In this ultimate guide, we will explore the world of web scraping, a powerful technique to extract data from websites. rat
Будь вы новичок, интересующийся концепцией, или опытный программист, желающий усовершенствовать свои навыки, в этом руководстве найдется что-то ценное для каждого. От понимания основ извлечения данных из HTML с помощью CSS и XPath селекторов до практического веб-скреппинга с помощью Python. Кроме того, мы рассмотрим юридические аспекты, этические соображения и лучшие практики для обеспечения ответственного веб-скреппинга.

Отказ от ответственности: Данный материал разработан строго в ознакомительных целях. Это не является одобрением какой-либо деятельности (включая незаконную деятельность), продуктов или услуг. Вы несете единоличную ответственность за соблюдение применимых законов, включая законы об интеллектуальной собственности, при использовании наших услуг или использовании любой информации, содержащейся в настоящем материале. Мы не несем никакой ответственности за ущерб, возникший в результате использования наших услуг или информации, содержащейся в настоящем материале, каким бы то ни было образом, за исключением случаев, когда это прямо требуется по закону.
Содержание
- Что такое веб-скрапинг и как он работает?
- Основы извлечения данных из HTML: Селекторы CSS и XPath.
- Веб-скрапинг с помощью Python (+ код).
- Законен ли веб-скрепинг?
- Как веб-сайты пытаются блокировать веб-скраппинг?
- Этические и лучшие практики веб-скрапинга.
- Веб-скрапинг: Часто задаваемые вопросы (FAQ)
- Заключение
1. Что такое веб-скраппинг и как он работает?
Веб-скрепинг (также известный как веб-сборка или извлечение данных) - это процесс автоматического извлечения данных с веб-сайтов, веб-сервисов и веб-приложений.
Веб-скреппинг избавляет нас от необходимости заходить на каждый сайт и вручную собирать данные - долгий и неэффективный процесс. Этот процесс включает в себя использование автоматизированных скриптов или программ. Скрипт или программа получает доступ к HTML-структуре веб-страницы, анализирует данные и извлекает нужные элементы страницы для дальнейшего анализа.
a. Для чего используется веб-скраппинг?
Веб-скреппинг - замечательная вещь, если подходить к ней ответственно. Как правило, его можно использовать для исследования рынков, например, для получения информации и изучения тенденций на конкретном рынке. Он также популярен в мониторинге конкурентов, чтобы отслеживать их стратегию, цены и т. д.
Более конкретные варианты использования:
- Социальные платформы (Скраппинг Facebook и Twitter)
- Онлайн-мониторинг изменения цен,
- Отзывы о товаре,
- SEO-кампании,
- Объявления о продаже недвижимости,
- Отслеживание погодных данных,
- Отслеживание репутации сайта,
- Мониторинг наличия и цен на рейсы,
- Тестируйте рекламу, независимо от географии,
- Мониторинг финансовых ресурсов,
b. Как работает веб-скраппинг?
Типичными элементами, участвующими в веб-скрапинге, являются инициатор и цель. Инициатор (веб-скрепер) использует программное обеспечение для автоматического извлечения данных, чтобы скрести веб-сайты. Целью, с другой стороны, обычно является содержимое сайта, контактная информация, формы или что-либо общедоступное в сети.
Типичный процесс выглядит следующим образом:
- ШАГ 1: Инициатор использует инструмент для скраппинга - программное обеспечение (которое может быть как облачным сервисом, так и самодельным скриптом), чтобы начать генерировать HTTP-запросы (используемые для взаимодействия с веб-сайтами и получения данных). Это программное обеспечение может генерировать любые запросы, начиная от HTTP GET, POST, PUT, DELETE или HEAD и заканчивая OPTIONS-запросом к целевому сайту.
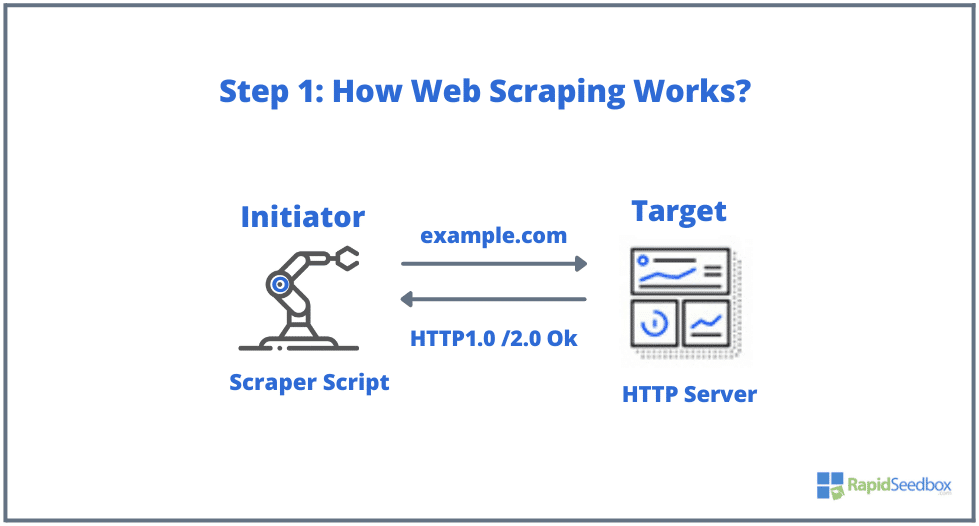
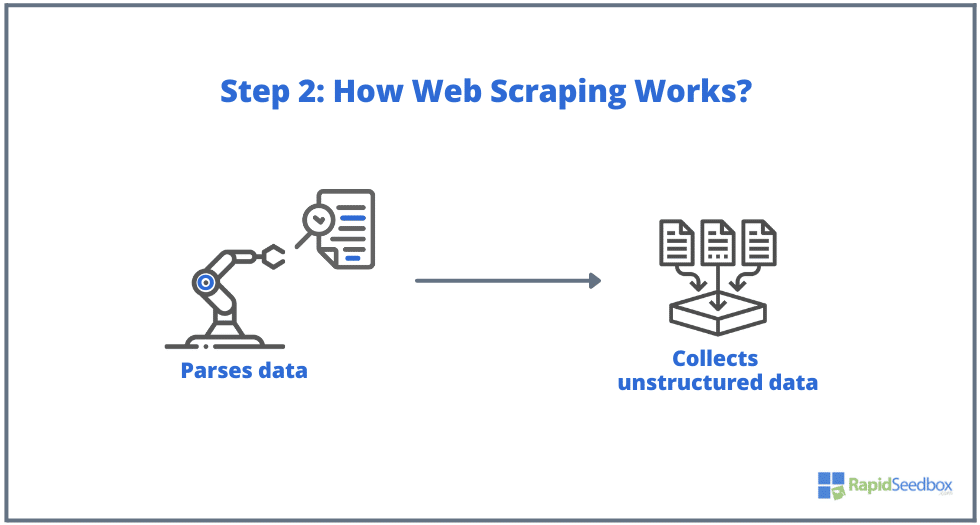
- ШАГ 2. Если страница существует, целевой сайт ответит на запрос скрепера сообщением HTTP/1.0 200 OK (типичный ответ посетителям). Получив HTML-ответ (например, 200 OK), скрепер приступит к разбору документа и сбору неструктурированных данных.
