).
- مكتبة الطلبات: قم بتثبيت
الطلباتمكتبة. يتم استخدامه لإرسال طلبات HTTP GET إلى عنوان URL المحدد. يمكنك تثبيته باستخدامنقطةعن طريق الجريطلبات التثبيتفي موجه الأوامر أو الطرفية. - مكتبة الحساء الجميل: قم بتثبيت
الحساء الجميل 4المكتبة. يمكنك تثبيته باستخدامنقطةعن طريق الجريتثبيت الحساء الجميل 4في جهازك الطرفي
كود Python لكشط بيانات الويب من صفحة (مع BeautifulSoup)
سيقوم البرنامج النصي التالي بجلب عنوان URL المحدد، وتحليل محتوى HTML باستخدام BeautifulSoup، وطباعة عناوين أهم المقالات الإخبارية على صفحة الويب.

عند تشغيل البرنامج النصي على IDLE Shell، تطبع الشاشة جميع "عناوين_الأخبار" المجمعة من الموقع الإلكتروني المستهدف.

b. الاختلافات في كود Python الخاص بنا لكشط الويب.
يمكننا أخذ كود بايثون السابق الخاص بكشط الويب والقيام ببعض الاختلافات لكشط أنواع مختلفة من البيانات.
على سبيل المثال:
- العثور على الصور: للعثور على جميع وسوم الصور (
) على صفحة الويب، يمكنك استخدام طريقة find_all() مع اسم الوسم "img":

- البحث عن الروابط: للعثور على جميع علامات الارتساء () التي تمثل الروابط على صفحة الويب، يمكنك استخدام طريقة find_all() مع اسم العلامة "a":

البرنامج النصي المقدم (مع الأشكال المختلفة) هو برنامج نصي أساسي لكشط الويب. فهو ببساطة يستخرج ويطبع عناوين أهم المقالات الإخبارية من عنوان URL المحدد. ولكن، للأسف، يفتقر هذا النص البرمجي البسيط إلى الكثير من الميزات التي تشكل مشروعًا أكثر شمولاً لكشط الويب. هناك العديد من العناصر التي قد ترغب في التفكير في إضافة تخزين البيانات، ومعالجة الأخطاء، وترقيم الصفحات/ الزحف، واستخدام وكيل المستخدم والعناوين، وإجراءات الاختناق والتهذيب، والقدرة على التعامل مع المحتوى الديناميكي.
4. هل كشط الويب قانوني؟
يُنظر إلى تجريف الويب بشكل عام على أنه أمر مثير للجدل أو غير قانوني. ولكن في الواقع، إنها ممارسة مشروعة إذا تم الالتزام بحدود أخلاقية وقانونية معينة، فإن تجريف الويب قانوني تمامًا.
تعتمد شرعية تجريف الويب على طبيعة البيانات التي يتم استخراجها والطرق المستخدمة. يعتبر كشط الويب قانونيًا عندما يُستخدم لجمع المعلومات المتاحة للجمهور من الإنترنت. ومع ذلك، يجب توخي الحذر دائمًا خاصة عند التعامل مع البيانات الشخصية أو المحتوى المحمي بحقوق الطبع والنشر.
إليك بعض المؤشرات التي يجب أن تضعها في اعتبارك:
- لا تتخلص من البيانات الخاصة. كما أنه من غير القانوني استخراج البيانات غير المتاحة للجمهور. فاستخراج البيانات الموجودة خلف صفحة تسجيل الدخول، مع تسجيل دخول المستخدم وكلمة المرور، مخالف للقانون في الولايات المتحدة وكندا ومعظم دول أوروبا.
- ما تفعله بالبيانات هو ما يمكن أن يوقعك في المشاكل. يستلزم التجريف الأخلاقي للويب الانتباه إلى البيانات التي يتم جمعها والغرض المقصود منها. يجب إيلاء اهتمام خاص للبيانات الشخصية والملكية الفكرية. تأكد من امتثالك للوائح مثل القانون العام لحماية البيانات العامة وقانون حماية البيانات الشخصية، والتي تحكم التعامل مع البيانات الشخصية. على سبيل المثال، تُعد إعادة استخدام أو إعادة بيع المحتوى أو تنزيل المواد المحمية بحقوق الطبع والنشر غير قانوني (ويجب تجنبه).
- من الضروري أيضاً مراجعة شروط الخدمة على المواقع الإلكترونية. هذه هي الوثائق التي توجه أي شخص يستخدم خدمتهم أو محتواهم إلى الكيفية التي يجب أن يتفاعلوا بها مع الموارد أو لا يتفاعلوا معها.
