In this ultimate guide, we will explore the world of web scraping, a powerful technique to extract data from websites. rat
İster konsepti merak eden bir acemi olun, ister becerilerinizi geliştirmek isteyen deneyimli bir programcı, bu kılavuzda herkes için değerli bir şeyler var. CSS kullanarak HTML veri çıkarmanın temellerini anlamaktan ve XPath seçicilerden Python ile uygulamalı web kazımaya kadar her şey elimizin altında. Ek olarak, sorumlu web kazıma sağlamak için yasal yönleri, etik hususları ve en iyi uygulamaları ele alacağız.

Sorumluluk reddi: Bu materyal kesinlikle bilgilendirme amaçlı olarak geliştirilmiştir. Herhangi bir faaliyetin (yasadışı faaliyetler dahil), ürünün veya hizmetin onaylandığı anlamına gelmez. Hizmetlerimizi kullanırken veya buradaki herhangi bir bilgiye güvenirken fikri mülkiyet yasaları da dahil olmak üzere yürürlükteki yasalara uymaktan yalnızca siz sorumlusunuz. Yasaların açıkça gerektirdiği durumlar dışında, hizmetlerimizin veya burada yer alan bilgilerin herhangi bir şekilde kullanılmasından kaynaklanan zararlar için herhangi bir sorumluluk kabul etmiyoruz.
İçindekiler.
- Web Kazıma Nedir ve Nasıl Çalışır?
- HTML Veri Çıkarmanın Temelleri: CSS ve XPath Seçicileri.
- Python ile Web Kazıma (+ Kod).
- Web Kazıma Yasal mı?
- Web siteleri web kazımayı nasıl engellemeye çalışır?
- Web Kazıma için Etik ve En İyi Uygulamalar.
- Web Kazıma: Sıkça Sorulan Sorular (SSS)
- Sonuç.
1. Web Kazıma Nedir ve Nasıl Çalışır?
Web kazıma (web hasadı veya veri çıkarma olarak da bilinir), web sitelerinden, web hizmetlerinden ve web uygulamalarından otomatik olarak veri çıkarma işlemidir.
Web kazıma, bizi her web sitesine girip manuel olarak veri çekmek zorunda kalmaktan kurtarmaya yardımcı olur - bu uzun ve etkisiz bir süreçtir. Süreç, otomatik komut dosyaları veya programların kullanılmasını içerir. Komut dosyası veya program web sayfasının HTML yapısına erişir, verileri ayrıştırır ve daha fazla analiz için sayfanın ihtiyaç duyulan belirli öğelerini çıkarır.
a. Web Kazıma Ne İçin Kullanılır?
Web kazıma, sorumlu bir şekilde yapılırsa harika bir yöntemdir. Genel olarak, belirli bir pazardaki eğilimler hakkında bilgi edinmek ve içgörü kazanmak gibi pazarları araştırmak için kullanılabilir. Ayrıca stratejilerini, fiyatlarını vb. takip etmek için rekabet izlemede de popülerdir.
Daha spesifik kullanım durumları şunlardır:
- Sosyal platformlar (Facebook ve Twitter kazıma)
- Çevrimiçi fiyat değişikliği izleme,
- Ürün incelemeleri,
- SEO kampanyaları,
- Emlak listeleri,
- Hava durumu verilerinin izlenmesi,
- Bir web sitesinin itibarını takip etme,
- Uçuşların uygunluğunu ve fiyatlarını izleme,
- Coğrafyadan bağımsız olarak reklamları test edin,
- Mali kaynakların izlenmesi,
b. Web Kazıma nasıl çalışır?
Web kazıma işleminde yer alan tipik unsurlar başlatıcı ve hedeftir. Başlatıcı (web kazıyıcı) web sitelerini kazımak için otomatik veri çıkarma yazılımı kullanır. Hedefler ise genellikle web sitesinin içeriği, iletişim bilgileri, formlar veya web'de herkese açık olarak bulunan herhangi bir şeydir.
Tipik süreç aşağıdaki gibidir:
- ADIM 1: Başlatıcı, HTTP istekleri (web siteleriyle etkileşim kurmak ve veri almak için kullanılır) oluşturmaya başlamak için kazıma aracını - yazılımı (bulut tabanlı bir hizmet veya ev yapımı bir komut dosyası olabilir) kullanır. Bu yazılım, hedef web sitesine HTTP GET, POST, PUT, DELETE veya HEAD'den OPTIONS isteğine kadar her şeyi başlatabilir.
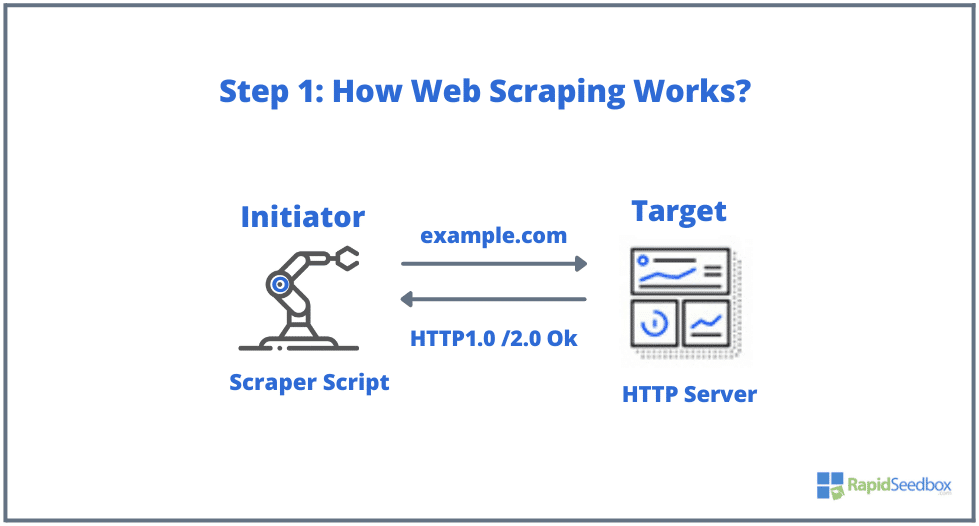
- ADIM 2. Sayfa mevcutsa, hedef web sitesi kazıyıcının isteğine HTTP/1.0 200 OK (ziyaretçilere verilen tipik yanıt) ile yanıt verecektir. Kazıyıcı HTML yanıtını aldığında (örneğin 200 OK), belgeyi ayrıştırmaya ve yapılandırılmamış verilerini toplamaya devam edecektir.
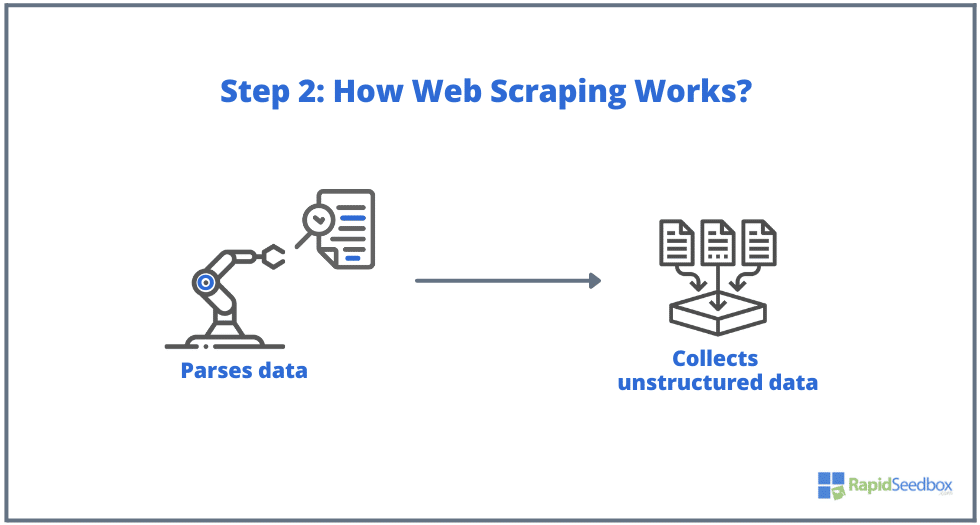
- ADIM 3. Kazıyıcı yazılım daha sonra ham verileri çıkarır, depolar ve başlatıcı tarafından belirtilen şekilde verilere yapı (indeksler) ekler. Yapılandırılmış verilere XLS, CSV, SQL veya XML gibi okunabilir formatlar aracılığıyla erişilebilir.