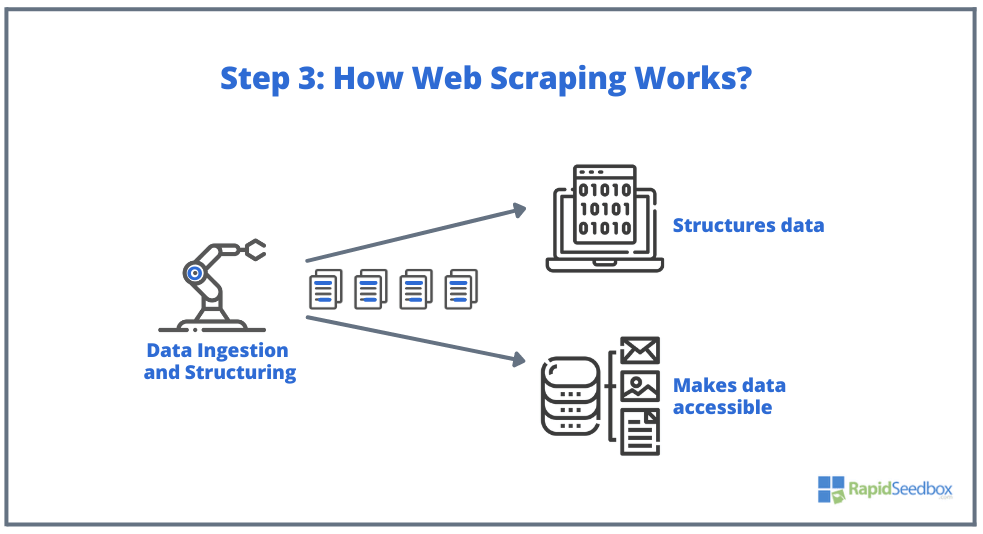
- ШАГ 3. Затем программа-скрепер извлекает необработанные данные, сохраняет их и добавляет к ним структуру (индексы) в соответствии с тем, что было указано инициатором. Структурированные данные доступны в таких форматах, как XLS, CSV, SQL или XML.
2. Основы извлечения данных из HTML: Селекторы CSS и XPath.
Возможно, вы уже знаете основы: Веб-скреппинг подразумевает извлечение данных с веб-сайтов, и все начинается с HTML.основа веб-страниц. В HTML-файле вы найдете классы и идентификаторы, таблицы, списки, блоки или контейнеры - все основные элементы, составляющие структуру страницы.
CSS, с другой стороны, - это язык таблиц стилей, используемый для управления представлением и оформлением HTML-документов. Он определяет, как HTML-элементы отображаются на веб-странице, например, цвета, шрифты, поля и позиционирование. CSS играет ключевую роль в веб-скреппинге, поскольку помогает извлекать данные из нужных элементов.
Примечание: Подробное объяснение того, что такое HTML и CSS и как они работают, выходит за рамки этой статьи. Мы предполагаем, что вы уже обладаете фундаментальными навыками HTML и CSS.
Хотя можно извлекать данные непосредственно из необработанного HTML с помощью различных техник, например регулярных выражений, это может занять много времени и быть очень сложным. Поскольку структурированный язык HTML был разработан как "машиночитаемый", он может быть очень сложным и разнообразным. Именно здесь селекторы CSS и XPath играют ключевую роль.
a. Компиляция и проверка HTML.
В следующем разделе мы приведем несколько примеров CSS и XPath-селекторов (скомпилированных и проверенных). Все приведенные ниже примеры HTML и CSS были скомпилированы с помощью онлайн-редактора HTML-CSS-JS.
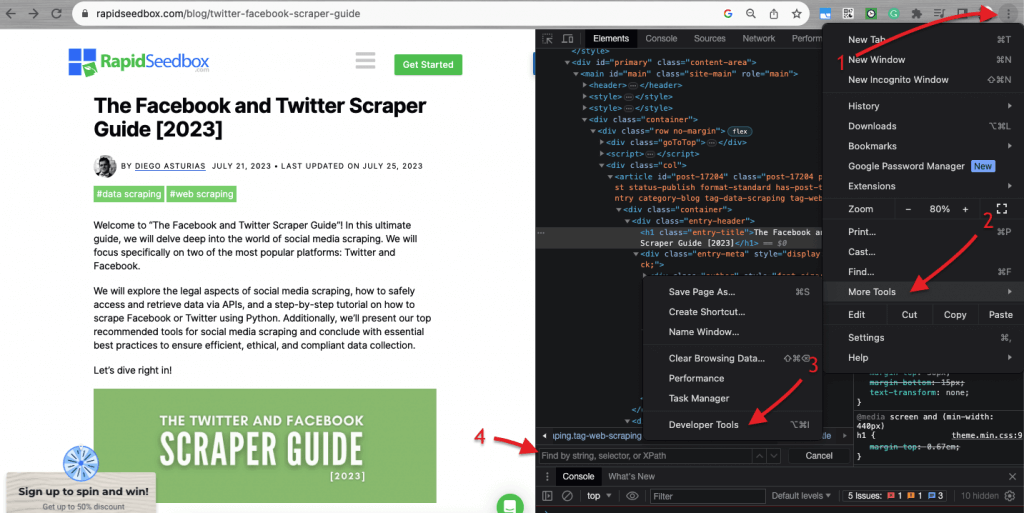
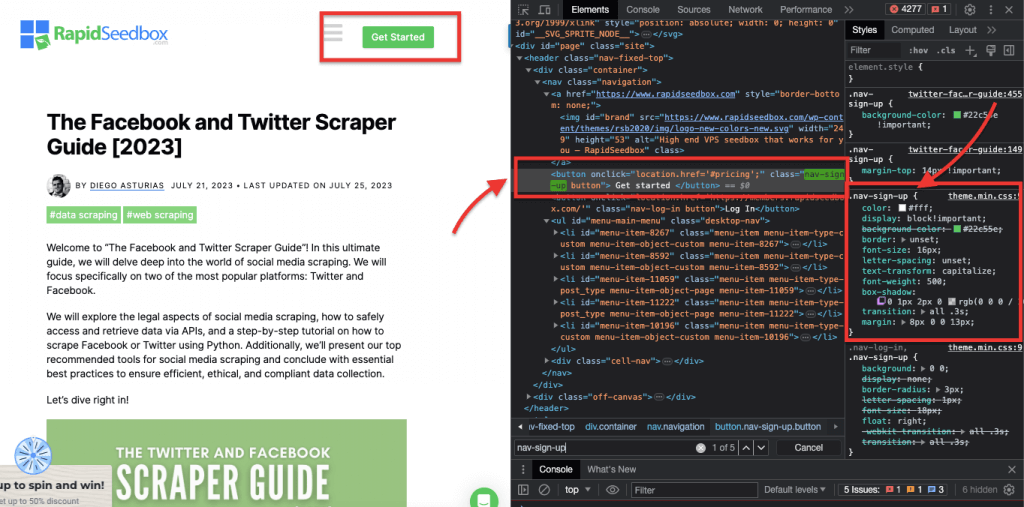
Когда дело доходит до проверки HTML-кода на сайтах, Веб-браузеры поставляются с инструментами разработчика, поэтому вы можете буквально изучить HTML или CSS, которые находятся в открытом доступе на любом сайте. Вы можете щелкнуть правой кнопкой мыши на веб-странице и выбрать "Inspect", "Inspect Element" или "Inspect Source". Чтобы лучше сравнить динамику страницы и кода, в браузере Chrome нажмите на три точки в левом верхнем углу (1) > "Другие инструменты" (2) > "Инструменты разработчика" (3).
Инструменты разработчика поставляются с удобным фильтром поиска (4), который позволяет искать по строке, селектору или XPath. В качестве примера мы возьмем некоторые данные из: https://www.rapidseedbox.com/blog/twitter-facebook-scraper-guide.
b. Селекторы CSS:
Селекторы CSS - это шаблоны, используемые для выбора и нацеливания HTML-элементов веб-страницы. Они полезны для веб-скрапинга (и стилизации), поскольку обеспечивают более эффективный и целенаправленный способ получения данных из HTML-документов. Хотя можно извлекать данные непосредственно из HTML-документа с помощью различных методов, например регулярных выражений, селекторы CSS обладают рядом преимуществ, которые делают их предпочтительным выбором для веб-скрапинга.