- تأكد دائمًا من وجود بدائل مثل استخدام واجهات برمجة التطبيقات المقدمة رسميًا. Some websites like Government agencies, Weather, and Social media platforms make some of their data accessible to the public via APIs.
- ضع في اعتبارك التحقق من ملف robots.txt. This file is saved on the web server and gives directions to web crawlers and web scraping about what parts of a website to avoid and what parts are authorized. It also gives directions about the rate limits.
- تجنب بدء هجمات تجريف الويب. اعتمادًا على السياق، يُشار إلى تجريف الويب أحيانًا باسم هجوم الكشط. عندما يستخدم مرسلو البريد العشوائي شبكات الروبوتات (جيوش من الروبوتات) لاستهداف موقع ويب بطلبات كبيرة وسريعة، قد تتعطل خدمة الموقع بالكامل. قد تؤدي عمليات كشط البيانات على نطاق واسع إلى تعطل مواقع بأكملها.
آخر الأخبار حول الجوانب القانونية لكشط الويب.
أوضحت الأحكام القانونية الأخيرة أن تجريف البيانات المتاحة للجمهور لا يعتبر انتهاكًا بشكل عام. وأعاد حكم تاريخي صادر عن محكمة الاستئناف الأمريكية التأكيد على مشروعية تجريف البيانات على شبكة الإنترنت، حيث نص على أن تجريف البيانات المتاحة للجمهور على الإنترنت لا ينتهك قانون مكافحة الاحتيال وإساءة استخدام الحاسوب (CFAA) [المصدر: تك كرانش].
في خبر آخر، تسلط الدعاوى القضائية الأخيرة ضد OpenAI و Microsoft الضوء على المخاوف بشأن الخصوصية وحقوق الملكية الفكرية وقوانين مكافحة الاختراق، وفقًا للأخبار الأخيرة.بلومبرج]. في حين أن قانون مكافحة الجرائم الإلكترونية محدود الفعالية، يجري استكشاف مطالبات خرق العقود وقوانين الخصوصية في الولايات. لا يزال التفاعل بين قانون حقوق النشر وقانون العقود دون حل، مما يترك العديد من الأسئلة دون إجابة في سياق تجريف الويب.
في آخر الأخبار، [المصدر إنديا تايمز] يقوم إيلون ماسك بتغيير قواعد تويتر لمنع المستويات القصوى من تجريف البيانات. ووفقًا لماسك، فإن التجريف الشديد للويب يؤثر سلبًا على تجربة المستخدم. واقترح أن المؤسسات التي تستخدم نماذج لغوية كبيرة للذكاء الاصطناعي التوليدي هي المسؤولة عن ذلك.
5. كيف تحاول مواقع الويب منع تجزئة الويب؟
تريد الشركات أن تكون بعض بياناتها متاحة للزوار من البشر. ولكن عندما تستخدم الشركات أو المستخدمون البرامج النصية الآلية أو الروبوتات لاستخراج البيانات من الموقع بقوة، قد يكون هناك الكثير من إساءة استخدام الخصوصية والموارد على خادم الويب والصفحة المستهدفة. وتفضل هذه المواقع الضحية ردع هذا النوع من الزيارات.
تقنيات مكافحة الاحتيال.
- عدد الزيارات غير المعتاد والكبير من مصدر واحد. قد تستخدم خوادم الويب جدران حماية تطبيقات الويب (WAFs) مع قوائم سوداء لعناوين IP المزعجة لحظر حركة المرور، ومرشحات على معدلات وأحجام الطلبات "غير العادية"، وآليات التصفية. تستخدم بعض المواقع مزيجًا من WAF وشبكات توصيل المحتوى (CDN) لتصفية أو تقليل التشويش من عناوين IP المزعجة تمامًا.
- يمكن لبعض المواقع الإلكترونية اكتشاف أنماط التصفح الشبيهة بالبوتات. على غرار التقنية السابقة، تحظر مواقع الويب أيضًا الطلبات بناءً على وكيل المستخدم (رأس HTTP). لا تستخدم الروبوتات متصفحًا عاديًا. تحتوي هذه الروبوتات على سلاسل مختلفة من وكيل المستخدم (أي الزاحف أو العنكبوت أو الروبوت)، وعدم وجود اختلاف، وعدم وجود رؤوس (متصفحات مقطوعة الرأس)، وطلب الأسعار، وغير ذلك الكثير.