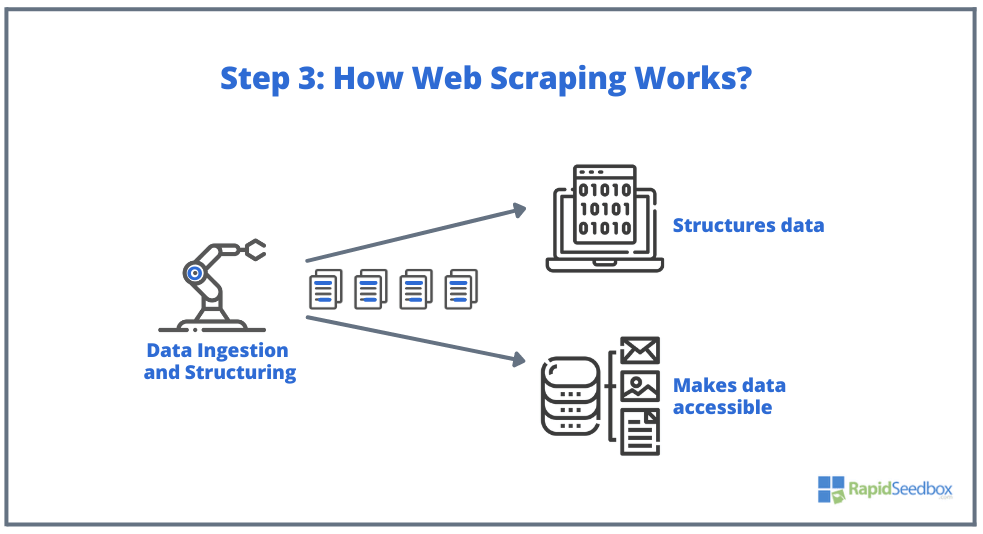
2. HTML Veri Çıkarmanın Temelleri: CSS ve XPath Seçicileri.
Temel bilgileri zaten biliyor olabilirsiniz: Web kazıma, web sitelerinden veri çıkarmayı içerir ve her şey HTML- ile başlar.web sayfalarının bel kemiğidir. Bir HTML dosyası içinde sınıflar ve kimlikler, tablolar, listeler, bloklar veya kapsayıcılar, yani bir sayfanın yapısını oluşturan tüm temel öğeleri bulabilirsiniz.
CSS ise HTML belgelerinin sunumunu ve düzenini kontrol etmek için kullanılan bir stil sayfası dilidir. Renkler, yazı tipleri, kenar boşlukları ve konumlandırma gibi HTML öğelerinin bir web sayfasında nasıl görüntüleneceğini tanımlar. CSS, istenen öğelerden veri çıkarmaya yardımcı olduğu için web kazımada önemli bir rol oynar.
Not: HTML ve CSS'in ne olduğunu ve nasıl çalıştıklarını tüm ayrıntılarıyla açıklamak bu makalenin kapsamı dışındadır. HTML ve CSS ile ilgili temel becerilere zaten sahip olduğunuzu varsayıyoruz.
Düzenli ifadeler gibi çeşitli teknikler kullanarak ham HTML'den doğrudan veri çıkarmak mümkün olsa da, bu gerçekten zaman alıcı ve zorlayıcı olabilir. HTML'nin yapılandırılmış dili "makine tarafından okunabilir" olacak şekilde tasarlandığından, gerçekten karmaşık ve çeşitli olabilir. İşte bu noktada CSS ve XPath seçicileri önemli bir rol oynar.
a. HTML Derleme ve Denetleme.
Aşağıdaki bölümde, birkaç CSS ve XPath seçici örneği (derlenmiş ve incelenmiş) sunacağız. Aşağıdaki tüm HTML ve CSS örnekleri çevrimiçi düzenleyici ile derlenmiştir HTML-CSS-JS.
Web sitelerindeki HTML kodunu incelemek söz konusu olduğunda, web tarayıcıları Geliştirici Araçları ile birlikte gelir, böylece herhangi bir web sitesinde herkese açık olan HTML veya CSS'yi tam anlamıyla inceleyebilirsiniz. Bir web sayfasına sağ tıklayıp "İncele", "Öğeyi İncele" veya "Kaynağı İncele "yi seçebilirsiniz. Daha iyi bir yan yana sayfa ve kod dinamiği karşılaştırması için Chrome Tarayıcıda > sol üstteki üç noktaya (1) > Diğer Araçlar (2) > Geliştirici Araçları (3) gidin.
Geliştirici araçları, dize, seçici veya XPath ile arama yapmanızı sağlayan kullanışlı bir arama filtresi (4) ile birlikte gelir. Örnek olarak, https://www.rapidseedbox.com/blog/twitter-facebook-scraper-guide adresinden bazı verileri kazıyacağız.
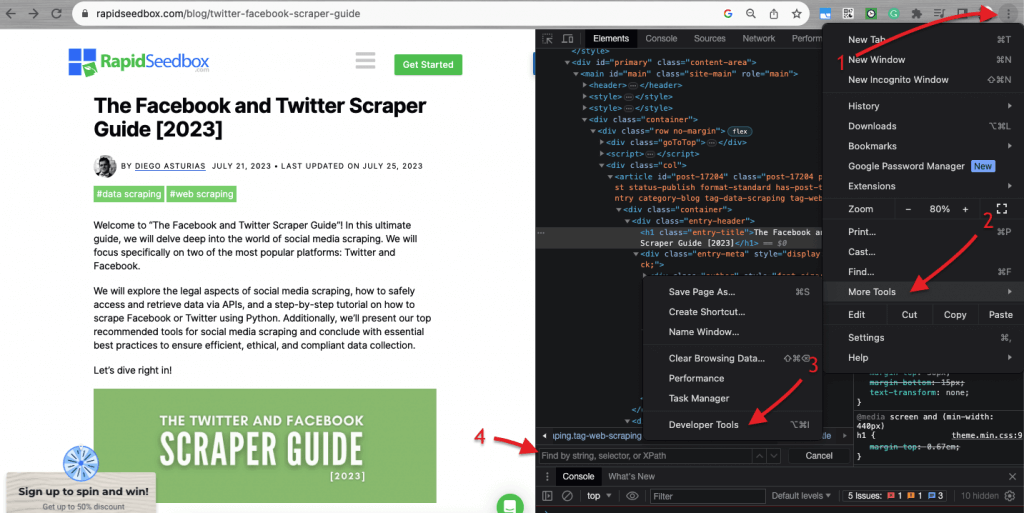
b. CSS Seçiciler:
CSS seçicileri, bir web sayfasının HTML öğelerini seçmek ve hedeflemek için kullanılan kalıplardır. HTML belgelerinden veri almak için daha verimli ve hedefli bir yol sağladıkları için web kazıma (ve stil oluşturma) için kullanışlıdırlar. Düzenli ifadeler gibi çeşitli teknikler kullanarak doğrudan ham HTML'den veri ayıklamak mümkün olsa da, CSS seçicileri web kazıma için tercih edilen bir seçim haline getiren çeşitli avantajlar sunar.
Bir web sayfası içindeki HTML öğelerini hedefleme ve seçme teknikleri:
i. Düğüm Seçimi.
Düğüm seçimi, HTML öğelerini düğüm adlarına göre seçme işlemidir. Örneğin, bir sayfadaki tüm 'p' öğelerini veya tüm 'a' öğelerini seçmek gibi. Bu teknik, HTML belgesindeki belirli öğe türlerini hedeflemenize olanak tanır.