Техники нацеливания и выбора HTML-элементов на веб-странице:
i. Выбор узла.
Выбор узла - это процесс выбора элементов HTML на основе имен их узлов. Например, выбор всех элементов 'p' или всех элементов 'a' на странице. Эта техника позволяет выбрать определенные типы элементов в HTML-документе.

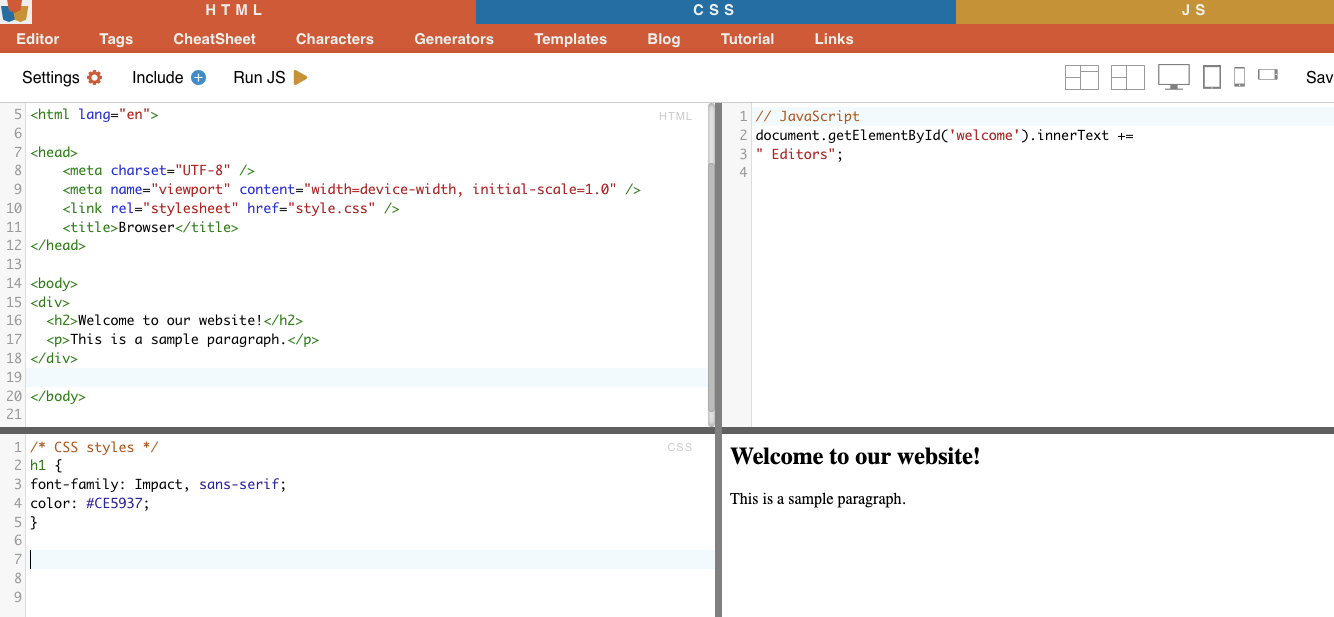
Пример из реальной жизни: Ручной поиск H2.
ii. Класс.
В CSS Selectors выбор класса подразумевает выбор HTML-элементов на основе назначенного им атрибута class. Атрибут class позволяет применить определенное имя класса к одному или нескольким элементам. Дополнительно в стилях CSS или JavaScript он может быть применен ко всем элементам с этим классом. Примерами имен "классов" являются кнопки, элементы форм, навигационные меню, макеты сетки и многое другое.
Пример: Следующий CSS-селектор: 'highlight' выберет все элементы с атрибутом class, установленным на "highlight".


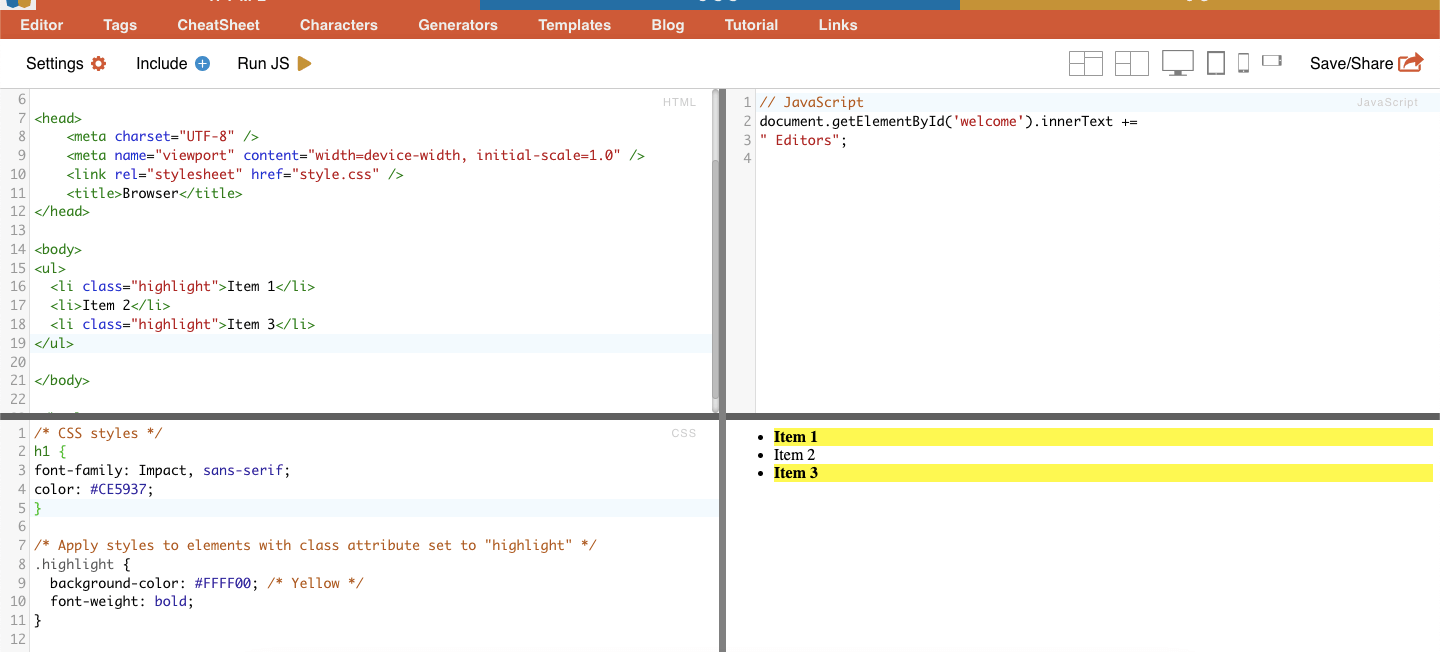
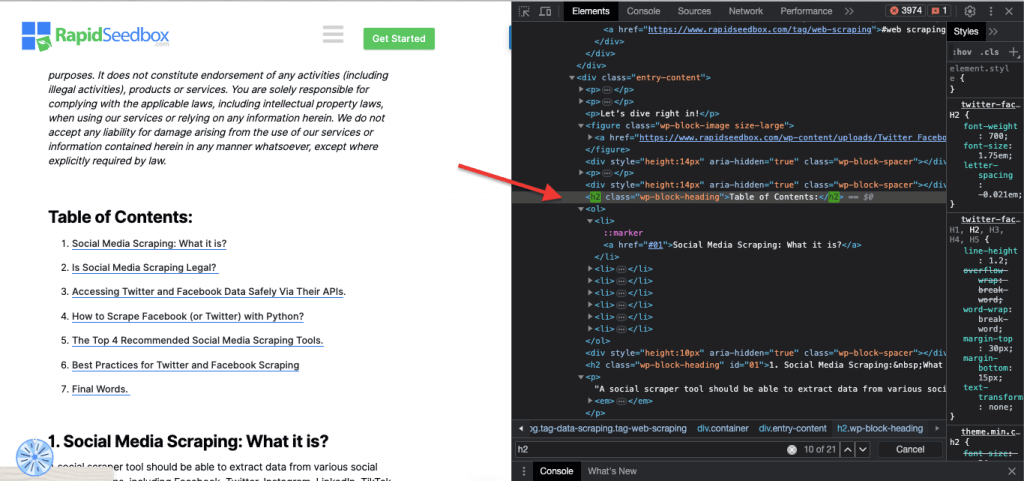
Пример из реальной жизни: Ручной поиск классов.
iii. Ограничения идентификации.