- تغير المواقع الإلكترونية أيضًا ترميز HTML الخاص بها كثيرًا. تتبع روبوتات كشط الويب مسارًا ثابتًا "ترميز HTML" عند اجتياز محتوى موقع ويب. تقوم بعض مواقع الويب بتغيير عناصر HTML داخل الترميز بشكل منتظم وعشوائي. هذه التقنية تُخرج الروبوت عن عادته أو جدوله الزمني المعتاد في الكشط. تغيير ترميز HTML لا يوقف تجريف الويب ولكنه يجعل الأمر أكثر صعوبة بكثير.
- استخدام التحديات مثل اختبار CAPTCHA. لتجنب الروبوتات التي تستخدم متصفحات بدون رأس، تتطلب بعض المواقع الإلكترونية تحديات CAPTCHA. تواجه الروبوتات التي تستخدم متصفحات مقطوعة الرأس صعوبة في حل هذه الأنواع من التحديات. صُممت تحديات CAPTCHA ليتم حلها على مستوى المستخدم (عبر المتصفح) وليس بواسطة الروبوتات.
- بعض المواقع عبارة عن مصائد (مصائد) لروبوتات الكشط. يتم إنشاء بعض المواقع الإلكترونية فقط من أجل محاصرة روبوتات الكشط، وهي تقنية يُشار إليها باسم "روبوتات العسل". لا يمكن رؤية روبوتات الكشط هذه إلا من قبل روبوتات الكشط (وليس من قبل الزوار البشريين العاديين) وهي مصممة لتوجيه كاشطي الويب إلى الفخ.
6. الممارسات الأخلاقية والممارسات الفضلى في مسح الويب.
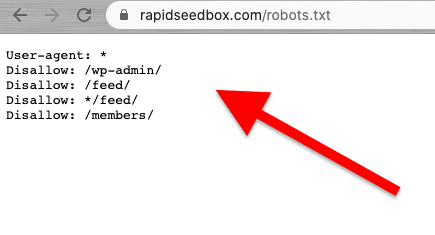
يجب أن يتم تجريف الويب بطريقة مسؤولة وأخلاقية. كما ذكرنا من قبل، يجب أن تعطيك قراءة الشروط والأحكام أو ToS فكرة عن القيود التي يجب عليك الالتزام بها. إذا كنت ترغب في الحصول على فكرة عن القواعد الخاصة ببرنامج الزحف على الويب، تحقق من ROBOTS.txt الخاص به.
إذا كان كشط الويب غير مسموح به أو محظور تمامًا، فاستخدم واجهة برمجة التطبيقات الخاصة بهم (إذا كانت متاحة).
انتبه أيضًا إلى النطاق الترددي لموقع الويب المستهدف لتجنب التحميل الزائد على الخادم بالكثير من الطلبات. من الأهمية بمكان أتمتة الطلبات بمعدل ومهلات مناسبة لتجنب الضغط على الخادم المستهدف. يجب أن تكون محاكاة المستخدم في الوقت الفعلي هي الأمثل. أيضًا، لا تقم أبدًا بكشط البيانات خلف صفحات تسجيل الدخول.
اتبع القواعد، وستكون على ما يرام.
أفضل ممارسات كشط الويب.
- استخدم وكيلاً. البروكسي هو خادم وسيط يقوم بإعادة توجيه الطلبات. عند كشط الويب باستخدام وكيل، فإنك تقوم بتوجيه طلبك الأصلي من خلاله. لذا، يقوم الوكيل بتعيين الطلب باستخدام عنوان IP الخاص به ويعيد توجيهه إلى الموقع المستهدف. استخدم البروكسي لـ
- تخلص من فرص إدراج عنوان IP الخاص بك في القائمة السوداء أو حظره. تقديم الطلبات دائمًا من خلال وكلاء مختلفين- وكلاء IPv6 مثال جيد. يمكن أن يساعدك تجمّع البروكسي في تنفيذ طلبات ذات حجم أكبر دون أن يتم حظرها.
- تجاوز المحتوى المخصص جغرافياً. يعد الوكيل في منطقة معينة مفيدًا في كشط البيانات وفقًا لتلك المنطقة الجغرافية المحددة. وهذا مفيد عندما تكون مواقع الويب والخدمات خلف شبكة CDN.
- الوكلاء المتناوبون. تأخذ البروكسيات الدوارة (تدوير) عنوان IP جديد من المجمع لكل اتصال جديد. ضع في اعتبارك أن الشبكات الافتراضية الخاصة الافتراضية ليست وكلاء. على الرغم من أنهم يقومون بشيء متشابه للغاية، وهو توفير إخفاء الهوية، إلا أنهم يعملون على مستويات مختلفة.
- تدوير UA (وكلاء المستخدم) ورؤوس طلبات HTTP. لتدوير سلاسل UAs وعناوين HTTP، ستحتاج إلى جمع قائمة بسلاسل UA من متصفحات الويب الحقيقية. ضع القائمة في شيفرة كشط الويب الخاصة بك في Python وقم بتعيين الطلبات لاختيار سلاسل عشوائية.