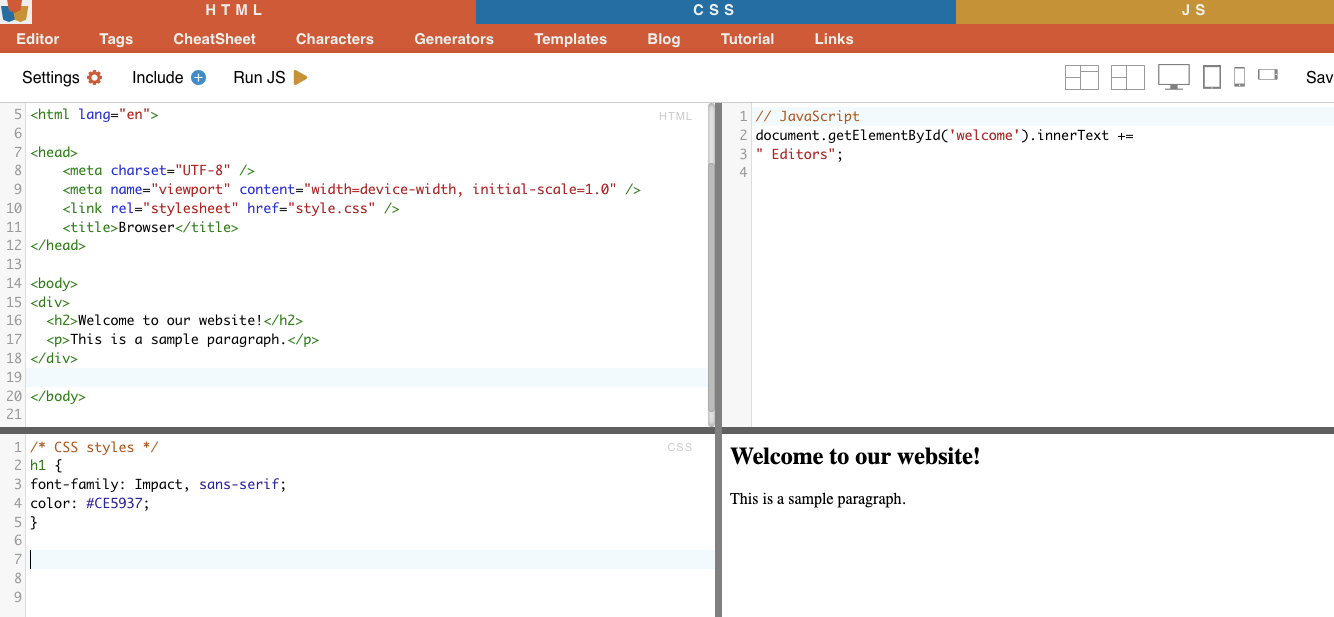
Gerçek Hayat Örneği: H2'leri manuel olarak aramak.
ii. Sınıf.
CSS Seçiciler'de sınıf seçimi, HTML öğelerinin atanmış sınıf niteliklerine göre seçilmesini içerir. Sınıf niteliği, bir veya daha fazla öğeye belirli bir sınıf adı uygulamanızı sağlar. Ayrıca CSS stillerinde veya JavaScript'te, bu sınıfa sahip tüm öğelere uygulanabilir. 'Sınıf' adlarına örnek olarak düğmeler, form öğeleri, gezinme menüleri, ızgara düzenleri ve daha fazlası verilebilir.
Örnek: Aşağıdaki CSS Seçici: 'highlight', sınıf niteliği "highlight" olarak ayarlanmış tüm öğeleri seçecektir.


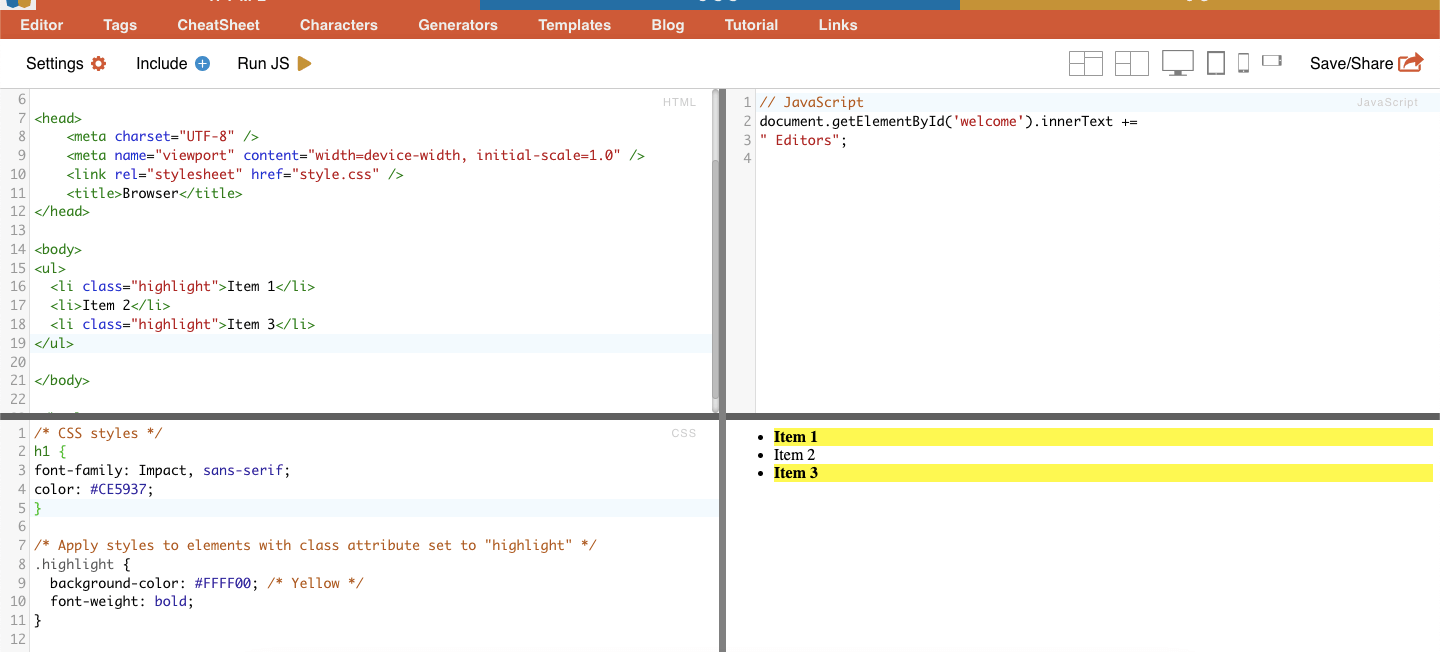
Gerçek Hayat Örneği: Sınıfları manuel olarak arama.
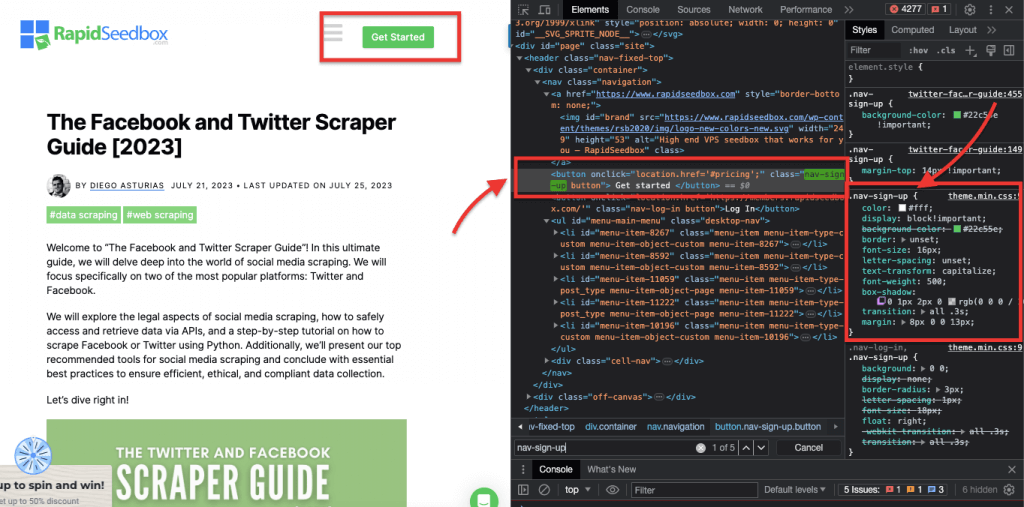
iii. Kimlik Kısıtlamaları.
ID kısıtlamaları, benzersiz ID niteliğine dayalı olarak bir HTML öğesinin seçilmesine yardımcı olur. Bu ID niteliği, web sayfasındaki tek bir öğeyi benzersiz bir şekilde tanımlamak için kullanılır. Birden fazla öğede kullanılabilen sınıfların aksine, ID'ler sayfa içinde benzersiz olmalıdır.
Örnek: CSS Seçici '#header', ID niteliği "header" olarak ayarlanmış öğeyi seçecektir.