Ограничения ID помогают выбрать элемент HTML на основе его уникального атрибута ID. Этот атрибут ID используется для уникальной идентификации отдельного элемента на веб-странице. В отличие от классов, которые могут использоваться для нескольких элементов, идентификаторы должны быть уникальными в пределах страницы.
Пример: CSS-селектор '#header' выберет элемент с атрибутом ID, установленным на "header".


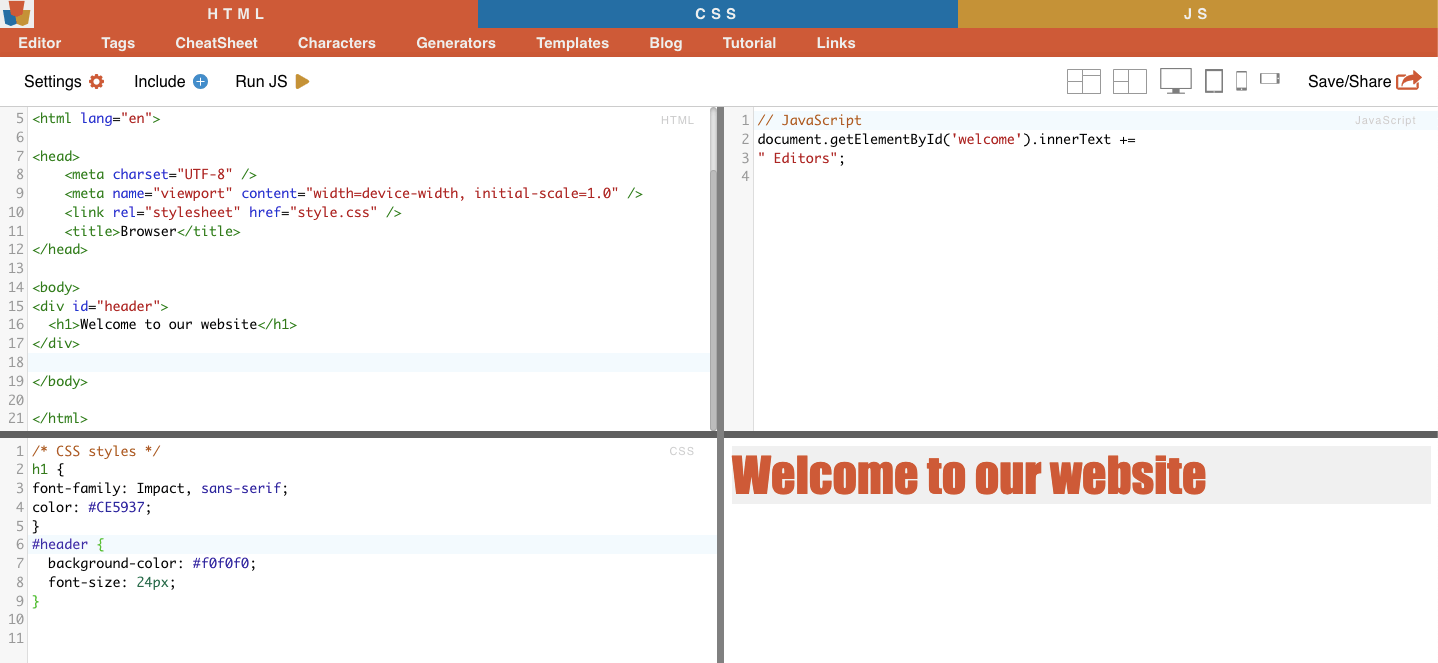
Пример из реальной жизни: Ручной поиск идентификаторов. После того как вы нашли #01, вам нужно найти id="01″.
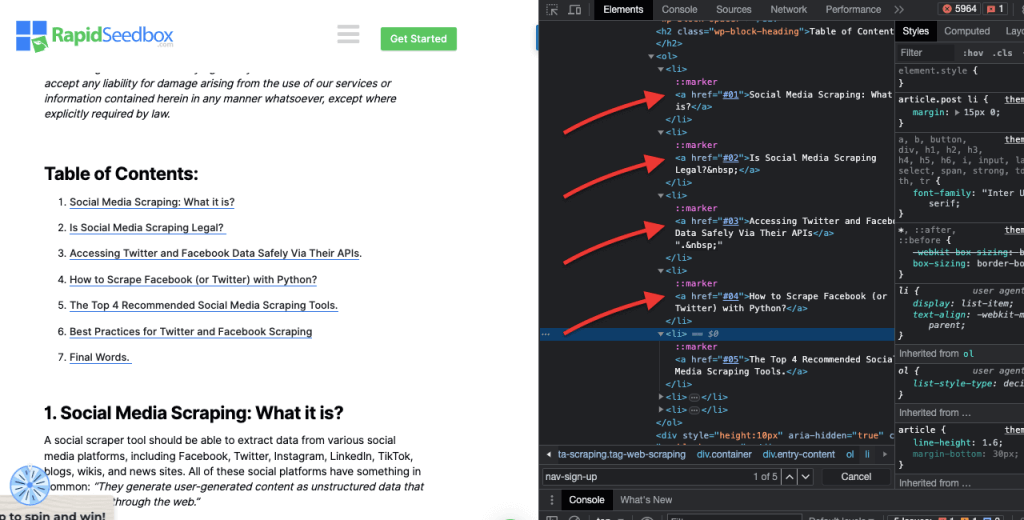
iv. Сопоставление атрибутов.
Эта техника предполагает выбор HTML-элементов на основе определенных атрибутов и их значений. Она позволяет выбрать элементы, которые имеют определенный атрибут или значение атрибута. Существуют различные типы подбора атрибутов, такие как точный подбор, подбор подстроки и другие.
Пример: В следующем примере показан пользовательский атрибут "Тип данных". Чтобы выделить или стилизовать определенные элементы (например, элементы списка, помеченные как "фрукты"), можно использовать селектор CSS, который выбирает элементы на основе значений их атрибутов.