- لا تتخطى الحدود. قلل عدد الطلبات وقم بالتناوب والعشوائية. إذا كنت تقدم عددًا كبيرًا من الطلبات لموقع إلكتروني، فابدأ بعشوائية. اجعل كل طلب يبدو عشوائيًا وشبيهًا بالبشر. أولاً، قم بتغيير عنوان IP لكل طلب بمساعدة تدوير البروكسيات. استخدم أيضًا رؤوس HTTP مختلفة لجعل الطلبات تبدو وكأنها قادمة من متصفحات أخرى.
عزز عملية كشط الويب باستخدام وكلاء سريعين وآمنين ومجهولين من RapidSeedbox.
7. الأسئلة الشائعة حول كشط الويب: الأسئلة المتداولة.
a. ما هو robots.txt وما هو الدور الذي يلعبه في تجريف الويب؟
تساعد الروبوتات.txt بمثابة أداة اتصال بين مالكي مواقع الويب وبرامج زحف الويب و"الكاشطات". وهو عبارة عن ملف نصي يوضع على خادم الموقع الإلكتروني ويوفر تعليمات لروبوتات الويب (برامج الزحف وعناكب الويب وغيرها من الروبوتات الآلية) حول أجزاء الموقع الإلكتروني المسموح لها بالوصول إليها وكشطها، والأجزاء التي يجب أن تتجنبها. برامج زحف الويب "حسنة السلوك" (مثل Googlebot) مصممة لقراءة الروبوتات تلقائيًا. لم يتم تصميم برامج الكشط لقراءة هذا الملف. لذلك، من المهم للغاية أن تكون على دراية بملف robots.txt من أجل احترام رغبات مالك الموقع الإلكتروني.
b. ما هي الأساليب التي يستخدمها مديرو المواقع الإلكترونية لتجنب محاولات التجريف "المسيئة" أو "غير المصرح بها" على الويب؟
لا تقوم جميع أدوات الكشط باستخراج البيانات بشكل أخلاقي وقانوني. فهي لا تتبع شروط الخدمة (شروط الخدمة) الخاصة بالموقع أو إرشادات robots.txt. لذلك قد يتخذ مديرو المواقع الإلكترونية تدابير إضافية لحماية بياناتهم ومواردهم، مثل استخدام حظر بروتوكول الإنترنت أو تحديات CAPTCHA. قد يستخدمون أيضًا تدابير الحد من المعدل أو التحقق من وكيل المستخدم (لتحديد الروبوتات المحتملة) أو تتبع الجلسات أو استخدام المصادقة المستندة إلى الرمز المميز أو استخدام شبكات توصيل المحتوى (CDN) أو حتى استخدام أنظمة الكشف القائمة على السلوك.
c. كشط الويب مقابل الزحف على الويب؟
Although web scraping and web crawling are both web data extraction techniques, they have different purposes, scopes, automation, and legal aspects. On the one hand, web scraping techniques aim to extract specific data from particular sites. They are targeted and have a specific, limited scope. Web scraping uses automated scripts or third-party tools to request, receive, parse, extract, and structure data. Web crawling techniques (like list crawling), on the other hand, are used to systematically search the web. They are popular among search engines (broader scope), social media platforms, researchers, content aggregators, etc. Web crawlers can visit many sites automatically (via bots, crawlers, or spiders), build a list, index data (create a copy), and store it in a database. Web crawlers usually check the ROBOTS.txt files.
d. التنقيب عن البيانات مقابل كشط البيانات: ما هي أوجه الاختلاف والتشابه بينهما؟
يتضمن كل من التنقيب عن البيانات وكشط البيانات استخراج البيانات. ومع ذلك، يركز استخراج البيانات على استخدام التقنيات الإحصائية وتقنيات التعلم الآلي لتحليل مجموعات البيانات المنظمة. ويهدف إلى تحديد الأنماط والعلاقات والرؤى ضمن مجموعات البيانات المنظمة الكبيرة والمعقدة. من ناحية أخرى، يركز التنقيب عن البيانات على "جزء جمع" معلومات محددة من صفحات الويب والمواقع الإلكترونية. ويمكن استخدام كلتا التقنيتين والأدوات معًا. يمكن أن تكون عملية كشط الويب خطوة أولية لجمع البيانات من الويب، والتي يتم إدخالها بعد ذلك في خوارزميات التنقيب عن البيانات من أجل التحليل المتعمق واكتشاف الرؤى.