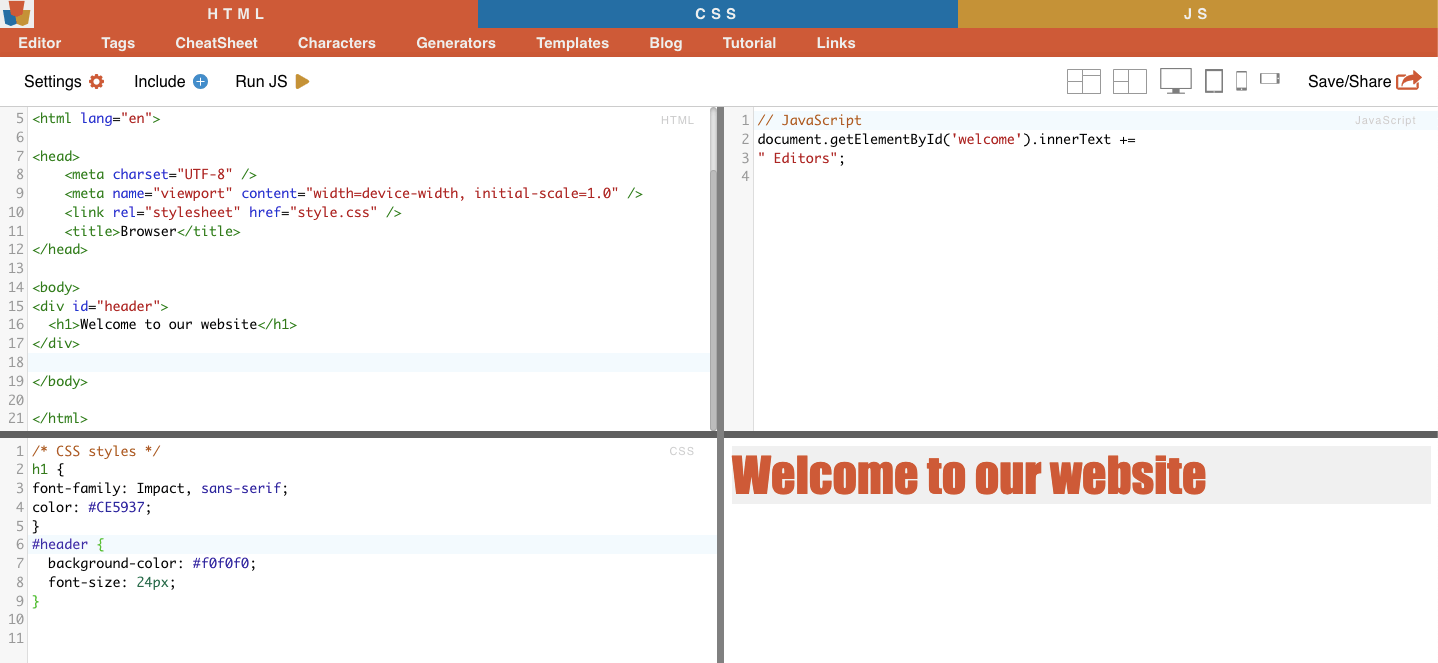
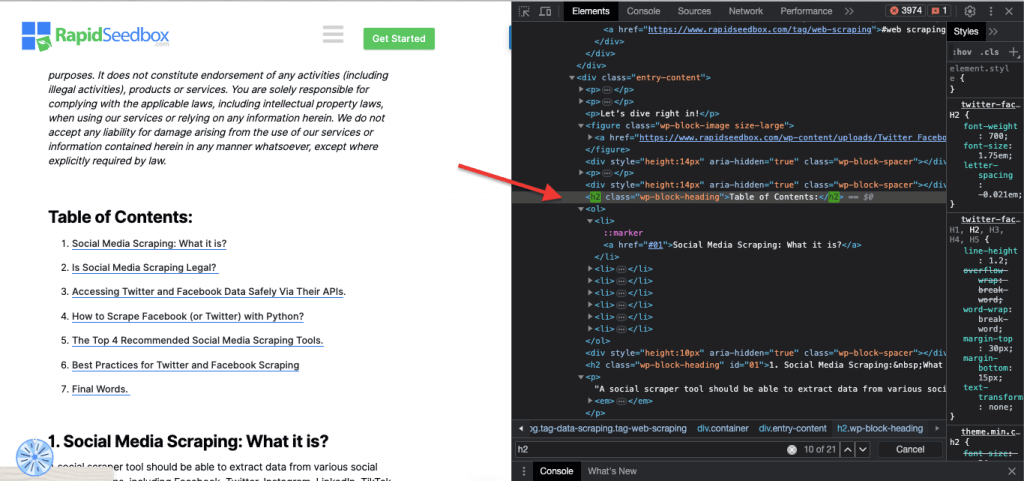
Gerçek hayattan örnek: Kimlikleri manuel olarak arama. #01'i bulduktan sonra id="01″'i bulmanız gerekecektir.
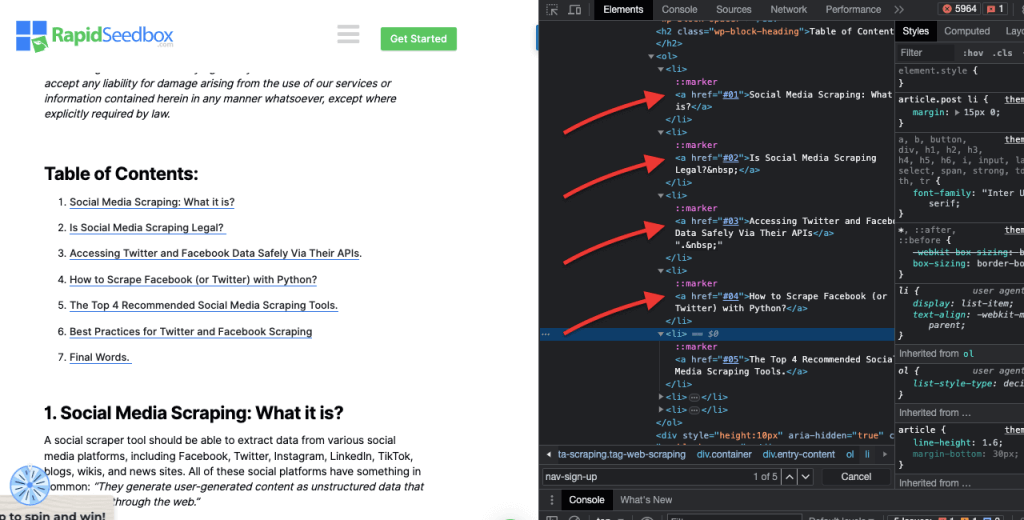
iv. Öznitelik Eşleştirme.
Bu teknik, HTML öğelerini belirli özniteliklere ve bunların değerlerine göre seçmeyi içerir. Belirli bir özniteliğe veya öznitelik değerine sahip öğeleri hedeflemenizi sağlar. Tam eşleme, alt dize eşleme ve daha fazlası gibi farklı öznitelik eşleme türleri vardır.
Örnek: Aşağıdaki örnekte veri türü adlı özel bir nitelik gösterilmektedir. Belirli öğeleri (örneğin "meyve" olarak işaretlenmiş liste öğeleri) hedeflemek veya stil vermek için, öğeleri öznitelik değerlerine göre seçen CSS seçicisini kullanabilirsiniz.
Yalnızca "meyve" olarak işaretlenmiş öğeleri kazımak için aşağıdaki CSS seçiciyi kullanabilirsiniz:

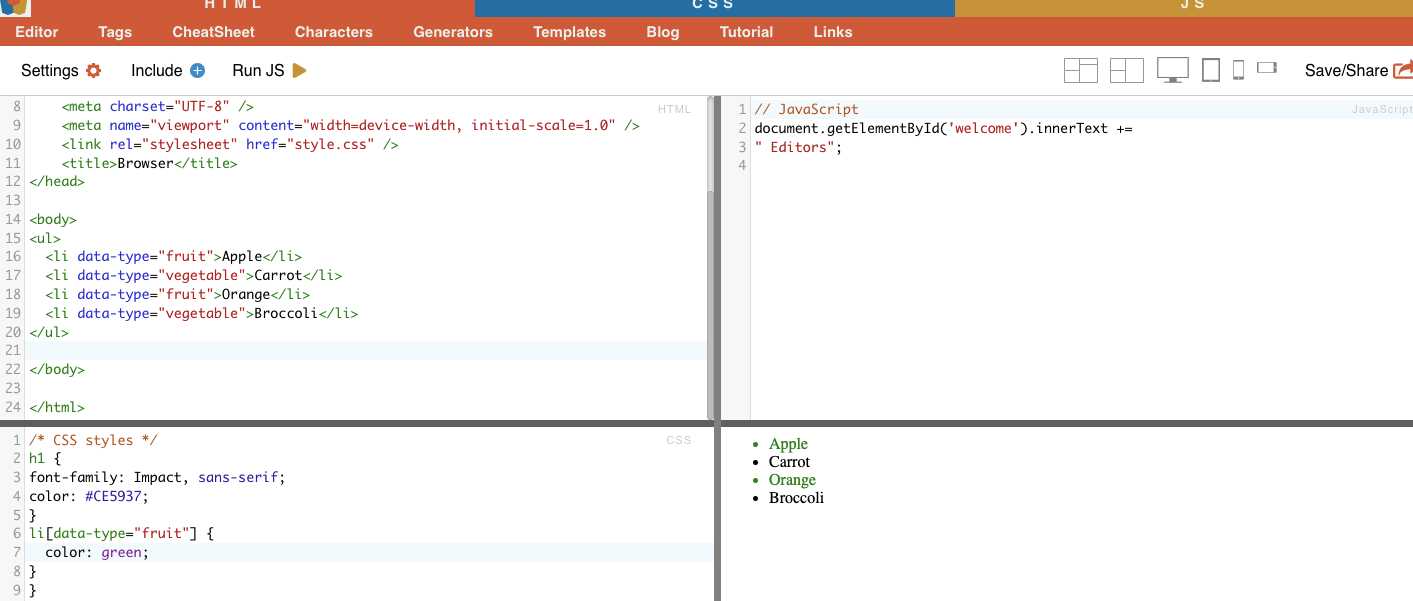
Gerçek Hayat Örneği: Öznitelikleri manuel olarak arama.
c. Xpath Seçicileri:
CSS seçicileri, HTML yapısının nispeten basit olduğu basit web kazıma görevleri için idealdir. Ancak HTML yapısı daha girift ve karmaşık hale geldiğinde, başka bir çözüm vardır: XPath seçicileri.