Чтобы отсканировать только те элементы, которые помечены как "фрукты", можно использовать следующий CSS-селектор:

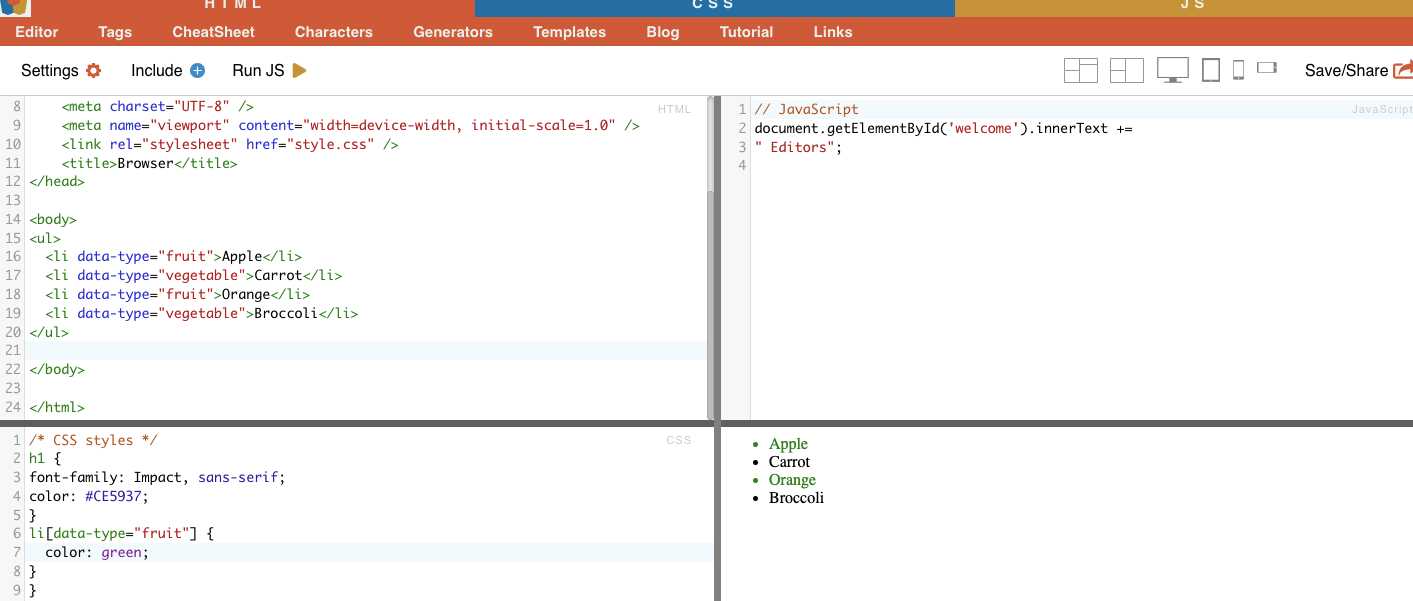
Пример из реальной жизни: Ручной поиск атрибутов.
c. Селекторы Xpath:
Селекторы CSS идеально подходят для простых задач веб-скрапинга, когда структура HTML относительно проста. Но когда структура HTML становится более запутанной и сложной, есть другое решение: селекторы XPath.
Селекторы XPath (селекторы языка XML Path) это гибкий язык путей, используемый для навигации по элементам XML или HTML-документа. Они помогают выбрать конкретные узлы в HTML-коде на основе местоположения, имен, атрибутов или содержимого. Селекторы XPath также могут быть полезны для выбора элементов на основе их класса и атрибутов ID.
Вот три примера селекторов XPath для веб-скраппинга.
i. Пример 1: Выражение XPath: ' //a
Выражение XPath ' //a' выбирает все элементы '' на странице, независимо от их расположения в документе. На следующем снимке экрана показано ручное определение местоположения всех элементов '' на странице.
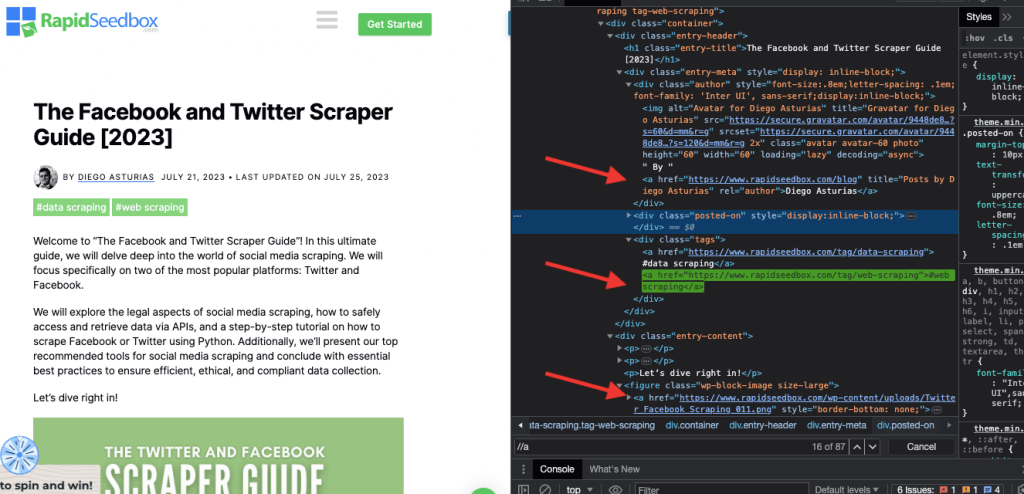
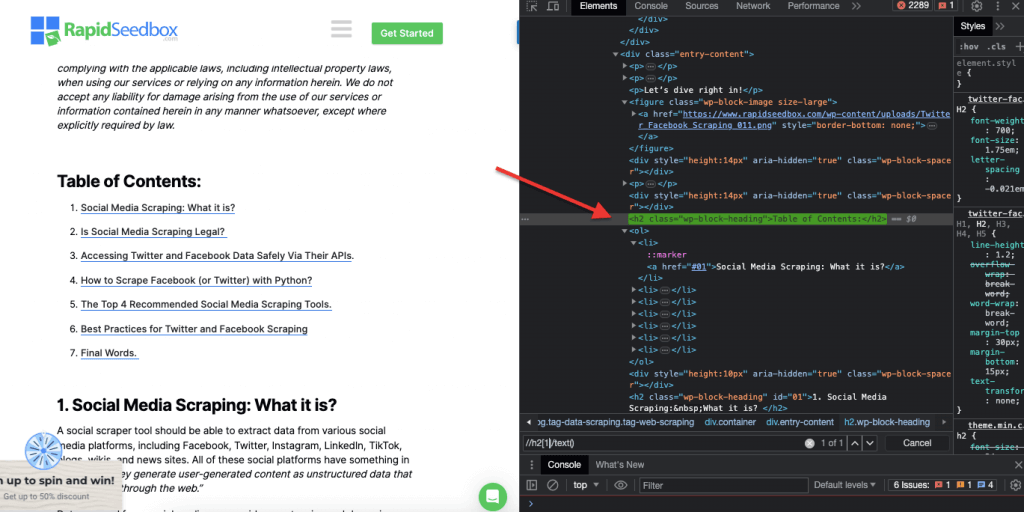
ii. Пример 2: ' //h2[1]/text()'
Выражение XPath:
' //h2[1]/text() '
Он выберет текстовое содержимое первого заголовка h2 на странице. Индекс '[1]' используется для указания первого вхождения элемента h2, вы также можете указать второе вхождение с помощью индекса '[2]' и так далее. На следующем снимке экрана показано ручное нахождение первого заголовка h2 на странице с помощью этого селектора XPath.