e. ما هو كشط الشاشة؟ وما علاقتها بكشط البيانات؟
تركز كلتا التقنيتين على استخراج البيانات ولكنهما تختلفان في نوع البيانات التي تستخرجانها. كشط الشاشة تهدف الأدوات إلى التقاط واستخراج البيانات المرئية المعروضة على مواقع الويب والمستندات "تلقائيًا"، بما في ذلك نصوص الشاشة. على عكس كشط الويب، الذي يقوم بتحليل البيانات من HTML (وبالتالي استخراج مجموعة واسعة من بيانات الويب)، فإن كشط الشاشة يقرأ البيانات النصية مباشرةً من شاشة العرض.
f. هل "حصاد الويب" هو نفسه "كشط الويب"؟
يرتبط تجريف البيانات وحصاد الويب ارتباطًا وثيقًا وغالبًا ما يتم استخدامهما بالتبادل، لكنهما ليسا نفس المفهوم. حصاد الويب له دلالة أوسع. فهو يشمل طرقًا مختلفة لاستخراج البيانات من الويب، بما في ذلك آليات الاستخراج التلقائي المختلفة من الويب، مثل كشط الويب. الفرق الواضح هو أن حصاد الويب غالبًا ما يُستخدم عندما يتعلق الأمر بواجهة برمجة التطبيقات، بدلاً من تحليل كود HTML مباشرةً من صفحات الويب (كما يفعل كشط الويب).
g. محدد CSS مقابل محدد XPath: ما هي الاختلافات عند الكشط؟
تعد محددات CSS طريقة فعالة لاستخراج البيانات أثناء كشط الويب. فهي توفر صيغة مباشرة وتعمل بشكل جيد في معظم سيناريوهات الكشط. ومع ذلك، في الحالات الأكثر تعقيدًا أو عند التعامل مع البنى المتداخلة، يمكن أن توفر محددات XPath مرونة ووظائف إضافية.
h. كيفية التعامل مع المواقع الديناميكية مع سيلينيوم؟
سيلينيوم أداة قوية لكشط المواقع الديناميكية على الويب. تسمح لك بالتفاعل مع العناصر الموجودة على صفحة الويب كما يتفاعل المستخدم البشري. تمكّن هذه القدرة "البرنامج النصي" من التنقل عبر المحتوى الذي تم إنشاؤه ديناميكيًا. باستخدام سيلينيوم ويب درايفر WebDriver الخاص بسيلينيوم، يمكنك انتظار تحميل عناصر الصفحة، والتفاعل مع عناصر AJAX، وكشط البيانات من مواقع الويب التي تعتمد بشكل كبير على JavaScript.
i. كيف تتعامل مع AJAX وجافا سكريبت أثناء كشط الويب؟
عند التعامل مع AJAX وجافا سكريبت أثناء كشط الويب، قد لا تكون المكتبات التقليدية مثل Requests و Beautiful Soup كافية. للتعامل مع طلبات AJAX والمحتوى الذي تم تقديمه بواسطة JavaScript، يمكنك استخدام أدوات مثل Selenium أو متصفحات بدون رأس مثل محرك الدمى.
8. كلمات ختامية.
تهانينا! لقد أكملت الدليل النهائي لكشط الويب!
نأمل أن يكون هذا الدليل قد زوّدك بالمعرفة والأدوات اللازمة للاستفادة من إمكانات كشط الويب لمشاريعك.
تذكر، مع القوة الكبيرة تأتي مسؤولية كبيرة. عندما تبدأ رحلتك في تجريف الويب، عليك دائمًا إعطاء الأولوية للممارسات الأخلاقية، واحترام شروط خدمة المواقع الإلكترونية، ومراعاة خصوصية البيانات.
لقد لمسنا قمة جبل الجليد. يمكن أن يكون كشط الويب موضوعًا شاملاً تمامًا. ولكن مهلا، لقد قمت بالفعل بكشط موقع ويب!
إن التعلم المستمر والبقاء على اطلاع دائم بأحدث التقنيات والتطورات القانونية سيمكنك من الإبحار في هذا العالم المعقد.
قد لا يكون الفحص البصري واستخراج البيانات يدويًا من صفحة HTML باستخدام محددات CSS و XPath هذه مستهلكًا للوقت فحسب، بل قد يكون عرضة للأخطاء أيضًا. بالإضافة إلى ذلك، فإن استخراج البيانات يدويًا أو بصريًا غير مناسب تمامًا لجمع البيانات على نطاق واسع أو مهام الكشط المتكررة. هذا هو المكان الذي تكون فيه البرمجة النصية والبرمجة مفيدة للغاية.
0التعليقات