XPath Seçicileri (XML Yol Dili Seçicileri) bir XML veya HTML belgesinin öğeleri arasında gezinmek için kullanılan esnek bir yol dilidir. HTML kodu içindeki belirli düğümlerin konum, ad, nitelik veya içerik temelinde seçilmesine yardımcı olurlar. XPath seçicileri, sınıf ve ID niteliklerine dayalı olarak öğeleri hedeflemek için de yararlı olabilir.
İşte web kazıma için üç XPath seçici örneği.
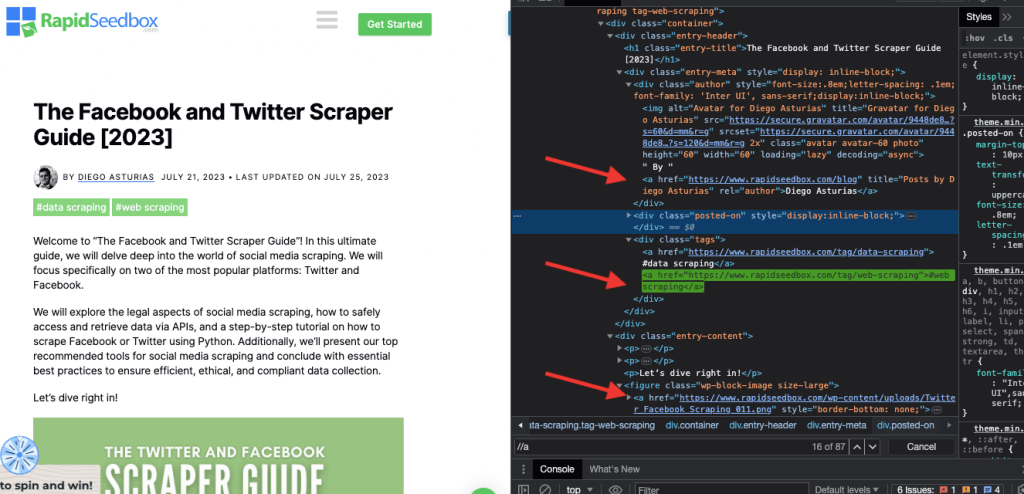
i. Örnek 1: XPath İfadesi: ' //a
XPath ifadesi ' //a', belgedeki konumlarından bağımsız olarak sayfadaki tüm '' öğelerini seçer. Aşağıdaki ekran görüntüsü, sayfadaki tüm '' öğelerinin manuel olarak konumlandırılmasını göstermektedir.
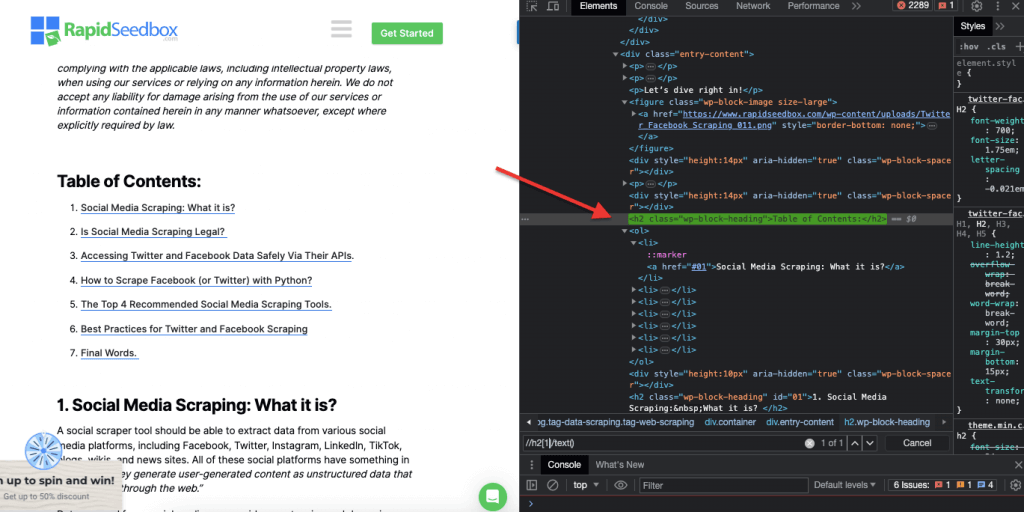
ii. Örnek 2: ' //h2[1]/text()'
XPath İfadesi:
' //h2[1]/text() '
Sayfadaki ilk h2 başlığının metin içeriğini seçecektir. '[1]' indeksi h2 öğesinin ilk oluşumunu belirtmek için kullanılır, ayrıca '[2]' indeksi ile ikinci oluşumu da belirtebilirsiniz ve bu böyle devam eder. Aşağıdaki ekran görüntüsü, bu XPath seçicisini kullanarak sayfadaki ilk h2 başlığının manuel olarak bulunmasını göstermektedir.
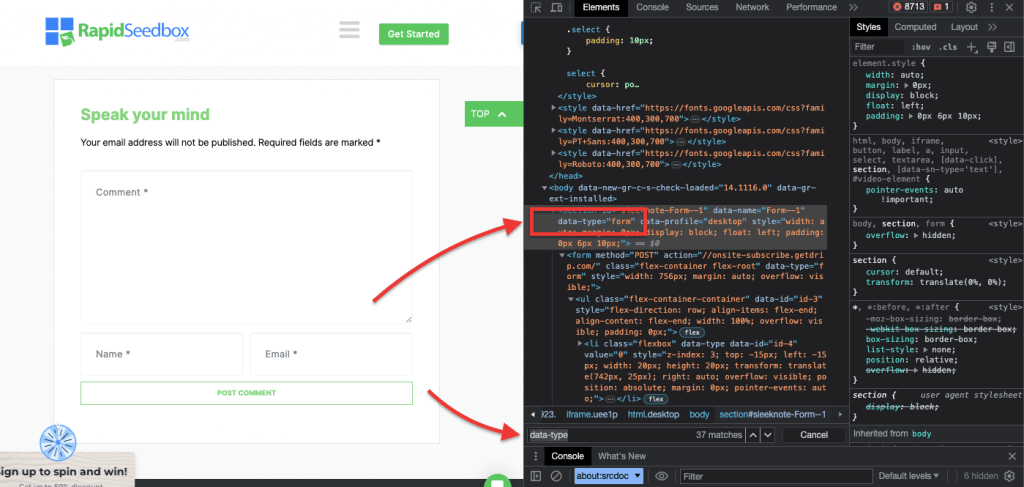
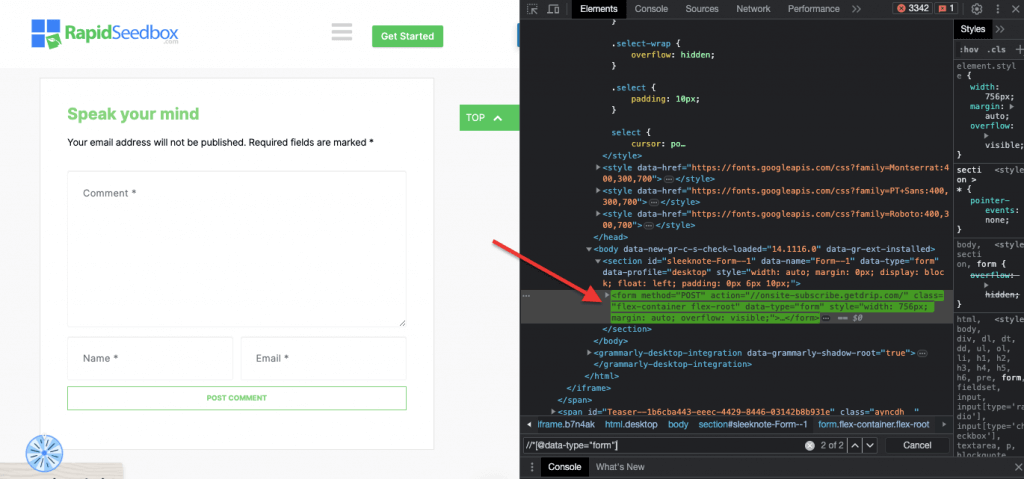
iii. Örnek 3. ' //* [@data-type="form"]'
XPath ifadesi //* [@data-type="form"] "form" değerine sahip bir veri özniteliğine sahip tüm öğeleri seçer. Form * sembolü, düğüm adına bakılmaksızın, belirtilen veri niteliğine sahip herhangi bir öğenin seçileceğini gösterir. Aşağıdaki ekran görüntüsü, "form" değerine sahip öğeleri manuel olarak bulma işlemini göstermektedir.