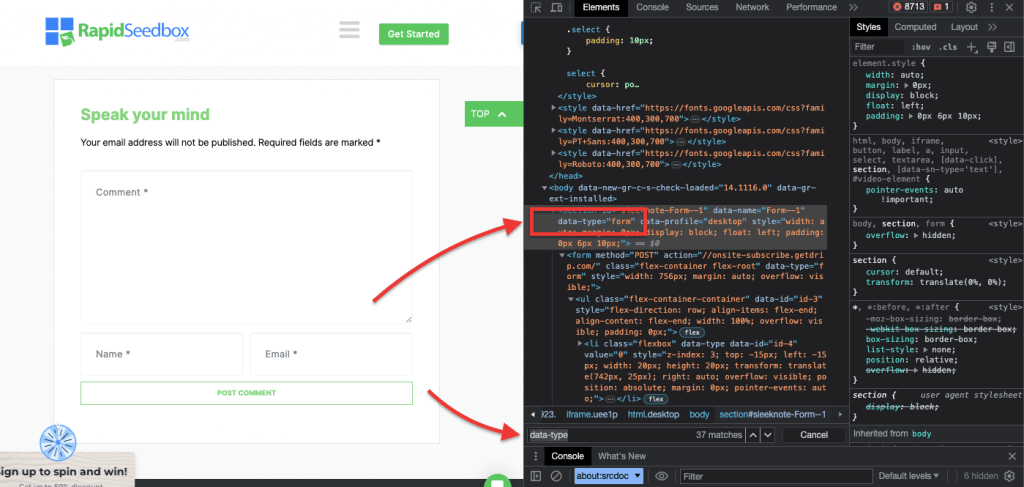
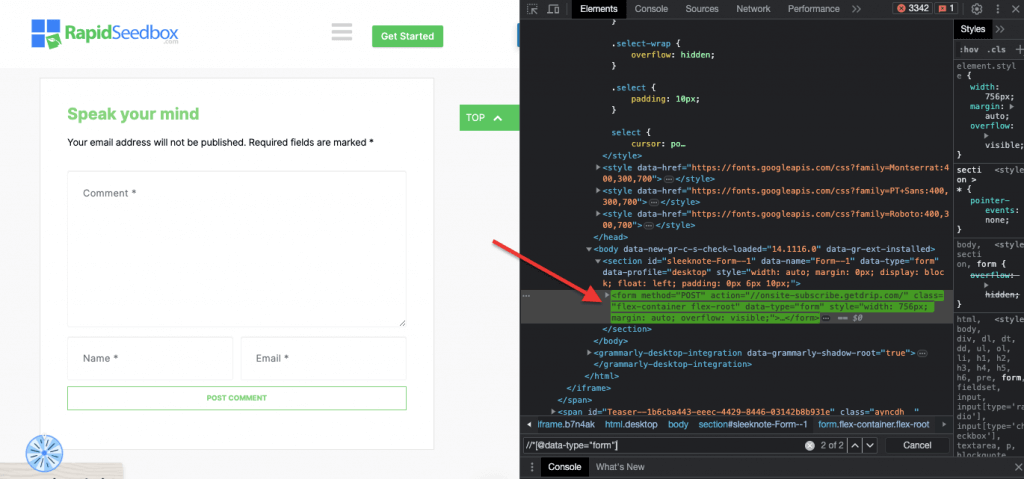
iii. Пример 3. ' //* [@data-type="form"]'
Выражение XPath //* [@data-type="form"] выбирает все элементы, имеющие атрибут data со значением "form". Адрес * символ указывает, что будет выбран любой элемент с указанным атрибутом данных, независимо от имени его узла. На следующем снимке экрана показан процесс ручного поиска элементов со значением "form".
Визуальный осмотр и извлечение данных из HTML-страницы вручную с помощью этих селекторов CSS и XPath может не только отнять много времени, но и привести к ошибкам. Кроме того, ручное или визуальное извлечение данных совершенно не подходит для масштабного сбора данных или повторяющихся задач скраппинга. Именно здесь очень полезны сценарии и программирование.
Усильте свой веб-скраппинг с помощью быстрых, безопасных и анонимных прокси-серверов от RapidSeedbox.
Какие языки программирования лучше всего подходят для веб-скреппинга?
Наиболее популярным языком программирования для скрапбукинга является Python благодаря наличию библиотек и пакетов (подробнее об этом в следующем разделе). Веб-скреппинг - это R, поскольку он также имеет фантастический набор поддерживаемых библиотек и фреймворков. Кроме того, стоит упомянуть о C# - популярном языке программирования, который используют многие веб-скреперы. На таких сайтах, как ZenRows, есть подробные руководства по как скреативить сайт в C#Это облегчает разработчикам понимание процесса и начало собственных проектов.
Для простоты изложения это руководство по веб-скреппингу будет посвящено веб-скреппингу с помощью Python. Продолжайте читать!
3. Веб-скрапинг с помощью Python (с кодом).
Зачем вам визуально проверять и вручную извлекать HTML-данные с помощью селекторов CSS или XPath, если вы можете использовать их систематически и автоматически с помощью языков программирования?
Существует множество популярных библиотек и фреймворков для веб-скрепинга, которые поддерживают CSS-селекторы для упрощения извлечения данных. Одним из самых популярных языков программирования для веб-скреппинга является Pythonдля своих библиотек, таких как BeautifulSoup, Запросы, CSS-Select, Селени Scrapy. Эти библиотеки позволяют веб-скреперам эффективно использовать селекторы CSS и XPath для извлечения данных.
BeautifulSoup.
BeautifulSoup - один из самых популярных и мощных пакетов Python, предназначенный для разбора HTML- и XML-документов. Этот пакет создает дерево разбора страниц, позволяя вам легко извлекать данные из HTML.
| Интересный факт! В борьбе с COVID-19, DXY-COVID-19-Crawler Цзябао Линя использовали BeautifulSoup для извлечения ценных данных с китайского медицинского сайта. Это помогло исследователям отследить и понять распространение вируса. [Источник] |
Запросы.
Python's Запросы это простая, но мощная библиотека HTTP. Она полезна для выполнения HTTP-запросов с целью получения данных с веб-сайтов. "Requests" упрощает процесс отправки HTTP-запросов и обработки ответов в вашем Python-проекте веб-скрапинга.
a. Учебник по веб-скрапингу с помощью Python (+ код)
В этом уроке по веб-скреппингу с помощью Python мы получим данные с целевого HTML-сайта, используя код Python с "запросами" и библиотеку BeautifulSoup.
Пререквизиты:
Убедитесь, что соблюдены следующие предварительные условия:
- Среда Python: Убедитесь, что у вас есть Python установлен на вашем компьютере. Также убедитесь, что вы можете запустить скрипт в предпочтительной среде Python (например, IDLE или Блокнот Jupyter).
- Запросы библиотеки: Установите
запросыбиблиотека. Она используется для отправки HTTP GET-запросов на указанный URL. Вы можете установить ее с помощьюpipбегомpip install requestsв командной строке или терминале. - Библиотека BeautifulSoup: Установите
красивый суп4библиотека. Вы можете установить ее, используяpipбегомpip install beautifulsoup4в вашем терминале.
Код на языке Python для извлечения данных из веб-страницы (w/ BeautifulSoup)
Следующий скрипт получит указанный URL-адрес, разберет HTML-содержимое с помощью BeautifulSoup и выведет заголовки лучших новостных статей на веб-странице.

При запуске скрипта в IDLE Shell на экран выводятся все собранные "news_titles" с целевого сайта.

b. Вариации нашего Python-кода для веб-скрапинга.
Мы можем взять наш предыдущий Python-код для веб-скреппинга и сделать несколько вариаций для поиска различных типов данных.
Например:
- Поиск изображений: Чтобы найти все теги изображений (
) на веб-странице, вы можете использовать метод find_all() с именем тега 'img':

- Поиск ссылок: Чтобы найти все теги якорей (), которые представляют ссылки на веб-странице, можно использовать метод find_all() с именем тега 'a':

Представленный скрипт (наряду с вариациями) является базовым скриптом веб-скрапинга. Он просто извлекает и печатает заголовки лучших новостных статей с указанного URL. Но, к сожалению, этому простому скрипту не хватает многих функций, которые составляют более полный проект веб-скреппинга. Есть несколько элементов, которые вы можете рассмотреть, добавив хранение данных, обработку ошибок, пагинацию/ползание, использование пользовательских агентов и заголовков, дросселирование и меры вежливости, а также возможность обработки динамического контента.
4. Законен ли веб-скрепинг?
Веб-скреппинг обычно воспринимается как противоречивая или незаконная практика. Но на самом деле это законная практика, которая при соблюдении определенных этических и правовых норм является совершенно легальной.
Законность веб-скрапинга зависит от характера извлекаемых данных и используемых методов. Веб-скреппинг считается законным, если он используется для сбора общедоступной информации из интернета. Однако всегда следует соблюдать осторожность, особенно когда речь идет о персональных данных или контенте, защищенном авторским правом.
Вот несколько советов, которые следует иметь в виду:
- Не выуживайте частные данные. Также незаконно извлекать данные, которые не находятся в открытом доступе. В США, Канаде и большинстве стран Европы извлечение данных, находящихся за страницей входа в систему с логином и паролем, запрещено законом.
- То, что вы делаете с этими данными, может привести к неприятностям. Этичный веб-скраппинг подразумевает осознание того, какие данные собираются и для чего они предназначены. Особое внимание следует уделять персональным данным и интеллектуальной собственности. Убедитесь, что вы соблюдаете такие нормативные акты, как GDPR и CCPA, которые регулируют работу с персональными данными. Например, повторное использование или перепродажа контента или загрузка материалов, защищенных авторским правом, являются незаконными (и их следует избегать).
- Также необходимо ознакомиться с условиями предоставления услуг на сайтах. Это документы, которые указывают всем, кто пользуется их услугами или контентом, как следует и как не следует взаимодействовать с ресурсами.
- Всегда используйте альтернативные варианты, например, использование официально предоставленных API. Некоторые сайты, такие как государственные учреждения, погода и платформы социальных сетей, предоставляют часть своих данных общественности через API.
- Проверьте файл robots.txt. This file is saved on the web server and gives directions to web crawlers and web scraping about what parts of a website to avoid and what parts are authorized. It also gives directions about the rate limits.
- Избегайте атак, связанных с веб-скреппингом. В зависимости от контекста, иногда веб-скраппинг называют атакой скраппинга. Когда спамеры используют ботнеты (армии ботов), чтобы направить на сайт большие и быстрые запросы, может произойти сбой в работе всего сайта. Крупномасштабное соскабливание данных может вывести из строя целые сайты.
Последние новости о юридических аспектах веб-скреппинга.
Недавние судебные решения разъяснили, что соскабливание общедоступных данных, как правило, не считается нарушением. Знаменательное решение апелляционного суда США подтвердило законность веб-скрепинга, заявив, что соскабливание общедоступных данных в Интернете не является нарушением Закона о компьютерном мошенничестве и злоупотреблениях (CFAA) [источник: TechCrunch].
Другие новости: недавние судебные иски против OpenAI и Microsoft подчеркивают озабоченность по поводу конфиденциальности, интеллектуальной собственности и законов о борьбе со взломом, согласно последним новостям [Bloomberg]. В то время как CFAA имеет ограниченную эффективность, рассматриваются иски о нарушении договора и законы штатов о конфиденциальности. Взаимодействие между авторским и договорным правом остается нерешенным, что оставляет многие вопросы без ответа в контексте веб-скреппинга.
Последние новости [источник: IndiaTimes] Элон Маск собирается изменить правила Twitter, чтобы предотвратить экстремальный уровень скраппинга данных. По мнению Маска, экстремальный веб-скрепинг негативно сказывается на пользовательском опыте. Он предположил, что в этом виноваты организации, использующие большие языковые модели для генеративного ИИ.
5. Как веб-сайты пытаются блокировать веб-скраппинг?
Компании хотят, чтобы некоторые из их данных были доступны для посетителей-людей. Но когда компании или пользователи используют автоматические скрипты или ботов для агрессивного извлечения данных с сайта, это может привести к нарушению конфиденциальности и ресурсов целевого веб-сервера и страницы. Сайты-жертвы предпочитают не допускать такого рода трафик.
Методы борьбы с кражами.
- Необычный и большой объем трафика из одного источника. На веб-серверах могут использоваться WAF (Web Application Firewalls) с черными списками шумных IP-адресов для блокировки трафика, фильтры на "необычные" скорости и размеры запросов, а также механизмы фильтрации. Некоторые сайты используют комбинацию WAF и CDN (сетей доставки контента) для полной фильтрации или уменьшения шума от таких IP-адресов.
- Некоторые веб-сайты могут обнаружить модели просмотра, похожие на ботов. Как и в предыдущем случае, сайты также блокируют запросы на основе User-Agent (HTTP-заголовок). Боты не используют обычный браузер. Эти боты имеют различные строки user-agent (например, crawler, spider или bot), отсутствие вариаций, отсутствие заголовков (безголовые браузеры), запрашивать тарифы и многое другое.
- Веб-сайты также часто меняют свою HTML-разметку. Боты, занимающиеся веб-скреппингом, следуют последовательным маршрутом "HTML-разметки" при просмотре содержимого веб-сайта. Некоторые сайты регулярно и беспорядочно меняют HTML-элементы в разметке. Такая техника выбивает бота из привычной колеи или расписания. Изменение HTML-разметки не останавливает веб-скраппинг, но делает его гораздо более сложным.
- Использование проблем, подобных CAPTCHA. Чтобы избежать использования ботами безголовых браузеров, некоторые сайты требуют заполнения CAPTCHA. Боты, использующие безголовые браузеры, с трудом решают подобные задачи. CAPTCHA были созданы для решения на уровне пользователя (через браузер), а не роботов.
- Некоторые сайты являются ловушками (honeypots) для ботов-скрепперов. Некоторые сайты создаются только для того, чтобы ловить ботов-скрепперов - такая техника называется honeypots. Эти honeypots видны только ботам-скреперам (но не обычным посетителям) и созданы для того, чтобы заманить веб-скреперов в ловушку.
6. Этические и лучшие практики для веб-скрапинга.
Веб-скреппинг должен осуществляться ответственно и этично. Как уже говорилось, чтение Условий и положений или ToS должно дать вам представление об ограничениях, которых вы должны придерживаться. Если вы хотите получить представление о правилах для веб-краулера, проверьте его ROBOTS.txt.
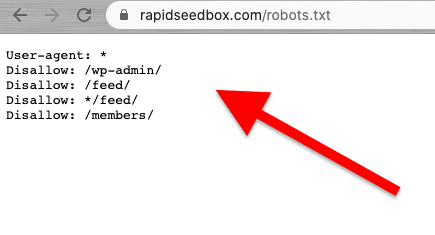
Если веб-скраппинг полностью запрещен или заблокирован, используйте их API (если он доступен).
Кроме того, учитывайте пропускную способность целевого сайта, чтобы не перегружать сервер слишком большим количеством запросов. Автоматизация запросов с определенной скоростью и правильными таймаутами, чтобы не создавать нагрузку на целевой сервер, имеет решающее значение. Оптимальной должна быть имитация работы пользователя в реальном времени. Кроме того, никогда не соскабливайте данные за страницами входа в систему.
Следуйте правилам, и все будет в порядке.
Лучшие практики веб-скрапинга.
- Используйте прокси-сервер. Прокси-сервер - это сервер-посредник, который перенаправляет запросы. При веб-скраппинге с помощью прокси-сервера вы направляете свой исходный запрос через него. Таким образом, прокси сопоставляет запрос со своим собственным IP и пересылает его на целевой сайт. Используйте прокси-сервер, чтобы:
- Исключите вероятность попадания вашего IP в черный список или блокировки. Всегда делайте запросы через различные прокси-серверы. прокси-серверы IPv6. являются хорошим примером. Пул прокси может помочь вам выполнять запросы большого объема, не подвергаясь блокировке.
- Обходите стороной геозависимый контент. Прокси в определенном регионе полезен для сбора данных в соответствии с конкретным географическим регионом. Это полезно, когда веб-сайты и сервисы находятся за CDN.