Bu CSS ve XPath seçicilerini kullanarak bir HTML sayfasından verileri görsel olarak incelemek ve manuel olarak ayıklamak sadece zaman alıcı değil aynı zamanda hatalara da açık olabilir. Ayrıca, manuel veya görsel olarak veri ayıklamak, büyük ölçekli veri toplama veya tekrarlayan kazıma görevleri için tamamen uygun değildir. İşte bu noktada komut dosyası oluşturma ve programlama son derece faydalıdır.
RapidSeedbox'ın hızlı, güvenli ve anonim proxy'leri ile web kazıma işlemlerinizi geliştirin.
Web kazıma için en iyi programlama dilleri hangileridir?
Kazıma için en popüler programlama dili, kütüphaneleri ve paketleri nedeniyle Python'dur (bu konuda daha fazla bilgi bir sonraki bölümde.) Bir başka popüler programlama dili web kazıma Rçünkü bu aynı zamanda harika bir desteklenen kütüphane ve çerçeve setine sahiptir. Ayrıca, birçok web kazıyıcının kullandığı popüler bir programlama dili olan C#'den de bahsetmek gerekir. ZenRows gibi web sitelerinde aşağıdakiler hakkında kapsamlı kılavuzlar bulunmaktadır C#'de bir web sitesi nasıl kazınırBu da geliştiricilerin süreci anlamalarını ve kendi projelerini başlatmalarını kolaylaştırır.
Basitlik adına, bu web kazıma kılavuzu Python ile web kazıma üzerine odaklanacaktır. Okumaya devam edin!
3. Python ile Web Kazıma (Kodlu).
Programlama dilleriyle sistematik ve otomatik bir şekilde kullanabilecekken neden CSS seçicileri veya XPath seçicileri kullanarak HTML verilerini görsel olarak inceleyip manuel olarak ayıklayasınız ki?
Daha kolay veri çıkarımı için CSS seçicilerini destekleyen birçok popüler web kazıma kütüphanesi ve çerçevesi vardır. Web kazıma için en popüler programlama dillerinden biri Pythongibi kütüphaneleri için BeautifulSoup, Talepler, CSS-Seçim, Selenyumve Scrapy. Bu kütüphaneler web kazıyıcılarının CSS ve XPath seçicilerinden yararlanarak verileri verimli bir şekilde ayıklamasını sağlar.
BeautifulSoup.
BeautifulSoup, HTML ve XML belgelerini ayrıştırmak için tasarlanmış en popüler ve güçlü Python paketlerinden biridir. Bu paket, sayfaların bir ayrıştırma ağacını oluşturarak HTML'den kolayca veri çıkarmanızı sağlar.
| İlginç Gerçek! COVID-19'a karşı mücadelede, Jiabao Lin'in DXY-COVID-19-Crawler'ı Çinli bir tıbbi web sitesinden değerli verileri ayıklamak için BeautifulSoup'u kullandı. Bu sayede araştırmacılara virüsün yayılmasını izleme ve anlama konusunda yardımcı oldu. [Kaynak] |
İstekler.
Python'un Talepler basit ama güçlü bir HTTP kütüphanesidir. Web sitelerinden veri almak için HTTP istekleri yapmak için kullanışlıdır. "Requests", web kazıma Python projenizde HTTP istekleri gönderme ve yanıtları işleme sürecini basitleştirir.
a. Python ile Web Kazıma Eğitimi (+ Kod)
Python ile web kazıma için bu eğitimde, "requests" ve BeautifulSoup kütüphanesi ile Python kodunu kullanarak bir hedef HTML web sitesinden veri alacağız.
Önkoşullar:
Aşağıdaki ön koşulların karşılandığından emin olun:
- Python ortamı: Sahip olduğunuzdan emin olun Python bilgisayarınızda yüklü olmalıdır. Ayrıca, betiği tercih ettiğiniz Python ortamında çalıştırabildiğinizden emin olun (örn, IDLE veya Jupyter Notebook).
- İstek Kütüphanesi: Yükleme
isteklerikütüphane. Belirtilen URL'ye HTTP GET istekleri göndermek için kullanılır. Kullanarak yükleyebilirsinizpipkoşarakpip yükleme isteklerikomut isteminizde veya terminalinizde. - BeautifulSoup Kütüphanesi: Yükleme
beautifulsoup4kütüphane. Bunu kullanarak yükleyebilirsinizpipkoşarakpip install beautifulsoup4terminalinizde.
Bir sayfadan veri kazımak için Python kodu (BeautifulSoup ile)
Aşağıdaki kod belirtilen URL'yi getirir, BeautifulSoup kullanarak HTML içeriğini ayrıştırır ve web sayfasındaki en iyi haber makalelerinin başlıklarını yazdırır.

Komut dosyası IDLE Kabuğunda çalıştırıldığında, ekran hedeflenen web sitesinden toplanan tüm "haber_başlıklarını" yazdırır.

b. Web kazıma için Python kodumuzun varyasyonları.
Önceki web kazıma Python kodumuzu alabilir ve farklı veri türlerini kazımak için bazı varyasyonlar yapabiliriz.
Örneğin:
- Görüntü Bulma: Web sayfasındaki tüm resim etiketlerini (
) bulmak için, 'img' etiket adıyla find_all() yöntemini kullanabilirsiniz:

- Bağlantıları Bulma: Web sayfasındaki bağlantıları temsil eden tüm anchor etiketlerini () bulmak için find_all() yöntemini 'a' etiket adıyla kullanabilirsiniz:

Sağlanan betik (varyasyonlarla birlikte) temel bir web kazıma betiğidir. Sadece belirtilen URL'den en iyi haber makalelerinin başlıklarını çıkarır ve yazdırır. Ancak, ne yazık ki, bu basit betik daha kapsamlı bir web kazıma projesi oluşturan birçok özellikten yoksundur. Veri depolama, hata işleme, sayfalama/tarama, kullanıcı aracısı ve başlık kullanımı, kısıtlama ve nezaket önlemleri ve dinamik içeriği işleme yeteneği eklemeyi düşünebileceğiniz birkaç unsur vardır.
4. Web Kazıma Yasal mı?
Web kazıma genellikle tartışmalı veya yasadışı olarak algılanır. Ancak gerçekte, belirli etik ve yasal sınırlara uyulduğu takdirde web kazıma tamamen yasal olan meşru bir uygulamadır.
Web kazımanın yasallığı, çıkarılan verilerin niteliğine ve kullanılan yöntemlere bağlıdır. Web kazıma, internetten kamuya açık bilgileri toplamak için kullanıldığında yasal kabul edilir. Bununla birlikte, özellikle kişisel veriler veya telif hakkıyla korunan içerikle uğraşırken her zaman dikkatli olunması gerekir.
İşte akılda tutulması gereken birkaç ipucu:
- Özel verileri kazımayın. Kamuya açık olmayan verileri çıkarmak da yasalara aykırıdır. Kullanıcı ve parola girişi olan bir giriş sayfasının arkasındaki verileri kazımak ABD, Kanada ve Avrupa'nın çoğunda yasalara aykırıdır.
- Verilerle ne yaptığınız başınızı belaya sokabilir. Etik web kazıma, toplanan verilere ve bunların kullanım amaçlarına dikkat edilmesini gerektirir. Kişisel verilere ve fikri mülkiyete özel önem verilmelidir. Kişisel verilerin işlenmesini düzenleyen GDPR ve CCPA gibi düzenlemelere uyduğunuzdan emin olun. Örneğin, içeriği yeniden kullanmak veya yeniden satmak ya da telif hakkıyla korunan materyalleri indirmek yasa dışıdır (ve bundan kaçınılmalıdır).