- Вращающиеся прокси. Ротационные прокси-серверы берут (ротируют) новый IP из пула для каждого нового соединения. Имейте в виду, что VPN - это не прокси-серверы. Несмотря на то, что они делают нечто очень похожее - обеспечивают анонимность, - они работают на разных уровнях.
- Повернуть UA (User Agents) и заголовки HTTP-запросов. Чтобы вращать UA и HTTP-заголовки, вам нужно собрать список строк UA из реальных веб-браузеров. Поместите этот список в код веб-скреппинга на Python и установите запросы на выбор случайных строк.
- Не ограничивайте себя. Замедляйте количество запросов, чередуйте и рандомизируйте. Если на сайт поступает большое количество запросов, начните с рандомизации. Сделайте так, чтобы каждый запрос выглядел случайным и похожим на человеческий. Во-первых, меняйте IP-адрес каждого запроса с помощью вращающихся прокси-серверов. Также используйте различные HTTP-заголовки, чтобы казалось, что запросы приходят из других браузеров.
Усильте свой веб-скраппинг с помощью быстрых, безопасных и анонимных прокси-серверов от RapidSeedbox.
7. FAQ по веб-скрапингу: Часто задаваемые вопросы.
a. Что такое robots.txt и какую роль он играет в веб-скреппинге?
RPC robots.txt файл служит средством связи между владельцами сайтов, веб-краулерами и "скреперами". Это текстовый файл, размещенный на сервере сайта и содержащий инструкции для веб-роботов (краулеров, веб-пауков и других автоматизированных ботов) о том, к каким частям сайта им разрешено обращаться и скрести, а каких частей им следует избегать. "Хорошие" веб-краулеры (например, Googlebot) предназначены для автоматического чтения robots.txt. Скреперы не предназначены для чтения этого файла. Поэтому знание robots.txt очень важно для того, чтобы уважать пожелания владельца сайта.
b. Какие методы используют администраторы веб-сайтов, чтобы избежать "неправомерных" или "несанкционированных" попыток веб-скрапинга?
Не все скреперы добывают данные этично и легально. Они не соблюдают TOS (Terms Of Service) сайта или рекомендации robots.txt. Поэтому администраторы сайтов могут принимать дополнительные меры для защиты своих данных и ресурсов, например, блокировать IP-адреса или использовать CAPTCHA-тесты. Они также могут использовать меры по ограничению скорости, проверять пользовательские агенты (для выявления потенциальных ботов), отслеживать сессии, использовать аутентификацию на основе токенов, использовать CDN (сети доставки контента) или даже применять системы обнаружения на основе поведения.
c. Веб-скраппинг против веб-краулинга?
Несмотря на то, что веб-скраппинг и веб-краулинг являются методами извлечения данных из Интернета, они имеют разные цели, сферы применения, автоматизацию и юридические аспекты. С одной стороны, методы веб-скреппинга направлены на извлечение конкретных данных с определенных сайтов. Они являются целевыми и имеют конкретную, ограниченную сферу применения. При веб-скреппинге используются автоматизированные скрипты или сторонние инструменты для запроса, получения, разбора, извлечения и структурирования данных. Методы веб-скреппинга (например просмотр списка), с другой стороны, используются для систематического поиска в Интернете. Они популярны среди поисковых систем (более широкая сфера применения), платформ социальных сетей, исследователей, агрегаторов контента и т. д. Веб-краулеры могут автоматически посещать множество сайтов (с помощью ботов, краулеров или пауков), составлять список, индексировать данные (создавать копии) и сохранять их в базе данных. Веб-краулеры обычно проверяют файлы ROBOTS.txt.
d. Data mining vs Data scraping: В чем их различия и сходства?
И добыча данных, и соскабливание данных подразумевают извлечение данных. Однако добыча данных направлена на использование статистических методов и методов машинного обучения для анализа структурированных наборов данных. Его цель - выявить закономерности, взаимосвязи и понять суть больших и сложных структурированных наборов данных. С другой стороны, скраппинг данных - это "сбор" определенной информации с веб-страниц и сайтов. Обе техники и инструменты могут использоваться вместе. Веб-скреппинг может быть предварительным этапом сбора данных из Интернета, которые затем поступают в алгоритмы интеллектуального анализа данных для углубленного анализа и обнаружения новых идей.
e. Что такое скрейпинг экрана? И как он связан со скраппингом данных?
Оба метода направлены на извлечение данных, но различаются по типу извлекаемых данных. Соскабливание экрана Инструменты предназначены для "автоматического" захвата и извлечения визуальных данных, отображаемых на веб-сайтах и в документах, включая экранный текст. В отличие от веб-скраппинга, который анализирует данные из HTML (таким образом, извлекается широкий спектр веб-данных), скринскраппинг считывает текстовые данные непосредственно с экрана.
f. Является ли веб-сборка тем же самым, что и веб-скраппинг?
Сбор данных и сбор информации в Интернете тесно связаны между собой и часто используются как взаимозаменяемые понятия, однако это не одно и то же. Веб-сборка имеет более широкое значение. Он включает в себя различные методы извлечения данных из Интернета, в том числе различные механизмы автоматического извлечения данных из Интернета, такие как веб-скрепинг. Четкое различие заключается в том, что веб-сборка часто используется, когда речь идет об API, а не о прямом разборе HTML-кода веб-страниц (как это делает веб-сборка).
g. CSS Selector vs XPath Selector: В чем разница при скраппинге?
Селекторы CSS - эффективный способ извлечения данных при веб-скреппинге. Они обладают простым синтаксисом и хорошо работают в большинстве сценариев скраппинга. Однако в более сложных случаях или при работе с вложенными структурами селекторы XPath могут обеспечить дополнительную гибкость и функциональность.
h. Как работать с динамическими веб-сайтами с помощью Selenium?
Selenium - это мощный инструмент для анализа динамических веб-сайтов. Он позволяет взаимодействовать с элементами на веб-странице так, как это делал бы пользователь. Эта способность позволяет вашему "скрипту" перемещаться по динамически генерируемому контенту. Используя WebDriver от SeleniumВы можете ждать загрузки элементов страницы, взаимодействовать с элементами AJAX и собирать данные с веб-сайтов, которые в значительной степени опираются на JavaScript.
i. Как работать с AJAX и JavaScript при веб-скрапинге?
При работе с AJAX и JavaScript во время веб-скрапинга традиционных библиотек, таких как Requests и Beautiful Soup, может быть недостаточно. Для обработки AJAX-запросов и JavaScript-рендеринга можно использовать такие инструменты, как Selenium, или безголовые браузеры, такие как Кукловод.
8. Заключение
Поздравляем! Вы завершаете работу над окончательным руководством по веб-скреппингу!
Мы надеемся, что это руководство снабдило вас знаниями и инструментами для использования потенциала веб-скреппинга в ваших проектах.
Помните, что с большой властью приходит и большая ответственность. Начиная свой путь в области веб-скреппинга, всегда отдавайте предпочтение этическим нормам, соблюдайте условия обслуживания сайтов и помните о конфиденциальности данных.
Мы коснулись верхушки айсберга. Веб-скрапинг может быть довольно обширной темой. Но, эй, вы уже скрапили сайт!
Постоянное обучение и знакомство с новейшими технологиями и правовыми изменениями позволят вам ориентироваться в этом сложном мире.
Визуальный осмотр и извлечение данных из HTML-страницы вручную с помощью этих селекторов CSS и XPath может не только отнять много времени, но и привести к ошибкам. Кроме того, ручное или визуальное извлечение данных совершенно не подходит для масштабного сбора данных или повторяющихся задач скраппинга. Именно здесь очень полезны сценарии и программирование.
0Комментарии