- Web sitelerindeki Hizmet Şartlarını gözden geçirmek de önemlidir. Bunlar, hizmetlerini veya içeriklerini kullanan kişileri kaynaklarla nasıl etkileşime girmeleri ve girmemeleri gerektiği konusunda yönlendiren belgelerdir.
- Her zaman resmi olarak sağlanan API'leri kullanmak gibi alternatiflerden emin olun. Some websites like Government agencies, Weather, and Social media platforms make some of their data accessible to the public via APIs.
- Robots.txt dosyasını kontrol etmeyi düşünün. This file is saved on the web server and gives directions to web crawlers and web scraping about what parts of a website to avoid and what parts are authorized. It also gives directions about the rate limits.
- Web kazıma saldırıları başlatmaktan kaçının. Bağlama bağlı olarak, bazen web kazıma, kazıma saldırısı olarak adlandırılır. Spam gönderenler botnet (bot orduları) kullanarak büyük ve hızlı taleplerle bir web sitesini hedef aldığında, tüm web sitesinin hizmeti başarısız olabilir. Büyük ölçekli veri kazıma saldırıları tüm siteleri çökertebilir.
Web kazımanın yasal yönleri hakkında son haberler.
Son yasal kararlar, kamuya açık verilerin kazınmasının genellikle bir ihlal olarak değerlendirilmediğini açıklığa kavuşturmuştur. ABD temyiz mahkemesi tarafından verilen dönüm noktası niteliğindeki bir karar, internette kamuya açık verilerin kazınmasının Bilgisayar Sahtekarlığı ve Suistimal Yasasını (CFAA) ihlal etmediğini belirterek web kazımanın yasallığını yeniden teyit etmiştir [kaynak: TechCrunch].
Diğer yandan, OpenAI ve Microsoft'a karşı açılan son davalar, gizlilik, fikri mülkiyet ve bilgisayar korsanlığı karşıtı yasalarla ilgili endişelerin altını çiziyor [Bloomberg]. CFAA sınırlı bir etkinliğe sahipken, sözleşmenin ihlali iddiaları ve eyalet gizlilik yasaları araştırılmaktadır. Telif hakkı ve sözleşme hukuku arasındaki etkileşim, web kazıma bağlamında birçok soruyu cevapsız bırakarak çözülmemiştir.
Son haberlerde, [kaynak: IndiaTimes] Elon Musk, aşırı düzeyde veri kazımayı önlemek için Twitter kurallarını değiştiriyor. Musk'a göre, aşırı web kazıma kullanıcı deneyimini olumsuz etkiliyor. Bunun sorumlusu olarak da üretici yapay zeka için büyük dil modelleri kullanan kuruluşları gösterdi.
5. Web Siteleri Web Kazımayı Nasıl Engellemeye Çalışır?
Şirketler, verilerinin bir kısmının insan ziyaretçiler tarafından erişilebilir olmasını ister. Ancak şirketler veya kullanıcılar siteden agresif bir şekilde veri çekmek için otomatik komut dosyaları veya botlar kullandığında, hedef web sunucusu ve sayfasında çok fazla gizlilik ve kaynak kötüye kullanımı olabilir. Bu mağdur siteler bu tür trafiği caydırmayı tercih eder.
Kazıma Önleme Teknikleri.
- Tek bir kaynaktan gelen olağandışı ve yüksek miktarda trafik. Web sunucuları, trafiği engellemek için gürültülü IP adreslerinin kara listelerini içeren WAF'lar (Web Uygulaması Güvenlik Duvarları), "olağandışı" istek oranları ve boyutlarına ilişkin filtreler ve filtreleme mekanizmaları kullanabilir. Bazı siteler, bu tür IP'lerden gelen gürültüyü tamamen filtrelemek veya azaltmak için WAF ve CDN (İçerik Dağıtım Ağları) kombinasyonunu kullanır.
- Bazı web siteleri bot benzeri tarama modellerini tespit edebilir. Önceki tekniğe benzer şekilde, web siteleri de User-Agent'a (HTTP başlığı) dayalı istekleri engeller. Botlar normal bir tarayıcı kullanmazlar. Bu botlar farklı kullanıcı aracısı dizelerine (yani, crawler, spider veya bot), çeşitlilik eksikliğine, başlıkların yokluğuna (başsız tarayıcılar), talep oranları ve daha fazlası.
- Web siteleri de HTML biçimlendirmelerini sık sık değiştirir. Web kazıma botları bir web sitesinin içeriğinde gezinirken tutarlı bir "HTML işaretleme" rotası izler. Bazı web siteleri işaretlemedeki HTML öğelerini düzenli olarak ve rastgele değiştirir. Bu teknik, bir botu düzenli kazıma alışkanlığından veya programından saptırır. HTML işaretlemesini değiştirmek web kazımayı durdurmaz ancak çok daha zor hale getirir.
- CAPTCHA gibi zorlukların kullanılması. Başlıksız tarayıcı kullanan botlardan kaçınmak için, bazı web siteleri CAPTCHA zorlukları gerektirir. Başlıksız tarayıcı kullanan botlar bu tür zorlukları çözmekte zorlanırlar. CAPTCHA'lar robotlar tarafından değil, kullanıcı düzeyinde (tarayıcı aracılığıyla) çözülmek üzere yapılmıştır.
- Bazı siteler kazıma botları için tuzaklardır (bal küpleri). Bazı web siteleri yalnızca kazıma botlarını tuzağa düşürmek için oluşturulur - bu, honeypot olarak adlandırılan bir tekniktir. Bu bal noktaları yalnızca kazıma botları tarafından görülebilir (sıradan insan ziyaretçiler tarafından değil) ve web kazıyıcılarını bir tuzağa yönlendirmek için inşa edilmiştir.
6. Web Kazıma için Etik ve En İyi Uygulamalar.
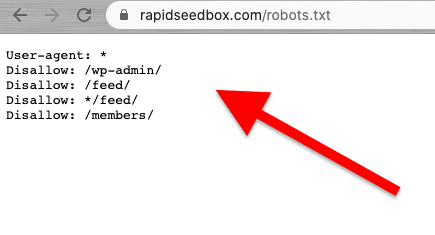
Web kazıma sorumlu ve etik bir şekilde yapılmalıdır. Daha önce de belirtildiği gibi, Şartlar ve Koşulları veya ToS'u okumak size uymanız gereken kısıtlamalar hakkında bir fikir verecektir. Bir web tarayıcısının kuralları hakkında fikir edinmek istiyorsanız, ROBOTS.txt dosyasını kontrol edin.
Web kazımaya tamamen izin verilmiyorsa veya engellenmişse, API'lerini kullanın (mevcutsa).
Ayrıca, bir sunucuyu çok fazla istekle aşırı yüklemekten kaçınmak için hedefin web sitesi bant genişliğine dikkat edin. Hedef sunucuyu zorlamamak için istekleri bir oran ve doğru zaman aşımları ile otomatikleştirmek çok önemlidir. Gerçek zamanlı bir kullanıcıyı simüle etmek en uygun yöntem olmalıdır. Ayrıca, oturum açma sayfalarının arkasındaki verileri asla kazımayın.
Kurallara uyarsanız, sorun yaşamazsınız.
Web Kazıma En İyi Uygulamaları.
- Bir Proxy kullanın. Proxy, istekleri ileten bir aracı sunucudur. Bir proxy ile web kazıma yaparken, orijinal isteğinizi onun üzerinden yönlendirirsiniz. Böylece, proxy isteği kendi IP'si ile eşler ve hedef web sitesine iletir. Şunlar için bir proxy kullanın:
- IP'nizin kara listeye alınması veya engellenmesi olasılığını ortadan kaldırın. Her zaman çeşitli vekiller aracılığıyla talepte bulunun- IPv6 proxy'leri iyi bir örnektir. Bir proxy havuzu, engellenmeden daha büyük hacimli istekleri gerçekleştirmenize yardımcı olabilir.
- Coğrafi olarak uyarlanmış içeriği atlayın. Belirli bir bölgedeki bir proxy, o coğrafi bölgeye göre veri kazımak için kullanışlıdır. Bu, web siteleri ve hizmetler bir CDN'nin arkasında olduğunda kullanışlıdır.
- Dönen Vekiller. Dönen Proxy'ler her yeni bağlantı için havuzdan yeni bir IP alır (döndürür). Unutmayın ki VPN'ler proxy değildir. Çok benzer bir şey yapmalarına rağmen, yani anonimlik sağlamalarına rağmen, farklı seviyelerde çalışırlar.
- Döndür UA (Kullanıcı Aracıları) ve HTTP İstek Başlıkları. UA'ları ve HTTP başlıklarını döndürmek için gerçek web tarayıcılarından UA dizelerinin bir listesini toplamanız gerekir. Listeyi Python'daki web kazıma kodunuza koyun ve istekleri rastgele dizeler seçecek şekilde ayarlayın.
- Sınırları zorlama. Talep sayısını yavaşlatın, döndürün ve rastgele hale getirin. Bir web sitesi için çok sayıda talepte bulunuyorsanız, işleri rastgele hale getirerek başlayın. Her isteğin rastgele ve insan gibi görünmesini sağlayın. İlk olarak, dönen proxy'ler yardımıyla her isteğin IP'sini değiştirin. Ayrıca, isteklerin başka tarayıcılardan geliyormuş gibi görünmesini sağlamak için farklı HTTP başlıkları kullanın.
RapidSeedbox'ın hızlı, güvenli ve anonim proxy'leri ile web kazıma işlemlerinizi geliştirin.
7. Web Kazıma SSS: Sıkça Sorulan Sorular.
a. Robots.txt nedir ve web kazımada nasıl bir rol oynar?
Bu robots.txt dosyası, web sitesi sahipleri, web tarayıcıları ve "kazıyıcılar" arasında bir iletişim aracı olarak hizmet eder. Bir web sitesinin sunucusuna yerleştirilen ve web robotlarına (tarayıcılar, web örümcekleri ve diğer otomatik botlar) web sitesinin hangi bölümlerine erişmelerine ve kazımalarına izin verildiği ve hangi bölümlerden kaçınmaları gerektiği hakkında talimatlar sağlayan bir metin dosyasıdır. "Uslu" web tarayıcıları (Googlebot gibi) robots.txt'yi otomatik olarak okuyacak şekilde tasarlanmıştır. Kazıyıcılar bu dosyayı okumak için tasarlanmamıştır. Bu nedenle, web sitesi sahibinin isteklerine saygı duymak için robots.txt dosyasının farkında olmak son derece önemlidir.
b. Web sitesi yöneticileri "kötü niyetli" veya "yetkisiz" web kazıma girişimlerini önlemek için hangi teknikleri kullanıyor?
Tüm kazıyıcılar etik ve yasal olarak veri elde etmez. Sitenin TOS'una (Hizmet Şartları) veya robots.txt yönergelerine uymazlar. Bu nedenle, web sitesi yöneticileri verilerini ve kaynaklarını korumak için IP engelleme veya CAPTCHA zorlukları gibi ek önlemler alabilirler. Ayrıca hız sınırlayıcı önlemler, kullanıcı aracısı doğrulama (potansiyel botları tanımlamak için), oturumları izleme, belirteç tabanlı kimlik doğrulama, CDN (İçerik Dağıtım Ağları) kullanma ve hatta davranış tabanlı algılama sistemleri kullanabilirler.
c. Web Kazıma vs. Web Tarama?
Although web scraping and web crawling are both web data extraction techniques, they have different purposes, scopes, automation, and legal aspects. On the one hand, web scraping techniques aim to extract specific data from particular sites. They are targeted and have a specific, limited scope. Web scraping uses automated scripts or third-party tools to request, receive, parse, extract, and structure data. Web crawling techniques (like list crawling), on the other hand, are used to systematically search the web. They are popular among search engines (broader scope), social media platforms, researchers, content aggregators, etc. Web crawlers can visit many sites automatically (via bots, crawlers, or spiders), build a list, index data (create a copy), and store it in a database. Web crawlers usually check the ROBOTS.txt files.
d. Veri madenciliği vs Veri kazıma: Farkları ve benzerlikleri nelerdir?
Hem veri madenciliği hem de veri kazıma veri çıkarmayı içerir. Ancak veri madenciliği, yapılandırılmış veri setlerini analiz etmek için istatistiksel ve makine öğrenimi tekniklerini kullanmaya odaklanır. Büyük ve karmaşık yapılandırılmış veri setleri içindeki kalıpları, ilişkileri ve içgörüleri belirlemeyi amaçlar. Veri kazıma ise web sayfalarından ve web sitelerinden belirli bilgilerin "toplanması kısmına" odaklanır. Her iki teknik ve araç birlikte kullanılabilir. Web kazıma, web'den veri toplamak için bir ön adım olabilir ve bu veriler daha sonra derinlemesine analiz ve içgörü keşfi için veri madenciliği algoritmalarına beslenir.
e. Ekran Kazıma Nedir? Ve Veri Kazıma ile nasıl ilişkilidir?
Her iki teknik de veri çıkarmaya odaklanır ancak çıkardıkları veri türü bakımından farklılık gösterir. Ekran kazıma araçları, ekran metni de dahil olmak üzere web sitelerinde ve belgelerde görüntülenen görsel verileri "otomatik olarak" yakalamayı ve çıkarmayı amaçlamaktadır. HTML'den veri ayrıştıran (böylece çok çeşitli web verilerini çıkaran) web kazımanın aksine, ekran kazıma metin verilerini doğrudan ekran görüntüsünden okur.
f. Web Hasadı, Web Kazıma ile aynı şey midir?
Veri kazıma ve web hasadı birbiriyle yakından ilişkilidir ve sıklıkla birbirinin yerine kullanılır, ancak aynı kavram değildir. Web hasadı daha geniş bir çağrışıma sahiptir. Web kazıma gibi çeşitli otomatik web çıkarma mekanizmaları da dahil olmak üzere web'den veri çıkarmanın farklı yöntemlerini kapsar. Açık bir ayrım, web hasadının genellikle web sayfalarından HTML kodunu doğrudan ayrıştırmak yerine (web kazımanın yaptığı gibi) bir API söz konusu olduğunda kullanılmasıdır.
g. CSS Seçici vs XPath Seçici: Kazıma yaparken farklar nelerdir?
CSS seçicileri, web kazıma sırasında veri ayıklamak için etkili bir yoldur. Basit bir sözdizimi sunarlar ve çoğu kazıma senaryosunda iyi çalışırlar. Ancak, daha karmaşık durumlarda veya iç içe geçmiş yapılarla uğraşırken, XPath seçicileri ek esneklik ve işlevsellik sağlayabilir.
h. Selenium ile dinamik web siteleri nasıl işlenir?
Selenium, dinamik web sitelerini kazımak için güçlü bir araçtır. Web sayfasındaki öğelerle bir insan kullanıcının yapacağı gibi etkileşime girmenizi sağlar. Bu yetenek, "betiğinizin" dinamik olarak oluşturulan içerikte gezinmesini sağlar. Kullanarak Selenium'un WebDriver'ıile sayfa öğelerinin yüklenmesini bekleyebilir, AJAX öğeleriyle etkileşime girebilir ve JavaScript'e büyük ölçüde güvenen web sitelerinden veri kazıyabilirsiniz.
i. Web Kazıma yaparken AJAX ve JavaScript ile nasıl başa çıkılır?
Web kazıma sırasında AJAX ve JavaScript ile uğraşırken, Requests ve Beautiful Soup gibi geleneksel kütüphaneler yeterli olmayabilir. AJAX isteklerini ve JavaScript ile oluşturulmuş içeriği işlemek için Selenium gibi araçları veya aşağıdaki gibi başsız tarayıcıları kullanabilirsiniz Kuklacı.
8. Sonuç
Tebrikler! Web kazıma için nihai kılavuzu tamamladınız!
Bu kılavuzun sizi projeleriniz için web kazıma potansiyelinden yararlanmaya yönelik bilgi ve araçlarla donatmasını umuyoruz.
Unutmayın, büyük güç büyük sorumluluk getirir. Web kazıma yolculuğunuza başlarken, her zaman etik uygulamalara öncelik verin, web sitelerinin hizmet şartlarına saygı gösterin ve veri gizliliğine dikkat edin.
Buzdağının görünen kısmına dokunduk. Web Kazıma oldukça kapsamlı bir konu olabilir. Ama hey, siz zaten bir web sitesi kazımışsınız!
Sürekli öğrenme ve en son teknolojiler ile yasal gelişmelerden haberdar olma, bu karmaşık dünyada yolunuzu bulmanızı sağlayacaktır.
Bu CSS ve XPath seçicilerini kullanarak bir HTML sayfasından verileri görsel olarak incelemek ve manuel olarak ayıklamak sadece zaman alıcı değil aynı zamanda hatalara da açık olabilir. Ayrıca, manuel veya görsel olarak veri ayıklamak, büyük ölçekli veri toplama veya tekrarlayan kazıma görevleri için tamamen uygun değildir. İşte bu noktada komut dosyası oluşturma ve programlama son derece faydalıdır.
0Yorumlar